North Frisian Dialects: a Quantitative Investigation Using a Parallel Corpus of Translations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ausgabe 09/2016
Nieblum Jahrgang 16 / Ausgabe 09 Mai 2016 Froh Pfi ngste! Beim Frühlingsfest am 21. Mai und Trachtentreffen am 5. Juni: Adenauer & Co · Alberto Golf · Dubarry · Emanuel Berg Eleven Elfs · Napapijri · River Woods · Saint James R95th · Wiesenzauber & Moritz · William Lockie La Moda Öffnungszeiten Utersum tanzt! Bi de Süd 30 Mo. - Fr. 10:00 - 18:00 25938 Nieblum Sa. 10:00 - 14:00 04681 741353 · [email protected] · www.lamoda-foehr.de Das Pfannkuchen·Haus feiert seinen 20. Geburtstag! Täglich durchgehend ab 12 Uhr geöffnet Prinzen·Hof am Wyker Südstrand, Gmelinstraße 29, Telefon (04681) 765 www.das-pfannkuchen-haus.de Restaurant Café Eisspezialitäten ... einfach märchenhaft! Utersum hat mit Göntje Schwab Mal findet am 21. Mai das be- Thomas Judisch Spielzeug Föhr Alle eine neue Bürgermeisterin. Ihr liebte Frühligsfest mit vielen Le- Playmobil, Barbie, Fisher-Price, zur Seite stehen als erste Stell- ckereien statt. Zum Programm 15. bis 29. Mai 2016 Puppen,Puppenzubehör, vertreterin Ilke Kurzweg und als gehören Auftritte der Utersu- 20% bruder, Wiking und herpa zweiter Stellvertreter Richard mer Trachtengruppe. Am 5. Juni Kleider machen Freunde auf (Einzelteile bis zu 50% reduziert!) Quedens: Aber nicht allein des- tanzt sie zum zweiten Mal - Das Museum Kunst der Westküste zu Gast bei Ihr ganz besonderes Einkaufserlebnis halb kann in Utersum gefeiert dann zum Trachtentreffen (Früh- Ehlers Fashion in Wyk auf Föhr in der Großen Straße 32, 25938 Wyk, Tel.: 57 01 74 werden. Bereits zum sechsten lingsfest siehe im Innenteil). Eröffnung Pfingstsonntag -

Außerschulische Lernorte
AußerschulischeBildung erleben in der AktivRegion NordfrieslandLernorte Nord Neukirchen Klanxbüll Ladelund Niebüll Leck Stadum Bordelum Goldebek Bredstedt Reußenköge Ahrenshöft 6 Heuherberge-Hedwigsruh 11 Nolde Stiftung Seebüll Spiel, Begegnung Natur G. + V. Clausen-Hansen Caroline Dieterich &Teambildung Hedwigsruh 6, 25917 Stadum Seebüll 11 Tel: 04662/70531 25927 Neukirchen Naturkundemuseum Niebüll [email protected] Tel: 04664/98 39 30 Ev. Familienbildungsstätte 1 www.heuherberge-nf.de [email protected] 16 Niebüll www.nolde-stiftung.de Carl-Heinz Christiansen Sachkundige Führungen; Mitmach-Aktionen; Hauptstr. 108, 25899 Niebüll Seminarraum mit techn. Ausstattung; 01. März - 30. Nov.; Sachkundige Führun- Diakonisches Werk Tel: 04661/5691 Max. Gruppenzahl: 30; Verpflegung buchbar gen; Mitmach-Aktionen: Malschule; Max. Südtondern gGmbH [email protected] Gruppenzahl: 25 pro Führung, ab dann Kornelia Klawonn-Domin www.nkm-niebuell.de 7 Infozentrum Wiedingharde Teilung der Gruppe; Verpflegung buchbar: z.T. Uhlebüller Str. 22, 25899 Niebüll Tel: 04661/9014110 Ganzjährig; Sachkundige Führungen; Carola Steltner 12 Dorfmuseum Ladelund [email protected] Mitmach-Aktionen; Seminarraum mit techn. Toft 1, 25924 Klanxbüll www.dw-suedtondern.de Ausstattung; Max. Gruppenzahl: 30 Tel: 04668/313 Martina Buldt Ganzjährig; Mitmach-Aktionen; Seminar- Naturzentrum Mittleres [email protected] Westerstr., 25926 Ladelund www.nordfrieslanderleben.de Tel: 0160/6768004 raum mit techn. Ausstattung 2 Nordfriesland [email protected] Ganzjährig; Sachkundige Führungen; Ev. Kinder- und Jugendbüro Internetseite: www.ladelund.de 17 Willi Klang Mitmach-Aktionen; Seminarraum mit techn. Nordfriesland Bahnhofstr. 23 Ausstattung; Max. Gruppenzahl: 20-40, 01.05. - 31.10., Mittw. 14-18 Uhr; Sachkun- 25821 Bredstedt, Tel: 04671/4555 je nach Angebot dige Führungen; Max. Gruppenzahl: 50 Susanne Kunsmann [email protected] Uhlebüllerstr. -

Mirebüller Route
Mergelschächte Dörpum Christian Jensen-Kolleg Soh olmer Au Mirebüller Route MÖNKEBÜLL Auf dieser Route zeigt sich, dass Nordfriesland nicht nur »platt« Missionsort Breklum ist, denn auf dieser Route erleben Sie die nordfriesische Geest Wieder zurück in Breklum informiert die »Eine-Welt-Ausstellung« LÜTJENHOLM mit dem in der Eiszeit entstandenen hügeligen Landschaftsbild. in acht Räumen über die Breklumer Missionsgeschichte und Alte Sie lernen einige beschauliche Geestdörfer und die Landschaft verschiedene interkulturelle Begegnungen der Kirchen des Schmiede um das ehemalige Gut Mirebüll kennen. Nordens und des Südens. Führungen können über das Büro des Die Route startet und endet beim Kirchspielkrug in Breklum. Hier Christian Jensen Kollegs vereinbart werden (04671-91120). Staatsforst Schleswig gibt eine Tafel den Überblick über den Routenverlauf. Das Christian Jensen Kolleg in Breklum ist eine große Tagungs- und Begegnungsstätte für Kirche und Gesellschaft. In direkter Kirche als Seezeichen Nachbarschaft liegt der Breklumer Baumlehrpfad. Der idyllische Die Tour führt zunächst entlang einem kleinen Bach zum statt- Weg verläuft parallel zur Bahnlinie und ist mit verschiedenen lichen Backsteinbau der Breklumer Kirche (12. Jh). Der Kirch- Holzskulpturen und informativen Tafeln ausgestattet. NSG Langenhorner turm dient den Schiffern seit jeher auf der nahen Nordsee zur und Bordelumer Heide 5 Orientierung. DÖRPUM Ochsenweg als zentrale Verkehrsader Schleswig-Holsteins Quickhorner Weiter nördlich in Vollstedt befindet sich »Königswasser«, eine Radeln und Baden Wald HÖGEL ehemalige königliche Viehtränke, an der die westliche Route des In den Sommermonaten laden auf der Route die Freibäder in Högel 4 Sportflug- alten Ochsenweges vorbei lief. Besonders im 16. und 17. Jahr- und Breklum zu einem erfrischenden Bad ein. platz hundert war dieser Weg eine stark frequentierte Trasse für Gnadenhof für Pferde Ochsendriften von Dänemark nach Deutschland. -

Ausflugsfahrten 2021
RegelnCOVID-19 im Innenteil Fahrkarten Online unter wattenmeerfahrten.de oder im Vorverkauf: Föhr-Amrumer Reisebüro (Wyk), Tourist-Informationen (Wyk, Nieblum, Utersum) List Sie können Ihre Fahrkarte auch am Schiff vor der Abfahrt erwerben, solange Plätze frei sind. Ausflugsfahrten Hallig Hooge Große Halligmeer-Kreuzfahrt Seetierfang MS Hauke Haien stellt sich vor Alle Schiffsabfahrts- und Ankunftszeiten gelten nur bei normalen Wind-, Wasser- und Sichtverhältnissen sowie genügender Beteiligung. Irrtum und Änderungen vorbehal- ten. Ankunftszeiten können auf Grund der Tide variieren. Es gelten die Beförderungs- Erwachsene Kinder (4-14 J) Familien* Erwachsene Kinder (4-14 J) Familien* Erwachsene Kinder (4-14 J) Familien* bedingungen der Halligreederei MS Hauke Haien. Wir, die Familie Diedrichsen, betreiben das Schiff seit 1988 2021 35 € 15 € 95 € 35 € 15 € 95 € 30 € 15 € 80 € und unser Heimathafen ist Hallig Hooge. Den Namen „Hau- ke Haien“ erhielt das Schiff nach der Hauptfigur aus Theodor Inkl. Seetierfang & Seehundsbänke (tideabhängig) Auf Hallig Gröde (1 Std. Landgang) · Seehundsbänke (tideabh.) Auf diesen Touren zeigen wir Ihnen die Unterwasserwelt. In der Für besondere Anlässe können Sie unser Schiff Wir wollen Sie auf Seereise zur Hallig Hooge mitnehmen. Am An- Unser Kurs geht ins östliche Wattenmeer vorbei an den Halligen Nähe der Wyker Küste wird ein Schleppnetz ausgeworfen und Storms Novelle „Der Schimmelreiter“. Unser Schiff wurde 1960 ab Wyk auf Föhr (alte Mole) leger können Fahrräder oder Kutschen gebucht werden, oder Sie Langeneß , Hooge, Oland, Gröde, Habel, Hamburger Hallig, Nord- der Seetierfang an Bord vom Kapitän oder der gebürtigen Nord- als erste Halligfähre von „Kapitän August Jakobs“ mit dem Na- auch chartern. Sprechen Sie uns gerneNiebüll an. -

Förderung Aus Dem Grundbudget: A
LAG AktivRegion Nordfriesland Nord e.V. 14.Vorstandstreffen Dienstag, 20.November 2018, 16 – 18 Uhr, Niebüll Regionalmanagement LAG AktivRegion Nordfriesland Nord – Dr. Simon Rietz 1 Tagesordnung 1. Begrüßung und Protokoll der letzten Sitzung 2. Mitteilungen zu Projekten a. „Neuausrichtung der Küche des Wilhelminen-Hospiz in Niebüll“ b. „Grünes Rechenzentren-Cluster Nordfriesland“ c. „Dörpshuus Stedesand“ 3. Klärungsbedarfe zu Projekten / Projektanfragen a. „Mähroboter in der AktivRegion Nordfriesland Nord“ b. „Gesundheitshaus Langenhorn“ 4. Förderanträge – Beratung und Empfehlung Zur Förderung aus dem Grundbudget: a. Dörpspark Enge-Sande b. Sport- & Freizeitheim und Fußball-Kleinfeld für Stadum c. Regionaler-Online-Marktplatz Südtondern d. Schöpfungsgarten / Garten der Sinne e. Umsetzung des Marketingkonzepts für die nordfriesischen Lammtage f. Strategieentwicklung 2030 für das Gebiet der Nordfriesland-Tourismus GmbH 5. Bericht aus den Handlungsfeldern 6. Verschiedenes, Termine 2 1. Begrüßung und Protokoll der letzten Sitzung 3 2. Mitteilungen zu Projekten a. Neuausrichtung der Küche des Wilhelminen-Hospiz in Niebüll • Beschluss zur Förderung liegt vor (VS-Beschluss vom 13.September 2018) • Ursprüngliche Förderquote = 80% mit einer Fördersumme von 181.828,40 € • Annahme: Der Projetträger, die gemeinnützige Wilhelminenhospiz GmbH, ist „öffentlichen Trägern gleichgestellt“ und profitiert von der höheren Förderquote. • Diese Prüfung der Gleichstellung würde mehrere Monate dauern, so dass der Projektträger wegen der schnelleren Umsetzbarkeit des Projekts darauf verzichtet. Die Förderquote ändert sich damit von 80% auf 70% mit einer Fördersumme von dann noch 159.099,85 €. • Die Mittelbindung im Förderschwerpunkt „Nachhaltige Daseinsvorsorge“ verringert sich folglich um 22.728,55 €. • Grundsätzliches Problem: Keine klare Trennung der Küchenneuausrichtung als Einzelprojekt des Gesamtprojektes „Erweiterung des Wilhelminen- Hospizes“, daher Schwierigkeiten der Bewilligung durch das LLUR. -

Wattenmeer Für Alle
BARRIEREFREIE NATURERLEBNISANGEBOTE IM NATIONALPARK Wattenmeer für Alle Nationalpark Wa ttenmeer SCHLESWIG-HOLSTEIN Hinweise zu Covid-19 Alle Änderungen bezüglich eines Lockdowns oder wegen geltender Covid-19-Maßnahmen sind nicht in dieser Broschüre aufgeführt. Bitte kontaktieren Sie in jedem Fall die Anbieterin oder den Anbieter ob Angebote momentan stattfinden und mit welchen Änderungen zu rechnen ist. Bitte informieren Sie sich rechtzeitig auch auf den entsprechenden Internetseiten über aktuelle Änderungen. Alle Kontaktdaten finden Sie in dieser Broschüre auf den entsprechenden Seiten des Angebotes. Kontaktdaten der Nationalparkverwaltung: Infotelefon: 0 48 61 / 96 20 0 E-Mail: [email protected] 2 Inhalt Zu dieser Broschüre �������������������������������������������������������������������������������������������������������������������4 Der Nationalpark Schleswig-Holsteinisches Wattenmeer ...........................................5 Lebensraum Watt �����������������������������������������������������������������������������������������������������������������������7 Nationalpark-Partner ����������������������������������������������������������������������������������������������������������������8 Hinweise zur Anreise mit der Bahn ......................................................................................9 Barrierefreie Angebote auf Sylt .......................................................................................... 10 Barrierefreie Angebote auf Föhr ....................................................................................... -
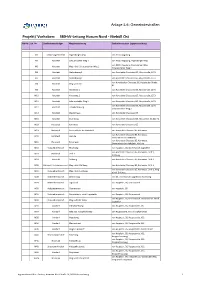
380-Kv-Leitung Husum Nord - Niebüll Ost
Anlage 3.6: Gemeindestraßen Projekt/ Vorhaben: 380-kV-Leitung Husum Nord - Niebüll Ost BW-Nr. Lfd.-Nr. Straßenbaulastträger Wegebezeichnung Stationierung bzw. Lagebeschreibung W1 Schwesing/Horstedt Engelsburger Weg von B200, Augsburg W2 Horstedt Schauendahler Weg 1 von B200, Augsburg, Engelsburger Weg von B200, Augsburg, Engelsburger Weg, W3 Horstedt Weg nördl. Schauendahler Weg 1 Schauendahler Weg 1 W6 Horstedt Nielandsweg 1 von Horstedter Chaussee, B5, Hauptstraße, L273 W7 Horstedt Nielandsweg 2 von Horstedter Chaussee, B5, Hauptstraße, L273 von Horststedter Chaussee, B5, Hattstedter Straße, W8 Horstedt Weg westl. B5 K2 W9 Horstedt Klingeweg 1 von Horstedter Chaussee, B5, Hauptstraße, L273 W10 Horstedt Klingeweg 2 von Horstedter Chaussee, B5, Hauptstraße, L273 W11 Horstedt Schauendahler Weg 2 von Horstedter Chaussee, B5, Hauptstraße, L273 von Horstedter Chaussee, B5, Hauptstraße, L273, W12 Horstedt Lehmkuhlenweg Schauendahler Weg 2 W14 Horstedt Westermaas von Horstedter Chaussee, B5 W15 Horstedt Ostermaas von Horstedter Chaussee, B5, Hattstedter Straße, K2 W18 Hattstedt Kornmaas von Horstedter Chaussee, B5 W19 Hattstedt Gemeindestr. bei Hattstedt von Horstedter Chausee, B5, Kornmaas von Horstedter Chausee, B5, Kornmaas, W20 Hattstedt Höchde Gemeindestr bei Hattstedt von Horstedter Chausee, B5, Kornmaas, W21 Hattstedt Birkenweg Gemeindestr bei Hattstedt, Höchde W22 Hattstedtermarsch Wischweg von Hauptstr., B5, Ostermarsch, Lagedeich von Horstedter Chausee, B5, Kornmaas, Drift 1, W23 Hattstedt Drift 1 Driftweg W24 Horstedt Driftweg von Horstedter Chausee, B5, Kornmaas, Drift 1 W25 Hattstedt/ Hattstedtermarsch Weg nördl. Dirftweg von Horstedter Chausee, B5, Kornmaas, Drift 1 von Horstedter Chausee, B5, Kornmaas, Drift 1, Weg W26 Hattstedtermarsch Weg nördl. Lundweg nördl. Driftweg W28 Hattstedtermarsch Elemenning von B5, Ostermarsch, Lagedeich, Wischweg W29 Hattstedtermarsch Lagedeich von Hauptstr., B5, Ostermarsch W30 Hattstedtermarsch Ostermarsch von Hauptstr., B5 W31 Hattstedtermarsch Gemeindestr. -

WBFSH Eventing Breeder 2020 (Final).Xlsx
LONGINES WBFSH WORLD RANKING LIST - BREEDERS OF EVENTING HORSES (includes validated FEI results from 01/10/2019 to 30/09/2020 WBFSH member studbook validated horses) RANK BREEDER POINTS HORSE (CURRENT NAME / BIRTH NAME) FEI ID BIRTH GENDER STUDBOOK SIRE DAM SIRE 1 J.M SCHURINK, WIJHE (NED) 172 SCUDERIA 1918 DON QUIDAM / DON QUIDAM 105EI33 2008 GELDING KWPN QUIDAM AMETHIST 2 W.H. VAN HOOF, NETERSEL (NED) 142 HERBY / HERBY 106LI67 2012 GELDING KWPN VDL ZIROCCO BLUE OLYMPIC FERRO 3 BUTT FRIEDRICH 134 FRH BUTTS AVEDON / FRH BUTTS AVEDON GER45658 2003 GELDING HANN HERALDIK XX KRONENKRANICH XX 4 PATRICK J KEARNS 131 HORSEWARE WOODCOURT GARRISON / WOODCOURT GARRISON104TB94 2009 MALE ISH GARRISON ROYAL FURISTO 5 ZG MEYER-KULENKAMPFF 129 FISCHERCHIPMUNK FRH / CHIPMUNK FRH 104LS84 2008 GELDING HANN CONTENDRO I HERALDIK XX 6 CAROLYN LANIGAN O'KEEFE 128 IMPERIAL SKY / IMPERIAL SKY 103SD39 2006 MALE ISH PUISSANCE HOROS 7 MME SOPHIE PELISSIER COUTUREAU, GONNEVILLE SUR127 MER TRITON(FRA) FONTAINE / TRITON FONTAINE 104LX44 2007 GELDING SF GENTLEMAN IV NIGHTKO 8 DR.V NATACHA GIMENEZ,M. SEBASTIEN MONTEIL, CRETEIL124 (FRA)TZINGA D'AUZAY / TZINGA D'AUZAY 104CS60 2007 MARE SF NOUMA D'AUZAY MASQUERADER 9 S.C.E.A. DE BELIARD 92410 VILLE D AVRAY (FRA) 122 BIRMANE / BIRMANE 105TP50 2011 MARE SF VARGAS DE STE HERMELLE DIAMANT DE SEMILLY 10 BEZOUW VAN A M.C.M. 116 Z / ALBANO Z 104FF03 2008 GELDING ZANG ASCA BABOUCHE VH GEHUCHT Z 11 A. RIJPMA, LIEVEREN (NED) 112 HAPPY BOY / HAPPY BOY 106CI15 2012 GELDING KWPN INDOCTRO ODERMUS R 12 KERSTIN DREVET 111 TOLEDO DE KERSER -

Kreisarchiv Nordfriesland Findbuch Des Bestandes Kreis Husum Erstellt
Kreisarchiv Nordfriesland Findbuch des Bestandes Kreis Husum erstellt 2004 Abteilung C14 Inhaltsverzeichnis 01. Landrat .................................................................................................................................................................................1 02. Kreispräsident ....................................................................................................................................................................2 03. Ausschüsse........................................................................................................................................................................4 03.01. Kreistags- und Kreisausschußprotokolle................................................................................................4 03.02. Sonstige Ausschußprotokolle....................................................................................................................6 03.03. Ausschußzusammensetzungen, Satzungen usw. ..............................................................................9 04. Kreisverwaltung................................................................................................................................................................12 04.01. Allgemein........................................................................................................................................................12 04.02. Organisation und Geschäftsführung .......................................................................................................15 -

Fourth Report of the Federal Republic of Germany in Accordance with Article 15 (1) of the European Charter for Regional Or Minority Languages
Fourth Report of the Federal Republic of Germany in accordance with Article 15 (1) of the European Charter for Regional or Minority Languages 2010 1 Contents No. Introduction Part A General situation and general framework 00101-00122 Part B Recommendations of the Committee of 00200-00401 Ministers Part C Protection of regional or minority 00701-00793 languages under Part II (Article 7) of the Charter Part D Implementation of the obligations 00800–61400 undertaken with regard to the various languages D.1 General policy remarks regarding the 00800-01400 various articles of the Charter D.2.1 Danish Danish in the Danish language area in 10801-11404 Schleswig-Holstein Art. 8 10801-10838 Art. 9 10901-10904 Art. 10 11001-11005 Art. 11 11101-11126 Art. 12 11201-11210 Art. 13 11301-11303 Art. 14 11401-11404 D.2.2 Sorbian Sorbian (Upper and Lower Sorbian) in the 20000-21313 Sorbian language area in Brandenburg and Saxony Art. 8 20801-20869 Art. 9 20901-20925 Art. 10 21001-21037 Art. 11 21101-21125 Art. 12 21201-21206 Art. 13 21301-21313 D.2.3 North North Frisian in the North Frisian language 30801-31403 Frisian area in Schleswig-Holstein Art. 8 30801-30834 2 Art. 9 30901-30903 Art. 10 31001-31009 Art. 11 31101-31115 Art. 12 31201-31217 Art. 13 31301 Art. 14 31401-31403 D.2.4 Sater Sater Frisian in the Sater Frisian language 40801-41302 Frisian area in Lower Saxony Art. 8 40801-40825 Art. 9 40901-40903 Art. 10 41001-41025 Art. 11 41101-41120 Art. -

Alkersum, Midlum, Nieblum, Oevenum Energetische Quartierskonzepte Auf Föhr
Alkersum, Midlum, Nieblum, Oevenum energetische Quartierskonzepte auf Föhr Die BIG Städtebau ist Partner der Kommunen als treuhänderischer Sanierungsträger, städtebaulicher Berater und Regionalentwickler. Zudem übernimmt sie Aufgaben der Projektentwicklung und -steuerung sowie Baubetreuung. Informationsauftakt am 22. März 2018 2 Übersicht Inhalt . Rahmenbedingungen der EU . Ziele der Bundes-und Landesregierung Schleswig-Holstein . Vorgehensweise bei den energetischen Quartierskonzepten . Nächste Schritte . Kontakt | Energetische Quartierskonzepte Alkersum, Nieblum, Midlum, Oevenum auf Föhr | März 2018 Klima in Mode? 3 Beispiele aus anderen Städten und Gemeinden Hannover: Klimafreundliches Energiekonzept für Neubau Wietzeaue Kitzingen: Gemeinsamer Kampf für ein besseres Klima Main-Taunus-Kreis: Gutes Klima erwünscht Schwedt: Schwedter Firmen treiben Energiewende voran Wurmlingen: will klimafreundlicher werden Murg: Mobil und klimaneutral bei Workshop in Murg Eurasburg: Klimakonzept für Eurasburg Landberg: Lohnend für Klima und Geldbeutel Bad Cannstatt: Lokal und emissionsfrei Alkersum, Nieblum, Midlum, Oevenum: 100% autark? | Energetische Quartierskonzepte Alkersum, Nieblum, Midlum, Oevenum auf Föhr | März 2018 Informationsauftakt am 22. März 2018 4 Inhalt . Rahmenbedingungen der EU . Ziele der Bundes- und Landesregierung Schleswig-Holstein . Vorgehensweise bei den energetischen Quartierskonzepten . Nächste Schritte . Kontakt Energetische Quartierskonzepte Alkersum, Nieblum, Midlum, Oevenum auf Föhr | März 2018 Rahmenbedingungen der EU -

Edited Volumes
PUBLIKATIONEN VON DR. STEFAN MAGNUSSEN (STAND: APRIL 2020) Monographie | Monography Magnussen, S. (2019). Burgen in umstrittenen Landschaften. Eine Studie zur Entwicklung und Funktion von Burgen im südlichen Jütland (1232–1443). Leiden: Sidestone (zugl.: Kiel, Univ., Diss., 2018). Herausgeberschaften | Edited Volumes Auge, O. & Magnussen, S. (Druck in Vorbereitung). Schwabstedt und die Bischöfe von Schleswig (1268–1705). Beiträge zur Geschichte der bischöflichen Burg und Residenz an der Treene. Kieler Werkstücke, A 52. Frankfurt am Main: Peter Lang. Magnussen, S. & Kossack, D. (2018). Castles as European Phenomena. Towards an international approach to medieval castles in Europe. Contributions to an international and interdisciplinary workshop in Kiel, February 2016. Kieler Werkstücke, A. Frankfurt am Main: Peter Lang. Wissenschaftliche Beiträge in Zeitschriften und Sammelbänden | Scientific Papers in Journals or edited Volumes Magnussen, S. (in Vorbereitung). Hof oder Burg? Überlegungen zu den Ursprüngen des Herrenhauses Uphusum in Bordelum. Magnussen, S. (in Vorbereitung). Periphery as a Center for Noble Policy. The Case of the Earls of Orkney from the Sinclair Clan (1379–1470/72). Grohse, I. P. & Magnussen, S. (in Vorbereitung). The confirmation of Earl William of Orkney in 1434 and its interregional context. Magnussen, S. (in Vorbereitung). Die Friesenburg. Ein Einheitsmythos der nordfriesischen Geschichtsschreibung? Magnussen, S. (Druck in Vorbereitung). Bischöfe als königliche Gesandte und Vermittler. Das Beispiel der Kirchenprovinz Magdeburg vom späten 10. bis ins 12. Jahrhundert. BÜNZ, E. & HUSCHNER, W. (Hg.), 1050 Jahre Erzbistum Magdeburg (968–2018). Die Errichtung und Etablierung des Erzbistums im europäischen und regionalen Kontext (10.–12. Jahrhundert). Italia Regia 7. Leipzig/Karlsruhe: Eudora. Magnussen, S. (Druck in Vorbereitung). Eine halbdunkle Schlossanlage im Glanz großer Politik.