An Improved Estimation Algorithm of Space Targets Pose Based on Multi-Modal Feature Fusion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cannabinoids and Endocannabinoid System Changes in Intestinal Inflammation and Colorectal Cancer
cancers Review Cannabinoids and Endocannabinoid System Changes in Intestinal Inflammation and Colorectal Cancer Viktoriia Cherkasova, Olga Kovalchuk * and Igor Kovalchuk * Department of Biological Sciences, University of Lethbridge, Lethbridge, AB T1K 7X8, Canada; [email protected] * Correspondence: [email protected] (O.K.); [email protected] (I.K.) Simple Summary: In recent years, multiple preclinical studies have shown that changes in endo- cannabinoid system signaling may have various effects on intestinal inflammation and colorectal cancer. However, not all tumors can respond to cannabinoid therapy in the same manner. Given that colorectal cancer is a heterogeneous disease with different genomic landscapes, experiments with cannabinoids should involve different molecular subtypes, emerging mutations, and various stages of the disease. We hope that this review can help researchers form a comprehensive understanding of cannabinoid interactions in colorectal cancer and intestinal bowel diseases. We believe that selecting a particular experimental model based on the disease’s genetic landscape is a crucial step in the drug discovery, which eventually may tremendously benefit patient’s treatment outcomes and bring us one step closer to individualized medicine. Abstract: Despite the multiple preventive measures and treatment options, colorectal cancer holds a significant place in the world’s disease and mortality rates. The development of novel therapy is in Citation: Cherkasova, V.; Kovalchuk, critical need, and based on recent experimental data, cannabinoids could become excellent candidates. O.; Kovalchuk, I. Cannabinoids and This review covered known experimental studies regarding the effects of cannabinoids on intestinal Endocannabinoid System Changes in inflammation and colorectal cancer. In our opinion, because colorectal cancer is a heterogeneous Intestinal Inflammation and disease with different genomic landscapes, the choice of cannabinoids for tumor prevention and Colorectal Cancer. -

Interact III Monitoring Committee Members
Interact III Monitoring Committee Members Version 71 (18.06.2021) Country Member/substitute Salutation Name Surname Position Organisation Unit Address Zip City Country Email Phone Austria Representative 1 Mr. Manfred Bruckmoser Deputy Head of Federal Ministry for Sustainability and Department IV/4 Coordination - Spatial Ferdinandstrasse 4 '1020 Vienna Austria [email protected] +43 1 71100 612913 Department Tourism Planning and Regional Policy Austria Substitute Ms. Alexandra Deimel Desk Officer Federal Ministry for Sustainability and Department IV/4 Coordination - Spatial Ballhausplatz 2 '1020 Vienna Austria [email protected] +43 1 71100 614384 Tourism Planning and Regional Policy Austria Representative 2 Mr. Martin Pospischill Head of Vienna City Administration Europäische Angelegenheiten Friedrich-Schmidt-Platz 3 1082 Vienna Austria [email protected] +43 1 4000 27001 Department Austria Substitute Ms. Andrea Schwecherl Representative of Vienna City Administration Europäische Angelegenheiten Friedrich-Schmidt-Platz 3 1082 Vienna Austria [email protected] +43 1 4000 27063 the hosting oranization Austria Representative 3 Ms. Tatjana Paar Head of Managing Regionalmanagement Burgenland GmbH Technologiezentrum '7000 Eisenstadt Austria [email protected] +43 (0) 5 9010 2423 Authority INTERREG Programme AT-HU Belgium - Capital Region Representative Mr. Valentin Graas Brussels International Brussels International Kruidtuinlaan 20 '1035 Brussel Belgium [email protected] Belgium - Capital Region Substitute Mr. Geert De Roep EU and multilateral Brussels Regional Public Service Brussels International Kruidtuinlaan 20 '1035 Brussel Belgium [email protected] +32 2 800 37 50 affaires coordinator Belgium - Flemish Region Representative Mr. Dominiek Dutoo Quality Coordinator Agentschap Ondernemen Entiteit Europa Economie Koning Albert II laan 35 bus 12 '1030 Brussel Belgium [email protected] Belgium - Flemish Region Substitute Mr. -

Surname Given Maiden Name Age Date Page Abblett Fred, D. (Sr.) 65 October Ll, L949 5 Abel Infant Infant November 6, L949 2
Surname Given Maiden Name Age Date Page Abblett Fred, D. (Sr.) 65 October ll, l949 5 Abel infant infant November 6, l949 2 Abrahamson Sholom (Sam) 60 August 8, l949 2 Abrudan Nicholas 73 April 3, l949 26 Acton John Wesley (Jr.) l7 December 8, l949 2 Adamczyk Thomas 59 20-Jan-49 Adamczyk Thomas 58 23-Jan-49 Adams Cecil, A. 39 January 3l, l949 Adams Ida, C. 84 January 24, l949 Adler Joseph, T. (Capt.) 58 July 26, l949 2 Agardi Sara 78 July 5, l949 2 Ahlborn John, F. 59 May 22, l949 2 Ahlering Edward, L. 46 December 29, 2 l949 Aiken Martha May 20, l949 2 Ainsworth Sidney 66 June 23, l949 l5 Ajerski John, M. 72 7-Jan-49 Akers William Eugene 2 20-Feb-49 Albertson Theron, R. l4 September l3, 2 l949 Alex Charles 58 November 2, l949 2 Alexander Esther Harrison 55 September 20, 2 l949 Alexander Harry 52 October 7, l949 2 Alexanderson Cecelia 5l April ll, l949 2 Alexanderson Charles, G. (Pfc.) 30 May 5, l949 2 Allie Sam 59 May 20, l949 2 Alonzo Elsie 37 May 2, l949 2 Alt Anna 75 December 2l, 2 l949 Amrai Joseph (Sr.) 64 July 3, l949 2 Anderson Catherine 8l October 4, l949 l7 Anderson Celia 9 June l, l949 9 Anderson Elizabeth 72 September l4, 2 l949 Anderson Oliver, A. September 22, 2 l949 Andree G.W. (Dr.) 43 October 7, l949 2 Andrews Oliver (Sr.) 80 April 4, l949 l3 Andriso Margaret, E. 34 November 25, 33 l949 Anglin M.L. -

Christopher Henry Schmid Professor and Chair of Biostatistics Brown University
September 7, 2021 Christopher Henry Schmid Professor and Chair of Biostatistics Brown University Department of Biostatistics Box G-S121-7 121 South Main St Brown University Providence, RI 02912 Email: [email protected] Phone: +1-401-863-6453 Orcid ID: 0000-0002-0855-5313 Education 1983 B.A. Haverford College (Mathematics) 1987 A.M. Harvard University (Statistics) 1991 PhD Harvard University (Statistics) 2013 A.M. Brown University (ad eundem) Academic Appointments 1991-1994 Statistician, Center for Health Services Research and Study Design, Tufts-New England Medical Center 1992-2012 Special and Scientific Staff, Department of Medicine, Tufts Medical Center 1992-1993 Senior Instructor, Tufts University School of Medicine 1993-1999 Assistant Professor of Medicine, Tufts University School of Medicine 1994-2006 Senior Statistician, Biostatistics Research Ctr, Div of Clinical Care Research/ ICRHPS, Tufts 1996-1999 Assistant Professor of Family Medicine and Community Health, TUSM 1999-2006 Associate Professor of Medicine, Tufts University School of Medicine Associate Prof. of Clinical Research, Sackler School of Graduate Biomedical Sciences, Tufts 2006-2012 Professor of Medicine, Tufts University School of Medicine Professor, Sackler School of Graduate Biomedical Sciences, Tufts University 2006-2012 Director, Biostatistics Research Center, ICRHPS, Tufts Medical Center 2007-2012 Adjunct Professor, Friedman School of Nutrition Science and Policy, Tufts University 2012-2020 Adjunct Professor of Medicine, Tufts University 2012- Professor -

The German Surname Atlas Project ± Computer-Based Surname Geography Kathrin Dräger Mirjam Schmuck Germany
Kathrin Dräger, Mirjam Schmuck, Germany 319 The German Surname Atlas Project ± Computer-Based Surname Geography Kathrin Dräger Mirjam Schmuck Germany Abstract The German Surname Atlas (Deutscher Familiennamenatlas, DFA) project is presented below. The surname maps are based on German fixed network telephone lines (in 2005) with German postal districts as graticules. In our project, we use this data to explore the areal variation in lexical (e.g., Schröder/Schneider µtailor¶) as well as phonological (e.g., Hauser/Häuser/Heuser) and morphological (e.g., patronyms such as Petersen/Peters/Peter) aspects of German surnames. German surnames emerged quite early on and preserve linguistic material which is up to 900 years old. This enables us to draw conclusions from today¶s areal distribution, e.g., on medieval dialect variation, writing traditions and cultural life. Containing not only German surnames but also foreign names, our huge database opens up possibilities for new areas of research, such as surnames and migration. Due to the close contact with Slavonic languages (original Slavonic population in the east, former eastern territories, migration), original Slavonic surnames make up the largest part of the foreign names (e.g., ±ski 16,386 types/293,474 tokens). Various adaptations from Slavonic to German and vice versa occurred. These included graphical (e.g., Dobschinski < Dobrzynski) as well as morphological adaptations (hybrid forms: e.g., Fuhrmanski) and folk-etymological reinterpretations (e.g., Rehsack < Czech Reåak). *** 1. The German surname system In the German speech area, people generally started to use an addition to their given names from the eleventh to the sixteenth century, some even later. -

Sales Report
Sales Listing Report Page 1 of 262 McHenry County 01/21/2021 08:25:40 01/01/2020 - 09/30/2020 Township: GRAFTON TWP Document Number Sale Year Sale Type Valid Sale Sale Date Dept. Study Selling Price Parcel Number Built Year Property Type Prop. Class Acres Square Ft. Lot Size Grantor Name Grantee Name Site Address 2020R0006895 2020 Warranty Deed Y 02/13/2020 Y $189,000.00 REINVEST HOMES, LLC ANGELA STROPE 160 S HEATHER DR 18-01-101-027 0 GARAGE/ NO O O 0040 .00 0 CRYSTAL LAKE, IL 600145177 160 S HEATHER DR CRYSTAL LAKE, IL 60014 - Legal Description: DOC 2020R0006895 LT 31 BLK 15 R A CEPEKS CRYSTAL VISTA 2020R0030830 2020 Partial Assessmen N 07/30/2020 N $136,500.00 DANIEL M ADAMS, AS TRUST BRETT A RIDINGS 1324 THORNWOOD LN 18-01-102-037 0 GARAGE/ NO O O 0040 .00 0 CRYSTAL LAKE, IL 600145042 TARI D RIDINGS 1324 THORNWOOD LANE CRYSTAL LAKE, IL 600140000 1324 THORNWOOD LN CRYSTAL LAKE, IL 60014 -5042 Legal Description: DOC 2020R0030830 LT 1 & PT LT 19 LYING N OF & ADJ BLK 14 R A CEPEKS CRYSTAL VISTA 2020R0010709 2020 Warranty Deed Y 03/16/2020 Y $210,000.00 PATRICK J. CARAMELA JUAN P. MIRANDA STACY C. CARAMELA 58 HOLLY DR 18-01-106-018 0 LDG SINGLE FAM 0040 .00 0 CRYSTAL LAKE, IL 600145022 58 HOLLY DR CRYSTAL LAKE, IL 60014 -5022 Legal Description: DOC 2020R0010709 LT 7 BLK 19 R A CEPEKS CRYSTAL VISTA 2020R0015717 2020 Warranty Deed Y 04/23/2020 Y $95,000.00 LISA M SULMA FANO THEOFANOUS 5011 NORTHWEST HWY 18-01-107-011 0 LDG SINGLE FAM 0040 .00 0 CRYSTAL LAKE, IL 600147330 STEVE THEOFANOUS 5011 NORTHWEST HIGHWAY CRYSTAL LAKE, IL 600147330 113 HEATHER DR CRYSTAL LAKE, IL 60014 - Legal Description: DOC 2020R0015717 LT 12 BLK 31 R A CEPEKS CRYSTAL VISTA Copyright (C) 1997-2021 DEVNET Incorporated MXSTIEG Sales Listing Report Page 2 of 262 McHenry County 01/21/2021 08:25:40 01/01/2020 - 09/30/2020 Township: GRAFTON TWP Document Number Sale Year Sale Type Valid Sale Sale Date Dept. -

Surname Folders.Pdf
SURNAME Where Filed Aaron Filed under "A" Misc folder Andrick Abdon Filed under "A" Misc folder Angeny Abel Anger Filed under "A" Misc folder Aberts Angst Filed under "A" Misc folder Abram Angstadt Achey Ankrum Filed under "A" Misc folder Acker Anns Ackerman Annveg Filed under “A” Misc folder Adair Ansel Adam Anspach Adams Anthony Addleman Appenzeller Ader Filed under "A" Misc folder Apple/Appel Adkins Filed under "A" Misc folder Applebach Aduddell Filed under “A” Misc folder Appleman Aeder Appler Ainsworth Apps/Upps Filed under "A" Misc folder Aitken Filed under "A" Misc folder Apt Filed under "A" Misc folder Akers Filed under "A" Misc folder Arbogast Filed under "A" Misc folder Albaugh Filed under "A" Misc folder Archer Filed under "A" Misc folder Alberson Filed under “A” Misc folder Arment Albert Armentrout Albight/Albrecht Armistead Alcorn Armitradinge Alden Filed under "A" Misc folder Armour Alderfer Armstrong Alexander Arndt Alger Arnold Allebach Arnsberger Filed under "A" Misc folder Alleman Arrel Filed under "A" Misc folder Allen Arritt/Erret Filed under “A” Misc folder Allender Filed under "A" Misc folder Aschliman/Ashelman Allgyer Ash Filed under “A” Misc folder Allison Ashenfelter Filed under "A" Misc folder Allumbaugh Filed under "A" Misc folder Ashoff Alspach Asper Filed under "A" Misc folder Alstadt Aspinwall Filed under "A" Misc folder Alt Aston Filed under "A" Misc folder Alter Atiyeh Filed under "A" Misc folder Althaus Atkins Filed under "A" Misc folder Altland Atkinson Alwine Atticks Amalong Atwell Amborn Filed under -
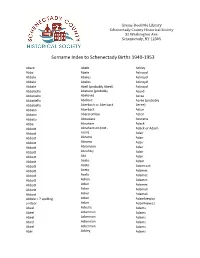
Surname Index to Schenectady Births 1940-1953
Grems-Doolittle Library Schenectady County Historical Society 32 Washington Ave. Schenectady, NY 12305 Surname Index to Schenectady Births 1940-1953 Abare Abele Ackley Abba Abele Ackroyd Abbale Abeles Ackroyd Abbale Abeles Ackroyd Abbale Abell (probably Abeel) Ackroyd Abbatiello Abelone (probably Acord Abbatiello Abelove) Acree Abbatiello Abelove Acree (probably Abbatiello Aberbach or Aberback Aeree) Abbato Aberback Acton Abbato Abercrombie Acton Abbato Aboudara Acucena Abbe Abraham Adack Abbott Abrahamson (not - Adack or Adach Abbott nson) Adair Abbott Abrams Adair Abbott Abrams Adair Abbott Abramson Adair Abbott Abrofsky Adair Abbott Abt Adair Abbott Aceto Adam Abbott Aceto Adamczak Abbott Aceto Adamec Abbott Aceto Adamec Abbott Acken Adamec Abbott Acker Adamec Abbott Acker Adamek Abbott Acker Adamek Abbzle = ? spelling Acker Adamkiewicz unclear Acker Adamkiewicz Abeel Ackerle Adams Abeel Ackerman Adams Abeel Ackerman Adams Abeel Ackerman Adams Abeel Ackerman Adams Abel Ackley Adams Grems-Doolittle Library Schenectady County Historical Society 32 Washington Ave. Schenectady, NY 12305 Surname Index to Schenectady Births 1940-1953 Adams Adamson Ahl Adams Adanti Ahles Adams Addis Ahman Adams Ademec or Adamec Ahnert Adams Adinolfi Ahren Adams Adinolfi Ahren Adams Adinolfi Ahrendtsen Adams Adinolfi Ahrendtsen Adams Adkins Ahrens Adams Adkins Ahrens Adams Adriance Ahrens Adams Adsit Aiken Adams Aeree Aiken Adams Aernecke Ailes = ? Adams Agans Ainsworth Adams Agans Aker (or Aeher = ?) Adams Aganz (Agans ?) Akers Adams Agare or Abare = ? Akerson Adams Agat Akin Adams Agat Akins Adams Agen Akins Adams Aggen Akland Adams Aggen Albanese Adams Aggen Alberding Adams Aggen Albert Adams Agnew Albert Adams Agnew Albert or Alberti Adams Agnew Alberti Adams Agostara Alberti Adams Agostara (not Agostra) Alberts Adamski Agree Albig Adamski Ahave ? = totally Albig Adamson unclear Albohm Adamson Ahern Albohm Adamson Ahl Albohm (not Albolm) Adamson Ahl Albrezzi Grems-Doolittle Library Schenectady County Historical Society 32 Washington Ave. -

European Platform for Roma Inclusion
European Platform for Roma inclusion, Transition from education to employment 27 & 28 November 2017 Agenda Venue: European Economic and Social Committee, rue Beliard 99, Brussels Plenary room: JDE 62, 6th floor Working Language: English Twitter: #RomaEU Justice and Consumers AGENDA The 11th meeting of the European Roma Platform will start with the workshop’ discussions on 27th November in the afternoon. Based on the outcomes of these discussions, the reflections will be put forward for the high level political debate which will continue on 28th of November, the whole day. The Platform will be accompanied by an exhibition by Hungarian art photographer Mr Tamás Schild. MONDAY 27TH NOVEMBER 2017 From 12.45 Registration 14.00 – 14.45 Setting the scene together Chair: • Szabolcs SCHMIDT, Head of Unit, Non-discrimination and Roma coordination, Directorate General for Justice and Consumers, European Commission Welcoming remarks • Ákos TOPOLÁNSZKY, President of the Permanent Study Group on the Inclusion of Roma, European Economic and Social Committee • Irena MOOZOVÁ, Director of Equality and Union Citizenship Directorate, Directorate General for Justice and Consumers, European Commission • Katarína MATHERNOVÁ, Deputy Director General, Directorate General for Neighbourhood and Enlargement Negotiations, European Commission • Ioannis DIMITRAKOPOULOS, Head of Equality and Citizens’ Department, EU Agency for Fundamental Rights 14.45 – 16.30 Workshops Workshop focusing on education aspects of transition from education to employment Facilitators: • Dana -
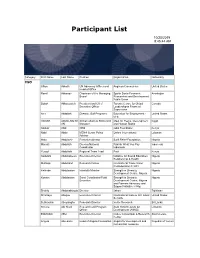
Participant List
Participant List 10/20/2019 8:45:44 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Ramil Abbasov Chariman of the Managing Spektr Socio-Economic Azerbaijan Board Researches and Development Public Union Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Amr Abdallah Director, Gulf Programs Educaiton for Employment - United States EFE HAGAR ABDELRAHM African affairs & SDGs Unit Maat for Peace, Development Egypt AN Manager and Human Rights Abukar Abdi CEO Juba Foundation Kenya Nabil Abdo MENA Senior Policy Oxfam International Lebanon Advisor Mala Abdulaziz Executive director Swift Relief Foundation Nigeria Maryati Abdullah Director/National Publish What You Pay Indonesia Coordinator Indonesia Yussuf Abdullahi Regional Team Lead Pact Kenya Abdulahi Abdulraheem Executive Director Initiative for Sound Education Nigeria Relationship & Health Muttaqa Abdulra'uf Research Fellow International Trade Union Nigeria Confederation (ITUC) Kehinde Abdulsalam Interfaith Minister Strength in Diversity Nigeria Development Centre, Nigeria Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Shahlo Abdunabizoda Director Jahon Tajikistan Shontaye Abegaz Executive Director International Insitute for Human United States Security Subhashini Abeysinghe Research Director Verite -

Integration and Name Changing Among Jewish Refugees from Central Europe in the United States
Reprinted from NAMES VOLUME VI • NUMBER 3 • SEPTEMBER 1958 Integration and Name Changing among Jewish Refugees from Central Europe in the United States ERNEST MAASS Acknowledgements The idea of writing this study came to me a number of years ago. However, it was not until I received a fellowship for this purpose from the Jewish Conference on Material Claims against Germany, Inc., which I gratefully acknowledge, that I was able to give the subject the time and attention I felt it deserved. In furthering the progress of the work several persons were particularly helpful. They gave me freely of their time, encouraged me in various ways, offered welcome critical advice, or commented on the draft manus- cript. Special thanks for such help are due to Abraham Aidenoff, William R. Gaede, Kurt R. Grossmann, Erwin G. Gudde, Hugo Hahn, Ernest Hamburger, Alfred L. Lehmann, Adolf Leschnitzer, Martin Sobotker, Arieh Tartakower and Fred S. Weissman. Among those who throughout the years brought name changes to my attention I am especially indebted to my mother. I also wish to thank the many other persons from whose active interest in the project I have profited and whom I may have failed to mention. Background, Immigration, Integration SE TERM "JEWISH REFUGEE FROM CENTRAL EUROPE", in this paper, refers to Jews from Germany and Austria who left their native lands in 1933 or later as a result of persecution by the Na- tional Socialist regime. It also includes Jews from Czechoslovakia whose mother tongue was German and. who escaped after the annexation by Germany of the Sudetenland in 1938 and the esta- blishment of a German Protectorate in 1939. -

Surname First Name Categorisation Abadin Jose Luis Silver Abbelen
2018 DRIVERS' CATEGORISATION LIST Updated on 09/07/2018 Drivers in red : revised categorisation Drivers in blue : new categorisation Surname First name Categorisation Abadin Jose Luis Silver Abbelen Klaus Bronze Abbott Hunter Silver Abbott James Silver Abe Kenji Bronze Abelli Julien Silver Abergel Gabriele Bronze Abkhazava Shota Bronze Abra Richard Silver Abreu Attila Gold Abril Vincent Gold Abt Christian Silver Abt Daniel Gold Accary Thomas Silver Acosta Hinojosa Julio Sebastian Silver Adam Jonathan Platinum Adams Rudi Bronze Adorf Dirk Silver Aeberhard Juerg Silver Afanasiev Sergei Silver Agostini Riccardo Gold Aguas Rui Gold Ahlin-Kottulinsky Mikaela Silver Ahrabian Darius Bronze Ajlani Karim Bronze Akata Emin Bronze Aksenov Stanislas Silver Al Faisal Abdulaziz Silver Al Harthy Ahmad Silver Al Masaood Humaid Bronze Al Qubaisi Khaled Bronze Al-Azhari Karim Bronze Alberico Neil Silver Albers Christijan Platinum Albert Michael Silver Albuquerque Filipe Platinum Alder Brian Silver Aleshin Mikhail Platinum Alesi Giuliano Silver Alessi Diego Silver Alexander Iradj Silver Alfaisal Saud Bronze Alguersuari Jaime Platinum Allegretta Vincent Silver Alleman Cyndie Silver Allemann Daniel Bronze Allen James Silver Allgàuer Egon Bronze Allison Austin Bronze Allmendinger AJ Gold Allos Manhal Bronze Almehairi Saeed Silver Almond Michael Silver Almudhaf Khaled Bronze Alon Robert Silver Alonso Fernando Platinum Altenburg Jeff Bronze Altevogt Peter Bronze Al-Thani Abdulrahman Silver Altoè Giacomo Silver Aluko Kolawole Bronze Alvarez Juan Cruz Silver Alzen