Dimensionality Estimation, Manifold Learning and Function Approximation Using Tensor Voting
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Grassmann Manifold
The Grassmann Manifold 1. For vector spaces V and W denote by L(V; W ) the vector space of linear maps from V to W . Thus L(Rk; Rn) may be identified with the space Rk£n of k £ n matrices. An injective linear map u : Rk ! V is called a k-frame in V . The set k n GFk;n = fu 2 L(R ; R ): rank(u) = kg of k-frames in Rn is called the Stiefel manifold. Note that the special case k = n is the general linear group: k k GLk = fa 2 L(R ; R ) : det(a) 6= 0g: The set of all k-dimensional (vector) subspaces ¸ ½ Rn is called the Grassmann n manifold of k-planes in R and denoted by GRk;n or sometimes GRk;n(R) or n GRk(R ). Let k ¼ : GFk;n ! GRk;n; ¼(u) = u(R ) denote the map which assigns to each k-frame u the subspace u(Rk) it spans. ¡1 For ¸ 2 GRk;n the fiber (preimage) ¼ (¸) consists of those k-frames which form a basis for the subspace ¸, i.e. for any u 2 ¼¡1(¸) we have ¡1 ¼ (¸) = fu ± a : a 2 GLkg: Hence we can (and will) view GRk;n as the orbit space of the group action GFk;n £ GLk ! GFk;n :(u; a) 7! u ± a: The exercises below will prove the following n£k Theorem 2. The Stiefel manifold GFk;n is an open subset of the set R of all n £ k matrices. There is a unique differentiable structure on the Grassmann manifold GRk;n such that the map ¼ is a submersion. -

On Manifolds of Tensors of Fixed Tt-Rank
ON MANIFOLDS OF TENSORS OF FIXED TT-RANK SEBASTIAN HOLTZ, THORSTEN ROHWEDDER, AND REINHOLD SCHNEIDER Abstract. Recently, the format of TT tensors [19, 38, 34, 39] has turned out to be a promising new format for the approximation of solutions of high dimensional problems. In this paper, we prove some new results for the TT representation of a tensor U ∈ Rn1×...×nd and for the manifold of tensors of TT-rank r. As a first result, we prove that the TT (or compression) ranks ri of a tensor U are unique and equal to the respective seperation ranks of U if the components of the TT decomposition are required to fulfil a certain maximal rank condition. We then show that d the set T of TT tensors of fixed rank r forms an embedded manifold in Rn , therefore preserving the essential theoretical properties of the Tucker format, but often showing an improved scaling behaviour. Extending a similar approach for matrices [7], we introduce certain gauge conditions to obtain a unique representation of the tangent space TU T of T and deduce a local parametrization of the TT manifold. The parametrisation of TU T is often crucial for an algorithmic treatment of high-dimensional time-dependent PDEs and minimisation problems [33]. We conclude with remarks on those applications and present some numerical examples. 1. Introduction The treatment of high-dimensional problems, typically of problems involving quantities from Rd for larger dimensions d, is still a challenging task for numerical approxima- tion. This is owed to the principal problem that classical approaches for their treatment normally scale exponentially in the dimension d in both needed storage and computa- tional time and thus quickly become computationally infeasable for sensible discretiza- tions of problems of interest. -
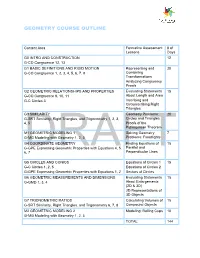
Geometry Course Outline
GEOMETRY COURSE OUTLINE Content Area Formative Assessment # of Lessons Days G0 INTRO AND CONSTRUCTION 12 G-CO Congruence 12, 13 G1 BASIC DEFINITIONS AND RIGID MOTION Representing and 20 G-CO Congruence 1, 2, 3, 4, 5, 6, 7, 8 Combining Transformations Analyzing Congruency Proofs G2 GEOMETRIC RELATIONSHIPS AND PROPERTIES Evaluating Statements 15 G-CO Congruence 9, 10, 11 About Length and Area G-C Circles 3 Inscribing and Circumscribing Right Triangles G3 SIMILARITY Geometry Problems: 20 G-SRT Similarity, Right Triangles, and Trigonometry 1, 2, 3, Circles and Triangles 4, 5 Proofs of the Pythagorean Theorem M1 GEOMETRIC MODELING 1 Solving Geometry 7 G-MG Modeling with Geometry 1, 2, 3 Problems: Floodlights G4 COORDINATE GEOMETRY Finding Equations of 15 G-GPE Expressing Geometric Properties with Equations 4, 5, Parallel and 6, 7 Perpendicular Lines G5 CIRCLES AND CONICS Equations of Circles 1 15 G-C Circles 1, 2, 5 Equations of Circles 2 G-GPE Expressing Geometric Properties with Equations 1, 2 Sectors of Circles G6 GEOMETRIC MEASUREMENTS AND DIMENSIONS Evaluating Statements 15 G-GMD 1, 3, 4 About Enlargements (2D & 3D) 2D Representations of 3D Objects G7 TRIONOMETRIC RATIOS Calculating Volumes of 15 G-SRT Similarity, Right Triangles, and Trigonometry 6, 7, 8 Compound Objects M2 GEOMETRIC MODELING 2 Modeling: Rolling Cups 10 G-MG Modeling with Geometry 1, 2, 3 TOTAL: 144 HIGH SCHOOL OVERVIEW Algebra 1 Geometry Algebra 2 A0 Introduction G0 Introduction and A0 Introduction Construction A1 Modeling With Functions G1 Basic Definitions and Rigid -
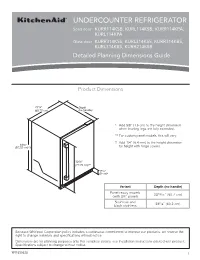
Dimension Guide
UNDERCOUNTER REFRIGERATOR Solid door KURR114KSB, KURL114KSB, KURR114KPA, KURL114KPA Glass door KURR314KSS, KURL314KSS, KURR314KBS, KURL314KBS, KURR214KSB Detailed Planning Dimensions Guide Product Dimensions 237/8” Depth (60.72 cm) (no handle) * Add 5/8” (1.6 cm) to the height dimension when leveling legs are fully extended. ** For custom panel models, this will vary. † Add 1/4” (6.4 mm) to the height dimension 343/8” (87.32 cm)*† for height with hinge covers. 305/8” (77.75 cm)** 39/16” (9 cm)* Variant Depth (no handle) Panel ready models 2313/16” (60.7 cm) (with 3/4” panel) Stainless and 235/8” (60.2 cm) black stainless Because Whirlpool Corporation policy includes a continuous commitment to improve our products, we reserve the right to change materials and specifications without notice. Dimensions are for planning purposes only. For complete details, see Installation Instructions packed with product. Specifications subject to change without notice. W11530525 1 Panel ready models Stainless and black Dimension Description (with 3/4” panel) stainless models A Width of door 233/4” (60.3 cm) 233/4” (60.3 cm) B Width of the grille 2313/16” (60.5 cm) 2313/16” (60.5 cm) C Height to top of handle ** 311/8” (78.85 cm) Width from side of refrigerator to 1 D handle – door open 90° ** 2 /3” (5.95 cm) E Depth without door 2111/16” (55.1 cm) 2111/16” (55.1 cm) F Depth with door 2313/16” (60.7 cm) 235/8” (60.2 cm) 7 G Depth with handle ** 26 /16” (67.15 cm) H Depth with door open 90° 4715/16” (121.8 cm) 4715/16” (121.8 cm) **For custom panel models, this will vary. -

INTRODUCTION to ALGEBRAIC GEOMETRY 1. Preliminary Of
INTRODUCTION TO ALGEBRAIC GEOMETRY WEI-PING LI 1. Preliminary of Calculus on Manifolds 1.1. Tangent Vectors. What are tangent vectors we encounter in Calculus? 2 0 (1) Given a parametrised curve α(t) = x(t); y(t) in R , α (t) = x0(t); y0(t) is a tangent vector of the curve. (2) Given a surface given by a parameterisation x(u; v) = x(u; v); y(u; v); z(u; v); @x @x n = × is a normal vector of the surface. Any vector @u @v perpendicular to n is a tangent vector of the surface at the corresponding point. (3) Let v = (a; b; c) be a unit tangent vector of R3 at a point p 2 R3, f(x; y; z) be a differentiable function in an open neighbourhood of p, we can have the directional derivative of f in the direction v: @f @f @f D f = a (p) + b (p) + c (p): (1.1) v @x @y @z In fact, given any tangent vector v = (a; b; c), not necessarily a unit vector, we still can define an operator on the set of functions which are differentiable in open neighbourhood of p as in (1.1) Thus we can take the viewpoint that each tangent vector of R3 at p is an operator on the set of differential functions at p, i.e. @ @ @ v = (a; b; v) ! a + b + c j ; @x @y @z p or simply @ @ @ v = (a; b; c) ! a + b + c (1.2) @x @y @z 3 with the evaluation at p understood. -

Spectral Dimensions and Dimension Spectra of Quantum Spacetimes
PHYSICAL REVIEW D 102, 086003 (2020) Spectral dimensions and dimension spectra of quantum spacetimes † Michał Eckstein 1,2,* and Tomasz Trześniewski 3,2, 1Institute of Theoretical Physics and Astrophysics, National Quantum Information Centre, Faculty of Mathematics, Physics and Informatics, University of Gdańsk, ulica Wita Stwosza 57, 80-308 Gdańsk, Poland 2Copernicus Center for Interdisciplinary Studies, ulica Szczepańska 1/5, 31-011 Kraków, Poland 3Institute of Theoretical Physics, Jagiellonian University, ulica S. Łojasiewicza 11, 30-348 Kraków, Poland (Received 11 June 2020; accepted 3 September 2020; published 5 October 2020) Different approaches to quantum gravity generally predict that the dimension of spacetime at the fundamental level is not 4. The principal tool to measure how the dimension changes between the IR and UV scales of the theory is the spectral dimension. On the other hand, the noncommutative-geometric perspective suggests that quantum spacetimes ought to be characterized by a discrete complex set—the dimension spectrum. We show that these two notions complement each other and the dimension spectrum is very useful in unraveling the UV behavior of the spectral dimension. We perform an extended analysis highlighting the trouble spots and illustrate the general results with two concrete examples: the quantum sphere and the κ-Minkowski spacetime, for a few different Laplacians. In particular, we find that the spectral dimensions of the former exhibit log-periodic oscillations, the amplitude of which decays rapidly as the deformation parameter tends to the classical value. In contrast, no such oscillations occur for either of the three considered Laplacians on the κ-Minkowski spacetime. DOI: 10.1103/PhysRevD.102.086003 I. -

DIFFERENTIAL GEOMETRY COURSE NOTES 1.1. Review of Topology. Definition 1.1. a Topological Space Is a Pair (X,T ) Consisting of A
DIFFERENTIAL GEOMETRY COURSE NOTES KO HONDA 1. REVIEW OF TOPOLOGY AND LINEAR ALGEBRA 1.1. Review of topology. Definition 1.1. A topological space is a pair (X; T ) consisting of a set X and a collection T = fUαg of subsets of X, satisfying the following: (1) ;;X 2 T , (2) if Uα;Uβ 2 T , then Uα \ Uβ 2 T , (3) if Uα 2 T for all α 2 I, then [α2I Uα 2 T . (Here I is an indexing set, and is not necessarily finite.) T is called a topology for X and Uα 2 T is called an open set of X. n Example 1: R = R × R × · · · × R (n times) = f(x1; : : : ; xn) j xi 2 R; i = 1; : : : ; ng, called real n-dimensional space. How to define a topology T on Rn? We would at least like to include open balls of radius r about y 2 Rn: n Br(y) = fx 2 R j jx − yj < rg; where p 2 2 jx − yj = (x1 − y1) + ··· + (xn − yn) : n n Question: Is T0 = fBr(y) j y 2 R ; r 2 (0; 1)g a valid topology for R ? n No, so you must add more open sets to T0 to get a valid topology for R . T = fU j 8y 2 U; 9Br(y) ⊂ Ug: Example 2A: S1 = f(x; y) 2 R2 j x2 + y2 = 1g. A reasonable topology on S1 is the topology induced by the inclusion S1 ⊂ R2. Definition 1.2. Let (X; T ) be a topological space and let f : Y ! X. -

Manifold Reconstruction in Arbitrary Dimensions Using Witness Complexes Jean-Daniel Boissonnat, Leonidas J
Manifold Reconstruction in Arbitrary Dimensions using Witness Complexes Jean-Daniel Boissonnat, Leonidas J. Guibas, Steve Oudot To cite this version: Jean-Daniel Boissonnat, Leonidas J. Guibas, Steve Oudot. Manifold Reconstruction in Arbitrary Dimensions using Witness Complexes. Discrete and Computational Geometry, Springer Verlag, 2009, pp.37. hal-00488434 HAL Id: hal-00488434 https://hal.archives-ouvertes.fr/hal-00488434 Submitted on 2 Jun 2010 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Manifold Reconstruction in Arbitrary Dimensions using Witness Complexes Jean-Daniel Boissonnat Leonidas J. Guibas Steve Y. Oudot INRIA, G´eom´etrica Team Dept. Computer Science Dept. Computer Science 2004 route des lucioles Stanford University Stanford University 06902 Sophia-Antipolis, France Stanford, CA 94305 Stanford, CA 94305 [email protected] [email protected] [email protected]∗ Abstract It is a well-established fact that the witness complex is closely related to the restricted Delaunay triangulation in low dimensions. Specifically, it has been proved that the witness complex coincides with the restricted Delaunay triangulation on curves, and is still a subset of it on surfaces, under mild sampling conditions. In this paper, we prove that these results do not extend to higher-dimensional manifolds, even under strong sampling conditions such as uniform point density. -

Zero-Dimensional Symmetry
Snapshots of modern mathematics № 3/2015 from Oberwolfach Zero-dimensional symmetry George Willis This snapshot is about zero-dimensional symmetry. Thanks to recent discoveries we now understand such symmetry better than previously imagined possible. While still far from complete, a picture of zero-dimen- sional symmetry is beginning to emerge. 1 An introduction to symmetry: spinning globes and infinite wallpapers Let’s begin with an example. Think of a sphere, for example a globe’s surface. Every point on it is specified by two parameters, longitude and latitude. This makes the sphere a two-dimensional surface. You can rotate the globe along an axis through the center; the object you obtain after the rotation still looks like the original globe (although now maybe New York is where the Mount Everest used to be), meaning that the sphere has rotational symmetry. Each rotation is prescribed by the latitude and longitude where the axis cuts the southern hemisphere, and by an angle through which it rotates the sphere. 1 These three parameters specify all rotations of the sphere, which thus has three-dimensional rotational symmetry. In general, a symmetry may be viewed as being a transformation (such as a rotation) that leaves an object looking unchanged. When one transformation is followed by a second, the result is a third transformation that is called the product of the other two. The collection of symmetries and their product 1 Note that we include the rotation through the angle 0, that is, the case where the globe actually does not rotate at all. 1 operation forms an algebraic structure called a group 2 . -

Hodge Theory
HODGE THEORY PETER S. PARK Abstract. This exposition of Hodge theory is a slightly retooled version of the author's Harvard minor thesis, advised by Professor Joe Harris. Contents 1. Introduction 1 2. Hodge Theory of Compact Oriented Riemannian Manifolds 2 2.1. Hodge star operator 2 2.2. The main theorem 3 2.3. Sobolev spaces 5 2.4. Elliptic theory 11 2.5. Proof of the main theorem 14 3. Hodge Theory of Compact K¨ahlerManifolds 17 3.1. Differential operators on complex manifolds 17 3.2. Differential operators on K¨ahlermanifolds 20 3.3. Bott{Chern cohomology and the @@-Lemma 25 3.4. Lefschetz decomposition and the Hodge index theorem 26 Acknowledgments 30 References 30 1. Introduction Our objective in this exposition is to state and prove the main theorems of Hodge theory. In Section 2, we first describe a key motivation behind the Hodge theory for compact, closed, oriented Riemannian manifolds: the observation that the differential forms that satisfy certain par- tial differential equations depending on the choice of Riemannian metric (forms in the kernel of the associated Laplacian operator, or harmonic forms) turn out to be precisely the norm-minimizing representatives of the de Rham cohomology classes. This naturally leads to the statement our first main theorem, the Hodge decomposition|for a given compact, closed, oriented Riemannian manifold|of the space of smooth k-forms into the image of the Laplacian and its kernel, the sub- space of harmonic forms. We then develop the analytic machinery|specifically, Sobolev spaces and the theory of elliptic differential operators|that we use to prove the aforementioned decom- position, which immediately yields as a corollary the phenomenon of Poincar´eduality. -

Appendix D: Manifold Maps for SO(N) and SE(N)
424 Appendix D: Manifold Maps for SO(n) and SE(n) As we saw in chapter 10, recent SLAM implementations that operate with three-dimensional poses often make use of on-manifold linearization of pose increments to avoid the shortcomings of directly optimizing in pose parameterization spaces. This appendix is devoted to providing the reader a detailed account of the mathematical tools required to understand all the expressions involved in on-manifold optimization problems. The presented contents will, hopefully, also serve as a solid base for bootstrap- ping the reader’s own solutions. 1. OPERATOR DEFINITIONS In the following, we will make use of some vector and matrix operators, which are rather uncommon in mobile robotics literature. Since they have not been employed throughout this book until this point, it is in order to define them here. The “vector to skew-symmetric matrix” operator: A skew-symmetric matrix is any square matrix A such that AA= − T . This implies that diagonal elements must be all zeros and off-diagonal entries the negative of their symmetric counterparts. It can be easily seen that any 2× 2 or 3× 3 skew-symmetric matrix only has 1 or 3 degrees of freedom (i.e. only 1 or 3 independent numbers appear in such matrices), respectively, thus it makes sense to parameterize them as a vector. Generating skew-symmetric matrices ⋅ from such vectors is performed by means of the []× operator, defined as: 0 −x 2× 2: = x ≡ []v × () × x 0 x 0 z y (1) − 3× 3: []v = y ≡ z0 − x × z −y x 0 × The origin of the symbol × in this operator follows from its application to converting a cross prod- × uct of two 3D vectors ( x y ) into a matrix-vector multiplication ([]x× y ). -
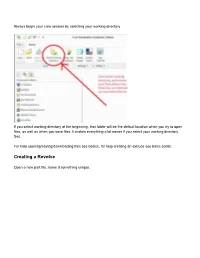
Creating a Revolve
Always begin your creo session by selecting your working directory If you select working directory at the beginning, that folder will be the default location when you try to open files, as well as when you save files. It makes everything a lot easier if you select your working directory first. For help opening/saving/downloading files see basics, for help creating an extrude see basic solids. Creating a Revolve Open a new part file, name it something unique. Choose a plane to sketch on Go to sketch view (if you don’t know where that is see Basic Solids) Move your cursor so the centerline snaps to the horizontal line as shown above You may now begin your sketch I have just sketched a random shape Sketch Tips: ● Your shape MUST be closed ● If you didn’t put a centerline in, you will get radial instead of diameter dimensions (in general this is bad) ● Remember this is being revolved so you are only sketching the profile on one side of the center line. If you need to put in diameter dimensions: Click normal, click the line or point you want the dimension for, click the centerline, and click the same line/point that you clicked the first time AGAIN, and then middle mouse button where you want the dimension to be placed. After your sketch is done, click the checkmark to get out of sketch, then click the checkmark again to complete the revolve The part in the sketch will look like this: .