A Scale-Based Approach to Finding Effective Dimensionality in Manifold
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
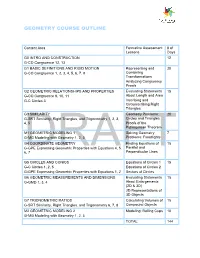
Geometry Course Outline
GEOMETRY COURSE OUTLINE Content Area Formative Assessment # of Lessons Days G0 INTRO AND CONSTRUCTION 12 G-CO Congruence 12, 13 G1 BASIC DEFINITIONS AND RIGID MOTION Representing and 20 G-CO Congruence 1, 2, 3, 4, 5, 6, 7, 8 Combining Transformations Analyzing Congruency Proofs G2 GEOMETRIC RELATIONSHIPS AND PROPERTIES Evaluating Statements 15 G-CO Congruence 9, 10, 11 About Length and Area G-C Circles 3 Inscribing and Circumscribing Right Triangles G3 SIMILARITY Geometry Problems: 20 G-SRT Similarity, Right Triangles, and Trigonometry 1, 2, 3, Circles and Triangles 4, 5 Proofs of the Pythagorean Theorem M1 GEOMETRIC MODELING 1 Solving Geometry 7 G-MG Modeling with Geometry 1, 2, 3 Problems: Floodlights G4 COORDINATE GEOMETRY Finding Equations of 15 G-GPE Expressing Geometric Properties with Equations 4, 5, Parallel and 6, 7 Perpendicular Lines G5 CIRCLES AND CONICS Equations of Circles 1 15 G-C Circles 1, 2, 5 Equations of Circles 2 G-GPE Expressing Geometric Properties with Equations 1, 2 Sectors of Circles G6 GEOMETRIC MEASUREMENTS AND DIMENSIONS Evaluating Statements 15 G-GMD 1, 3, 4 About Enlargements (2D & 3D) 2D Representations of 3D Objects G7 TRIONOMETRIC RATIOS Calculating Volumes of 15 G-SRT Similarity, Right Triangles, and Trigonometry 6, 7, 8 Compound Objects M2 GEOMETRIC MODELING 2 Modeling: Rolling Cups 10 G-MG Modeling with Geometry 1, 2, 3 TOTAL: 144 HIGH SCHOOL OVERVIEW Algebra 1 Geometry Algebra 2 A0 Introduction G0 Introduction and A0 Introduction Construction A1 Modeling With Functions G1 Basic Definitions and Rigid -
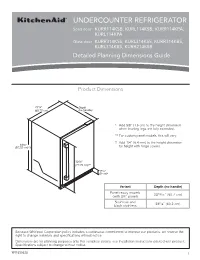
Dimension Guide
UNDERCOUNTER REFRIGERATOR Solid door KURR114KSB, KURL114KSB, KURR114KPA, KURL114KPA Glass door KURR314KSS, KURL314KSS, KURR314KBS, KURL314KBS, KURR214KSB Detailed Planning Dimensions Guide Product Dimensions 237/8” Depth (60.72 cm) (no handle) * Add 5/8” (1.6 cm) to the height dimension when leveling legs are fully extended. ** For custom panel models, this will vary. † Add 1/4” (6.4 mm) to the height dimension 343/8” (87.32 cm)*† for height with hinge covers. 305/8” (77.75 cm)** 39/16” (9 cm)* Variant Depth (no handle) Panel ready models 2313/16” (60.7 cm) (with 3/4” panel) Stainless and 235/8” (60.2 cm) black stainless Because Whirlpool Corporation policy includes a continuous commitment to improve our products, we reserve the right to change materials and specifications without notice. Dimensions are for planning purposes only. For complete details, see Installation Instructions packed with product. Specifications subject to change without notice. W11530525 1 Panel ready models Stainless and black Dimension Description (with 3/4” panel) stainless models A Width of door 233/4” (60.3 cm) 233/4” (60.3 cm) B Width of the grille 2313/16” (60.5 cm) 2313/16” (60.5 cm) C Height to top of handle ** 311/8” (78.85 cm) Width from side of refrigerator to 1 D handle – door open 90° ** 2 /3” (5.95 cm) E Depth without door 2111/16” (55.1 cm) 2111/16” (55.1 cm) F Depth with door 2313/16” (60.7 cm) 235/8” (60.2 cm) 7 G Depth with handle ** 26 /16” (67.15 cm) H Depth with door open 90° 4715/16” (121.8 cm) 4715/16” (121.8 cm) **For custom panel models, this will vary. -

Spectral Dimensions and Dimension Spectra of Quantum Spacetimes
PHYSICAL REVIEW D 102, 086003 (2020) Spectral dimensions and dimension spectra of quantum spacetimes † Michał Eckstein 1,2,* and Tomasz Trześniewski 3,2, 1Institute of Theoretical Physics and Astrophysics, National Quantum Information Centre, Faculty of Mathematics, Physics and Informatics, University of Gdańsk, ulica Wita Stwosza 57, 80-308 Gdańsk, Poland 2Copernicus Center for Interdisciplinary Studies, ulica Szczepańska 1/5, 31-011 Kraków, Poland 3Institute of Theoretical Physics, Jagiellonian University, ulica S. Łojasiewicza 11, 30-348 Kraków, Poland (Received 11 June 2020; accepted 3 September 2020; published 5 October 2020) Different approaches to quantum gravity generally predict that the dimension of spacetime at the fundamental level is not 4. The principal tool to measure how the dimension changes between the IR and UV scales of the theory is the spectral dimension. On the other hand, the noncommutative-geometric perspective suggests that quantum spacetimes ought to be characterized by a discrete complex set—the dimension spectrum. We show that these two notions complement each other and the dimension spectrum is very useful in unraveling the UV behavior of the spectral dimension. We perform an extended analysis highlighting the trouble spots and illustrate the general results with two concrete examples: the quantum sphere and the κ-Minkowski spacetime, for a few different Laplacians. In particular, we find that the spectral dimensions of the former exhibit log-periodic oscillations, the amplitude of which decays rapidly as the deformation parameter tends to the classical value. In contrast, no such oscillations occur for either of the three considered Laplacians on the κ-Minkowski spacetime. DOI: 10.1103/PhysRevD.102.086003 I. -

Zero-Dimensional Symmetry
Snapshots of modern mathematics № 3/2015 from Oberwolfach Zero-dimensional symmetry George Willis This snapshot is about zero-dimensional symmetry. Thanks to recent discoveries we now understand such symmetry better than previously imagined possible. While still far from complete, a picture of zero-dimen- sional symmetry is beginning to emerge. 1 An introduction to symmetry: spinning globes and infinite wallpapers Let’s begin with an example. Think of a sphere, for example a globe’s surface. Every point on it is specified by two parameters, longitude and latitude. This makes the sphere a two-dimensional surface. You can rotate the globe along an axis through the center; the object you obtain after the rotation still looks like the original globe (although now maybe New York is where the Mount Everest used to be), meaning that the sphere has rotational symmetry. Each rotation is prescribed by the latitude and longitude where the axis cuts the southern hemisphere, and by an angle through which it rotates the sphere. 1 These three parameters specify all rotations of the sphere, which thus has three-dimensional rotational symmetry. In general, a symmetry may be viewed as being a transformation (such as a rotation) that leaves an object looking unchanged. When one transformation is followed by a second, the result is a third transformation that is called the product of the other two. The collection of symmetries and their product 1 Note that we include the rotation through the angle 0, that is, the case where the globe actually does not rotate at all. 1 operation forms an algebraic structure called a group 2 . -
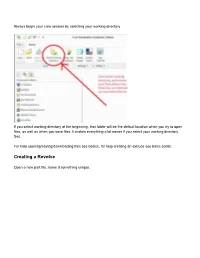
Creating a Revolve
Always begin your creo session by selecting your working directory If you select working directory at the beginning, that folder will be the default location when you try to open files, as well as when you save files. It makes everything a lot easier if you select your working directory first. For help opening/saving/downloading files see basics, for help creating an extrude see basic solids. Creating a Revolve Open a new part file, name it something unique. Choose a plane to sketch on Go to sketch view (if you don’t know where that is see Basic Solids) Move your cursor so the centerline snaps to the horizontal line as shown above You may now begin your sketch I have just sketched a random shape Sketch Tips: ● Your shape MUST be closed ● If you didn’t put a centerline in, you will get radial instead of diameter dimensions (in general this is bad) ● Remember this is being revolved so you are only sketching the profile on one side of the center line. If you need to put in diameter dimensions: Click normal, click the line or point you want the dimension for, click the centerline, and click the same line/point that you clicked the first time AGAIN, and then middle mouse button where you want the dimension to be placed. After your sketch is done, click the checkmark to get out of sketch, then click the checkmark again to complete the revolve The part in the sketch will look like this: . -

Why Observable Space Is Three Dimensional
Adv. Studies Theor. Phys., Vol. 8, 2014, no. 17, 689 – 700 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/astp.2014.4675 Why Observable Space Is Solely Three Dimensional Mario Rabinowitz Armor Research, 715 Lakemead Way Redwood City, CA 94062-3922, USA Copyright © 2014 Mario Rabinowitz. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Quantum (and classical) binding energy considerations in n-dimensional space indicate that atoms (and planets) can only exist in three-dimensional space. This is why observable space is solely 3-dimensional. Both a novel Virial theorem analysis, and detailed classical and quantum energy calculations for 3-space circular and elliptical orbits indicate that they have no orbital binding energy in greater than 3-space. The same energy equation also excludes the possibility of atom-like bodies in strictly 1 and 2-dimensions. A prediction is made that in the search for deviations from r2 of the gravitational force at sub-millimeter distances such a deviation must occur at < ~ 1010m (or < ~1012 m considering muoniom), since atoms would disintegrate if the curled up dimensions of string theory were larger than this. Callender asserts that the often-repeated claim in previous work that stable orbits are possible in only three dimensions is not even remotely established. The binding energy analysis herein avoids the pitfalls that Callender points out, as it circumvents stability issues. An uncanny quantum surprise is present in very high dimensions. -

Dimension Theory: Road to the Forth Dimension and Beyond
Dimension Theory: Road to the Fourth Dimension and Beyond 0-dimension “Behold yon miserable creature. That Point is a Being like ourselves, but confined to the non-dimensional Gulf. He is himself his own World, his own Universe; of any other than himself he can form no conception; he knows not Length, nor Breadth, nor Height, for he has had no experience of them; he has no cognizance even of the number Two; nor has he a thought of Plurality, for he is himself his One and All, being really Nothing. Yet mark his perfect self-contentment, and hence learn this lesson, that to be self-contented is to be vile and ignorant, and that to aspire is better than to be blindly and impotently happy.” ― Edwin A. Abbott, Flatland: A Romance of Many Dimensions 0-dimension Space of zero dimensions: A space that has no length, breadth or thickness (no length, height or width). There are zero degrees of freedom. The only “thing” is a point. = ∅ 0-dimension 1-dimension Space of one dimension: A space that has length but no breadth or thickness A straight or curved line. Drag a multitude of zero dimensional points in new (perpendicular) direction Make a “line” of points 1-dimension One degree of freedom: Can only move right/left (forwards/backwards) { }, any point on the number line can be described by one number 1-dimension How to visualize living in 1-dimension Stuck on an endless one-lane one-way road Inhabitants: points and line segments (intervals) Live forever between your front and back neighbor. -

DIMENSION* 0.10% Plus Fertilizer NOT for USE on Turf Being Grown for Sale Or Other Commercial Use As Sod, Or for Commercial Seed Production, Or for Research Purposes
DIMENSION* 0.10% Plus Fertilizer NOT FOR USE on turf being grown for sale or other commercial use as sod, or for commercial seed production, or for research purposes. In New York State this product may only be used by commercial applicators and Warm-Season Grasses at no more than 500 lb (0.5 lb of active ingredient) per acre per year (or 11.5 lb Common Name Scientific Name product per 1,000 ft sq per year) and is prohibited from use in Nassau and Bahiagrass Paspalum notatum Suffolk Counties. Bermudagrass Cynodon dactylon Contains LESCO® Poly Plus® Sulfur Coated Urea to provide a uniform growth Buffalograss*** Buchloe dactyloides with extended nitrogen feeding. Carpetgrass Axonopus affinis ACTIVE INGREDIENT: Centipedegrass Eremochloa ophiuroides Dithiopyr, 3,5-pyridinedicarbothioic acid, 2-(difluoromethyl)-4-(2-methylpropyl)- Kikuyugrass Pennisetum clandestinum 6-(trifluoromethyl)-S,S-dimethyl ester....................................................... 0.10% St. Augustinegrass Stenotaphrum secundatum INERT INGREDIENTS:...................................................................................... 99.90% Zoysiagrass Zoysia, japonica Total: ............................................................................................................... 100.00% DO NOT apply this product to Colonial Bentgrass (Agrostis tenuis) varieties. Product protected by U.S. Patent No. 4,692,184. Other patents pending. *Use of this product on certain varieties of Creeping Bentgrass, such as 'Cohansey', 'Carmen', Read the entire label before using this product. Use only according to label instructions. 'Seaside', and 'Washington' may result in undesirable turfgrass injury. Not all varieties of NOTICE: Before using this product, read the Use Precautions, Warranty Statements, Creeping Bentgrass have been tested. Directions for Use, and the Storage and Disposal Instructions. If the Warranty statements **Use of this product on certain varieties of Fine Fescue may result in undesirable turf injury. -

7 Dimensioning Section 7.1 Basic Dimensioning Principles Section 7.2 Dimensioning Techniques
7 Dimensioning Section 7.1 Basic Dimensioning Principles Section 7.2 Dimensioning Techniques Chapter Objectives • Add measurements, notes, and symbols to a technical drawing. • Apply ASME and ISO standards to dimen- sions and notes. • Differentiate between size dimen- sions and location dimensions. • Specify geometric tol- erances using symbols and notes. • Add dimensions to a drawing using board- drafting techniques. • Use a CAD system to add dimensions, notes, and geometric tolerances to a techni- cal drawing. Playing with Plastics Jonathan Ive says that engineers and designers can now do things with plastic that were previously impossible. What are the characteristics of plastic that give it this ability? 214 Drafting Career Jonathan Ive, Engineer What comes to mind when you think of a mobile phone that offers all these features: multimedia player, access to the Internet, camera, text messaging, and visual voicemail? Probably the iPhone designed by Jonathan Ive, senior vice president of industrial design at Apple Inc., and his product design team. Ive, recipient of many awards, is especially proud of what the iPod shuffl e represents. Originally shipped for $79, its aluminum body clips together with a tolerance of ±0.03 mm—remarkable precision. “I don’t think there’s ever been a product produced in such volume at that price … given so much time and care.… I hope that integrity is obvious.” Academic Skills and Abilities • Math • Science • English • Social Studies • Physics • Mechanical Drawing Career Pathways A bachelor’s degree in engineering is required for almost all entry-level engineering jobs. Some engineers must be licensed by all 50 states and the District of Columbia. -

Visualization of Surfaces in Four-Dimensional Space
Purdue University Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1990 Visualization of Surfaces in Four-Dimensional Space Christoph M. Hoffmann Purdue University, [email protected] Jianhua Zhou Report Number: 90-960 Hoffmann, Christoph M. and Zhou, Jianhua, "Visualization of Surfaces in Four-Dimensional Space" (1990). Department of Computer Science Technical Reports. Paper 814. https://docs.lib.purdue.edu/cstech/814 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. VISUALIZATION OF SURFACES IN FOUR·DIM:ENSIONAL SPACE Christoph M. Hoffman Jianhua Zhou CSD TR·960 May 1990 Visualization of Surfaces in Four-Dimensional Space * Christoph M. Hoffmann Jianhua Zhou Department of Computer Science Purdue University West Lafayette, IN 47907 Abstract We discuss some issues of displaying ~wo-dimensional surfaces in four-dimensional (4D) space, including the behavior of surface normals under projedion, the silhouette points due to the projection, and methods Cor object orientation and projection center specification. We have implemented an interactive 4D display system on z-butrer based graphics workstations. Preliminary experiments show that such a 4D display system can give valuable insights into high-dimensional geometry. We present some pictures from the examples using high-dimensional geometry, offset curve tracing and collision detection problems, and explain some of the insights they convey. 1 Introduction The geometry of high-dimensional space has shown to be quite useful in the area of CAGD and solid modeling. Applications include describing the motion of 3D objects, modeling solids with nonuniform material properties, and formulating constraints for offset surfaces and Varonoi surfaces (3, 8, 15]. -

Introduction to Differential Geometry
Introduction to Differential Geometry Lecture Notes for MAT367 Contents 1 Introduction ................................................... 1 1.1 Some history . .1 1.2 The concept of manifolds: Informal discussion . .3 1.3 Manifolds in Euclidean space . .4 1.4 Intrinsic descriptions of manifolds . .5 1.5 Surfaces . .6 2 Manifolds ..................................................... 11 2.1 Atlases and charts . 11 2.2 Definition of manifold . 17 2.3 Examples of Manifolds . 20 2.3.1 Spheres . 21 2.3.2 Products . 21 2.3.3 Real projective spaces . 22 2.3.4 Complex projective spaces . 24 2.3.5 Grassmannians . 24 2.3.6 Complex Grassmannians . 28 2.4 Oriented manifolds . 28 2.5 Open subsets . 29 2.6 Compact subsets . 31 2.7 Appendix . 33 2.7.1 Countability . 33 2.7.2 Equivalence relations . 33 3 Smooth maps .................................................. 37 3.1 Smooth functions on manifolds . 37 3.2 Smooth maps between manifolds . 41 3.2.1 Diffeomorphisms of manifolds . 43 3.3 Examples of smooth maps . 45 3.3.1 Products, diagonal maps . 45 3.3.2 The diffeomorphism RP1 =∼ S1 ......................... 45 -3 -2 Contents 3.3.3 The diffeomorphism CP1 =∼ S2 ......................... 46 3.3.4 Maps to and from projective space . 47 n+ n 3.3.5 The quotient map S2 1 ! CP ........................ 48 3.4 Submanifolds . 50 3.5 Smooth maps of maximal rank . 55 3.5.1 The rank of a smooth map . 56 3.5.2 Local diffeomorphisms . 57 3.5.3 Level sets, submersions . 58 3.5.4 Example: The Steiner surface . 62 3.5.5 Immersions . 64 3.6 Appendix: Algebras . -

Dimension* 0.15% + Fertilizer #902238
Dimension* 0.15% + Fertilizer For season-long control of crabgrass and control or suppression of listed annual grasses and broadleaf weeds in established lawns and ornamental turf, including golf course fairways, roughs and tee boxes. • NOT FOR USE on plants being grown for sale or other commercial use, or for commercial seed production, or for research purposes. • For use on plants intended for aesthetic purposes or climatic modification and being grown in ornamental gardens or parks, or on golf courses or lawns. • Covers up to 17,240 sq ft (131’ x 131’) In the state of New York, this product may be applied only by commercial NOTICE: Read the entire label. Use only according to label directions . applicators at no more than 333 lb (0.5 lb of active ingredient) per acre (7.7 lb Before using this product, read Warranty Disclaimer, Inherent Risk of per 1,000 sq ft) per year. Use of this product in Nassau and Suffolk Counties Use, and Limitations of Remedies at the end of Directions for Use. If of New York is prohibited. terms are unacceptable, return at once unopened. ACTIVE INGREDIENT: DIRECTIONS FOR USE Dithiopyr: 3,5-pyridinedicarbothioic acid, 2-(difluoromethyl)-4-(2-methylpropyl)- 6-(trifluoromethyl)-S,S-dimethyl ester ........................................................ 0.15% It is a violation of Federal law to use this product in any manner inconsistent with OTHER INGREDIENTS : ................................................................................ 99.85% its labeling. Total: .............................................................................................................. 100.0% Use Directions for Turf This product contains 0.075 pounds of the active ingredient dithiopyr per 50 pound bag. Dimension* 0.15% + Fertilizer turf and ornamental herbicide provides season-long control of crabgrass and control or suppression of other listed annual grasses and broadleaf weeds in established lawns and ornamental turfs, including golf course fairways, roughs, and tee boxes.