Translating Pharmacogenetics Treat Everyone As an Individual DMET™ Plus Solution Translating Pharmacogenetics Into Practice DMET™ Plus Solution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Identification and Developmental Expression of the Full Complement Of
Goldstone et al. BMC Genomics 2010, 11:643 http://www.biomedcentral.com/1471-2164/11/643 RESEARCH ARTICLE Open Access Identification and developmental expression of the full complement of Cytochrome P450 genes in Zebrafish Jared V Goldstone1, Andrew G McArthur2, Akira Kubota1, Juliano Zanette1,3, Thiago Parente1,4, Maria E Jönsson1,5, David R Nelson6, John J Stegeman1* Abstract Background: Increasing use of zebrafish in drug discovery and mechanistic toxicology demands knowledge of cytochrome P450 (CYP) gene regulation and function. CYP enzymes catalyze oxidative transformation leading to activation or inactivation of many endogenous and exogenous chemicals, with consequences for normal physiology and disease processes. Many CYPs potentially have roles in developmental specification, and many chemicals that cause developmental abnormalities are substrates for CYPs. Here we identify and annotate the full suite of CYP genes in zebrafish, compare these to the human CYP gene complement, and determine the expression of CYP genes during normal development. Results: Zebrafish have a total of 94 CYP genes, distributed among 18 gene families found also in mammals. There are 32 genes in CYP families 5 to 51, most of which are direct orthologs of human CYPs that are involved in endogenous functions including synthesis or inactivation of regulatory molecules. The high degree of sequence similarity suggests conservation of enzyme activities for these CYPs, confirmed in reports for some steroidogenic enzymes (e.g. CYP19, aromatase; CYP11A, P450scc; CYP17, steroid 17a-hydroxylase), and the CYP26 retinoic acid hydroxylases. Complexity is much greater in gene families 1, 2, and 3, which include CYPs prominent in metabolism of drugs and pollutants, as well as of endogenous substrates. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Synonymous Single Nucleotide Polymorphisms in Human Cytochrome
DMD Fast Forward. Published on February 9, 2009 as doi:10.1124/dmd.108.026047 DMD #26047 TITLE PAGE: A BIOINFORMATICS APPROACH FOR THE PHENOTYPE PREDICTION OF NON- SYNONYMOUS SINGLE NUCLEOTIDE POLYMORPHISMS IN HUMAN CYTOCHROME P450S LIN-LIN WANG, YONG LI, SHU-FENG ZHOU Department of Nutrition and Food Hygiene, School of Public Health, Peking University, Beijing 100191, P. R. China (LL Wang & Y Li) Discipline of Chinese Medicine, School of Health Sciences, RMIT University, Bundoora, Victoria 3083, Australia (LL Wang & SF Zhou). 1 Copyright 2009 by the American Society for Pharmacology and Experimental Therapeutics. DMD #26047 RUNNING TITLE PAGE: a) Running title: Prediction of phenotype of human CYPs. b) Author for correspondence: A/Prof. Shu-Feng Zhou, MD, PhD Discipline of Chinese Medicine, School of Health Sciences, RMIT University, WHO Collaborating Center for Traditional Medicine, Bundoora, Victoria 3083, Australia. Tel: + 61 3 9925 7794; fax: +61 3 9925 7178. Email: [email protected] c) Number of text pages: 21 Number of tables: 10 Number of figures: 2 Number of references: 40 Number of words in Abstract: 249 Number of words in Introduction: 749 Number of words in Discussion: 1459 d) Non-standard abbreviations: CYP, cytochrome P450; nsSNP, non-synonymous single nucleotide polymorphism. 2 DMD #26047 ABSTRACT Non-synonymous single nucleotide polymorphisms (nsSNPs) in coding regions that can lead to amino acid changes may cause alteration of protein function and account for susceptivity to disease. Identification of deleterious nsSNPs from tolerant nsSNPs is important for characterizing the genetic basis of human disease, assessing individual susceptibility to disease, understanding the pathogenesis of disease, identifying molecular targets for drug treatment and conducting individualized pharmacotherapy. -

Enzyme DHRS7
Toward the identification of a function of the “orphan” enzyme DHRS7 Inauguraldissertation zur Erlangung der Würde eines Doktors der Philosophie vorgelegt der Philosophisch-Naturwissenschaftlichen Fakultät der Universität Basel von Selene Araya, aus Lugano, Tessin Basel, 2018 Originaldokument gespeichert auf dem Dokumentenserver der Universität Basel edoc.unibas.ch Genehmigt von der Philosophisch-Naturwissenschaftlichen Fakultät auf Antrag von Prof. Dr. Alex Odermatt (Fakultätsverantwortlicher) und Prof. Dr. Michael Arand (Korreferent) Basel, den 26.6.2018 ________________________ Dekan Prof. Dr. Martin Spiess I. List of Abbreviations 3α/βAdiol 3α/β-Androstanediol (5α-Androstane-3α/β,17β-diol) 3α/βHSD 3α/β-hydroxysteroid dehydrogenase 17β-HSD 17β-Hydroxysteroid Dehydrogenase 17αOHProg 17α-Hydroxyprogesterone 20α/βOHProg 20α/β-Hydroxyprogesterone 17α,20α/βdiOHProg 20α/βdihydroxyprogesterone ADT Androgen deprivation therapy ANOVA Analysis of variance AR Androgen Receptor AKR Aldo-Keto Reductase ATCC American Type Culture Collection CAM Cell Adhesion Molecule CYP Cytochrome P450 CBR1 Carbonyl reductase 1 CRPC Castration resistant prostate cancer Ct-value Cycle threshold-value DHRS7 (B/C) Dehydrogenase/Reductase Short Chain Dehydrogenase Family Member 7 (B/C) DHEA Dehydroepiandrosterone DHP Dehydroprogesterone DHT 5α-Dihydrotestosterone DMEM Dulbecco's Modified Eagle's Medium DMSO Dimethyl Sulfoxide DTT Dithiothreitol E1 Estrone E2 Estradiol ECM Extracellular Membrane EDTA Ethylenediaminetetraacetic acid EMT Epithelial-mesenchymal transition ER Endoplasmic Reticulum ERα/β Estrogen Receptor α/β FBS Fetal Bovine Serum 3 FDR False discovery rate FGF Fibroblast growth factor HEPES 4-(2-Hydroxyethyl)-1-Piperazineethanesulfonic Acid HMDB Human Metabolome Database HPLC High Performance Liquid Chromatography HSD Hydroxysteroid Dehydrogenase IC50 Half-Maximal Inhibitory Concentration LNCaP Lymph node carcinoma of the prostate mRNA Messenger Ribonucleic Acid n.d. -

(12) Patent Application Publication (10) Pub. No.: US 2003/0082511 A1 Brown Et Al
US 20030082511A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2003/0082511 A1 Brown et al. (43) Pub. Date: May 1, 2003 (54) IDENTIFICATION OF MODULATORY Publication Classification MOLECULES USING INDUCIBLE PROMOTERS (51) Int. Cl." ............................... C12O 1/00; C12O 1/68 (52) U.S. Cl. ..................................................... 435/4; 435/6 (76) Inventors: Steven J. Brown, San Diego, CA (US); Damien J. Dunnington, San Diego, CA (US); Imran Clark, San Diego, CA (57) ABSTRACT (US) Correspondence Address: Methods for identifying an ion channel modulator, a target David B. Waller & Associates membrane receptor modulator molecule, and other modula 5677 Oberlin Drive tory molecules are disclosed, as well as cells and vectors for Suit 214 use in those methods. A polynucleotide encoding target is San Diego, CA 92121 (US) provided in a cell under control of an inducible promoter, and candidate modulatory molecules are contacted with the (21) Appl. No.: 09/965,201 cell after induction of the promoter to ascertain whether a change in a measurable physiological parameter occurs as a (22) Filed: Sep. 25, 2001 result of the candidate modulatory molecule. Patent Application Publication May 1, 2003 Sheet 1 of 8 US 2003/0082511 A1 KCNC1 cDNA F.G. 1 Patent Application Publication May 1, 2003 Sheet 2 of 8 US 2003/0082511 A1 49 - -9 G C EH H EH N t R M h so as se W M M MP N FIG.2 Patent Application Publication May 1, 2003 Sheet 3 of 8 US 2003/0082511 A1 FG. 3 Patent Application Publication May 1, 2003 Sheet 4 of 8 US 2003/0082511 A1 KCNC1 ITREXCHO KC 150 mM KC 2000000 so 100 mM induced Uninduced Steady state O 100 200 300 400 500 600 700 Time (seconds) FIG. -

CYP2F1 (NM 000774) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC223097 CYP2F1 (NM_000774) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: CYP2F1 (NM_000774) Human Tagged ORF Clone Tag: Myc-DDK Symbol: CYP2F1 Synonyms: C2F1; CYP2F; CYPIIF1 Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 4 CYP2F1 (NM_000774) Human Tagged ORF Clone – RC223097 ORF Nucleotide >RC223097 representing NM_000774 Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGACAGCATAAGCACAGCCATCTTACTCCTGCTCCTGGCTCTCGTCTGTCTGCTCCTGACCCTAAGCT CAAGAGATAAGGGAAAGCTGCCTCCGGGACCCAGACCCCTCTCAATCCTGGGAAACCTGCTGCTGCTTTG CTCCCAAGACATGCTGACTTCTCTCACTAAGCTGAGCAAGGAGTATGGCTCCATGTACACAGTGCACCTG GGACCCAGGCGGGTGGTGGTCCTCAGCGGGTACCAAGCTGTGAAGGAGGCCCTGGTGGACCAGGGAGAGG AGTTTAGTGGCCGCGGTGACTACCCTGCCTTTTTCAACTTTACCAAGGGCAATGGCATCGCCTTCTCCAG TGGGGATCGATGGAAGGTCCTGAGACAGTTCTCTATCCAGATTCTACGGAATTTCGGGATGGGGAAGAGA AGCATTGAGGAGCGAATCCTAGAGGAGGGCAGCTTCCTGCTGGCGGAGCTGCGGAAAACTGAAGGCGAGC CCTTTGACCCCACGTTTGTGCTGAGTCGCTCAGTGTCCAACATTATCTGTTCCGTGCTCTTCGGCAGCCG CTTCGACTATGATGATGAGCGTCTGCTCACCATTATCCGCCTTATCAATGACAACTTCCAAATCATGAGC -

Metabolic Activation and Toxicological Evaluation of Polychlorinated Biphenyls in Drosophila Melanogaster T
www.nature.com/scientificreports OPEN Metabolic activation and toxicological evaluation of polychlorinated biphenyls in Drosophila melanogaster T. Idda1,7, C. Bonas1,7, J. Hofmann1, J. Bertram1, N. Quinete1,2, T. Schettgen1, K. Fietkau3, A. Esser1, M. B. Stope4, M. M. Leijs3, J. M. Baron3, T. Kraus1, A. Voigt5,6 & P. Ziegler1* Degradation of polychlorinated biphenyls (PCBs) is initiated by cytochrome P450 (CYP) enzymes and includes PCB oxidation to OH-metabolites, which often display a higher toxicity than their parental compounds. In search of an animal model refecting PCB metabolism and toxicity, we tested Drosophila melanogaster, a well-known model system for genetics and human disease. Feeding Drosophila with lower chlorinated (LC) PCB congeners 28, 52 or 101 resulted in the detection of a human-like pattern of respective OH-metabolites in fy lysates. Feeding fies high PCB 28 concentrations caused lethality. Thus we silenced selected CYPs via RNA interference and analyzed the efect on PCB 28-derived metabolite formation by assaying 3-OH-2′,4,4′-trichlorobiphenyl (3-OHCB 28) and 3′-OH-4′,4,6′-trichlorobiphenyl (3′-OHCB 28) in fy lysates. We identifed several drosophila CYPs (dCYPs) whose knockdown reduced PCB 28-derived OH-metabolites and suppressed PCB 28 induced lethality including dCYP1A2. Following in vitro analysis using a liver-like CYP-cocktail, containing human orthologues of dCYP1A2, we confrm human CYP1A2 as a PCB 28 metabolizing enzyme. PCB 28-induced mortality in fies was accompanied by locomotor impairment, a common phenotype of neurodegenerative disorders. Along this line, we show PCB 28-initiated caspase activation in diferentiated fy neurons. -

Endogenous Protein Interactome of Human UDP-Glucuronosyltransferases Exposed by Untargeted Proteomics
ORIGINAL RESEARCH published: 03 February 2017 doi: 10.3389/fphar.2017.00023 Endogenous Protein Interactome of Human UDP-Glucuronosyltransferases Exposed by Untargeted Proteomics Michèle Rouleau, Yannick Audet-Delage, Sylvie Desjardins, Mélanie Rouleau, Camille Girard-Bock and Chantal Guillemette * Pharmacogenomics Laboratory, Canada Research Chair in Pharmacogenomics, Faculty of Pharmacy, Centre Hospitalier Universitaire de Québec Research Center, Laval University, Québec, QC, Canada The conjugative metabolism mediated by UDP-glucuronosyltransferase enzymes (UGTs) significantly influences the bioavailability and biological responses of endogenous molecule substrates and xenobiotics including drugs. UGTs participate in the regulation of cellular homeostasis by limiting stress induced by toxic molecules, and by Edited by: controlling hormonal signaling networks. Glucuronidation is highly regulated at genomic, Yuji Ishii, transcriptional, post-transcriptional and post-translational levels. However, the UGT Kyushu University, Japan protein interaction network, which is likely to influence glucuronidation, has received Reviewed by: little attention. We investigated the endogenous protein interactome of human UGT1A Ben Lewis, Flinders University, Australia enzymes in main drug metabolizing non-malignant tissues where UGT expression is Shinichi Ikushiro, most prevalent, using an unbiased proteomics approach. Mass spectrometry analysis Toyama Prefectural University, Japan of affinity-purified UGT1A enzymes and associated protein complexes in liver, -

Strong Correlation Between Air-Liquid Interface Cultures and in Vivo Transcriptomics of Nasal Brush Biopsy
Am J Physiol Lung Cell Mol Physiol 318: L1056–L1062, 2020. First published April 1, 2020; doi:10.1152/ajplung.00050.2020. RAPID REPORT Translational Physiology Strong correlation between air-liquid interface cultures and in vivo transcriptomics of nasal brush biopsy X Baishakhi Ghosh,1 Bongsoo Park,1 Debarshi Bhowmik,2 Kristine Nishida,3 Molly Lauver,3 Nirupama Putcha,3 Peisong Gao,4 Murugappan Ramanathan, Jr.,5 Nadia Hansel,3 Shyam Biswal,1 and Venkataramana K. Sidhaye1,3 1Department of Environmental Health and Engineering, Johns Hopkins Bloomberg School of Public Health, Baltimore, Maryland; 2Department of Biology, Johns Hopkins University, Baltimore, Maryland; 3Department of Pulmonary and Critical Care Medicine, Johns Hopkins School of Medicine, Baltimore, Maryland; 4Division of Allergy and Clinical Immunology, Johns Hopkins School of Medicine, Baltimore, Maryland; and 5Department of Otolaryngology-Head and Neck Surgery, Johns Hopkins School of Medicine, Baltimore, Maryland Submitted 18 February 2020; accepted in final form 24 March 2020 Ghosh B, Park B, Bhowmik D, Nishida K, Lauver M, Putcha N, RNA sequencing to determine the correlation between ALI- Gao P, Ramanathan M Jr, Hansel N, Biswal S, Sidhaye VK. cultured epithelial cells and epithelial cells obtained from nasal Strong correlation between air-liquid interface cultures and in vivo brushing and identify differences that may arise as a result of transcriptomics of nasal brush biopsy. Am J Physiol Lung Cell Mol redifferentiation. Physiol 318: L1056–L1062, 2020. First published April 1, 2020; doi:10.1152/ajplung.00050.2020.—Air-liquid interface (ALI) cultures METHODS are ex vivo models that are used extensively to study the epithelium of patients with chronic respiratory diseases. -
Figure S1. Reverse Transcription‑Quantitative PCR Analysis of ETV5 Mrna Expression Levels in Parental and ETV5 Stable Transfectants
Figure S1. Reverse transcription‑quantitative PCR analysis of ETV5 mRNA expression levels in parental and ETV5 stable transfectants. (A) Hec1a and Hec1a‑ETV5 EC cell lines; (B) Ishikawa and Ishikawa‑ETV5 EC cell lines. **P<0.005, unpaired Student's t‑test. EC, endometrial cancer; ETV5, ETS variant transcription factor 5. Figure S2. Survival analysis of sample clusters 1‑4. Kaplan Meier graphs for (A) recurrence‑free and (B) overall survival. Survival curves were constructed using the Kaplan‑Meier method, and differences between sample cluster curves were analyzed by log‑rank test. Figure S3. ROC analysis of hub genes. For each gene, ROC curve (left) and mRNA expression levels (right) in control (n=35) and tumor (n=545) samples from The Cancer Genome Atlas Uterine Corpus Endometrioid Cancer cohort are shown. mRNA levels are expressed as Log2(x+1), where ‘x’ is the RSEM normalized expression value. ROC, receiver operating characteristic. Table SI. Clinicopathological characteristics of the GSE17025 dataset. Characteristic n % Atrophic endometrium 12 (postmenopausal) (Control group) Tumor stage I 91 100 Histology Endometrioid adenocarcinoma 79 86.81 Papillary serous 12 13.19 Histological grade Grade 1 30 32.97 Grade 2 36 39.56 Grade 3 25 27.47 Myometrial invasiona Superficial (<50%) 67 74.44 Deep (>50%) 23 25.56 aMyometrial invasion information was available for 90 of 91 tumor samples. Table SII. Clinicopathological characteristics of The Cancer Genome Atlas Uterine Corpus Endometrioid Cancer dataset. Characteristic n % Solid tissue normal 16 Tumor samples Stagea I 226 68.278 II 19 5.740 III 70 21.148 IV 16 4.834 Histology Endometrioid 271 81.381 Mixed 10 3.003 Serous 52 15.616 Histological grade Grade 1 78 23.423 Grade 2 91 27.327 Grade 3 164 49.249 Molecular subtypeb POLE 17 7.328 MSI 65 28.017 CN Low 90 38.793 CN High 60 25.862 CN, copy number; MSI, microsatellite instability; POLE, DNA polymerase ε. -

Resveratrol Inhibits Cell Cycle Progression by Targeting Aurora Kinase a and Polo-Like Kinase 1 in Breast Cancer Cells
3696 ONCOLOGY REPORTS 35: 3696-3704, 2016 Resveratrol inhibits cell cycle progression by targeting Aurora kinase A and Polo-like kinase 1 in breast cancer cells RUBICELI MEDINA-AGUILAR1, LAURENCE A. Marchat2, ELENA ARECHAGA OCAMPO3, Patricio GARIGLIO1, JAIME GARCÍA MENA1, NICOLÁS VILLEGAS SEPÚlveda4, MACARIO MartÍNEZ CASTILLO4 and CÉSAR LÓPEZ-CAMARILLO5 1Department of Genetics and Molecular Biology, CINVESTAV-IPN, Mexico D.F.; 2Molecular Biomedicine Program and Biotechnology Network, National School of Medicine and Homeopathy, National Polytechnic Institute, Mexico D.F.; 3Natural Sciences Department, Metropolitan Autonomous University, Mexico D.F.; 4Department of Molecular Biomedicine, CINVESTAV-IPN, Mexico D.F.; 5Oncogenomics and Cancer Proteomics Laboratory, Universidad Autónoma de la Ciudad de México, Mexico D.F., Mexico Received December 4, 2015; Accepted January 8, 2016 DOI: 10.3892/or.2016.4728 Abstract. The Aurora protein kinase (AURKA) and the MDA-MB-231 and MCF-7 cells. By western blot assays, we Polo-like kinase-1 (PLK1) activate the cell cycle, and they confirmed that resveratrol suppressed AURKA, CCND1 and are considered promising druggable targets in cancer CCNB1 at 24 and 48 h. In summary, we showed for the first time therapy. However, resistance to chemotherapy and to specific that resveratrol regulates cell cycle progression by targeting small-molecule inhibitors is common in cancer patients; thus AURKA and PLK1. Our findings highlight the potential use of alternative therapeutic approaches are needed to overcome resveratrol as an adjuvant therapy for breast cancer. clinical resistance. Here, we showed that the dietary compound resveratrol suppressed the cell cycle by targeting AURKA Introduction and PLK1 kinases. First, we identified genes modulated by resveratrol using a genome-wide analysis of gene expression Cancer development results from the interaction between in MDA-MB-231 breast cancer cells. -
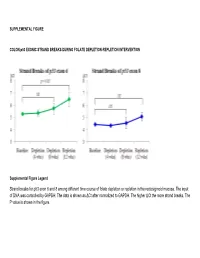
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA.