DX12 & Vulkan Dawn of a New Generation of Graphics Apis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to the Vulkan Computer Graphics API
1 Introduction to the Vulkan Computer Graphics API Mike Bailey mjb – July 24, 2020 2 Computer Graphics Introduction to the Vulkan Computer Graphics API Mike Bailey [email protected] SIGGRAPH 2020 Abridged Version This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License http://cs.oregonstate.edu/~mjb/vulkan ABRIDGED.pptx mjb – July 24, 2020 3 Course Goals • Give a sense of how Vulkan is different from OpenGL • Show how to do basic drawing in Vulkan • Leave you with working, documented, understandable sample code http://cs.oregonstate.edu/~mjb/vulkan mjb – July 24, 2020 4 Mike Bailey • Professor of Computer Science, Oregon State University • Has been in computer graphics for over 30 years • Has had over 8,000 students in his university classes • [email protected] Welcome! I’m happy to be here. I hope you are too ! http://cs.oregonstate.edu/~mjb/vulkan mjb – July 24, 2020 5 Sections 13.Swap Chain 1. Introduction 14.Push Constants 2. Sample Code 15.Physical Devices 3. Drawing 16.Logical Devices 4. Shaders and SPIR-V 17.Dynamic State Variables 5. Data Buffers 18.Getting Information Back 6. GLFW 19.Compute Shaders 7. GLM 20.Specialization Constants 8. Instancing 21.Synchronization 9. Graphics Pipeline Data Structure 22.Pipeline Barriers 10.Descriptor Sets 23.Multisampling 11.Textures 24.Multipass 12.Queues and Command Buffers 25.Ray Tracing Section titles that have been greyed-out have not been included in the ABRIDGED noteset, i.e., the one that has been made to fit in SIGGRAPH’s reduced time slot. -

Real-Time Finite Element Method (FEM) and Tressfx
REAL-TIME FEM AND TRESSFX 4 ERIC LARSEN KARL HILLESLAND 1 FEBRUARY 2016 | CONFIDENTIAL FINITE ELEMENT METHOD (FEM) SIMULATION Simulates soft to nearly-rigid objects, with fracture Models object as mesh of tetrahedral elements Each element has material parameters: ‒ Young’s Modulus: How stiff the material is ‒ Poisson’s ratio: Effect of deformation on volume ‒ Yield strength: Deformation limit before permanent shape change ‒ Fracture strength: Stress limit before the material breaks 2 FEBRUARY 2016 | CONFIDENTIAL MOTIVATIONS FOR THIS METHOD Parameters give a lot of design control Can model many real-world materials ‒Rubber, metal, glass, wood, animal tissue Commonly used now for film effects ‒High-quality destruction Successful real-time use in Star Wars: The Force Unleashed 1 & 2 ‒DMM middleware [Parker and O’Brien] 3 FEBRUARY 2016 | CONFIDENTIAL OUR PROJECT New implementation of real-time FEM for games Planned CPU library release ‒Heavy use of multithreading ‒Open-source with GPUOpen license Some highlights ‒Practical method for continuous collision detection (CCD) ‒Mix of CCD and intersection contact constraints ‒Efficient integrals for intersection constraint 4 FEBRUARY 2016 | CONFIDENTIAL STATUS Proof-of-concept prototype First pass at optimization Offering an early look for feedback Several generic components 5 FEBRUARY 2016 | CONFIDENTIAL CCD Find time of impact between moving objects ‒Impulses can prevent intersections [Otaduy et al.] ‒Catches collisions with fast-moving objects Our approach ‒Conservative-advancement based ‒Geometric -

AMD Powerpoint- White Template
RDNA Architecture Forward-looking statement This presentation contains forward-looking statements concerning Advanced Micro Devices, Inc. (AMD) including, but not limited to, the features, functionality, performance, availability, timing, pricing, expectations and expected benefits of AMD’s current and future products, which are made pursuant to the Safe Harbor provisions of the Private Securities Litigation Reform Act of 1995. Forward-looking statements are commonly identified by words such as "would," "may," "expects," "believes," "plans," "intends," "projects" and other terms with similar meaning. Investors are cautioned that the forward-looking statements in this presentation are based on current beliefs, assumptions and expectations, speak only as of the date of this presentation and involve risks and uncertainties that could cause actual results to differ materially from current expectations. Such statements are subject to certain known and unknown risks and uncertainties, many of which are difficult to predict and generally beyond AMD's control, that could cause actual results and other future events to differ materially from those expressed in, or implied or projected by, the forward-looking information and statements. Investors are urged to review in detail the risks and uncertainties in AMD's Securities and Exchange Commission filings, including but not limited to AMD's Quarterly Report on Form 10-Q for the quarter ended March 30, 2019 2 Highlights of the RDNA Workgroup Processor (WGP) ▪ Designed for lower latency and higher -

Amd Filed: February 24, 2009 (Period: December 27, 2008)
FORM 10-K ADVANCED MICRO DEVICES INC - amd Filed: February 24, 2009 (period: December 27, 2008) Annual report which provides a comprehensive overview of the company for the past year Table of Contents 10-K - FORM 10-K PART I ITEM 1. 1 PART I ITEM 1. BUSINESS ITEM 1A. RISK FACTORS ITEM 1B. UNRESOLVED STAFF COMMENTS ITEM 2. PROPERTIES ITEM 3. LEGAL PROCEEDINGS ITEM 4. SUBMISSION OF MATTERS TO A VOTE OF SECURITY HOLDERS PART II ITEM 5. MARKET FOR REGISTRANT S COMMON EQUITY, RELATED STOCKHOLDER MATTERS AND ISSUER PURCHASES OF EQUITY SECURITIES ITEM 6. SELECTED FINANCIAL DATA ITEM 7. MANAGEMENT S DISCUSSION AND ANALYSIS OF FINANCIAL CONDITION AND RESULTS OF OPERATIONS ITEM 7A. QUANTITATIVE AND QUALITATIVE DISCLOSURE ABOUT MARKET RISK ITEM 8. FINANCIAL STATEMENTS AND SUPPLEMENTARY DATA ITEM 9. CHANGES IN AND DISAGREEMENTS WITH ACCOUNTANTS ON ACCOUNTING AND FINANCIAL DISCLOSURE ITEM 9A. CONTROLS AND PROCEDURES ITEM 9B. OTHER INFORMATION PART III ITEM 10. DIRECTORS, EXECUTIVE OFFICERS AND CORPORATE GOVERNANCE ITEM 11. EXECUTIVE COMPENSATION ITEM 12. SECURITY OWNERSHIP OF CERTAIN BENEFICIAL OWNERS AND MANAGEMENT AND RELATED STOCKHOLDER MATTERS ITEM 13. CERTAIN RELATIONSHIPS AND RELATED TRANSACTIONS AND DIRECTOR INDEPENDENCE ITEM 14. PRINCIPAL ACCOUNTANT FEES AND SERVICES PART IV ITEM 15. EXHIBITS, FINANCIAL STATEMENT SCHEDULES SIGNATURES EX-10.5(A) (OUTSIDE DIRECTOR EQUITY COMPENSATION POLICY) EX-10.19 (SEPARATION AGREEMENT AND GENERAL RELEASE) EX-21 (LIST OF AMD SUBSIDIARIES) EX-23.A (CONSENT OF ERNST YOUNG LLP - ADVANCED MICRO DEVICES) EX-23.B -

Candidate Features for Future Opengl 5 / Direct3d 12 Hardware and Beyond 3 May 2014, Christophe Riccio
Candidate features for future OpenGL 5 / Direct3D 12 hardware and beyond 3 May 2014, Christophe Riccio G-Truc Creation Table of contents TABLE OF CONTENTS 2 INTRODUCTION 4 1. DRAW SUBMISSION 6 1.1. GL_ARB_MULTI_DRAW_INDIRECT 6 1.2. GL_ARB_SHADER_DRAW_PARAMETERS 7 1.3. GL_ARB_INDIRECT_PARAMETERS 8 1.4. A SHADER CODE PATH PER DRAW IN A MULTI DRAW 8 1.5. SHADER INDEXED LOSE STATES 9 1.6. GL_NV_BINDLESS_MULTI_DRAW_INDIRECT 10 1.7. GL_AMD_INTERLEAVED_ELEMENTS 10 2. RESOURCES 11 2.1. GL_ARB_BINDLESS_TEXTURE 11 2.2. GL_NV_SHADER_BUFFER_LOAD AND GL_NV_SHADER_BUFFER_STORE 11 2.3. GL_ARB_SPARSE_TEXTURE 12 2.4. GL_AMD_SPARSE_TEXTURE 12 2.5. GL_AMD_SPARSE_TEXTURE_POOL 13 2.6. SEAMLESS TEXTURE STITCHING 13 2.7. 3D MEMORY LAYOUT FOR SPARSE 3D TEXTURES 13 2.8. SPARSE BUFFER 14 2.9. GL_KHR_TEXTURE_COMPRESSION_ASTC 14 2.10. GL_INTEL_MAP_TEXTURE 14 2.11. GL_ARB_SEAMLESS_CUBEMAP_PER_TEXTURE 15 2.12. DMA ENGINES 15 2.13. UNIFIED MEMORY 16 3. SHADER OPERATIONS 17 3.1. GL_ARB_SHADER_GROUP_VOTE 17 3.2. GL_NV_SHADER_THREAD_GROUP 17 3.3. GL_NV_SHADER_THREAD_SHUFFLE 17 3.4. GL_NV_SHADER_ATOMIC_FLOAT 18 3.5. GL_AMD_SHADER_ATOMIC_COUNTER_OPS 18 3.6. GL_ARB_COMPUTE_VARIABLE_GROUP_SIZE 18 3.7. MULTI COMPUTE DISPATCH 19 3.8. GL_NV_GPU_SHADER5 19 3.9. GL_AMD_GPU_SHADER_INT64 20 3.10. GL_AMD_GCN_SHADER 20 3.11. GL_NV_VERTEX_ATTRIB_INTEGER_64BIT 21 3.12. GL_AMD_ SHADER_TRINARY_MINMAX 21 4. FRAMEBUFFER 22 4.1. GL_AMD_SAMPLE_POSITIONS 22 4.2. GL_EXT_FRAMEBUFFER_MULTISAMPLE_BLIT_SCALED 22 4.3. GL_NV_MULTISAMPLE_COVERAGE AND GL_NV_FRAMEBUFFER_MULTISAMPLE_COVERAGE 22 4.4. GL_AMD_DEPTH_CLAMP_SEPARATE 22 5. BLENDING 23 5.1. GL_NV_TEXTURE_BARRIER 23 5.2. GL_EXT_SHADER_FRAMEBUFFER_FETCH (OPENGL ES) 23 5.3. GL_ARM_SHADER_FRAMEBUFFER_FETCH (OPENGL ES) 23 5.4. GL_ARM_SHADER_FRAMEBUFFER_FETCH_DEPTH_STENCIL (OPENGL ES) 23 5.5. GL_EXT_PIXEL_LOCAL_STORAGE (OPENGL ES) 24 5.6. TILE SHADING 25 5.7. GL_INTEL_FRAGMENT_SHADER_ORDERING 26 5.8. GL_KHR_BLEND_EQUATION_ADVANCED 26 5.9. -

AMD Firepro™ W5000
AMD FirePro™ W5000 Be Limitless, When Every Detail Counts. Powerful mid-range workstation graphics. This powerful product, designed for delivering superior performance for CAD/CAE and Media workflows, can process Key Features: up to 1.65 billion triangles per second. This means during > Utilizes Graphics Core Next (GCN) to the design process you can easily interact and render efficiently balance compute tasks with your 3D models, while the competition can only process 3D workloads, enabling multi-tasking that is designed to optimize utilization up to 0.41 billion triangles per second (up to four times and maximize performance. less performance). It also offers double the memory > Unmatched application of competing products (2GB vs. 1GB) and 2.5x responsiveness in your workflow, the memory bandwidth. It’s the ideal solution whether in advanced visualization, for professionals working with a broad range of complex models, large data sets or applications, moderately complex models and datasets, video editing. and advanced visual effects. > AMD ZeroCore Power Technology enables your GPU to power down when your monitor is off. Product features: > AMD ZeroCore Power technology leverages > GeometryBoost—the GPU processes > Optimized and certified for major CAD and M&E AMD’s leadership in notebook power efficiency geometry data at a rate of twice per clock cycle, doubling the rate of primitive applications delivering 1 TFLOP of single precision and 80 to enable our desktop GPUs to power down and vertex processing. GFLOPs of double precision performance with when your monitor is off, also known as the > AMD Eyefinity Technology— outstanding reliability for the most demanding “long idle state.” Industry-leading multi-display professional tasks. -

AMD Firepro™Professional Graphics for CAD & Engineering and Media & Entertainment
AMD FirePro™Professional Graphics for CAD & Engineering and Media & Entertainment Performance at every price point. AMD FirePro professional graphics offer breakthrough capabilities that can help maximize productivity and help lower cost and complexity — giving you the edge you need in your business. Outstanding graphics performance, compute power and ultrahigh-resolution multidisplay capabilities allows broadcast, design and engineering professionals to work at a whole new level of detail, speed, responsiveness and creativity. AMD FireProTM W9100 AMD FireProTM W8100 With 16GB GDDR5 memory and the ability to support up to six 4K The new AMD FirePro W8100 workstation graphics card is based on displays via six Mini DisplayPort outputs,1 the AMD FirePro W9100 the AMD Graphics Core Next (GCN) GPU architecture and packs up graphics card is the ideal single-GPU solution for the next generation to 4.2 TFLOPS of compute power to accelerate your projects beyond of ultrahigh-resolution visualization environments. just graphics. AMD FireProTM W7100 AMD FireProTM W5100 The new AMD FirePro W7100 graphics card delivers 8GB The new AMD FirePro™ W5100 graphics card delivers optimized of memory, application performance and special features application and multidisplay performance for midrange users. that media and entertainment and design and engineering With 4GB of ultra-fast GDDR5 memory, users can tackle moderately professionals need to take their projects to the next level. complex models, assemblies, data sets or advanced visual effects with ease. AMD FireProTM W4100 AMD FireProTM W2100 In a class of its own, the AMD FirePro Professional graphics starts with AMD W4100 graphics card is the best choice FirePro W2100 graphics, delivering for entry-level users who need a boost in optimized and certified professional graphics performance to better address application performance that similarly- their evolving workflows. -

Standards for Vision Processing and Neural Networks
Standards for Vision Processing and Neural Networks Radhakrishna Giduthuri, AMD [email protected] © Copyright Khronos Group 2017 - Page 1 Agenda • Why we need a standard? • Khronos NNEF • Khronos OpenVX dog Network Architecture Pre-trained Network Model (weights, …) © Copyright Khronos Group 2017 - Page 2 Neural Network End-to-End Workflow Neural Network Third Vision/AI Party Applications Training Frameworks Tools Datasets Trained Vision and Neural Network Network Inferencing Runtime Network Model Architecture Desktop and Cloud Hardware Embedded/Mobile Embedded/MobileEmbedded/Mobile Embedded/Mobile/Desktop/CloudVision/InferencingVision/Inferencing Hardware Hardware cuDNN MIOpen MKL-DNN Vision/InferencingVision/Inferencing Hardware Hardware GPU DSP CPU Custom FPGA © Copyright Khronos Group 2017 - Page 3 Problem: Neural Network Fragmentation Neural Network Training and Inferencing Fragmentation NN Authoring Framework 1 Inference Engine 1 NN Authoring Framework 2 Inference Engine 2 NN Authoring Framework 3 Inference Engine 3 Every Tool Needs an Exporter to Every Accelerator Neural Network Inferencing Fragmentation toll on Applications Inference Engine 1 Hardware 1 Vision/AI Inference Engine 2 Hardware 2 Application Inference Engine 3 Hardware 3 Every Application Needs know about Every Accelerator API © Copyright Khronos Group 2017 - Page 4 Khronos APIs Connect Software to Silicon Software Silicon Khronos is an International Industry Consortium of over 100 companies creating royalty-free, open standard APIs to enable software to access -

Comparison of Technologies for General-Purpose Computing on Graphics Processing Units
Master of Science Thesis in Information Coding Department of Electrical Engineering, Linköping University, 2016 Comparison of Technologies for General-Purpose Computing on Graphics Processing Units Torbjörn Sörman Master of Science Thesis in Information Coding Comparison of Technologies for General-Purpose Computing on Graphics Processing Units Torbjörn Sörman LiTH-ISY-EX–16/4923–SE Supervisor: Robert Forchheimer isy, Linköpings universitet Åsa Detterfelt MindRoad AB Examiner: Ingemar Ragnemalm isy, Linköpings universitet Organisatorisk avdelning Department of Electrical Engineering Linköping University SE-581 83 Linköping, Sweden Copyright © 2016 Torbjörn Sörman Abstract The computational capacity of graphics cards for general-purpose computing have progressed fast over the last decade. A major reason is computational heavy computer games, where standard of performance and high quality graphics con- stantly rise. Another reason is better suitable technologies for programming the graphics cards. Combined, the product is high raw performance devices and means to access that performance. This thesis investigates some of the current technologies for general-purpose computing on graphics processing units. Tech- nologies are primarily compared by means of benchmarking performance and secondarily by factors concerning programming and implementation. The choice of technology can have a large impact on performance. The benchmark applica- tion found the difference in execution time of the fastest technology, CUDA, com- pared to the slowest, OpenCL, to be twice a factor of two. The benchmark applica- tion also found out that the older technologies, OpenGL and DirectX, are compet- itive with CUDA and OpenCL in terms of resulting raw performance. iii Acknowledgments I would like to thank Åsa Detterfelt for the opportunity to make this thesis work at MindRoad AB. -

The Amd Linux Graphics Stack – 2018 Edition Nicolai Hähnle Fosdem 2018
THE AMD LINUX GRAPHICS STACK – 2018 EDITION NICOLAI HÄHNLE FOSDEM 2018 1FEBRUARY 2018 | CONFIDENTIAL GRAPHICS STACK: KERNEL / USER-SPACE / X SERVER Mesa OpenGL & Multimedia Vulkan Vulkan radv AMDVLK OpenGL X Server radeonsi Pro/ r600 Workstation radeon amdgpu LLVM SCPC libdrm radeon amdgpu FEBRUARY 2018 | AMD LINUX GRAPHICS STACK 2FEBRUARY 2018 | CONFIDENTIAL GRAPHICS STACK: OPEN-SOURCE / CLOSED-SOURCE Mesa OpenGL & Multimedia Vulkan Vulkan radv AMDVLK OpenGL X Server radeonsi Pro/ r600 Workstation radeon amdgpu LLVM SCPC libdrm radeon amdgpu FEBRUARY 2018 | AMD LINUX GRAPHICS STACK 3FEBRUARY 2018 | CONFIDENTIAL GRAPHICS STACK: SUPPORT FOR GCN / PRE-GCN HARDWARE ROUGHLY: GCN = NEW GPUS OF THE LAST 5 YEARS Mesa OpenGL & Multimedia Vulkan Vulkan radv AMDVLK OpenGL X Server radeonsi Pro/ r600 Workstation radeon amdgpu LLVM(*) SCPC libdrm radeon amdgpu (*) LLVM has pre-GCN support only for compute FEBRUARY 2018 | AMD LINUX GRAPHICS STACK 4FEBRUARY 2018 | CONFIDENTIAL GRAPHICS STACK: PHASING OUT “LEGACY” COMPONENTS Mesa OpenGL & Multimedia Vulkan Vulkan radv AMDVLK OpenGL X Server radeonsi Pro/ r600 Workstation radeon amdgpu LLVM SCPC libdrm radeon amdgpu FEBRUARY 2018 | AMD LINUX GRAPHICS STACK 5FEBRUARY 2018 | CONFIDENTIAL MAJOR MILESTONES OF 2017 . Upstreaming the DC display driver . Open-sourcing the AMDVLK Vulkan driver . Unified driver delivery . OpenGL 4.5 conformance in the open-source Mesa driver . Zero-day open-source support for new hardware FEBRUARY 2018 | AMD LINUX GRAPHICS STACK 6FEBRUARY 2018 | CONFIDENTIAL KERNEL: AMDGPU AND RADEON HARDWARE SUPPORT Pre-GCN radeon GCN 1st gen (Southern Islands, SI, gfx6) GCN 2nd gen (Sea Islands, CI(K), gfx7) GCN 3rd gen (Volcanic Islands, VI, gfx8) amdgpu GCN 4th gen (Polaris, RX 4xx, RX 5xx) GCN 5th gen (RX Vega, Ryzen Mobile, gfx9) FEBRUARY 2018 | AMD LINUX GRAPHICS STACK 7FEBRUARY 2018 | CONFIDENTIAL KERNEL: AMDGPU VS. -
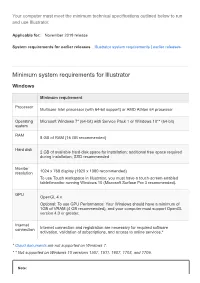
Minimum System Requirements for Illustrator
Your computer must meet the minimum technical specifications outlined below to run and use Illustrator. Applicable for: November 2019 release System requirements for earlier releases Illustrator system requirements | earlier releases Minimum system requirements for Illustrator Windows Minimum requirement Processor Multicore Intel processor (with 64-bit support) or AMD Athlon 64 processor Operating Microsoft Windows 7* (64-bit) with Service Pack 1 or Windows 10** (64-bit) system RAM 8 GB of RAM (16 GB recommended) Hard disk 2 GB of available hard-disk space for installation; additional free space required during installation; SSD recommended Monitor resolution 1024 x 768 display (1920 x 1080 recommended) To use Touch workspace in Illustrator, you must have a touch-screen-enabled tablet/monitor running Windows 10 (Microsoft Surface Pro 3 recommended). GPU OpenGL 4.x Optional: To use GPU Performance: Your Windows should have a minimum of 1GB of VRAM (4 GB recommended), and your computer must support OpenGL version 4.0 or greater. Internet connection Internet connection and registration are necessary for required software activation, validation of subscriptions, and access to online services.* * Cloud documents are not supported on Windows 7. * * Not supported on Windows 10 versions 1507, 1511, 1607, 1703, and 1709. Note: Scalable UI feature is supported on Windows 10 (minimum resolution supported is 1920 x 1080). Auto handle feature is supported on Windows 10. GPU in Outline mode is supported on monitor with display resolution at least 2000 pixels in any dimension. Supported video adapter The following video adapter series support the new Windows GPU Performance features in Illustrator: NVIDIA NVIDIA Quadro K Series NVIDIA Quadro 6xxx NVIDIA Quadro 5xxx NVIDIA Quadro 4xxx NVIDIA Quadro 2xxx NVIDIA Quadro 2xxxD NVIDIA Quadro 6xx NVIDIA GeForce GTX Series (4xx, 5xx, 6xx, 7xx, 9xx, Titan) NVIDIA Quadro M Series NVIDIA Quadro P Series NVIDIA Quadro RTX 4000 Important: Microsoft Windows may not detect the availability of the latest device drivers for NVIDIA GPU cards. -

Khronos Template 2015
Ecosystem Overview Neil Trevett | Khronos President NVIDIA Vice President Developer Ecosystem [email protected] | @neilt3d © Copyright Khronos Group 2016 - Page 1 Khronos Mission Software Silicon Khronos is an Industry Consortium of over 100 companies creating royalty-free, open standard APIs to enable software to access hardware acceleration for graphics, parallel compute and vision © Copyright Khronos Group 2016 - Page 2 http://accelerateyourworld.org/ © Copyright Khronos Group 2016 - Page 3 Vision Pipeline Challenges and Opportunities Growing Camera Diversity Diverse Vision Processors Sensor Proliferation 22 Flexible sensor and camera Use efficient acceleration to Combine vision output control to GENERATE PROCESS with other sensor data an image stream the image stream on device © Copyright Khronos Group 2016 - Page 4 OpenVX – Low Power Vision Acceleration • Higher level abstraction API - Targeted at real-time mobile and embedded platforms • Performance portability across diverse architectures - Multi-core CPUs, GPUs, DSPs and DSP arrays, ISPs, Dedicated hardware… • Extends portable vision acceleration to very low power domains - Doesn’t require high-power CPU/GPU Complex - Lower precision requirements than OpenCL - Low-power host can setup and manage frame-rate graph Vision Engine Middleware Application X100 Dedicated Vision Processing Hardware Efficiency Vision DSPs X10 GPU Compute Accelerator Multi-core Accelerator Power Efficiency Power X1 CPU Accelerator Computation Flexibility © Copyright Khronos Group 2016 - Page 5 OpenVX Graphs