Gpgpus and Their Programming
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GPU Architecture • Display Controller • Designing for Safety • Vision Processing
i.MX 8 GRAPHICS ARCHITECTURE FTF-DES-N1940 RAFAL MALEWSKI HEAD OF GRAPHICS TECH ENGINEERING CENTER MAY 18, 2016 PUBLIC USE AGENDA • i.MX 8 Series Scalability • GPU Architecture • Display Controller • Designing for Safety • Vision Processing 1 PUBLIC USE #NXPFTF 1 PUBLIC USE #NXPFTF i.MX is… 2 PUBLIC USE #NXPFTF SoC Scalability = Investment Re-Use Replace the Chip a Increase capability. (Pin, Software, IP compatibility among parts) 3 PUBLIC USE #NXPFTF i.MX 8 Series GPU Cores • Dual Core GPU Up to 4 displays Accelerated ARM Cores • 16 Vec4 Shaders Vision Cortex-A53 | Cortex-A72 8 • Up to 128 GFLOPS • 64 execution units 8QuadMax 8 • Tessellation/Geometry total pixels Shaders Pin Compatibility Pin • Dual Core GPU Up to 4 displays Accelerated • 8 Vec4 Shaders Vision 4 • Up to 64 GFLOPS • 32 execution units 4 total pixels 8QuadPlus • Tessellation/Geometry Compatibility Software Shaders • Dual Core GPU Up to 4 displays Accelerated • 8 Vec4 Shaders Vision 4 • Up to 64 GFLOPS 4 • 32 execution units 8Quad • Tessellation/Geometry total pixels Shaders • Single Core GPU Up to 2 displays Accelerated • 8 Vec4 Shaders 2x 1080p total Vision • Up to 64 GFLOPS pixels Compatibility Pin 8 • 32 execution units 8Dual8Solo • Tessellation/Geometry Shaders • Single Core GPU Up to 2 displays Accelerated • 4 Vec4 Shaders 2x 1080p total Vision • Up to 32 GFLOPS pixels 4 • 16 execution units 8DualLite8Solo • Tessellation/Geometry Shaders 4 PUBLIC USE #NXPFTF i.MX 8 Series – The Doubles GPU Cores • Dual Core GPU Up to 4 displays Accelerated • 16 Vec4 Shaders Vision -
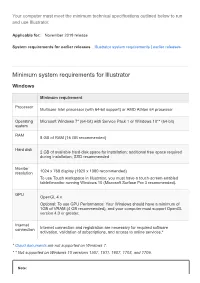
Minimum System Requirements for Illustrator
Your computer must meet the minimum technical specifications outlined below to run and use Illustrator. Applicable for: November 2019 release System requirements for earlier releases Illustrator system requirements | earlier releases Minimum system requirements for Illustrator Windows Minimum requirement Processor Multicore Intel processor (with 64-bit support) or AMD Athlon 64 processor Operating Microsoft Windows 7* (64-bit) with Service Pack 1 or Windows 10** (64-bit) system RAM 8 GB of RAM (16 GB recommended) Hard disk 2 GB of available hard-disk space for installation; additional free space required during installation; SSD recommended Monitor resolution 1024 x 768 display (1920 x 1080 recommended) To use Touch workspace in Illustrator, you must have a touch-screen-enabled tablet/monitor running Windows 10 (Microsoft Surface Pro 3 recommended). GPU OpenGL 4.x Optional: To use GPU Performance: Your Windows should have a minimum of 1GB of VRAM (4 GB recommended), and your computer must support OpenGL version 4.0 or greater. Internet connection Internet connection and registration are necessary for required software activation, validation of subscriptions, and access to online services.* * Cloud documents are not supported on Windows 7. * * Not supported on Windows 10 versions 1507, 1511, 1607, 1703, and 1709. Note: Scalable UI feature is supported on Windows 10 (minimum resolution supported is 1920 x 1080). Auto handle feature is supported on Windows 10. GPU in Outline mode is supported on monitor with display resolution at least 2000 pixels in any dimension. Supported video adapter The following video adapter series support the new Windows GPU Performance features in Illustrator: NVIDIA NVIDIA Quadro K Series NVIDIA Quadro 6xxx NVIDIA Quadro 5xxx NVIDIA Quadro 4xxx NVIDIA Quadro 2xxx NVIDIA Quadro 2xxxD NVIDIA Quadro 6xx NVIDIA GeForce GTX Series (4xx, 5xx, 6xx, 7xx, 9xx, Titan) NVIDIA Quadro M Series NVIDIA Quadro P Series NVIDIA Quadro RTX 4000 Important: Microsoft Windows may not detect the availability of the latest device drivers for NVIDIA GPU cards. -

Directx and GPU (Nvidia-Centric) History Why
10/12/09 DirectX and GPU (Nvidia-centric) History DirectX 6 DirectX 7! ! DirectX 8! DirectX 9! DirectX 9.0c! Multitexturing! T&L ! SM 1.x! SM 2.0! SM 3.0! DirectX 5! Riva TNT GeForce 256 ! ! GeForce3! GeForceFX! GeForce 6! Riva 128! (NV4) (NV10) (NV20) Cg! (NV30) (NV40) XNA and Programmable Shaders DirectX 2! 1996! 1998! 1999! 2000! 2001! 2002! 2003! 2004! DirectX 10! Prof. Hsien-Hsin Sean Lee SM 4.0! GTX200 NVidia’s Unified Shader Model! Dualx1.4 billion GeForce 8 School of Electrical and Computer 3dfx’s response 3dfx demise ! Transistors first to Voodoo2 (G80) ~1.2GHz Engineering Voodoo chip GeForce 9! Georgia Institute of Technology 2006! 2008! GT 200 2009! ! GT 300! Adapted from David Kirk’s slide Why Programmable Shaders Evolution of Graphics Processing Units • Hardwired pipeline • Pre-GPU – Video controller – Produces limited effects – Dumb frame buffer – Effects look the same • First generation GPU – PCI bus – Gamers want unique look-n-feel – Rasterization done on GPU – Multi-texturing somewhat alleviates this, but not enough – ATI Rage, Nvidia TNT2, 3dfx Voodoo3 (‘96) • Second generation GPU – Less interoperable, less portable – AGP – Include T&L into GPU (D3D 7.0) • Programmable Shaders – Nvidia GeForce 256 (NV10), ATI Radeon 7500, S3 Savage3D (’98) – Vertex Shader • Third generation GPU – Programmable vertex and fragment shaders (D3D 8.0, SM1.0) – Pixel or Fragment Shader – Nvidia GeForce3, ATI Radeon 8500, Microsoft Xbox (’01) – Starting from DX 8.0 (assembly) • Fourth generation GPU – Programmable vertex and fragment shaders -

MSI Afterburner V4.6.4
MSI Afterburner v4.6.4 MSI Afterburner is ultimate graphics card utility, co-developed by MSI and RivaTuner teams. Please visit https://msi.com/page/afterburner to get more information about the product and download new versions SYSTEM REQUIREMENTS: ...................................................................................................................................... 3 FEATURES: ............................................................................................................................................................. 3 KNOWN LIMITATIONS:........................................................................................................................................... 4 REVISION HISTORY: ................................................................................................................................................ 5 VERSION 4.6.4 .............................................................................................................................................................. 5 VERSION 4.6.3 (PUBLISHED ON 03.03.2021) .................................................................................................................... 5 VERSION 4.6.2 (PUBLISHED ON 29.10.2019) .................................................................................................................... 6 VERSION 4.6.1 (PUBLISHED ON 21.04.2019) .................................................................................................................... 7 VERSION 4.6.0 (PUBLISHED ON -

Amd Driver 17.11.2 Download DRIVER RADEON V17.11.2 for WINDOWS 7 DOWNLOAD
amd driver 17.11.2 download DRIVER RADEON V17.11.2 FOR WINDOWS 7 DOWNLOAD. The headline changes to switch optimization between graphics support for free. Rx vega radeon setting enhanced sync - amd rx vega radeon relive. 330 free download the release notes for free. Show me where to locate my serial number or snid on my device. The system might tells you it is not supported but do not mind that. Issues with access violations, Community. Gpu workload, a new toggle in radeon settings that can be found under the gaming, global settings options. Power supply power to manually requires some computer hardware. Amd for radeon products such as 17. Windows operating systems only or select your device. This package includes laptop and patience. Ethereum + OpenCL Benchmarks With The Latest AMDGPU-PRO. This toggle will allow you to switch optimization between graphics or compute workloads on select radeon rx 500, radeon rx 400, radeon r9 390, radeon r9 380, radeon r9 290 and radeon r9 285 series graphics products. The radeon software adrenalin 2020 edition 20.3.1 configuration scored an average of 139.1 fps, while the 20.2.2 edition configuration scored an average of 133.1 fps, showing an 5% uplift driver over driver. Download new and previously released drivers including support software, bios, utilities, firmware and patches for intel products. The amd product verification tool, donlot driver number of. Download latest reply on this page. A4-6300 apu with the samsung devices. This is a number for mac. Downloaded 5193 times, i was created, and 11. -

Full Edition 1
WAKE FOREST JOURNAL OF BUSINESS AND INTELLECTUAL PROPERTY LAW VOLUME 14 NUMBER 1 FALL 2013 AN EXAMINATION OF BASEL III AND THE NEW U.S. BANKING REGULATIONS Andrew L. McElroy .................................................................. 5 HOW TO KILL COPYRIGHT: A BRUTE-FORCE APPROACH TO CONTENT CREATION Kirk Sigmon ........................................................................... 26 THE MIXED USE OF A PERSONAL RESIDENCE: INTEGRATION OF CONFLICTING HOLDING PURPOSES UNDER I.R.C. SECTIONS 121, 280A, AND 1031 Christine Manolakas ............................................................... 62 OPEN SOURCE MODELS IN BIOMEDICINE: WORKABLE COMPLEMENTARY FLEXIBILITIES WITHIN THE PATENT SYSTEM? Aura Bertoni ......................................................................... 126 PRIVATE FAIR USE: STRENGTHENING POLISH COPYRIGHT PROTECTION OF ONLINE WORKS BY LOOKING TO U.S. COPYRIGHT LAW Michał Pękała ....................................................................... 166 THE DMCA’S SAFE HARBOR PROVISION: IS IT REALLY KEEPING THE PIRATES AT BAY? Charles K. Lane .................................................................... 192 PERMISSIBLE ERROR?: WHY THE NINTH CIRCUIT’S INCORRECT APPLICATION OF THE DMCA IN MDY INDUSTRIES, LLC V. BLIZZARD ENTERTAINMENT, INC. REACHES THE CORRECT RESULT James Harrell ........................................................................ 211 ABOUT THE JOURNAL The WAKE FOREST JOURNAL OF BUSINESS AND INTELLECTUAL PROPERTY LAW is a student organization sponsored by Wake Forest University -

Graphics Shaders Mike Hergaarden January 2011, VU Amsterdam
Graphics shaders Mike Hergaarden January 2011, VU Amsterdam [Source: http://unity3d.com/support/documentation/Manual/Materials.html] Abstract Shaders are the key to finalizing any image rendering, be it computer games, images or movies. Shaders have greatly improved the output of computer generated media; from photo-realistic computer generated humans to more vivid cartoon movies. Furthermore shaders paved the way to general-purpose computation on GPU (GPGPU). This paper introduces shaders by discussing the theory and practice. Introduction A shader is a piece of code that is executed on the Graphics Processing Unit (GPU), usually found on a graphics card, to manipulate an image before it is drawn to the screen. Shaders allow for various kinds of rendering effect, ranging from adding an X-Ray view to adding cartoony outlines to rendering output. The history of shaders starts at LucasFilm in the early 1980’s. LucasFilm hired graphics programmers to computerize the special effects industry [1]. This proved a success for the film/ rendering industry, especially at Pixars Toy Story movie launch in 1995. RenderMan introduced the notion of Shaders; “The Renderman Shading Language allows material definitions of surfaces to be described in not only a simple manner, but also highly complex and custom manner using a C like language. Using this method as opposed to a pre-defined set of materials allows for complex procedural textures, new shading models and programmable lighting. Another thing that sets the renderers based on the RISpec apart from many other renderers, is the ability to output arbitrary variables as an image—surface normals, separate lighting passes and pretty much anything else can be output from the renderer in one pass.” [1] The term shader was first only used to refer to “pixel shaders”, but soon enough new uses of shaders such as vertex and geometry shaders were introduced, making the term shaders more general. -

SAPPHIRE R9 285 2GB GDDR5 ITX COMPACT OC Edition (UEFI)
Specification Display Support 4 x Maximum Display Monitor(s) support 1 x HDMI (with 3D) Output 2 x Mini-DisplayPort 1 x Dual-Link DVI-I 928 MHz Core Clock GPU 28 nm Chip 1792 x Stream Processors 2048 MB Size Video Memory 256 -bit GDDR5 5500 MHz Effective 171(L)X110(W)X35(H) mm Size. Dimension 2 x slot Driver CD Software SAPPHIRE TriXX Utility DVI to VGA Adapter Mini-DP to DP Cable Accessory HDMI 1.4a high speed 1.8 meter cable(Full Retail SKU only) 1 x 8 Pin to 6 Pin x2 Power adaptor Overview HDMI (with 3D) Support for Deep Color, 7.1 High Bitrate Audio, and 3D Stereoscopic, ensuring the highest quality Blu-ray and video experience possible from your PC. Mini-DisplayPort Enjoy the benefits of the latest generation display interface, DisplayPort. With the ultra high HD resolution, the graphics card ensures that you are able to support the latest generation of LCD monitors. Dual-Link DVI-I Equipped with the most popular Dual Link DVI (Digital Visual Interface), this card is able to display ultra high resolutions of up to 2560 x 1600 at 60Hz. Advanced GDDR5 Memory Technology GDDR5 memory provides twice the bandwidth per pin of GDDR3 memory, delivering more speed and higher bandwidth. Advanced GDDR5 Memory Technology GDDR5 memory provides twice the bandwidth per pin of GDDR3 memory, delivering more speed and higher bandwidth. AMD Stream Technology Accelerate the most demanding applications with AMD Stream technology and do more with your PC. AMD Stream Technology allows you to use the teraflops of compute power locked up in your graphics processer on tasks other than traditional graphics such as video encoding, at which the graphics processor is many, many times faster than using the CPU alone. -

CPU-GPU Benchmark Description
UC San Diego UC San Diego Electronic Theses and Dissertations Title Heterogeneity and Density Aware Design of Computing Systems Permalink https://escholarship.org/uc/item/9qd6w8cw Author Arora, Manish Publication Date 2018 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO Heterogeneity and Density Aware Design of Computing Systems A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Computer Science (Computer Engineering) by Manish Arora Committee in charge: Professor Dean M. Tullsen, Chair Professor Renkun Chen Professor George Porter Professor Tajana Simunic Rosing Professor Steve Swanson 2018 Copyright Manish Arora, 2018 All rights reserved. The dissertation of Manish Arora is approved, and it is ac- ceptable in quality and form for publication on microfilm and electronically: Chair University of California, San Diego 2018 iii DEDICATION To my family and friends. iv EPIGRAPH Do not be embarrassed by your failures, learn from them and start again. —Richard Branson If something’s important enough, you should try. Even if the probable outcome is failure. —Elon Musk v TABLE OF CONTENTS Signature Page . iii Dedication . iv Epigraph . v Table of Contents . vi List of Figures . viii List of Tables . x Acknowledgements . xi Vita . xiii Abstract of the Dissertation . xvi Chapter 1 Introduction . 1 1.1 Design for Heterogeneity . 2 1.1.1 Heterogeneity Aware Design . 3 1.2 Design for Density . 6 1.2.1 Density Aware Design . 7 1.3 Overview of Dissertation . 8 Chapter 2 Background . 10 2.1 GPGPU Computing . 10 2.2 CPU-GPU Systems . -

Model System of Zirconium Oxide An
First-principles based treatment of charged species equilibria at electrochemical interfaces: model system of zirconium oxide and titanium oxide by Jing Yang B.S., Physics, Peking University, China Submitted to the Department of Materials Science and Engineering in partial fulfillment of the requirements for the degree of Doctor of Philosophy at the MASSACHUSETTS INSTITUTE OF TECHONOLOGY February 2020 © Massachusetts Institute of Technology 2020. All rights reserved. Signature of Author: Jing Yang Department of Materials Science and Engineering January 10th, 2020 Certified by: Bilge Yildiz Professor of Materials Science and Engineering And Professor of Nuclear Science and Engineering Thesis Supervisor Accepted by: Donald R. Sadoway John F. Elliott Professor of Materials Chemistry Chair, Department Committee on Graduate Studies 2 First-principles based treatment of charged species equilibria at electrochemical interfaces: model system of zirconium oxide and titanium oxide by Jing Yang Submitted to the Department of Materials Science and Engineering on Jan. 10th, 2020 in partial fulfillment of the requirements for the degree of Doctor of Philosophy Abstract Ionic defects are known to influence the magnetic, electronic and transport properties of oxide materials. Understanding defect chemistry provides guidelines for defect engineering in various applications including energy storage and conversion, corrosion, and neuromorphic computing devices. While DFT calculations have been proven as a powerful tool for modeling point defects in bulk oxide materials, challenges remain for linking atomistic results with experimentally-measurable materials properties, where impurities and complicated microstructures exist and the materials deviate from ideal bulk behavior. This thesis aims to bridge this gap on two aspects. First, we study the coupled electro-chemo-mechanical effects of ionic impurities in bulk oxide materials. -

AMD Catalyst™ Software Suite Version 12.3 Release Notes
Page 1 of 4 AMD Catalyst™ Software Suite Version 12.3 • Back Release Notes Last Updated 3/28/2012 Article Number 158 This article provides information on the latest posting of AMD’s software suite, AMD Catalyst™12.3. This particular software suite updates the AMD display driver and the AMD Catalyst Control Center/ AMD Vision Engine Control Center. This unified driver has been updated to provide enhanced level of power, performance, and reliability. Package Content The AMD Catalyst software suite 12.3 contains the following: • AMD display driver version 8.951 • HydraVision™ for Windows Vista ® and Windows ® 7 • Southbridge/IXP Driver • AMD Catalyst Control Center version 8.951 / AMD Vision Engine Control Center version 8.951 Important! Caution! • The AMD Catalyst Control Center/ AMD Vision Engine Control Center requires that the Microsoft® .NET Framework SP1 be installed for Windows XP and Windows Vista. Without .NET SP1 installed, the AMD Catalyst Control Center / AMD Vision Engine Control Center will not launch properly and the user will see an error message. Notes. • When installing the AMD Catalyst driver for Windows operating system, the user must be logged on as Administrator or have Administrator rights to complete the installation of the AMD Catalyst driver. • The Catalyst driver requires Windows 7 Service Pack 1 to be installed. • These release notes provide information on the AMD display driver only. For information on the ATI Multimedia Center™, HydraVision, HydraVision Basic Edition, Remote Wonder, or the Southbridge/IXP driver, please refer to their respective release notes found at : http://support.amd.com/. • AMD Eyefinity technology gives gamers access to high display resolutions. -

AMD Releases ATI Catalyst 72
AMD Releases ATI Catalyst 7.2 1 / 4 AMD Releases ATI Catalyst 7.2 2 / 4 3 / 4 Just moments ago AMD released this months update to the ATI Catalyst drivers, bringing the Radeon powering software up to version 7.2. Along with the usual .... AMD --. Version 7.2.0 of the xf86-video-ati DDX driver was released this morning. While the X.Org drivers aren't too exciting these days with .... Catalyst 7.2 is available now and boosts performance for all ATI Radeon X1000 series cards. ATI has released new drivers for Windows XP, .... File Description: ATI CATALYST 7.2(FEBRUARY 2007) OFFICAL RELEASE VGA/SOUTHBRIDGE DRIVER FEATURING NEW CATALYST .... Developer. AMD Inc. Latest Version. ATI Catalyst Drivers 14.6 (Beta). Supported Systems ... Version Name. Released Date. Size ... ATI Catalyst 7.2. 22 February .... AMD just released the new Catalyst 7.2 drivers for ATI graphics cards. Some of the ... Open GL performance improves for all ATI Radeon X1000 series products.. This release for all Radeon family products updates the AMD display driver to the latest version. This unified driver has been further enhanced .... ATI Catalyst 7.2 Released AMD/ATI have released their latest set of video card drivers for both Windows XP and Windows Vista. Catalyst™ 7.2 .... AMD/ATI has released its latest version of the Catalyst drivers, which are used by the Radeon 9500 series and higher. There are 32-bit and .... ATI Catalyst™ Software Suite Version 7.2. This release note provides information on the latest posting of AMD's industry leading software suite, Catalyst™.