Dong, S., Sun, Y., Bohm Agostini, N., Karimi, E., Lowell, D., Zhou, J., Cano, J
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
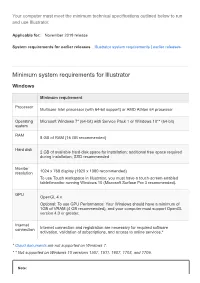
Minimum System Requirements for Illustrator
Your computer must meet the minimum technical specifications outlined below to run and use Illustrator. Applicable for: November 2019 release System requirements for earlier releases Illustrator system requirements | earlier releases Minimum system requirements for Illustrator Windows Minimum requirement Processor Multicore Intel processor (with 64-bit support) or AMD Athlon 64 processor Operating Microsoft Windows 7* (64-bit) with Service Pack 1 or Windows 10** (64-bit) system RAM 8 GB of RAM (16 GB recommended) Hard disk 2 GB of available hard-disk space for installation; additional free space required during installation; SSD recommended Monitor resolution 1024 x 768 display (1920 x 1080 recommended) To use Touch workspace in Illustrator, you must have a touch-screen-enabled tablet/monitor running Windows 10 (Microsoft Surface Pro 3 recommended). GPU OpenGL 4.x Optional: To use GPU Performance: Your Windows should have a minimum of 1GB of VRAM (4 GB recommended), and your computer must support OpenGL version 4.0 or greater. Internet connection Internet connection and registration are necessary for required software activation, validation of subscriptions, and access to online services.* * Cloud documents are not supported on Windows 7. * * Not supported on Windows 10 versions 1507, 1511, 1607, 1703, and 1709. Note: Scalable UI feature is supported on Windows 10 (minimum resolution supported is 1920 x 1080). Auto handle feature is supported on Windows 10. GPU in Outline mode is supported on monitor with display resolution at least 2000 pixels in any dimension. Supported video adapter The following video adapter series support the new Windows GPU Performance features in Illustrator: NVIDIA NVIDIA Quadro K Series NVIDIA Quadro 6xxx NVIDIA Quadro 5xxx NVIDIA Quadro 4xxx NVIDIA Quadro 2xxx NVIDIA Quadro 2xxxD NVIDIA Quadro 6xx NVIDIA GeForce GTX Series (4xx, 5xx, 6xx, 7xx, 9xx, Titan) NVIDIA Quadro M Series NVIDIA Quadro P Series NVIDIA Quadro RTX 4000 Important: Microsoft Windows may not detect the availability of the latest device drivers for NVIDIA GPU cards. -

AMD Releases ATI Catalyst 72
AMD Releases ATI Catalyst 7.2 1 / 4 AMD Releases ATI Catalyst 7.2 2 / 4 3 / 4 Just moments ago AMD released this months update to the ATI Catalyst drivers, bringing the Radeon powering software up to version 7.2. Along with the usual .... AMD --. Version 7.2.0 of the xf86-video-ati DDX driver was released this morning. While the X.Org drivers aren't too exciting these days with .... Catalyst 7.2 is available now and boosts performance for all ATI Radeon X1000 series cards. ATI has released new drivers for Windows XP, .... File Description: ATI CATALYST 7.2(FEBRUARY 2007) OFFICAL RELEASE VGA/SOUTHBRIDGE DRIVER FEATURING NEW CATALYST .... Developer. AMD Inc. Latest Version. ATI Catalyst Drivers 14.6 (Beta). Supported Systems ... Version Name. Released Date. Size ... ATI Catalyst 7.2. 22 February .... AMD just released the new Catalyst 7.2 drivers for ATI graphics cards. Some of the ... Open GL performance improves for all ATI Radeon X1000 series products.. This release for all Radeon family products updates the AMD display driver to the latest version. This unified driver has been further enhanced .... ATI Catalyst 7.2 Released AMD/ATI have released their latest set of video card drivers for both Windows XP and Windows Vista. Catalyst™ 7.2 .... AMD/ATI has released its latest version of the Catalyst drivers, which are used by the Radeon 9500 series and higher. There are 32-bit and .... ATI Catalyst™ Software Suite Version 7.2. This release note provides information on the latest posting of AMD's industry leading software suite, Catalyst™. -

Technical Specifications Features Specifications
AQ01 SKU: ZBOXNANO-AQ01-BE/U/J/AUS Embrace quad processor cores in a palm-sized form factor with the ZOTAC ZBOX nano AQ01 series. Powered by the latest high-performance AMD APU, the ZOTAC ZBOX nano AQ01 series ushers in a new era of palm-sized computing that offers whisper-quiet noise levels, outstanding energy-efficiency and rich AMD Radeon HD graphics. AMD Radeon HD 8000 series graphics processing enables compatibility with Microsoft DirectX 11.1, OpenCL and compute technologies on the ZOTAC ZBOX nano AQ01 series for excellent performance and compatibility with the latest applications. High-definition video processing capabilities transforms the ZOTAC ZBOX nano AQ01 series into a multimedia powerhouse for stunning HD audio and video playback. THE IDEAL MINIATURE SOLUTION FOR ANY ROOM IN YOUR HOME. TECHNICAL SPECIFICATIONS In your living room... In your kitchen... In your bedroom... FEATURES FRONT PORTS • Universal Video Decoder (UVD) • 2 USB 2.0 ports • Blu-ray hardware decode acceleration • Microphone jack • Adobe Flash Player acceleration • 7-in-1 Memory card reader • Microsoft DirectX 11.1 compatible • (MMC/SD/SDHC/SDXC/MS/MS Pro/xD) • OpenGL 4.3 compatible • Integrated IR receiver • OpenCL compatible • Power button SPECIFICATIONS REAR PORTS • AMD Radeon HD 8330 • 2 USB 3.0 ports • AMD A4-5000 (quad-core, 1.5 GHz) • 3 USB 2.0 ports • 10/100/1000 Ethernet (RJ45) HARD DRIVE & MEMORY • Power connector • WiFi antenna connector • 1 2.5-inch SATA 6.0 Gb/s (9.5mm height) • 1 204-pin DDR3-1600 SO-DIMM (up to 8GB) SOFTWARE COMPATIBILITY DISPLAY -

Amd Radeon 7000 Series Driver Download Amd Radeon 7000 Series Driver Download
amd radeon 7000 series driver download Amd radeon 7000 series driver download. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 67a1b815bb7484d4 • Your IP : 188.246.226.140 • Performance & security by Cloudflare. DRIVERS AMD RADEONTM HD 7000 SERIES WINDOWS VISTA. Tech tip, updating drivers manually requires some computer skills and patience. Amd/ati drivers you have been having this graphic. This tool is designed to detect the model of amd graphics card and the version of microsoft windows installed in your system, and then provide the option to download and install the latest official amd driver. Compaq cq42-304au. Your system for the radeon hd 7000. For use with systems equipped with amd radeon discrete desktop graphics, mobile graphics, or amd processors with radeon graphics. Download drivers are running amd radeon drivers by jervis on topic. Hd 7000 series for amd 7000 series amd accelerated processing units. Integer Scaling. Developers working with the amd embedded r-series apu can implement remote management, client virtualization and security capabilities to help reduce deployment costs and increase security and reliability of their amd r-series based platform through amd das 1.0 featuring dash 1.1, amd virtualization and trusted platform module tpm 1.2 support. -

Adobe Illustrator - Minimum System Requirements
Adobe Illustrator - Minimum system requirements Windows Minimum requirement Multicore Intel processor (with 32/64-bit support) or AMD Athlon 64 Processor processor Operating Microsoft Windows 7 with Service Pack 1, Windows 10* system 2 GB of RAM (4 GB recommended) for 32 bit; 4 GB of RAM (16 GB RAM recommended) for 64 bit 2 GB of available hard-disk space for installation; additional free space Hard disk required during installation; SSD recommended 1024 x 768 display (1920 x 1080 recommended) Monitor To use Touch workspace in Illustrator, you must have a touch-screen- resolution enabled tablet/monitor running Windows 10 (Microsoft Surface Pro 3 recommended). OpenGL 4.x GPU Optional: To use GPU Performance: Your Windows should have a minimum of 1GB of VRAM (4 GB recommended), and your computer must support OpenGL version 4.0 or greater. Internet Internet connection and registration are necessary for required software connection activation, validation of subscriptions, and access to online services.* * October 2018 release of Illustrator is not supported on Windows 10 version 1507, 1511, 1607. Note: • Scalable UI feature is supported on Winodws 10 (minimum resolution supported is 1920 x 1080). • Auto handle feature is supported on Windows 10. • GPU in Outline mode is supported on monitor with display resolution at least 2000 pixels in any dimension. • Graphics processor-powered features are not supported on 32-bit Windows platform. • Actual view feature is not supported on 32-bit Windows 7 platform. Supported video adapter The following video adapter series support the new Windows GPU Performance features in Illustrator: NVIDIA • NVIDIA Quadro K Series • NVIDIA Quadro 6xxx • NVIDIA Quadro 5xxx • NVIDIA Quadro 4xxx • NVIDIA Quadro 2xxx • NVIDIA Quadro 2xxxD • NVIDIA Quadro 6xx • NVIDIA GeForce GTX Series (4xx, 5xx, 6xx, 7xx, 9xx, Titan) • NVIDIA Quadro M Series • NVIDIA Quadro P Series Important: Microsoft Windows may not detect the availability of the latest device drivers for NVIDIA GPU cards. -
GPU Busy Than Opengl Is
6/29/2020 1 Computer Graphics Introduction to the Vulkan Computer Graphics API Mike Bailey [email protected] This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License http://cs.oregonstate.edu/~mjb/vulkan FULL.pptx mjb – June 25, 2020 2 Course Goals • Give a sense of how Vulkan is different from OpenGL • Show how to do basic drawing in Vulkan • Leave you with working, documented sample code http://cs.oregonstate.edu/~mjb/vulkan mjb – June 25, 2020 1 6/29/2020 3 Mike Bailey • Professor of Computer Science, Oregon State University • Has been in computer graphics for over 30 years • Has had over 8,000 students in his university classes • [email protected] Welcome! I’m happy to be here. I hope you are too ! http://cs.oregonstate.edu/~mjb/vulkan mjb – June 25, 2020 4 Sections 13.Swap Chain 1. Introduction 14.Push Constants 2. Sample Code 15.Physical Devices 3. Drawing 16.Logical Devices 4. Shaders and SPIR-V 17.Dynamic State Variables 5. Dats Buffers 18.Getting Information Back 6. GLFW 19.Compute Shaders 7. GLM 20.Specialization Constants 8. Instancing 21.Synchronization 9. Graphics Pipeline Data Structure 22.Pipeline Barriers 10.Descriptor Sets 23.Multisampling 11.Textures 24.Multipass 12.Queues and Command Buffers 25.Ray Tracing mjb – June 25, 2020 2 6/29/2020 5 My Favorite Vulkan Reference Graham Sellers, Vulkan Programming Guide, Addison-Wesley, 2017. mjb – June 25, 2020 6 Introduction Mike Bailey [email protected] http://cs.oregonstate.edu/~mjb/vulkan mjb – June 25, 2020 3 6/29/2020 Acknowledgements 7 First of all, thanks to the inaugural class of 19 students who braved new, unrefined, and just- in-time course materials to take the first Vulkan class at Oregon State University – Winter Quarter, 2018. -

AMD Codexl 1.3 GA Release Notes
AMD CodeXL 1.3 GA Release Notes Thank you for using CodeXL. We appreciate any feedback you have! Please use the CodeXL Forum to provide your feedback. You can also check out the Getting Started guide on the CodeXL Web Page and the latest CodeXL blog at AMD Developer Central - Blogs This version contains: For Windows for 32-bit and 64-bit Windows platforms o CodeXL Standalone application o CodeXL Microsoft® Visual Studio® 2010 extension o CodeXL Microsoft® Visual Studio® 2012 extension o CodeXL Remote Agent For 64-bit Linux platforms o CodeXL Standalone application o CodeXL Remote Agent Note about 32-bit Windows CodeXL 1.3 Upgrade Error On 32-bit Windows platforms, upgrading from CodeXL 1.0 using the CodeXL 1.3 installer will remove the previous version and then display an error message without installing CodeXL 1.3. The recommended method is to uninstall previous CodeXL versions before installing CodeXL 1.3. If you ran the 1.3 installer to upgrade a previous installation and encountered the error mentioned above, ignore the error and run the installer again to install CodeXL 1.3. Note about installing CodeAnalyst after installing CodeXL for Windows CodeXL can be safely installed on a Windows station where AMD CodeAnalyst is already installed. However, do not install CodeAnalyst on a Windows station already installed with CodeXL. Uninstall CodeXL first, and then install CodeAnalyst. System Requirements CodeXL contains a host of development features with varying system requirements: GPU Profiling and OpenCL Kernel Debugging o An AMD GPU (Radeon HD 5000 series or newer, desktop or mobile version) or APU is required. -
United States Securities and Exchange Commission Form
Table of Contents UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 10-K (Mark One) x ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934. For the fiscal year ended December 29, 2012 OR ¨ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934. For the transition period from to Commission File Number 001-07882 ADVANCED MICRO DEVICES, INC. (Exact name of registrant as specified in its charter) Delaware 94-1692300 (State or other jurisdiction of incorporation or organization) (I.R.S. Employer Identification No.) One AMD Place, Sunnyvale, California 94088 (Address of principal executive offices) (Zip Code) (408) 749-4000 (Registrant’s telephone number, including area code) Securities registered pursuant to Section 12(b) of the Act: (Title of each class) (Name of each exchange on which registered) Common Stock per share $0.01 par value New York Stock Exchange Securities registered pursuant to Section 12(g) of the Act: None Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes x No ¨ Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Exchange Act. Yes ¨ No x Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -

Gpgpus and Their Programming
GPGPUs and their programming Sima, Dezső Szénási, Sándor Created by XMLmind XSL-FO Converter. GPGPUs and their programming írta Sima, Dezső és Szénási, Sándor Szerzői jog © 2013 Typotex Kivonat The widespread use of GPGPUs in an increasing number of HPC (High Performance Computing) areas, such as scientific, engineering, financial and business applications, is one of recent major trends in using informatics. The lecture slides worked out pursuit two goals. On the one side the lecture aims at presenting the principle of operation, the microarchitecture and main features of GPGPU cores, as well as their implementation as graphics cards or data parallel accelerators. On the other hand, the practical part of the lectures aims at acquainting students with data parallel programming, first of all with GPGPU programming and program optimization using the CUDA language and programming environment. Created by XMLmind XSL-FO Converter. Tartalom I. GPGPUs .......................................................................................................................................... 1 Aim .......................................................................................................................................... ix 1. Introduction to GPGPUs .................................................................................................... 10 1. Representation of objects by triangles ...................................................................... 10 1.1. Main types of shaders in GPUs ................................................................... -

FGPU : a Flexible Soft GPU Architecture for General Purpose Computing On
FGPU:A Flexible Soft GPU Architecture for General Purpose Computing on FPGAs by Muhammed AL KADI A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Chair for Embedded Systems for Information Technology Ruhr University of Bochum FGPU:A Flexible Soft GPU Architecture for General Purpose Computing on FPGAs Dissertation zur Erlangung des Grades eines Doktor-Ingenieurs der Fakultät für Elektrotechnik und Informationstechnik an der Ruhr-Universität Bochum vorgelegt von Muhammed AL KADI geboren in Edlib, Syrien Bochum, 2017 Hauptbetreuer: Prof. Dr.-Ing. Michael Hübner Co-Betreuer: Prof. João Cardoso Tag der mündlichen Prüfung: 10.11.2017 Abstract Realizing embedded Graphics Processing Units (GPUs) on top of Field-Programmable Gate Arrays (FPGAs) would lead a new family of processors: it offers the efficiency and the standardized programming of GPU architectures with the flexibility and reconfig- urability of FPGA platforms. This dissertation describes the hardware and the tool flow of the FPGA-GPU (FGPU): a configurable, scalable and portable GPU designed specially for FPGAs. It is an open-source 32 bit processor programmable in OpenCL. FGPU is designed to perform General Purpose Computing on GPUs (GPGPU). On a middle-sized Zynq System-On-Chip (SoC), up to 64 Processing Elements (PEs) can be realized at 250MHz. Over a benchmark of 20 applications, the biggest FGPU outperforms a hard ARM Cortex-A9 processor supported with a 128 bit NEON vec- tor engine running at 667MHz by a factor of 4x, on average. FGPU supports single precision floating-point arithmetic in hardware or as emulated instructions in soft- ware. -

Brno University of Technology Demonstration
BRNO UNIVERSITY OF TECHNOLOGY VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND MULTIMEDIA FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ DEMONSTRATION AND BENCHMARKING OF NEXT-GEN GRAPHICS APIS DEMONSTRACE A PROMĚŘENÍ "NEXT-GEN" GRAFICKÝCH API MASTER’S THESIS DIPLOMOVÁ PRÁCE AUTHOR Bc. MATĚJ MAINUŠ AUTOR PRÁCE SUPERVISOR prof. Ing. ADAM HEROUT, Ph.D. VEDOUCÍ PRÁCE BRNO 2016 Abstract The goal of master’s thesis was to demonstrate and benchmark peformance of Mantle and Vulkan APIs with different optimization methods. This thesis proposes a rendering toolkit with optimization methods based on parallel command buffer generating, persistent staging buffers mapping, minimal pipeline configuration and descriptor sets changing, device memory pre-allocating with managing and sharing between multiple resources. The result is reference implementation that could render dynamic scene with thousands of objects in real time. Abstrakt Cílem diplomové práce bylo demonstrovat vlastnosti a změřit výkonost při různých úrovních optimalizace v grafických API Mantle a Vulkan. Navrhuje vykreslovací nástroj s optimal- izacemi založenými na paralelním generování command bufferů, kopírování dat na GPU pomocí perzistentně mapovaných staging bufferů, efektivních změn konfigurace vykreslo- vacího řetězce a descriptor setů, alokaci paměti GPU z předalokovaných stránek se sdílením regionů mezi více zdroji. Výsledkem práce je referenční implementace, která dokáže vykres- lit tisíce samostatných objektů v reálném čase. Keywords Next-Gen graphics API, Vulkan, Mantle, rendering optimization, realtime-rendering, bench- marking Klíčová slova Next-Gen grafické API, Vulkan, Mantle, optimalizace vykreslování, vykreslování v reálném čase, měření výkonu Reference MAINUŠ, Matěj. Demonstration and Benchmarking of Next-Gen Graphics APIs. Brno, 2016. Master’s thesis. -

"RDNA 1.0" Instruction Set Architecture Reference Guide
"RDNA 1.0" Instruction Set Architecture Reference Guide AMD 25-September-2020 Specification Agreement This Specification Agreement (this "Agreement") is a legal agreement between Advanced Micro Devices, Inc. ("AMD") and "You" as the recipient of the attached AMD Specification (the "Specification"). If you are accessing the Specification as part of your performance of work for another party, you acknowledge that you have authority to bind such party to the terms and conditions of this Agreement. If you accessed the Specification by any means or otherwise use or provide Feedback (defined below) on the Specification, You agree to the terms and conditions set forth in this Agreement. If You do not agree to the terms and conditions set forth in this Agreement, you are not licensed to use the Specification; do not use, access or provide Feedback about the Specification. In consideration of Your use or access of the Specification (in whole or in part), the receipt and sufficiency of which are acknowledged, You agree as follows: 1. You may review the Specification only (a) as a reference to assist You in planning and designing Your product, service or technology ("Product") to interface with an AMD product in compliance with the requirements as set forth in the Specification and (b) to provide Feedback about the information disclosed in the Specification to AMD. 2. Except as expressly set forth in Paragraph 1, all rights in and to the Specification are retained by AMD. This Agreement does not give You any rights under any AMD patents, copyrights, trademarks or other intellectual property rights.