Downloaded Articles
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Urokinase Receptor Induces a Mesenchymal Gene Expression Signature in Glioblastoma Cells and Promotes Tumor Cell Survival In
www.nature.com/scientificreports OPEN The Urokinase Receptor Induces a Mesenchymal Gene Expression Signature in Glioblastoma Cells and Received: 20 October 2017 Accepted: 2 February 2018 Promotes Tumor Cell Survival in Published: xx xx xxxx Neurospheres Andrew S. Gilder1, Letizia Natali1, Danielle M. Van Dyk1, Cristina Zalfa1, Michael A. Banki1, Donald P. Pizzo1, Huawei Wang 1, Richard L. Klemke1, Elisabetta Mantuano 1,2 & Steven L. Gonias1 PLAUR encodes the urokinase receptor (uPAR), which promotes cell survival, migration, and resistance to targeted cancer therapeutics in glioblastoma cells in culture and in mouse model systems. Herein, we show that patient survival correlates inversely with PLAUR mRNA expression in gliomas of all grades, in glioblastomas, and in the subset of glioblastomas that demonstrate the mesenchymal gene expression signature. PLAUR clusters with genes that defne the more aggressive mesenchymal subtype in transcriptome profles of glioblastoma tissue and glioblastoma cells in neurospheres, which are enriched for multipotent cells with stem cell-like qualities. When PLAUR was over-expressed or silenced in glioblastoma cells, neurosphere growth and expression of mesenchymal subtype biomarkers correlated with uPAR abundance. uPAR also promoted glioblastoma cell survival in neurospheres. Constitutively-active EGF Receptor (EGFRvIII) promoted neurosphere growth; however, unlike uPAR, EGFRvIII did not induce the mesenchymal gene expression signature. Immunohistochemical analysis of human glioblastomas showed that uPAR is typically expressed by a small sub-population of the cancer cells; it is thus reasonable to conclude that this subpopulation of cells is responsible for the efects of PLAUR on patient survival. We propose that uPAR-expressing glioblastoma cells demonstrate a mesenchymal gene signature, an increased capacity for cell survival, and stem cell-like properties. -

Cómo Citar El Artículo Número Completo Más Información Del
Revista de Biología Tropical ISSN: 0034-7744 ISSN: 0034-7744 Universidad de Costa Rica Alpízar-Alpízar, Warner; Malespín-Bendaña, Wendy; Une, Clas; Ramírez-Mayorga, Vanessa Relevance of the plasminogen activation system in the pathogenesis and progression of gastric cancer Revista de Biología Tropical, vol. 66, núm. 1, 2018, pp. 28-47 Universidad de Costa Rica DOI: 10.15517/rbt.v66i1.29014 Disponible en: http://www.redalyc.org/articulo.oa?id=44955366003 Cómo citar el artículo Número completo Sistema de Información Científica Redalyc Más información del artículo Red de Revistas Científicas de América Latina y el Caribe, España y Portugal Página de la revista en redalyc.org Proyecto académico sin fines de lucro, desarrollado bajo la iniciativa de acceso abierto Relevance of the plasminogen activation system in the pathogenesis and progression of gastric cancer Warner Alpízar-Alpízar1,2*, Wendy Malespín-Bendaña3, Clas Une3 & Vanessa Ramírez-Mayorga3,4 1. Centro de Investigación en Estructuras Microscópicas (CIEMic), Universidad de Costa Rica, San José, Costa Rica; [email protected] 2. Departamento de Bioquímica, Escuela de Medicina, Universidad de Costa Rica, San José, Costa Rica. 3. Instituto de Investigaciones en Salud (INISA), Universidad de Costa Rica, San José, Costa Rica; [email protected], [email protected], [email protected] 4. Sección de Nutrición Pública, Escuela de Nutrición, Universidad de Costa Rica, San José, Costa Rica. * Correspondence Received 14-VII-2017. Corrected 18-X-2017. Accepted 16-XI-2017. Abstract: Gastric cancer is ranked as the third death-causing cancer and one of the most incident malignancies worldwide. -

Receptor-Like 1 and -Like 2 Is an Endogenous Ligand for Formyl Peptide Through a Urokinase Receptor Epitope That Urokinase Induc
Urokinase Induces Basophil Chemotaxis through a Urokinase Receptor Epitope That Is an Endogenous Ligand for Formyl Peptide Receptor-Like 1 and -Like 2 This information is current as of May 10, 2019. Amato de Paulis, Nunzia Montuori, Nella Prevete, Isabella Fiorentino, Francesca Wanda Rossi, Valeria Visconte, Guido Rossi, Gianni Marone and Pia Ragno J Immunol 2004; 173:5739-5748; ; doi: 10.4049/jimmunol.173.9.5739 http://www.jimmunol.org/content/173/9/5739 Downloaded from References This article cites 65 articles, 33 of which you can access for free at: http://www.jimmunol.org/content/173/9/5739.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on May 10, 2019 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2004 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Urokinase Induces Basophil Chemotaxis through a Urokinase Receptor Epitope That Is an Endogenous Ligand for Formyl Peptide Receptor-Like 1 and -Like 21 Amato de Paulis,* Nunzia Montuori,† Nella Prevete,* Isabella Fiorentino,* Francesca Wanda Rossi,* Valeria Visconte,‡ Guido Rossi,‡ Gianni Marone,2* and Pia Ragno† Basophils circulate in the blood and are able to migrate into tissues at sites of inflammation. -

The Urokinase Receptor: a Multifunctional Receptor in Cancer Cell Biology
International Journal of Molecular Sciences Review The Urokinase Receptor: A Multifunctional Receptor in Cancer Cell Biology. Therapeutic Implications Anna Li Santi 1,†, Filomena Napolitano 2,†, Nunzia Montuori 2 and Pia Ragno 1,* 1 Department of Chemistry and Biology, University of Salerno, Fisciano, 84084 Salerno, Italy; [email protected] 2 Department of Translational Medical Sciences, “Federico II” University, 80135 Naples, Italy; fi[email protected] (F.N.); [email protected] (N.M.) * Correspondence: [email protected] † Equal contribution. Abstract: Proteolysis is a key event in several biological processes; proteolysis must be tightly con- trolled because its improper activation leads to dramatic consequences. Deregulation of proteolytic activity characterizes many pathological conditions, including cancer. The plasminogen activation (PA) system plays a key role in cancer; it includes the serine-protease urokinase-type plasminogen activator (uPA). uPA binds to a specific cellular receptor (uPAR), which concentrates proteolytic activity at the cell surface, thus supporting cell migration. However, a large body of evidence clearly showed uPAR involvement in the biology of cancer cell independently of the proteolytic activity of its ligand. In this review we will first describe this multifunctional molecule and then we will discuss how uPAR can sustain most of cancer hallmarks, which represent the biological capabilities acquired during the multistep cancer development. Finally, we will illustrate the main data available in the literature on uPAR as a cancer biomarker and a molecular target in anti-cancer therapy. Citation: Li Santi, A.; Napolitano, F.; Montuori, N.; Ragno, P. The Keywords: urokinase receptor; uPAR; cancer hallmarks Urokinase Receptor: A Multifunctional Receptor in Cancer Cell Biology. -

Folate Receptor Β Regulates Integrin Cd11b/CD18 Adhesion of a Macrophage Subset to Collagen
Folate Receptor β Regulates Integrin CD11b/CD18 Adhesion of a Macrophage Subset to Collagen This information is current as Christian Machacek, Verena Supper, Vladimir Leksa, Goran of September 24, 2021. Mitulovic, Andreas Spittler, Karel Drbal, Miloslav Suchanek, Anna Ohradanova-Repic and Hannes Stockinger J Immunol 2016; 197:2229-2238; Prepublished online 17 August 2016; doi: 10.4049/jimmunol.1501878 Downloaded from http://www.jimmunol.org/content/197/6/2229 Supplementary http://www.jimmunol.org/content/suppl/2016/08/17/jimmunol.150187 Material 8.DCSupplemental http://www.jimmunol.org/ References This article cites 49 articles, 23 of which you can access for free at: http://www.jimmunol.org/content/197/6/2229.full#ref-list-1 Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision by guest on September 24, 2021 • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Folate Receptor b Regulates Integrin CD11b/CD18 Adhesion of a Macrophage Subset to Collagen Christian Machacek,* Verena Supper,* Vladimir Leksa,*,† Goran Mitulovic,‡ Andreas Spittler,x Karel Drbal,{,1 Miloslav Suchanek,{ Anna Ohradanova-Repic,* and Hannes Stockinger* Folate, also known as vitamin B9, is necessary for essential cellular functions such as DNA synthesis, repair, and methylation. -
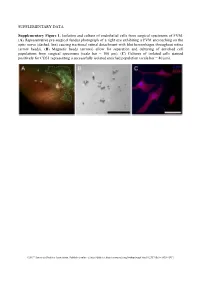
Supplementary Figures and Tables
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Soluble Urokinase Plasminogen Activator Receptor Predicts
1112 Diabetes Care Volume 42, June 2019 Viktor Rotbain Curovic,1 Simone Theilade,1 Soluble Urokinase Plasminogen Signe A. Winther,1 Nete Tofte,1 Jesper Eugen-Olsen,2 Frederik Persson,1 Activator Receptor Predicts Tine W. Hansen,1 Jørgen Jeppesen,3,4 and Cardiovascular Events, Kidney Peter Rossing1,4 Function Decline, and Mortality in Patients With Type 1 Diabetes Diabetes Care 2019;42:1112–1119 | https://doi.org/10.2337/dc18-1427 OBJECTIVE Soluble urokinase plasminogen activator receptor (suPAR) is an important in- flammatory biomarker implicated in endothelial and podocyte dysfunction. How- ever, suPAR’s predictive qualities for complications in type 1 diabetes have yet to be determined. We investigated the prognostic value of suPAR for the development of cardiovascularevents,declineinrenalfunction, andmortalityinpatientswith type1 diabetes. RESEARCH DESIGN AND METHODS We included 667 patients with type 1 diabetes with various degrees of albuminuria inaprospective study. End points were cardiovascular events (cardiovascular death, nonfatal acute myocardial infarction, nonfatal stroke, or coronary or peripheral arterial interventions), estimated glomerular filtration rate (eGFR) decline ‡30%, progressionfromlowertohigheralbuminuricstate,developmentofend-stagerenal disease (ESRD), and mortality. Follow-up was 5.2–6.2 years. Results were adjusted for known risk factors. Hazard ratios (HRs) are presented per doubling of suPAR with 95% CI. Relative integrated discrimination improvement (rIDI) was calculated. 1Steno Diabetes Center Copenhagen, -

Conformation Based Reagents for the Detection of Disease-Associated Prion Protein
CONFORMATION BASED REAGENTS FOR THE DETECTION OF DISEASE-ASSOCIATED PRION PROTEIN By KRISTEN-LOUISE HATCHER Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Dissertation Advisor: Shu G. Chen, Ph.D. Department of Pathology CASE WESTERN RESERVE UNIVERSITY May, 2009 CASE WESTERN RESERVE UNIVERSITY SCHOOL OF GRADUATE STUDIES We hereby approve the thesis/dissertation of _____________________________________________________ candidate for the ______________________degree *. (signed)_______________________________________________ (chair of the committee) ________________________________________________ ________________________________________________ ________________________________________________ ________________________________________________ ________________________________________________ (date) _______________________ *We also certify that written approval has been obtained for any proprietary material contained therein. To Grandad Dee, for teaching me to love science, and Grandad Hatcher, for always believing I could do it Table of Contents List of Tables 3 List of Figures 4 Acknowledgements 5 List of Abbreviations 6 Abstract 7 Chapter 1: Introduction 1.1 The Prion Protein 9 1.1.1 The Codon 129 Polymorphism 11 1.2 The Pathogenic Prion Protein 12 1.2.1 Prion Conversion 12 1.2.2 PK Sensitive PrPSc 14 1.2.3 Prion Strains 15 1.3 Creutzfeldt-Jakob Disease 16 1.3.1 Sporadic Creutzfeldt-Jakob Disease 16 1.3.2 Familial Creutzfeldt-Jakob Disease 19 1.3.3 Acquired Creutzfeldt-Jakob Disease 22 1.3.3.1 Iatrogenic -

The Low-Density Lipoprotein Receptor-Related Protein 1 (LRP1) Mediates the Endocytosis of the Cellular Prion Protein David R Taylor, Nigel M Hooper
The low-density lipoprotein receptor-related protein 1 (LRP1) mediates the endocytosis of the cellular prion protein David R Taylor, Nigel M Hooper To cite this version: David R Taylor, Nigel M Hooper. The low-density lipoprotein receptor-related protein 1 (LRP1) mediates the endocytosis of the cellular prion protein. Biochemical Journal, Portland Press, 2006, 402 (1), pp.17-23. 10.1042/BJ20061736. hal-00478699 HAL Id: hal-00478699 https://hal.archives-ouvertes.fr/hal-00478699 Submitted on 30 Apr 2010 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Biochemical Journal Immediate Publication. Published on 8 Dec 2006 as manuscript BJ20061736 The low-density lipoprotein receptor-related protein 1 (LRP1) mediates the endocytosis of the cellular prion protein David R. Taylor and Nigel M. Hooper* Proteolysis Research Group Institute of Molecular and Cellular Biology Faculty of Biological Sciences and Leeds Institute of Genetics, Health and Therapeutics University of Leeds Leeds LS2 9JT UK * To whom correspondence should be addressed: tel. +44 113 343 3163; fax. +44 113 343 3167; e-mail: [email protected] Running title: LRP1 mediates the endocytosis of PrP Key words: amyloid precursor protein, copper, endocytosis, low-density lipoprotein receptor-related protein-1, prion, receptor associated protein. -

Adhesion (Cd11b/CD18) in Regulating Neutrophil Mac-1/Complement Receptor Type 3 Function of the Lectin Domain Of
Function of the Lectin Domain of Mac-1/Complement Receptor Type 3 (CD11b/CD18) in Regulating Neutrophil Adhesion This information is current as of September 25, 2021. Yu Xia, Gita Borland, Jibiao Huang, Ikuko F. Mizukami, Howard R. Petty, Robert F. Todd III and Gordon D. Ross J Immunol 2002; 169:6417-6426; ; doi: 10.4049/jimmunol.169.11.6417 http://www.jimmunol.org/content/169/11/6417 Downloaded from References This article cites 60 articles, 38 of which you can access for free at: http://www.jimmunol.org/content/169/11/6417.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on September 25, 2021 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2002 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Function of the Lectin Domain of Mac-1/Complement Receptor Type 3 (CD11b/CD18) in Regulating Neutrophil Adhesion1 Yu Xia,2* Gita Borland,* Jibiao Huang,† Ikuko F. -

Expression of Xv Integrins and Vitronectin Receptor Identity in Breast Cancer Cells
British Joumal of Cancer (1998) 77(4), 530-536 © 1998 Cancer Research Campaign Expression of xv integrins and vitronectin receptor identity in breast cancer cells T Meyer, JF Marshall and IR Hart Richard Dimbleby Department of Cancer Research/lCRF Laboratory, St Thomas' Hospital, Lambeth Palace Road, London SE1 7EH, UK Summary In the present study we have used fluorocytometry and immunoprecipitation to characterize the expression of av-containing integrins in a panel of eight human breast cancer cell lines and one normal human mammary epithelial line. We show that the classical vitronectin receptor avO3 is expressed in only one cell line (MDA-MB-231), whereas avP5 is expressed on all breast cancer cell lines and av,1 is expressed on the majority. Using adherence assays to purified ligands in the presence and absence of function-blocking monoclonal antibodies, we have demonstrated that avJ5 mediates adhesion to vitronectin in the majority of these cells. In one cell line, ZR75-1, avp1 contributes significantly to adhesion to immobilized vitronectin. The formation of focal adhesions containing the av and P1 subunits on vitronectin is also demonstrated by indirect immunofluorescence. Keywords: Breast cancer; integrins; cell adhesion; vitronectin; extracellular matrix; fluorocytometry Breast cancer affects 1 in 12 women in the UK and accounts for bind to the substrate vitronectin. Some of these receptors have 18% of female malignant disease worldwide. Of those who present other ligands, most notably the promiscuous avP3, so that the with apparently operable disease, more than half will die from composition of the av-containing heterodimers can affect cell metastatic disease. -

Table S3: List of EGFR Pathway-Regulated Genes. Gene Name Fold Fold
Table S3: List of EGFR pathway-regulated genes. Gene Name Fold Fold EGF4h/Control EGF12h/Control Up-regulated by EGFR activation Increased at 4 hours but declined at 12 hours A kinase (PRKA) anchor protein (gravin) 12 7.67 1.58 Ab2-427 3.05 0.99 acyl-CoA synthetase long-chain family member 1 3.88 0.94 acyl-CoA synthetase long-chain family member 4 6.25 3.58 adipose differentiation-related protein 5.46 3.51 Aldehyde dehydrogenase family 1, subfamily A3 38.45 1.78 amphiregulin 77.79 27.77 arginase 1 4.10 2.06 arginosuccinate synthetase 3.00 1.19 aryl hydrocarbon receptor 5.03 1.55 ATPase, Ca++ transporting, plasma membrane 1 4.08 2.31 basic helix-loop-helix domain containing, class B2 7.86 4.12 Basophilic leukemia expressed sequence 06 (Bles06) 2.89 1.17 BH3 interacting domain death agonist 3.09 1.17 brain-specific angiogenesis inhibitor 1-associated protein 2 7.73 2.80 breast cancer anti-estrogen resistance 3 (predicted) 3.71 1.85 bridging integrator 1 6.07 2.08 cellular retinoic acid binding protein 2 2.47 1.11 charged amino acid rich leucine zipper 1 (predicted) 2.22 1.25 chemokine (C-C motif) ligand 2 3.29 1.34 chemokine (C-C motif) ligand 20 5.91 0.98 Chemotactic protein-3 3.82 -2.1 cryptochrome 1 (photolyase-like) 2.99 0.51 cyclin H 2.26 1.34 cyclin-dependent kinase inhibitor 2B (p15, inhibits CDK4) 3.25 1.25 cysteine knot superfamily 1, BMP antagonist 1 20.20 3.28 cytokine receptor-like factor 1 (predicted) 5.43 1.23 death-associated kinase 2 (predicted) 5.03 3.07 DEAD (Asp-Glu-Ala-Asp) box polypeptide 27 (predicted) 2.46 1.38 decay