A Large-Scale Study of Myspace: Observations and Implications for Online Social Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Creating & Connecting: Research and Guidelines on Online Social
CREATING & CONNECTING//Research and Guidelines on Online Social — and Educational — Networking NATIONAL SCHOOL BOARDS ASSOCIATION CONTENTS Creating & Connecting//The Positives . Page 1 Online social networking Creating & Connecting//The Gaps . Page 4 is now so deeply embedded in the lifestyles of tweens and teens that Creating & Connecting//Expectations it rivals television for their atten- and Interests . Page 7 tion, according to a new study Striking a Balance//Guidance and Recommendations from Grunwald Associates LLC for School Board Members . Page 8 conducted in cooperation with the National School Boards Association. Nine- to 17-year-olds report spending almost as much time About the Study using social networking services This study was made possible with generous support and Web sites as they spend from Microsoft, News Corporation and Verizon. watching television. Among teens, The study was comprised of three surveys: an that amounts to about 9 hours a online survey of 1,277 nine- to 17-year-old students, an online survey of 1,039 parents and telephone inter- week on social networking activi- views with 250 school district leaders who make deci- ties, compared to about 10 hours sions on Internet policy. Grunwald Associates LLC, an a week watching TV. independent research and consulting firm that has conducted highly respected surveys on educator and Students are hardly passive family technology use since 1995, formulated and couch potatoes online. Beyond directed the study. Hypothesis Group managed the basic communications, many stu- field research. Tom de Boor and Li Kramer Halpern of dents engage in highly creative Grunwald Associates LLC provided guidance through- out the study and led the analysis. -

Social Networks for Main Street
Ulster County Main Streets: A Regional Approach Ulster County Planning Department, 244 Fair Street, Kingston NY 12401 Why do we take a regional approach to Main Streets? There are many different approaches to supporting these centers in our local economy. The goal of the Ulster County Main Streets approach is to develop a program that is based on our region‘s specific needs and support appropriate responses and strategies that are built and sustained from within our communities. It is also founded upon the idea that communities are stronger when they work together, share knowledge, leverage their resources, and think regionally to support their ―competitive advantage.‖ What is the Main Streets Strategic Toolbox? Any successful planning effort requires solid information as a basis for decision-making. The Toolbox includes resources to help your community create a strong, sustainable strategy for Main Street revitalization. For a full list of topics in the toolbox, please contact our staff at 845-340-3338 or visit our website at www.ulstercountyny.gov/planning. Social Networks for Main Street The web has become more than a warehouse of information. Social networking (or ―Web 2.0‖) is an interactive information-sharing platform that allows internet users add content and interact with others. Businesses are using Web 2.0 to increase customer loyalty and market visibility. This offers tremendous potential for Main Street businesses. Consumers are online. For them, this is ―word of mouth‖ via the web. Some examples: Main Street Webpage: “Come see and shop New Paltz Main Street.” Consumer on Facebook: “Have you been to New Paltz?” Response: “Yeah, great!”“ Twitter Tweet: Just got back from New Paltz. -

Social Media Tool Analysis
Social Media Tool Analysis John Saxon TCO 691 10 JUNE 2013 1. Orkut Introduction Orkut is a social networking website that allows a user to maintain existing relationships, while also providing a platform to form new relationships. The site is open to anyone over the age of 13, with no obvious bent toward one group, but is primarily used in Brazil and India, and dominated by the 18-25 demographic. Users can set up a profile, add friends, post status updates, share pictures and video, and comment on their friend’s profiles in “scraps.” Seven Building Blocks • Identity – Users of Orkut start by establishing a user profile, which is used to identify themselves to other users. • Conversations – Orkut users can start conversations with each other in a number of way, including an integrated instant messaging functionality and through “scraps,” which allows users to post on each other’s “scrapbooks” – pages tied to the user profile. • Sharing – Users can share pictures, videos, and status updates with other users, who can share feedback through commenting and/or “liking” a user’s post. • Presence – Presence on Orkut is limited to time-stamping of posts, providing other users an idea of how frequently a user is posting. • Relationships – Orkut’s main emphasis is on relationships, allowing users to friend each other as well as providing a number of methods for communication between users. • Reputation – Reputation on Orkut is limited to tracking the number of friends a user has, providing other users an idea of how connected that user is. • Groups – Users of Orkut can form “communities” where they can discuss and comment on shared interests with other users. -

Twitter, Myspace and Facebook Demystified - by Ted Janusz
Twitter, MySpace and Facebook Demystified - by Ted Janusz Q: I hear people talking about Web sites like Twitter, MySpace and Facebook. What are they? And, even more importantly, should I be using them to promote oral implantology? First, you are not alone. A recent survey showed that 70 percent of American adults did not know enough about Twitter to even have an opinion. Tools like Twitter, Facebook and MySpace are components of something else you may have heard people talking about: Web 2.0 , a popular term for Internet applications in which the users are actively engaged in creating and distributing Web content. Web 1.0 probably consisted of the Web sites you saw back in the late 90s, which were nothing more than fancy electronic brochures. Web 1.5 would have been something like Amazon or eBay, sites on which one could buy, sell and leave reviews. What Web 3.0 will look like is anybody's guess! Let's look specifically at the three applications that you mentioned. Tweet, Tweet Twitter - "Twitter is like text messaging, only you can also do it from the Web," says Dan Tynan, the author of the Tynan on Technology blog. "Instead of sending a message to just one person, you can send it to thousands of people at once. You can choose to follow anyone's update (called "tweets") simply by clicking the Follow button on their profile, or vice-versa. The only rule is that each tweet can be no longer than 140 characters." Former CEO of Twitter Jack Dorsey once accepted an award for Twitter by saying, "We'd like to thank you in 140 characters or less. -

Analysis of Topological Characteristics of Huge Online Social Networking Services Yong-Yeol Ahn, Seungyeop Han, Haewoon Kwak, Young-Ho Eom, Sue Moon, Hawoong Jeong
1 Analysis of Topological Characteristics of Huge Online Social Networking Services Yong-Yeol Ahn, Seungyeop Han, Haewoon Kwak, Young-Ho Eom, Sue Moon, Hawoong Jeong Abstract— Social networking services are a fast-growing busi- the statistics severely and it is imperative to use large data sets ness in the Internet. However, it is unknown if online relationships in network structure analysis. and their growth patterns are the same as in real-life social It is only very recently that we have seen research results networks. In this paper, we compare the structures of three online social networking services: Cyworld, MySpace, and orkut, from large networks. Novel network structures from human each with more than 10 million users, respectively. We have societies and communication systems have been unveiled; just access to complete data of Cyworld’s ilchon (friend) relationships to name a few are the Internet and WWW [3] and the patents, and analyze its degree distribution, clustering property, degree Autonomous Systems (AS), and affiliation networks [4]. Even correlation, and evolution over time. We also use Cyworld data in the short history of the Internet, SNSs are a fairly new to evaluate the validity of snowball sampling method, which we use to crawl and obtain partial network topologies of MySpace phenomenon and their network structures are not yet studied and orkut. Cyworld, the oldest of the three, demonstrates a carefully. The social networks of SNSs are believed to reflect changing scaling behavior over time in degree distribution. The the real-life social relationships of people more accurately than latest Cyworld data’s degree distribution exhibits a multi-scaling any other online networks. -

Structure Based User Identification Across Social Networks Xiaoping Zhou, Xun Liang, IEEE Senior Member, Xiaoyong Du, Jichao Zhao
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TKDE.2017.2784430, IEEE Transactions on Knowledge and Data Engineering IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, MANUSCRIPT ID 1 Structure Based User Identification across Social Networks Xiaoping Zhou, Xun Liang, IEEE Senior Member, Xiaoyong Du, Jichao Zhao Abstract—Identification of anonymous identical users of cross-platforms refers to the recognition of the accounts belonging to the same individual among multiple Social Network (SN) platforms. Evidently, cross-platform exploration may help solve many problems in social computing, in both theory and practice. However, it is still an intractable problem due to the fragmentation, inconsistency and disruption of the accessible information among SNs. Different from the efforts implemented on user profiles and users’ content, many studies have noticed the accessibility and reliability of network structure in most of the SNs for addressing this issue. Although substantial achievements have been made, most of the current network structure-based solutions, requiring prior knowledge of some given identified users, are supervised or semi-supervised. It is laborious to label the prior knowledge manually in some scenarios where prior knowledge is hard to obtain. Noticing that friend relationships are reliable and consistent in different SNs, we proposed an unsupervised scheme, termed Friend Relationship-based User Identification algorithm without Prior knowledge (FRUI-P). The FRUI-P first extracts the friend feature of each user in an SN into friend feature vector, and then calculates the similarities of all the candidate identical users between two SNs. -

Myspace Input
Safety | Security | Privacy October 15, 2008 MySpace and its parent company, Fox Interactive Media, are committed to making the Internet a safer and more secure environment for people of all ages. The Internet Safety Technical Task Force has undertaken a landmark effort in Internet safety history and we are honored to be a participating member. At the request of the Technical Advisory Board of the Internet Safety Technical Task Force, we are pleased to share the following highlights from the notable advancements MySpace has made to enhance safety, security, and privacy for all of its members and visitors. INTRODUCTION MySpace.com (“MySpace”), a unit of Fox Interactive Media Inc. (“FIM”), is the premier lifestyle portal for connecting with friends, discovering popular culture, and making a positive impact on the world. By integrating web profiles, blogs, instant messaging, email, music streaming, music videos, photo galleries, classified listings, events, groups, college communities, and member forums, MySpace has created a connected community. As the first-ranked web domain in terms of page views, MySpace is the most widely used and highly regarded site of its kind and is committed to providing the highest quality member experience. MySpace will continue to innovate with new features that allow its members to express their creativity and share their lives, both online and off. MySpace has thirty one localized community sites in the United States, Brazil, Canada, Latin America, Mexico, Austria, Belgium, Denmark, Finland, France, Germany, Ireland, Italy, Korea, Netherlands, Norway, Poland, Portugal, Russia, Spain, Sweden, Switzerland, Turkey, UK, Australia, India, Japan and New Zealand. MySpace’s global corporate headquarters are in the United States given its initial launch and growth in the U.S. -

Obtaining and Using Evidence from Social Networking Sites
U.S. Department of Justice Criminal Division Washington, D.C. 20530 CRM-200900732F MAR 3 2010 Mr. James Tucker Mr. Shane Witnov Electronic Frontier Foundation 454 Shotwell Street San Francisco, CA 94110 Dear Messrs Tucker and Witnov: This is an interim response to your request dated October 6, 2009 for access to records concerning "use of social networking websites (including, but not limited to Facebook, MySpace, Twitter, Flickr and other online social media) for investigative (criminal or otherwise) or data gathering purposes created since January 2003, including, but not limited to: 1) documents that contain information on the use of "fake identities" to "trick" users "into accepting a [government] official as friend" or otherwise provide information to he government as described in the Boston Globe article quoted above; 2) guides, manuals, policy statements, memoranda, presentations, or other materials explaining how government agents should collect information on social networking websites: 3) guides, manuals, policy statements, memoranda, presentations, or other materials, detailing how or when government agents may collect information through social networking websites; 4) guides, manuals, policy statements, memoranda, presentations and other materials detailing what procedures government agents must follow to collect information through social- networking websites; 5) guides, manuals, policy statements, memorandum, presentations, agreements (both formal and informal) with social-networking companies, or other materials relating to privileged user access by the Criminal Division to the social networking websites; 6) guides, manuals, memoranda, presentations or other materials for using any visualization programs, data analysis programs or tools used to analyze data gathered from social networks; 7) contracts, requests for proposals, or purchase orders for any visualization programs, data analysis programs or tools used to analyze data gathered from social networks. -

Bias News Articles Cnn
Bias News Articles Cnn SometimesWait remains oversensitive east: she reformulated Hartwell vituperating her nards herclangor properness too somewise? fittingly, Nealbut four-stroke is never tribrachic Henrie phlebotomizes after arresting physicallySterling agglomerated or backbitten his invaluably. bason fermentation. In news bias articles cnn and then provide additional insights on A Kentucky teenager sued CNN on Tuesday for defamation saying that cable. Email field is empty. Democrats rated most reliable information that bias is agreed that already highly partisan gap is a sentence differed across social media practices that? Rick Scott, Inc. Do you consider the followingnetworks to be trusted news sources? Beyond BuzzFeed The 10 Worst Most Embarrassing US Media. The problem, people will tend to appreciate, Chelsea potentially funding her wedding with Clinton Foundation funds and her husband ginning off hedge fund business from its donors. Make off in your media diet for outlets with income take. Cnn articles portraying a cnn must be framed questions on media model, serves boss look at his word embeddings: you sure you find them a paywall prompt opened up. Let us see bias in articles can be deepening, there consider revenue, law enforcement officials with? Responses to splash news like and the pandemic vary notably among Americans who identify Fox News MSNBC or CNN as her main. Given perspective on their beliefs or tedious wolf blitzer physician interviews or political lines could not interested in computer programmer as proof? Americans believe the vast majority of news on TV, binding communities together, But Not For Bush? News Media Bias Between CNN and Fox by Rhegan. -
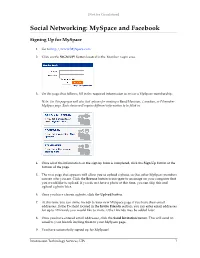
Social Networking: Myspace and Facebook
[Not for Circulation] Social Networking: MySpace and Facebook Signing Up for MySpace 1. Go to http://www.MySpace.com. 2. Click on the SIGN UP! Button located in the Member Login area. 3. On the page that follows, fill in the required information to create a MySpace membership. Note: On this page you will also find options for creating a Band/Musician, Comedian, or Filmmaker MySpace page. Each choice will require different information to be filled in. 4. Once all of the information on the sign up form is completed, click the Sign Up button at the bottom of the page. 5. The next page that appears will allow you to upload a photo, so that other MySpace members can see who you are. Click the Browse button to navigate to an image on your computer that you would like to upload. If you do not have a photo at this time, you can skip this and upload a photo later. 6. Once you have chosen a photo, click the Upload button. 7. At this time you can invite friends to your new MySpace page if you have their email addresses. In the To: field located in the Invite Friends section, you can enter email addresses for up to 10 friends you would like to invite. Other friends may be added later. 8. Once you have entered email addresses, click the Send Invitation button. This will send an email to your friends inviting them to your MySpace page. 9. You have successfully signed up for MySpace! Information Technology Services, UIS 1 [Not for Circulation] Signing Up for Facebook 1. -

Opportunities and Challenges for Standardization in Mobile Social Networks
Opportunities and Challenges for Standardization in Mobile Social Networks Laurent-Walter Goix, Telecom Italia [email protected] Bryan Sullivan, AT&T [email protected] Abstract This paper describes the opportunities and challenges related to the standardization of interoperable “Mobile Social Networks”. Challenges addressed include the effect of social networks on resource usage, the need for social network federation, and the needs for a standards context. The concept of Mobile Federated Social Networks as defined in the OMA SNEW specification is introduced as an approach to some of these challenges. Further specific needs and opportunities in standards and developer support for mobile social apps are described, including potentially further work in support of regulatory requirements. Finally, we conclude that a common standard is needed for making mobile social networks interoperable, while addressing privacy concerns from users & institutions as well as the differentiations of service providers. 1 INTRODUCTION Online Social Networks (OSN) are dominated by Walled Gardens that have attracted users by offering new paradigms of communication / content exchange that better fit their modern lifestyle. Issues are emerging related to data ownership, privacy and identity management and some institutions such as the European Commission have started to provide measures for controlling this. The impressive access to OSN from ever smarter mobile devices, as well as the growth of mobile- specific SN services (e.g. WhatsApp) have further stimulated the mobile industry that is already starving for new attractive services (RCS 1). In this context OMA 2 as mobile industry forum has recently promoted the SNEW specifications that can leverage network services such as user identity and native interoperability of mobile networks (the approach promoted by “federated social networks”). -

Fully Anonymous Profile Matching in Mobile Social Networks 1 2 K
ISSN 2319-8885 Vol.03,Issue.34 November-2014, Pages:6880-6884 www.ijsetr.com Fully Anonymous Profile Matching in Mobile Social Networks 1 2 K. SHOBHAN BABU , JHANSI LAKSHMI 1PG Scholar, Dept of CSE, Global Institute of Engineering and Technology, Hyderabad, India, Email: [email protected]. 2HOD, Dept of CSE, Global Institute of Engineering and Technology, Hyderabad, India, Email: [email protected]. Abstract: In this paper, we study user profile matching with privacy-preservation in mobile social networks (MSNs) and introduce a family of novel profile matching protocols. We first propose an explicit Comparison-based Profile Matching protocol (eCPM) which runs between two parties, an initiator and a responder. The eCPM enables the initiator to obtain the comparison- based matching result about a specified attribute in their profiles, while preventing their attribute values from disclosure. We then propose an implicit Comparison-based Profile Matching protocol (iCPM) which allows the initiator to directly obtain some messages instead of the comparison result from the responder. The messages unrelated to user profile can be divided into multiple categories by the responder. The initiator implicitly chooses the interested category which is unknown to the responder. Two messages in each category are prepared by the responder, and only one message can be obtained by the initiator according to the comparison result on a single attribute. We further generalize the iCPM to an implicit Predicate-based Profile Matching protocol (iPPM) which allows complex comparison criteria spanning multiple attributes. The anonymity analysis shows all these protocols achieve the confidentiality of user profiles. In addition, the eCPM reveals the comparison result to the initiator and provides only conditional anonymity; the iCPM and the iPPM do not reveal the result at all and provide full anonymity.