COMPUTER SYSTEM ARCHITECTURE Reviewer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Is Parallel Programming Hard, And, If So, What Can You Do About It?
Is Parallel Programming Hard, And, If So, What Can You Do About It? Edited by: Paul E. McKenney Linux Technology Center IBM Beaverton [email protected] December 16, 2011 ii Legal Statement This work represents the views of the authors and does not necessarily represent the view of their employers. IBM, zSeries, and Power PC are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. Linux is a registered trademark of Linus Torvalds. i386 is a trademarks of Intel Corporation or its subsidiaries in the United States, other countries, or both. Other company, product, and service names may be trademarks or service marks of such companies. The non-source-code text and images in this doc- ument are provided under the terms of the Creative Commons Attribution-Share Alike 3.0 United States li- cense (http://creativecommons.org/licenses/ by-sa/3.0/us/). In brief, you may use the contents of this document for any purpose, personal, commercial, or otherwise, so long as attribution to the authors is maintained. Likewise, the document may be modified, and derivative works and translations made available, so long as such modifications and derivations are offered to the public on equal terms as the non-source-code text and images in the original document. Source code is covered by various versions of the GPL (http://www.gnu.org/licenses/gpl-2.0.html). Some of this code is GPLv2-only, as it derives from the Linux kernel, while other code is GPLv2-or-later. -

Management of Data Elements in Information Processing
PB-249-530 MANAGEMENT OF DATA ELEMENTS IN INFORMATION PROCESSING U.S. DEPARTMENT OF COMMERCE / National Bureau of Standards SECOND NATIONAL SYMPOSIUM NATIONAL BUREAU OF STANDARDS GAITHERSBURG, MARYLAND 1975 OCTOBER 23-24 Available by purchase from the National Technical Information Service, 5285 Port Royal Road, Springfield, Va. 221 Price: $9.25 hardcopy; $2.25 microfiche. National Technical Information Service U. S. DEPARTMENT OF COMMERCE PB-249-530 Management of Data Elements in Information Processing Proceedings of a Second Symposium Sponsored by the American National Standards Institute and by The National Bureau of Standards 1975 October 23-24 NBS, Gaithersburg, Maryland Hazel E. McEwen, Editor Institute for Computer Sciences and Technology National Bureau of Standards Washington, D.C. 20234 U.S. DEPARTMENT OF COMMERCE, Elliot L. Richardson, Secrefary NATIONAL BUREAU OF STANDARDS, Ernest Ambler, Acfing Direc/or Table of Contents Page Introduction to the Program of the Second National Symposium on The Management of Data Elements in Information Processing ix David V. Savidge, Program Chairman On-Line Tactical Data Inputting: Research in Operator Training and Performance 1 Irving Alderman, Ph.D. "Turning the Corner" on MIS, A Proposed Program of Data Standards in Post-Secondary Education 9 Donald R. Arnold, Ph.D. ASCII - The Data Alphabet That Will Endure 17 Robert W. Bemer Techniques in Developing Standard Procedures for Data Editing 23 George W. Covill An Adaptive File Management Systems 45 Dennis L. Dance and Udo W. Pooch (Given by Dance) A Focus on the Role of the Data Manager 57 Ruth M, Davis, Ph.D. A Proposed Standard Routine for Generating Proposed Standard Check Characters 61 Paul -Andre Desjardins Methodology for Development of Standard Data Elements within Multiple Public Agencies 69 L. -

Antipatterns Refactoring Software, Architectures, and Projects in Crisis
AntiPatterns Refactoring Software, Architectures, and Projects in Crisis William J. Brown Raphael C. Malveau Hays W. McCormick III Thomas J. Mowbray John Wiley & Sons, Inc. Publisher: Robert Ipsen Editor: Theresa Hudson Managing Editor: Micheline Frederick Text Design & Composition: North Market Street Graphics Copyright © 1998 by William J. Brown, Raphael C. Malveau, Hays W. McCormick III, and Thomas J. Mowbray. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per−copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750−8400, fax (978) 750−. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158−, (212) 850−, fax (212) 850−, E−Mail: PERMREQ @ WILEY.COM. This publication is designed to provide accurate and authoritative information in regard to the subject matter covered. It is sold with the understanding that the publisher is not engaged in professional services. If professional advice or other expert assistance is required, the services of a competent professional person should be sought. Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or all capital letters. -

H/W3 Binary to Denary
Name ___________________________________ Form ________ H/W Year 8 Homework Booklet Theme 1 Data Representation Computers themselves, and “ software yet to be developed, will revolutionize “ the way we learn. - Steve Jobs Founder of Apple Introduction What language does a computer understand? How does a computer represent data, information and images? Soon, you will be able to answer the questions above! In this theme we will explore the different ways in which data is represented by the computer, ranging from numbers to images. We will learn and understand the number bases and conversions between denary and binary. We will also be looking at units of information, binary addition and how we can convert binary data into a black and white image! See the key below to find out what the icons below mean: Self Assessment: You will mark your work at the start of next lesson. ENSURE YOU COMPELTE HOMEWORK AS MARKS WILL BE COLLECTED IN! Edmodo Quiz: The will be a quiz the start of next lesson based on your homework. SO MAKE SURE YOU REVISE! Peer Assessment: Homework marked by your class mate at the start of next lesson. MAKE SURE YOU HAVE YOUR HOMEWORK DONE SO YOU CAN SWAP WITH ANOTHER PUPIL! Stuck? Got a question? Email your teacher. Mr Rifai (Head of Computing) [email protected] Miss Davison [email protected] Miss Pascoe [email protected] 2 Due Date: H/W1 Data & Number Bases Read and digest the information below. You will be quizzed next lesson! Any set of characters gathered and translated for What is Data? some purpose. -

Performance Analyses and Code Transformations for MATLAB Applications Patryk Kiepas
Performance analyses and code transformations for MATLAB applications Patryk Kiepas To cite this version: Patryk Kiepas. Performance analyses and code transformations for MATLAB applications. Computa- tion and Language [cs.CL]. Université Paris sciences et lettres, 2019. English. NNT : 2019PSLEM063. tel-02516727 HAL Id: tel-02516727 https://pastel.archives-ouvertes.fr/tel-02516727 Submitted on 24 Mar 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Préparée à MINES ParisTech Analyses de performances et transformations de code pour les applications MATLAB Performance analyses and code transformations for MATLAB applications Soutenue par Composition du jury : Patryk KIEPAS Christine EISENBEIS Le 19 decembre 2019 Directrice de recherche, Inria / Paris 11 Présidente du jury João Manuel Paiva CARDOSO Professeur, University of Porto Rapporteur Ecole doctorale n° 621 Erven ROHOU Ingénierie des Systèmes, Directeur de recherche, Inria Rennes Rapporteur Matériaux, Mécanique, Michel BARRETEAU Ingénieur de recherche, THALES Examinateur Énergétique Francois GIERSCH Ingénieur de recherche, THALES Invité Spécialité Claude TADONKI Informatique temps-réel, Chargé de recherche, MINES ParisTech Directeur de thèse robotique et automatique Corinne ANCOURT Maître de recherche, MINES ParisTech Co-directrice de thèse Jarosław KOŹLAK Professeur, AGH UST Co-directeur de thèse 2 Abstract MATLAB is an interactive computing environment with an easy programming language and a vast library of built-in functions. -

Large-Scale Software Architecture
Large-Scale Software Architecture A Practical Guide using UML Jeff Garland CrystalClear Software Inc. Richard Anthony Object Computing Inc. Large-Scale Software Architecture Large-Scale Software Architecture A Practical Guide using UML Jeff Garland CrystalClear Software Inc. Richard Anthony Object Computing Inc. Copyright # 2003 by John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England Telephone (+44) 1243 779777 Email (for orders and customer service enquiries): [email protected] Visit our Home Page on www.wileyeurope.com or www.wiley.com All Rights Reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except under the terms of the Copyright, Designs and Patents Act 1988 or under the terms of a licence issued by the Copyright Licensing Agency Ltd, 90 Tottenham Court Road, London W1T 4LP, UK, without the permission in writing of the Publisher, with the exception of any material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the publication. Requests to the Publisher should be addressed to the Permissions Department, John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England, or emailed to [email protected], or faxed to (+44) 1243 770571. Neither the authors nor John Wiley & Sons, Ltd accept any responsibility or liability for loss or damage occasioned to any person or property through using the material, instructions, methods or ideas contained herein, or acting or freraining from acting as a result of such use. -

On Identifying Basic Discourse Units in Speech: Theoretical and Empirical Issues
Discours Revue de linguistique, psycholinguistique et informatique. A journal of linguistics, psycholinguistics and computational linguistics 4 | 2009 Linearization and Segmentation in Discourse On identifying basic discourse units in speech: theoretical and empirical issues Liesbeth Degand and Anne Catherine Simon Electronic version URL: http://journals.openedition.org/discours/5852 DOI: 10.4000/discours.5852 ISSN: 1963-1723 Publisher: Laboratoire LATTICE, Presses universitaires de Caen Electronic reference Liesbeth Degand and Anne Catherine Simon, « On identifying basic discourse units in speech: theoretical and empirical issues », Discours [Online], 4 | 2009, Online since 30 June 2009, connection on 10 December 2020. URL : http://journals.openedition.org/discours/5852 ; DOI : https://doi.org/ 10.4000/discours.5852 Discours est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International. Discours 4 | 2009, Linearization and Segmentation in Discourse (Special issue) On identifying basic discourse units in speech: theoretical and empirical issues Liesbeth Degand1,2, Anne Catherine Simon2 1FNRS, 2Université catholique de Louvain Abstract: In spite of its crucial role in discourse segmentation and discourse interpretation, there is no consensus in the literature on what a discourse unit is and how it should be identified. Working with spoken data, we claim that the basic discourse unit (BDU) is a multi-dimensional unit that should be defined in terms of two linguistic criteria: prosody and syntax. In this paper, we explain which criteria are used to perform the prosodic and syntactic segmentation, and how these levels are mapped onto one another. We discuss three types BDUs (one-to-one, syntax-bound, prosody- bound) and open up a number of theoretical issues with respect to their function in discourse interpretation. -

Lecture Notes
CSCI E-84 A Practical Approach to Data Science Ramon A. Mata-Toledo, Ph.D. Professor of Computer Science Harvard University Unit 1 - Lecture 1 January, Wednesday 27, 2016 Required Textbooks Main Objectives of the Course This course is an introduction to the field of data science and its applicability to the business world. At the end of the semester you should be able to: • Understand how data science fits in an organization and gather, select, and model large amounts of data. • Identify the appropriate data and the methods that will allow you to extract knowledge from this data using the programming language R. What This Course is NOT is an in-depth calculus based statistic research environment . What is this course all about? It IS is a practical “hands-on approach” to understanding the methodology and tools of Data Science from a business prospective. Some of the technical we will briefly consider are: • Statistics • Database Querying • SQL • Data Warehousing • Regression Analysis • Explanatory versus Predictive Modeling Brief History of Data Science/Big Data The term data science can be considered the result of three main factors: • Evolution of data processing methods • Internet – particularly the Web 2.0 • Technological Advancements in computer processing speed/storage and development of algorithms for extracting useful information and knowledge from big data Brief History of Data Science/Big Data (continuation) However, “…Already seventy years ago we encounter the first attempts to quantify the growth rate in the volume of data or what has popularly been known as the “information explosion” (a term first used in 1941, according to the Oxford English Dictionary). -
![[0470848499]Large-Scale Software Architecture.Pdf](https://docslib.b-cdn.net/cover/7472/0470848499-large-scale-software-architecture-pdf-1907472.webp)
[0470848499]Large-Scale Software Architecture.Pdf
Y L F M A E T Team-Fly® Large-Scale Software Architecture A Practical Guide using UML Jeff Garland CrystalClear Software Inc. Richard Anthony Object Computing Inc. Large-Scale Software Architecture Large-Scale Software Architecture A Practical Guide using UML Jeff Garland CrystalClear Software Inc. Richard Anthony Object Computing Inc. Copyright # 2003 by John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England Telephone (+44) 1243 779777 Email (for orders and customer service enquiries): [email protected] Visit our Home Page on www.wileyeurope.com or www.wiley.com All Rights Reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except under the terms of the Copyright, Designs and Patents Act 1988 or under the terms of a licence issued by the Copyright Licensing Agency Ltd, 90 Tottenham Court Road, London W1T 4LP, UK, without the permission in writing of the Publisher, with the exception of any material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the publication. Requests to the Publisher should be addressed to the Permissions Department, John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England, or emailed to [email protected], or faxed to (+44) 1243 770571. Neither the authors nor John Wiley & Sons, Ltd accept any responsibility or liability for loss or damage occasioned to any person or property through using the material, instructions, methods or ideas contained herein, or acting or freraining from acting as a result of such use. -

Download Full Book
Introduction to Computing Explorations in Language, Logic, and Machines David Evans University of Virginia For the latest version of this book and supplementary materials, visit: http://computingbook.org Version: August 19, 2011 Attribution-Noncommercial-Share Alike 3.0 United States License Contents 1 Computing 1 1.1 Processes, Procedures, and Computers . 2 1.2 Measuring Computing Power . 3 1.2.1 Information . 3 1.2.2 Representing Data . 8 1.2.3 Growth of Computing Power . 12 1.3 Science, Engineering, and the Liberal Arts . 13 1.4 Summary and Roadmap . 16 Part I: Defining Procedures 2 Language 19 2.1 Surface Forms and Meanings . 19 2.2 Language Construction . 20 2.3 Recursive Transition Networks . 22 2.4 Replacement Grammars . 26 2.5 Summary . 32 3 Programming 35 3.1 Problems with Natural Languages . 36 3.2 Programming Languages . 37 3.3 Scheme . 39 3.4 Expressions . 40 3.4.1 Primitives . 40 3.4.2 Application Expressions . 41 3.5 Definitions . 44 3.6 Procedures . 45 3.6.1 Making Procedures . 45 3.6.2 Substitution Model of Evaluation . 46 3.7 Decisions . 48 3.8 Evaluation Rules . 50 3.9 Summary . 52 4 Problems and Procedures 53 4.1 Solving Problems . 53 4.2 Composing Procedures . 54 4.2.1 Procedures as Inputs and Outputs . 55 4.3 Recursive Problem Solving . 56 4.4 Evaluating Recursive Applications . 64 4.5 Developing Complex Programs . 67 4.5.1 Printing . 68 4.5.2 Tracing . 69 4.6 Summary . 73 5 Data 75 5.1 Types . 75 5.2 Pairs . -
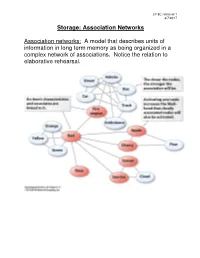
Storage: Association Networks Association Networks: a Model That
LP 8C retrieval 1 3/7/2017 Storage: Association Networks Association networks: A model that describes units of information in long term memory as being organized in a complex network of associations. Notice the relation to elaborative rehearsal. LP 8C retrieval 2 3/7/2017 Broken Associations Make Retrieval Difficult LP 8C retrieval 3 3/7/2017 Schemas and Encoding Schemas: Cognitive structures that help us perceive, organize, process and use information ( page 280). In the following example, a schema helps organize the seemingly random and obscure statements. Instructions: Take a minute to read through this paragraph. After a minute, try to recall as much information about the paragraph as you can. Do the best you can, exact word for word recall is not required as long as it is close. The procedure is actually quite simple. First arrange things into different groups. Of course, one pile may be sufficient depending on how much there is to do. If you have to go somewhere else due to lack of facilities that is the next step, otherwise you are pretty well set. It is important not to overdo things. That is, it is better to do too few things at once than too many. In the short run this may not seem important but complications can easily arise. A mistake can be expensive as well. At first, the whole procedure will seem complicated. Soon, however, it will become just another facet of life. It is difficult to foresee any end of the necessity for this task in the immediate future, but then one never can tell. -

Megabyte from Wikipedia, the Free Encyclopedia
Megabyte From Wikipedia, the free encyclopedia The megabyte is a multiple of the unit byte for digital information storage or transmission with two different values depending on context: 1 048 576 bytes (220) generally for computer memory;[1][2] and one million bytes (106, see prefix mega-) generally for computer storage.[1][3] The IEEE Standards Board has decided that "Mega will mean 1 000 000", with exceptions allowed for the base-two meaning.[3] In rare cases, it is used to mean 1000×1024 (1 024 000) bytes.[3] It is commonly abbreviated as Mbyte or MB (compare Mb, for the megabit). Multiples of bytes Contents SI decimal prefixes Binary IEC binary prefixes Name Value usage Name Value 1 Definition (Symbol) (Symbol) 2 Examples of use 3 10 10 3 See also kilobyte (kB) 10 2 kibibyte (KiB) 2 4 References megabyte (MB) 106 220 mebibyte (MiB) 220 5 External links gigabyte (GB) 109 230 gibibyte (GiB) 230 terabyte (TB) 1012 240 tebibyte (TiB) 240 Definition petabyte (PB) 1015 250 pebibyte (PiB) 250 exabyte (EB) 1018 260 exbibyte (EiB) 260 The term "megabyte" is commonly used to mean either zettabyte (ZB) 1021 270 zebibyte (ZiB) 270 10002 bytes or 10242 bytes. This originated as yottabyte (YB) 1024 280 yobibyte (YiB) 280 compromise technical jargon for the byte multiples that needed to be expressed by the powers of 2 but lacked See also: Multiples of bits · Orders of magnitude of data a convenient name. As 1024 (210) approximates 1000 (103), roughly corresponding SI multiples began to be used for binary multiples.