Multi-Stroke Thai Finger-Spelling Sign Language Recognition System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sign Language Typology Series
SIGN LANGUAGE TYPOLOGY SERIES The Sign Language Typology Series is dedicated to the comparative study of sign languages around the world. Individual or collective works that systematically explore typological variation across sign languages are the focus of this series, with particular emphasis on undocumented, underdescribed and endangered sign languages. The scope of the series primarily includes cross-linguistic studies of grammatical domains across a larger or smaller sample of sign languages, but also encompasses the study of individual sign languages from a typological perspective and comparison between signed and spoken languages in terms of language modality, as well as theoretical and methodological contributions to sign language typology. Interrogative and Negative Constructions in Sign Languages Edited by Ulrike Zeshan Sign Language Typology Series No. 1 / Interrogative and negative constructions in sign languages / Ulrike Zeshan (ed.) / Nijmegen: Ishara Press 2006. ISBN-10: 90-8656-001-6 ISBN-13: 978-90-8656-001-1 © Ishara Press Stichting DEF Wundtlaan 1 6525XD Nijmegen The Netherlands Fax: +31-24-3521213 email: [email protected] http://ishara.def-intl.org Cover design: Sibaji Panda Printed in the Netherlands First published 2006 Catalogue copy of this book available at Depot van Nederlandse Publicaties, Koninklijke Bibliotheek, Den Haag (www.kb.nl/depot) To the deaf pioneers in developing countries who have inspired all my work Contents Preface........................................................................................................10 -

Sign Language Endangerment and Linguistic Diversity Ben Braithwaite
RESEARCH REPORT Sign language endangerment and linguistic diversity Ben Braithwaite University of the West Indies at St. Augustine It has become increasingly clear that current threats to global linguistic diversity are not re - stricted to the loss of spoken languages. Signed languages are vulnerable to familiar patterns of language shift and the global spread of a few influential languages. But the ecologies of signed languages are also affected by genetics, social attitudes toward deafness, educational and public health policies, and a widespread modality chauvinism that views spoken languages as inherently superior or more desirable. This research report reviews what is known about sign language vi - tality and endangerment globally, and considers the responses from communities, governments, and linguists. It is striking how little attention has been paid to sign language vitality, endangerment, and re - vitalization, even as research on signed languages has occupied an increasingly prominent posi - tion in linguistic theory. It is time for linguists from a broader range of backgrounds to consider the causes, consequences, and appropriate responses to current threats to sign language diversity. In doing so, we must articulate more clearly the value of this diversity to the field of linguistics and the responsibilities the field has toward preserving it.* Keywords : language endangerment, language vitality, language documentation, signed languages 1. Introduction. Concerns about sign language endangerment are not new. Almost immediately after the invention of film, the US National Association of the Deaf began producing films to capture American Sign Language (ASL), motivated by a fear within the deaf community that their language was endangered (Schuchman 2004). -

Reimagine Thailand Hotel Participating List AVISTA GRANDE
Reimagine Thailand Hotel Participating List AVISTA GRANDE PHUKET KARON HOTEL BARAQUDA PATTAYA MGALLERY GRAND MERCURE ASOKE RESIDENCE GRAND MERCURE BANGKOK FORTUNE GRAND MERCURE BANGKOK WINDSOR GRAND MERCURE KHAO LAK GRAND MERCURE PHUKET PATONG HOTEL MUSE BANGKOK LANGSUAN IBIS BANGKOK IMPACT IBIS BANGKOK RIVERSIDE IBIS BANGKOK SATHORN IBIS BANGKOK SIAM IBIS BANGKOK SUKHUMVIT 24 IBIS BANGKOK SUKHUMVIT 4 IBIS HUA HIN IBIS PATTAYA IBIS PHUKET KATA IBIS PHUKET PATONG IBIS SAMUI BOPHUT IBIS STYLES BANGKOK RATCHADA IBIS STYLES BANGKOK SILOM IBIS STYLES BANGKOK SUKHUMVIT 4 IBIS STYLES BANGKOK SUKHUMVIT 50 IBIS STYLES KOH SAMUI CHAWENG IBIS STYLES KRABI AO NANG IBIS STYLES PHUKET CITY MERCURE BANGKOK SIAM MERCURE BANGKOK SUKHUMVIT 24 MERCURE CHIANG MAI MERCURE KOH CHANG HIDEAWAY MERCURE KOH SAMUI BEACH RESORT MERCURE PATTAYA MERCURE PATTAYA OCEAN RESORT MERCURE RAYONG LOMTALAY MOVENPICK ASARA HUA HIN MOVENPICK BANGTAO BEACH PHUKET MOVENPICK RESORT KHAO YAI MOVENPICK SIAM HOTEL PATTA NOVOTEL BANGKOK ON SIAM SQUARE NOVOTEL BANGKOK IMPACT NOVOTEL BANGKOK PLATINUM NOVOTEL BANGKOK SUKHUMVIT 20 NOVOTEL BANGKOK SUKHUMVIT 4 NOVOTEL CHIANGMAI NIMMAN NOVOTEL HUA HIN CHA AM RESORT NOVOTEL PHUKET CITY PHOKEETHRA NOVOTEL RAYONG RIM PAE RESORT NOVOTEL SRIRACHA MARINA BAY NOVOTEL SUITES SUKHUMVIT 34 NOVOTEL SUVARNABHUMI AIRPORT PULLMAN BANGKOK HOTEL G PULLMAN BANGKOK KING POWER PULLMAN KHAO LAK RESORT PULLMAN KHON KAEN RAJA ORCHID PULLMAN PATTAYA HOTEL G PULLMAN PHUKET ARCADIA RESORT PULLMAN PHUKET PANWA SO SOFITEL HUA HIN SO/ BANGKOK SOFITEL BANGKOK SUKHUMVIT SOFITEL KRABI PHOKEETHRA SWISSOTEL BANGKOK RATCHADA VERANDA HIGH RESORT MGALLERY VERANDA RESORT HUA HIN VERANDA RESORT PATTAYA VIE HOTEL BANGKOK MGALLERY *Latest update: 22 Feb 2021 . -

The Signed Languages of Indonesia: an Enigma
DigitalResources Electronic Survey Report 2014-005 ® The Signed Languages of Indonesia: An Enigma Hope M. Hurlbut The Signed Languages of Indonesia: An Enigma Hope M. Hurlbut SIL International® 2014 SIL Electronic Survey Report 2014-005, April 2014 © 2014 SIL International® All rights reserved 1 2 Abstract In 2003–2005, SIL International undertook a lexicostatistical survey of the signed languages of Indonesia. Wordlists and stories were collected from each of the nineteen states where one or more schools for the Deaf were run privately or by the government. The wordlists were video recorded and transcribed by hand using the SignWriting orthography. The results of the wordlist comparisons point out the need for intelligibility testing between users of the various varieties of Indonesian Sign Language. Intelligibility testing should be carried out sometime in at least eleven of the nineteen states where the similarity between the signs in the list is low. This paper focuses on the results of the lexicostatistical survey. There are at least two signed languages in use in Indonesia, Indonesian Sign Language and Bengkala Sign Language. Bengkala Sign Language is an isolect found in northern Bali in the village of Bengkala where there is a high proportion of Deaf among the inhabitants. It has been called Bali Sign Language in the past, but since it seems to be more or less confined to the village of Bengkala, it seems better to call it Bengkala Sign Language. The rest of the Deaf on the island use a form of Indonesian Sign Language. At the time of the survey there were two Deaf youth from Bengkala going to school in the Deaf school (or a Deaf class) in Singaraja which is about 17 kilometers from Bengkala Village. -

Final Project Report English Pdf 463.15 KB
CEPF Final Project Completion Report Organization Legal Name Bird Conservation Society of Thailand Project Title Building a Network for Monitoring Important Bird Areas in Thailand CEPF GEM No. CEPF-032-2014 Date of Report Report Author Thattaya Bidayabha 221 Moo 2 Soi Ngamwongwan 27 Ngamwongwan Road, Bangkhen, Muang, Nonthaburi 11000 Thailand Author Contact Information Tel.: +66 2 588 2277 Fax: +66 2 588 2277 E-mail: [email protected] CEPF Region: Indo-Burma Strategic Direction: Strategic Direction 8: "Strengthen the capacity of civil society to work on biodiversity, communities and livelihoods at regional, national, local and grassroots levels" Grant Amount: $19,999 Project Dates: November 1st, 2014 to October 31st, 2015 1. Implementation Partners for this Project Department of National Parks, Wildlife, and Plant Conservation - the government agency that is responsible for the management of and law enforcement in protected areas. Universities - Kasetsart University, Chiang Mai University, Khon Kaen University, and Walailuck University hosted the IBA monitoring workshops. Local Conservation Clubs; - Khok Kham Conservation Club, Khok Kham district, Samut Sakhon province. They were involved in IBA monitoring in the Inner Gulf of Thailand - Lanna Bird Club, Chiang Mai province. They were involved in IBA monitoring in northern Thailand. - Nan Birding Club, Nan province. They were involved in IBA monitoring in northern Thailand. - Mae Moh Bird Conservation Club, Lampang province. They were involved in IBA monitoring in northern Thailand. - Chun Conservation Club, Phayao province. They were involved in IBA monitoring in northern Thailand. - Flyway Foundation, Chumphon province. They were involved in IBA monitoring in southern Thailand. - Khao Luang Bird Conservation Club, Nakhon Sri Thammarat province. -

Typology of Signed Languages: Differentiation Through Kinship Terminology Erin Wilkinson
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by University of New Mexico University of New Mexico UNM Digital Repository Linguistics ETDs Electronic Theses and Dissertations 7-1-2009 Typology of Signed Languages: Differentiation through Kinship Terminology Erin Wilkinson Follow this and additional works at: https://digitalrepository.unm.edu/ling_etds Recommended Citation Wilkinson, Erin. "Typology of Signed Languages: Differentiation through Kinship Terminology." (2009). https://digitalrepository.unm.edu/ling_etds/40 This Dissertation is brought to you for free and open access by the Electronic Theses and Dissertations at UNM Digital Repository. It has been accepted for inclusion in Linguistics ETDs by an authorized administrator of UNM Digital Repository. For more information, please contact [email protected]. TYPOLOGY OF SIGNED LANGUAGES: DIFFERENTIATION THROUGH KINSHIP TERMINOLOGY BY ERIN LAINE WILKINSON B.A., Language Studies, Wellesley College, 1999 M.A., Linguistics, Gallaudet University, 2001 DISSERTATION Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Linguistics The University of New Mexico Albuquerque, New Mexico August, 2009 ©2009, Erin Laine Wilkinson ALL RIGHTS RESERVED iii DEDICATION To my mother iv ACKNOWLEDGMENTS Many thanks to Barbara Pennacchi for kick starting me on my dissertation by giving me a room at her house, cooking me dinner, and making Italian coffee in Rome during November 2007. Your endless support, patience, and thoughtful discussions are gratefully taken into my heart, and I truly appreciate what you have done for me. I heartily acknowledge Dr. William Croft, my advisor, for continuing to encourage me through the long number of months writing and rewriting these chapters. -

Gallbladder and Extrahepatic Bile Duct
Surathat Pongnikorn, Nimit Martin Gallbladder and Extrahepatic Bile Duct In Thailand during the period males (377 cases) in a ratio of 1.9:1. 1995-1997, carcinoma of gallblad- Gallbladder cancer and extra- Chapter II der and extrahepatic duct is not in- hepatic bile duct carcinoma are the cluded in the top ten of the most tenth in frequency in Lampang in frequency. The estimated inci- both males (ASR = 3.6) and fe- dence rate is 1.6 per 100 000 among males (ASR = 3.3) which is the males and 2.4 per 100 000 among highest incidence rate among five females. Females (728 cases) are centers. Female are affected more affected by gallbladder and extra- than males in Chiang Mai, Bang- 8 hepatic bile duct cancer more than kok and Songkhla although in Figure 2.8.1 Gallbladder and extrahepatic bile duct cancer in different regions, 1995- GALLBLADDER 1997 AND EXTRAHEPATIC Male *USA, New Maxico 4.3 BILE DUCT American Indian ICD-10 C23-24 Thailand 1.6 Chiang Mai 1.5 Surathat Pongnikorn, M.D. Nimit Martin, M.D. Lampang 3.6 Khon Kaen 1.9 Bangkok 1.2 Songkhla 0.9 0510 ASR (World) Female *India, Delhi 8.8 Thailand 2.4 Chiang Mai 3.2 Lampang 3.3 Khon Kaen 1.6 Bangkok 1.4 Songkhla 1.1 0510 ASR (World) *The highest incidence in CI5 Vol. VIII 38 p. 38-¥” Gallbladder and Extrahepatic Bile Duct Surathat Pongnikorn, Nimit Martin Lampang and Khon Kaen males are Figure 2.8.2 Age-specific incidence rates of gallbladder and extrahepatic bile duct affected more than females. -

Toponyms in Ban Khor Sign Language | Angela M
Toponyms in Ban Khor Sign Language | Angela M. Nonaka 66 Toponyms in Ban Khor Sign Language Angela M. Nonaka The University of Texas at Austin (USA) [email protected] Introduction Ban Khor Sign Language (BKSL) is a rare language variety known as a ‘village’ (Zeshan 2004) or ‘indigenous’ (Woodward 2000) sign language. This type of sign language develops in small face-to-face communities where historically there are/were: 1) demographically `1#$%%%%}`` #####$}`T$ } ~` $ #} ` %T$!;# characteristics of the language ecologies of signing village communities, however, involve their local language ideologies and practices. In such communities, there are no sign language interpreters. Instead, it is common not only for deaf people but also for hearing residents to acquire and use the village sign language. Because it is widely used by both deaf and hearing people in the course of everyday life, the village sign language facilitates the inclusion (vs. exclusion) of deaf members of the community. Villages with indigenous sign languages are unusual but have been found elsewhere: in Africa, the Americas, Asia, Australia and Oceania, the Caribbean, and the Middle East (Branson & ^}@!}#$$}}} }@}X;}$¥}}¨}¨ }~}=#}=$}=~¥ $}=¥}=}+#¢^$}+ }^+¥}^}^%#¢<}^!} ~$}¥}!}\ !}}*!}*$}*#};! }@}$¥}`!* communities’ alternative social constructions of and communicative responses to deafness is enriching anthropological understanding of cultural variation, and research on the local sign languages is expanding knowledge of linguistics in areas such as: documentary linguistics, typological linguistics, historical linguistics, language universals, and so on. In anthropological linguistics, there is a robust literature on onomastics—the study of the origin and forms of proper names (personal, place, brand, etc.). Names are interesting and useful phenomena for linguistic and cultural analysis because naming systems and practices mirror and order the social world. -
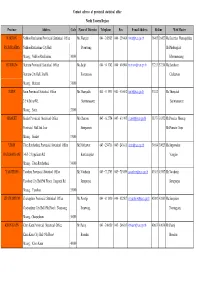
Province Address Code Name of Director Telephone Fax E-Mail
Contact adrress of provincial statistical office North Eastern Region Province Address Code Name of Director Telephone Fax E-mail AddressHotline Web Master NAKHON Nakhon Ratchasima Provincial Statistical Office Ms.Wanpen 044 - 242985 044 - 256406 [email protected] 36465 36427 Ms.Kanittha Wannapakdee RATCHASIMA Nakhon Ratchasima City Hall Poonwong Mr.Phadungkiat Muang , Nakhon Ratchasima 30000 Khmmamuang BURIRUM Burirum Provincial Statistical Office Ms.Saijit 044 - 611742 044 - 614904 [email protected] 37213 37214 Ms.Somboon Burirum City Hall, Jira Rd. Kootaranon Chaleewan Muang , Burirum 31000 SURIN Surin Provincial Statistical Office Ms.Thanyalak 044 - 511931 044 - 516062 [email protected] 37812 Ms.Thanyalak 2/5-6 Sirirat Rd. Surintarasaree Surintarasaree Muang , Surin 32000 SISAKET Sisaket Provincial Statistical Office Mr.Charoon 045 - 612754 045 - 611995 [email protected] 38373 38352 Mr.Preecha Meesup Provincial Hall 2nd floor Siengsanan Mr.Pramote Sopa Muang , Sisaket 33000 UBON Ubon Ratchathani Provincial Statistical Office Mr.Natthawat 045 - 254718 045 - 243811 [email protected] 39014 39023 Ms.Supawadee RATCHATHANI 146/1-2 Uppalisarn Rd. Kanthanaphat Vonglao Muang , Ubon Ratchathani 34000 YASOTHON Yasothon Provincial Statistical Office Mr.Vatcharin 045 - 712703 045 - 713059 [email protected] 43563 43567 Mr.Vatcharin Yasothon City Hall(5th Floor), Jangsanit Rd. Jermprapai Jermprapai Muang , Yasothon 35000 CHAIYAPHUM Chaiyaphum Provincial Statistical Office Ms.Porntip 044 - 811810 044 - 822507 [email protected] 42982 42983 Ms.Sanyakorn -

Floods and Landslides
Information bulletin Thailand: Floods and Landslides Glide n° Date of issue: 7 September 2019 Date of disaster 29 August 2019 (Ongoing) Point of contact (name and title): Hung Ha Nguyen, Manager, Community Safety Resilience Operation start date: TBC Expected timeframe: TBC Category of disaster: Orange Host National Society: Thai Red Cross Society Number of people affected: 158,028 households Number of people to be assisted: TBC N° of National Societies currently involved in the operation (if available and relevant): TRCS is working with the International Federation of Red Cross and Red Crescent (IFRC), International Committee of red Cross (ICRC) and Partner National Societies (PNS) with presence in Thailand N° of other partner organizations involved in the operation (if available and relevant): Department of Disaster Prevention and Mitigation (DDPM) This bulletin is being issued for information only and reflects the current situation and details available at this time. The Thai Red Cross Society with the support of the International Federation of Red Cross and Red Crescent Societies (IFRC) is currently considering whether external assistance is required. <click here to view the map of the affected area, or here for detailed contact information> The situation On 29 August 2019, Tropical Storm (TS) Podul crossed into north-east and northern Thailand bringing rainfall and winds causing flash flooding and landslides affecting 32 provinces namely Amnat Charoen, Chaiyaphoom, Chiang Mai, Chumporn, Kalasin, Khon Kaen, Krabi, Loei, Lumpang, Mae Hong Son, Maha Sarakham, Mukdaharn, Nakorn Phanom, Nan, Nong Bua Lam Phu, Petchaboon, Phitsanulok, Pichit, Pracheenburi, Prae, Ranong, Roi- Et, Sakon Nakorn, Srakeo, Sri Saket, Sukhothai, Surin, Trad, Ubon Ratchathani, Udon Thani, Utaradit and Yasothorn). -

Goat-Sheep-Mixed-Sign” in Lhasa - Deaf Tibetans’ Language Ideologies and Unimodal Codeswitching in Tibetan and Chinese Sign Languages, Tibet Autonomous Region, China’
Hofer, T. (2020). "Goat-Sheep-Mixed-Sign” in Lhasa - Deaf Tibetans’ Language Ideologies and Unimodal Codeswitching in Tibetan and Chinese Sign Languages, Tibet Autonomous Region, China’. In A. Kusters, M. E. Green, E. Moriarty Harrelson, & K. Snoddon (Eds.), Sign Language Ideologies in Practice (pp. 81-105). DeGruyter. https://doi.org/10.1515/9781501510090-005 Publisher's PDF, also known as Version of record License (if available): CC BY-NC-ND Link to published version (if available): 10.1515/9781501510090-005 Link to publication record in Explore Bristol Research PDF-document This is the final published version of the article (version of record). It first appeared online via DeGruyter at https://doi.org/10.1515/9781501510090-005 . Please refer to any applicable terms of use of the publisher. University of Bristol - Explore Bristol Research General rights This document is made available in accordance with publisher policies. Please cite only the published version using the reference above. Full terms of use are available: http://www.bristol.ac.uk/red/research-policy/pure/user-guides/ebr-terms/ Theresia Hofer “Goat-Sheep-Mixed-Sign” in Lhasa – Deaf Tibetans’ language ideologies and unimodal codeswitching in Tibetan and Chinese sign languages, Tibet Autonomous Region, China 1 Introduction Among Tibetan signers in Lhasa, there is a growing tendency to mix Tibetan Sign Language (TSL) and Chinese Sign Language (CSL). I have been learning TSL from deaf TSL teachers and other deaf, signing Tibetan friends since 2007, but in more recent conversations with them I have been more and more exposed to CSL. In such contexts, signing includes not only loan signs, loan blends or loan trans- lations from CSL that have been used in TSL since its emergence, such as signs for new technical inventions or scientific terms. -

WHO Thailand Situation Report
Coronavirus disease 2019 (COVID-19) Data as reported by the CCSA mid-day press briefing 27 December 2020 WHO Thailand Situation Report THAILAND SITUATION 6,141 60 1,902 4,161 UPDATE Confirmed Deaths Hospitalized Recovered SPOTLIGHT • On the 27th of December 2020, 121 new cases of laboratory-confirmed COVID-19 were reported by the Ministry of Public Health. The total number of cases reported in Thailand is currently 6,141. • Of these cases, 68 % (4,161) have recovered, 1% (60) have died and 31 % (1,902) are still receiving treatment. No new deaths were reported. • The 121 laboratory-confirmed cases reported today include 8 individuals who entered the country recently and were diagnosed in quarantine facilities. A case is also reported in an individual who entered Thailand recently, but was not in Quarantine. There are 94 new cases classified as ‘domestic transmission’. The remaining 18 cases are in individuals in Samut Sakhon who have been identified through contact tracing and active case finding. • COVID-19 cases linked to the event in Samut Sakhon have now been reported in an additional 38 Provinces. o 18-21 December: Bangkok, Nakhon Pathom, Samut Prakan (3) o 22 December: Chachoengsao, Pathum Thani, Saraburi, Uttradit and Petchaburi (5) o 23 December: Petchabun, Krabi, Kampaeng Phet, Khon Kaen, Ayutthaya, Nakhon Ratchasima, Prachinburi, Phuket, Suphanburi (9) o 24 December: Samut Songkram, Chainat, Pichit, Ang Thong, Nakhon Sawan, Udon Tani, Chaiyaphum, Nakhon Si Thammarat, and Surat Thani (9) o 25 December: Ratchaburi, Chonburi, Loei, Ubon Ratchatani, Songkhla, Nonthaburi (6) o 26 December: Rayong, Trang, Satun, Sukhothai, Nakhon Nayok (5) • In total, 11,620 individuals have been tested through active cases finding / screening in Samut Sakhon, of ths total, 1356 (11.7%) have been confirmed infected with COVID-19.