EVALUATION of LINKAGE-BASED WEB DISCOVERY SYSTEMS by Cathal G. Gurrin a Dissertation Submitted in Partial Fulfillment of The
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rolling Stone Magazine's Top 500 Songs
Rolling Stone Magazine's Top 500 Songs No. Interpret Title Year of release 1. Bob Dylan Like a Rolling Stone 1961 2. The Rolling Stones Satisfaction 1965 3. John Lennon Imagine 1971 4. Marvin Gaye What’s Going on 1971 5. Aretha Franklin Respect 1967 6. The Beach Boys Good Vibrations 1966 7. Chuck Berry Johnny B. Goode 1958 8. The Beatles Hey Jude 1968 9. Nirvana Smells Like Teen Spirit 1991 10. Ray Charles What'd I Say (part 1&2) 1959 11. The Who My Generation 1965 12. Sam Cooke A Change is Gonna Come 1964 13. The Beatles Yesterday 1965 14. Bob Dylan Blowin' in the Wind 1963 15. The Clash London Calling 1980 16. The Beatles I Want zo Hold Your Hand 1963 17. Jimmy Hendrix Purple Haze 1967 18. Chuck Berry Maybellene 1955 19. Elvis Presley Hound Dog 1956 20. The Beatles Let It Be 1970 21. Bruce Springsteen Born to Run 1975 22. The Ronettes Be My Baby 1963 23. The Beatles In my Life 1965 24. The Impressions People Get Ready 1965 25. The Beach Boys God Only Knows 1966 26. The Beatles A day in a life 1967 27. Derek and the Dominos Layla 1970 28. Otis Redding Sitting on the Dock of the Bay 1968 29. The Beatles Help 1965 30. Johnny Cash I Walk the Line 1956 31. Led Zeppelin Stairway to Heaven 1971 32. The Rolling Stones Sympathy for the Devil 1968 33. Tina Turner River Deep - Mountain High 1966 34. The Righteous Brothers You've Lost that Lovin' Feelin' 1964 35. -

Ramones 2002.Pdf
PERFORMERS THE RAMONES B y DR. DONNA GAINES IN THE DARK AGES THAT PRECEDED THE RAMONES, black leather motorcycle jackets and Keds (Ameri fans were shut out, reduced to the role of passive can-made sneakers only), the Ramones incited a spectator. In the early 1970s, boredom inherited the sneering cultural insurrection. In 1976 they re earth: The airwaves were ruled by crotchety old di corded their eponymous first album in seventeen nosaurs; rock & roll had become an alienated labor - days for 16,400. At a time when superstars were rock, detached from its roots. Gone were the sounds demanding upwards of half a million, the Ramones of youthful angst, exuberance, sexuality and misrule. democratized rock & ro|ft|you didn’t need a fat con The spirit of rock & roll was beaten back, the glorious tract, great looks, expensive clothes or the skills of legacy handed down to us in doo-wop, Chuck Berry, Clapton. You just had to follow Joey’s credo: “Do it the British Invasion and surf music lost. If you were from the heart and follow your instincts.” More than an average American kid hanging out in your room twenty-five years later - after the band officially playing guitar, hoping to start a band, how could you broke up - from Old Hanoi to East Berlin, kids in full possibly compete with elaborate guitar solos, expen Ramones regalia incorporate the commando spirit sive equipment and million-dollar stage shows? It all of DIY, do it yourself. seemed out of reach. And then, in 1974, a uniformed According to Joey, the chorus in “Blitzkrieg Bop” - militia burst forth from Forest Hills, Queens, firing a “Hey ho, let’s go” - was “the battle cry that sounded shot heard round the world. -

Rhino Reissues the Ramones' First Four Albums
2011-07-11 09:13 CEST Rhino Reissues The Ramones’ First Four Albums NOW I WANNA SNIFF SOME WAX Rhino Reissues The Ramones’ First Four Albums Both Versions Available July 19 Hey, ho, let’s go. Rhino celebrates the Ramones’ indelible musical legacy with reissues of the pioneering group’s first four albums on 180-gram vinyl. Ramones, Leave Home, Rocket To Russia and Road To Ruin look amazing and come in accurate reproductions of the original packaging. More importantly, the records sound magnificent and were made using lacquers cut from the original analog masters by Chris Bellman at Bernie Grundman Mastering. For these releases, Rhino will – for the first time ever on vinyl – reissue the first pressing of Leave Home, which includes “Carbona Not Glue,” a track that was replaced with “Sheena Is A Punk Rocker” on all subsequent pressings. Joey, Johnny, Dee Dee and Tommy Ramone. The original line-up – along with Marky Ramone who joined in 1978 – helped blaze a trail more than 30 years ago with this classic four-album run. It’s hard to overstate how influential the group’s signature sound – minimalist rock played at maximum volume – was at the time, and still is today. These four landmark albums – Ramones (1976), Leave Home (1977), Rocket To Russia (1977) and Road to Ruin (1978) – contain such unforgettable songs as: “Blitzkrieg Bop,” “Sheena Is Punk Rocker,” “Beat On The Brat,” “Now I Wanna Sniff Some Glue,” “Pinhead,” “Rockaway Beach” and “I Wanna Be Sedated.” RAMONES Side One Side Two 1. “Blitzkrieg Bop” 1. “Loudmouth” 2. “Beat On The Brat” 2. -

21 Pilots Heathens the Allman Brothers Melissa Aloe Black I Need
21 Pilots Heathens The Allman Brothers Melissa Aloe Black I Need a Dollar Amy Winehouse Valerie Angus & Julia Stone Big Jet Plane The Animals House of the Rising Sun The Backboners Let it Blow My Way The Beatles Blackbird Come Together Here Comes the Sun Hey Jude In My Life I've Just Seen a Face I Wanna Hold Your Hand Let It Be Lucy in the Sky with Diamonds Norwegian Wood Octopus's Garden Oh Darlin Twist and shout Yesterday Yellow Submarine Bill Withers Ain't No Sunshine Stand By Me Billy Joel Piano Man Bob Dylan Knocking on Heaven’s Door Bob Marley Bob Marley Medley Is This Love No Woman No Cry Redemption Song Three Little Birds Bob Seger Turn the Page Cascada Every Time We Touch Cindy Lauper Girls Just Wanna Have Fun Coldplay Fix You Yellow Common Kings Alcoholic Cream Sunshine of Your Love Crowded House Weather With You DaFt Punk Ft. Pharell Get Lucky/Stronger David Guetta Ft Sia Titanium Death Cab For Cutie I Will Follow You Into the Dark The Decemberists Crane Wife Deep Blue Something Breakfast at Tiffany’s Derek and the Dominos Layla Disney Under the sea Dispatch The General Eagle Eye Cherry/Avicii Save Tonight/Wake Me Up The Eagles Hotel California Elvis Presley Can’t Help Falling in Love Eminem Lose Yourself Eurythmics Sweet Dreams Flight oF the Conchords Rhymnocerous Flobots Handlebars Fountain oF Wayne Stacey's mom George Ezra Budapest Gnarles Barkley Crazy Gotye Somebody I used to know Green Day Basket Case Good Riddance Imagine Dragons Radioactive The Isley Brothers Shout! Jack Johnson Banana Pancakes Jason Mraz I'm Yours Jimi Hendrix All Along the Watchtower Purple Haze Joan Jett I Love Rock and Roll John Paul Young Love is in the Air Johnny Cash Folsom Prison Blues John Lennon Imagine John Mellencamp Jack and Diane Journey Don't Stop Believing K’Naan Waving Flag Kenny Rogers The Gambler Ke$ha Tik Tok The Killers Mr. -

Songs Always Something There to Remind
Flashback Heart Attack - Songs Always Something There to Remind Me - Naked Eyes Anything Anything – Dramarama Any Way You Want It – Journey Bad Luck - Social Distortion Bizarre Love Triangle - New Order Blister in Sun/Add it Up/Gone Daddy Gone (Medley) - Violent Femmes Blitzkrieg Bop –Ramones Blue Monday - New Order Boys Don’t Cry – The Cure Centerfold - J Giles Band Come on Eileen – Dexies Midnight Runner Dancing w Myself - Billy Idol Destination Unknown – Missing Persons Don’t Change - INXS Don’t Stop Belivin – Journey Don’t You Forget About Me - Simple Minds Don’t You Want Me – Human League Dream Police - Cheap Trick Erotic City - Prince Everybody Wants to Rule the World - Tears for Fears Eyes without a Face – Billy Idol Fascination - Human League Fight for Your Right to Party – Beastie Boys Girls Just Wanna Have Fun – Cyndi Lauper Hungry Like the Wolf – Duran Duran I Love Rock n Roll - Joan Jett I Ran - A Flock of Seagulls In Cars - Gary Newman Jenny Jenny (867-5309) - Tommy Tutone Jesses Girl - Rick Springfield Just Can’t Get Enough - Depeche Mode Just Like Heaven - The Cure Just What I Needed - The Cars Land Down Under – Men at Work Let’s Go Crazy – Prince Live and Let Die – Wings Living on a Prayer – Bon Jovi Mexican Radio – Wall of VooDoo Melt With You - Modern English Metro - Berlin Million Miles Away – The Plimsouls Mirror in the Bathroom – English Beat Modern Love - David Bowie Need You Tonight - INXS Only the Lonely – The Motels Personal Jesus - Depeche Mode Pretty In Pink – Psychedelic Furs Promises Promises – Naked Eyes -

Power Syndicate
Beautiful Disaster 311 You Shook Me All Night Long AC/DC Walk This Way Aerosmith Would Alice In Chains Bring The Noise Anthrax/Public Enemy (1986) Show Me How To Live Audioslave Fight For Your Right Beastie Boys Paul Revere Beastie Boys The Metro Berlin White Wedding Billy Idol Everybody Wants You Billy Squier Paranoid Black Sabbath One Way or Another Blondie Burning For You Blue Oyster Cult Crazy Bitch Buckcherry Surrender Cheap Trick Clean My Wounds Corrosion of Conformity Butterfly Crazy Town Pour Some Sugar on Me Def Leppard Whip It Devo Down With The Sickness Disturbed Heavy Metal (Takin' a Ride) Don Felder Anything, Anything Dramarama Girls on Film Duran Duran Lose Yourself Eminem Sweet Dreams Eurythmics Say What You Will Fastway Paralyzer Finger Eleven I Ran Flock of Seagulls All Right Now Free Whatever Godsmack We're An American Band Grand Funk Railroad Brain Stew Green Day Mr. Brownstone Guns 'N' Roses Unsung Helmet Tonight Kool & The Gang Break Stuff Limp Bizkit One Step Closer Linkin Park My Own Worst Enemy Lit Simple Man Lynyrd Skynyrd The Beautiful People Marilyn Manson Symphony of Destruction Megadeth Sad But True Metallica No Parking on the Dance Floor Midnight Star This Is How We Do It Montel Jordan Kickstart My Heart Motley Crue Ace of Spades Motorhead Hella Good No Doubt Come Out And Play Offspring Hit Me With Your Best Shot Pat Benetar Snortin' Whiskey, Drinkin' Cocaine Pat Travers Band Young Lust Pink Floyd Metal Health Quiet Riot Killing In The Name Of Rage Against The Machine Sleep Now In The Fire Rage Against The -

Die Ramones Als Helden Der Pop-Kultur
Nutzungshinweis: Es ist erlaubt, dieses Dokument zu drucken und aus diesem Dokument zu zitieren. Wenn Sie aus diesem Dokument zitieren, machen Sie bitte vollständige Angaben zur Quelle (Name des Autors, Titel des Beitrags und Internet-Adresse). Jede weitere Verwendung dieses Dokuments bedarf der vorherigen schriftlichen Genehmigung des Autors. Quelle: http://www.mythos-magazin.de CHRISTIAN BÖHM Die Ramones als Helden der Pop-Kultur Inhalt 1. Einleitung 2. Punk und Pop 2.1 Punk und Punk Rock: Begriffsklärung und Geschichte 2.1.1 Musik und Themen 2.1.2 Kleidung 2.1.3 Selbstverständnis und Motivation 2.1.4 Regionale Besonderheiten 2.1.5 Punk heute 2.2 Exkurs: Pop-Musik und Pop-Kultur 2.3 Rekurs: Punk als Pop 3. Mythen, Helden und das Star-System 3.1 Der traditionelle Mythos- und Helden-Begriff 3.2 Der moderne Helden- bzw. Star-Begriff innerhalb des Star-Systems 4. Die Ramones 4.1 Einführung in das ‚ Wesen ’ Ramones 4.1.1 Kurze Biographie der Ramones 4.1.2 Musikalische Charakteristika 4.2 Analysen und Interpretationen 4.2.1 Analyse von Presseartikeln und Literatur 4.2.1.1 Zur Ästhetik der Ramones 4.2.1.1.1 Die Ramones als ‚ Familie ’ 4.2.1.1.2 Das Band-Logo 4.2.1.1.3 Minimalismus 4.2.1.2 Amerikanischer vs. britischer Punk: Vergleich von Ramones und Sex Pistols 4.2.1.3 Die Ramones als Helden 4.2.1.4 Eine typisch amerikanische Band? 4.2.2 Analyse von Ramones-Songtexten 4.2.2.1 Blitzkrieg Bop 4.2.2.2 Sheena Is A Punk Rocker 4.2.2.3 Häufig vorkommende Motive und Thematiken in Texten der Ramones 4.2.2.3.1 Individualismus 4.2.2.3.2 Motive aus dem Psychiatrie- Comic- und Horror-Kontext 4.2.2.3.3 Das Deutsche als Klischee 4.2.2.3.4 Spaß / Humor 4.3 Der Film Rock’n’Roll High School 4.3.1 Kurze Inhaltsangabe des Films 4.3.2 Analyse und Interpretation des Films 4.3.2.1 Die Protagonistin: Riff Randell [...] Is A Punk Rocker 4.3.2.2 Die Antagonistin: Ms. -

Live Band Karaoke Song List 2017
Live Band Karaoke Song List 2017 50s, 60s & 70s Pop/Rock A Hard Day’s Night – The Beatles All Day And All Of The Night – The Kinks American Woman – The Guess Who Back In The USSR – The Beatles Bad Moon Rising – CCR Bang A Gong – T. Rex Barracuda – Heart Be My Baby – The Ronettes Beast Of Burden – Rolling Stones Birthday – The Beatles Black Dog – Led Zeppelin Born To Be Wild – Steppenwolf Born to Run – Bruce Springsteen Break On Through – The Doors California Dreaming – Mamas & The Papas Come Together – The Beatles Communication Breakdown – Led Zeppelin Crazy Little Thing Called Love – Queen Dead Flowers – The Rolling Stones Don’t Let Me Be Misunderstood – The Animals Don’t Let Me Down – The Beatles Dream On – Aerosmith D’yer Mak’er – Led Zeppelin Fat Bottom Girls – Queen Funk #49 – James Gang Get Back – The Beatles Good Times and Bad Times – Led Zeppelin Happy Together – The Turtles Heartbreaker/ Living Loving Maid – Led Zeppelin Helter Skelter – The Beatles Hey Joe – Jimi Hendrix Hit Me With Your Best Shot – Pat Benatar Hold On Loosely – .38 Special Hound Dog – Elvis Presley House Of The Rising Sun – The Animals I Got You Babe – Sonny and Cher Immigrant Song – Led Zeppelin Into the Mystic – Van Morrison Jumpin’ Jack Flash – The Rolling Stones Lights – Journey Manic Depression – Jimi Hendrix Mony Mony – Tommy James and the Shondells More Than A Feeling – Boston Oh! Darling – The Beatles Paint It Black – Rolling Stones Peggy Sue – Buddy Holly Purple Haze – Jimi Hendrix Revolution – The Beatles Rock and Roll – Led Zeppelin Rock And Roll -

Ramones, Foi Formada Em 1974, Forest Hills, Queens, Nova Iorque, EUA
“ROCKAWAY BEACH” Por: TÇwxÜáÉÇ VÄx|àÉÇ eÉwÜ|zâxá 09/2011 BATERA CENTER-SBO/SP. A banda de Punk Rock Ramones, foi formada em 1974, Forest Hills, Queens, Nova Iorque, EUA. Foi uma das bandas mais influentes da história do rock mundial, e considerada a precursora do estilo Punk, composta inicialmente por Joey, Dee Dee e Johnny. Ao longo de seus 22 anos de existência, os Ramones totalizaram 2.263 apresentações ao redor do mundo. O último show foi realizado em Los Angeles, Califórnia, em 6 de agosto de 1996. Em 2 de março de 2002 a banda foi incluída no Salão da Fama do Rock and Roll, e em 2004 a revista Rolling Stone elegeu as cem maiores personalidades dos primeiros cinqüenta anos do rock, ficando os Ramones em 26º lugar. A música “ROCKAWAY BEACH” A canção pertence ao terceiro álbum de estúdio do Ramones, o “Rocket to Russia”, de 1977. O álbum inclui algumas das mais conhecidas canções dos Ramones, e em 2003, o álbum foi colocado número 105 na lista da revista Rolling Stone dos 500 melhores álbuns de todos os tempos. Foi o último álbum com o baterista original Tommy Ramone que saiu da banda para trabalhar como produtor musical. Integrantes: Joey Ramone (voz), Johnny Ramone (guitarra), Dee Dee Ramone (baixo), Tommy Ramone (bateria). OObateristabaterista “TOMMY RAMONE” Tamás Erdélyi (Tommy Ramone) nasceu dia 29 de Janeiro de 1952, Budapeste, Hungria. É um produtor e baterista, o último integrante original sobrevivente da banda Ramones. Após a gravação do terceiro disco do Ramones o Rockway Beach de 1977, Tommy deixou a bateria e virou produtor da banda. -
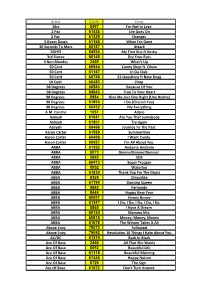
Karaoke List
Artist Code Song 10cc 8497 I'm Not In Love 2 Pac 61426 Life Goes On 2 Pac 61425 Changes 3 Doors Down 61165 When I'm Gone 30 Seconds To Mars 60147 Attack 3OH!3 84954 My First Kiss ft Kesha 3rd Storee 60145 Dry Your Eyes 4 Non Blondes 2459 What's Up 50 Cent 60944 Candy Shop ft. Olivia 50 Cent 61147 In Da Club 50 Cent 60748 21 Questions ft Nate Dogg 50 Cent 60483 Pimp 98 Degrees 60543 Because Of You 98 Degrees 84943 True To Your Heart 98 Degrees 8984 Give Me Just One Night (Una Noche) 98 Degrees 61890 I Do (Cherish You) 98 Degrees 60332 My Everything A.M. Canche 1051 Adoro Aaliyah 61681 Are You That Somebody Aaliyah 61801 Try Again Aaliyah 60468 Journey To The Past Aaron Carter 61588 Summertime Aaron Carter 60458 I Want Candy Aaron Carter 60557 I'm All About You ABBA 61352 Andante Andante ABBA 8073 Gimme!Gimme!Gimme! ABBA 2692 SOS ABBA 60413 Super Trooper ABBA 8952 Waterloo ABBA 61830 Thank You For The Music ABBA 8369 Chiquitita ABBA 61199 Dancing Queen ABBA 8842 Fernando ABBA 8444 Happy New Year ABBA 60001 Honey Honey ABBA 61347 I Do, I Do, I Do, I Do, I Do ABBA 8865 I Have A Dream ABBA 60134 Mamma Mia ABBA 60818 Money, Money, Money ABBA 61678 The Winner Takes It All Above Envy 79073 Followed Above Envy 79092 Revolution 10 Things I Hate About You AC/DC 61319 Back In Black Ace Of Base 2466 All That She Wants Ace Of Base 8592 Beautiful Life Ace Of Base 61118 Beautiful Morning Ace Of Base 61346 Happy Nation Ace Of Base 8729 The Sign Ace Of Base 61672 Don't Turn Around Acid House Kings 61904 This Heart Is A Stone Acquiesce 60699 Oasis Adam -

Read Razorcake Issue #48 As a PDF
RIP THIS PAGE OUT Razorcake LV D ERQD¿GH QRQSUR¿W PXVLF PDJD]LQH GHGLFDWHG WR If you wish to donate through the mail, PLEASE supporting independent music culture. All donations, subscriptions, please rip this page out and send it to: and orders directly from us—regardless of amount—have been large Razorcake/Gorsky Press, Inc. components to our continued survival. $WWQ1RQSUR¿W0DQDJHU PO Box 42129 Razorcake has been very fortunate. Why? By the mere fact that Los Angeles, CA 90042 we still exist today. By the fact that we have over one hundred regular contributors—in addition to volunteers coming in every week day—at a time when our print media brethren are getting knocked down and out. Name What you may not realize is that the fanciest part about Razorcake is the zine you’re holding in your hands. We put everything we have into Address it. We pay attention to the pragmatic details that support our ideology. Our entire operations are run out of a 500 square foot basement. We don’t outsource any labor we can do ourselves (we don’t own a printing press or run the postal service). We’re self-reliant and take great pains E-mail WRFRYHUDERRPLQJIRUPRIPXVLFWKDWÀRXULVKHVRXWVLGHRIWKHPXVLF Phone industry, that isn’t locked into a fair weather scene or subgenre. Company name if giving a corporate donation 6RKHUH¶VWRDQRWKHU\HDURIJULWWHGWHHWKKLJK¿YHVDQGVWDULQJDW disbelief at a brand new record spinning on a turntable, improving our Name if giving on behalf of someone quality of life with each spin. Donation amount If you would like to give Razorcake some -

RAMONES: 40Th ANNIVERSARY DELUXE EDITION Track Listing
RAMONES: 40th ANNIVERSARY DELUXE EDITION Track Listing Disc One: Original Album Stereo Version 1. “Blitzkrieg Bop” 2. “Beat On The Brat” 3. “Judy Is A Punk” 4. “I Wanna Be Your Boyfriend” 5. “Chain Saw” 6. “Now I Wanna Sniff Some Glue” 7. “I Don’t Wanna Go Down To The Basement” 8. “Loudmouth” 9. “Havana Affair” 10. “Listen To My Heart” 11. “53rd & 3rd” 12. “Let’s Dance” 13. “I Don’t Wanna Walk Around With You” 14. “Today Your Love, Tomorrow The World” 40th Anniversary Mono Mix 15. “Blitzkrieg Bop”* 16. “Beat On The Brat”* 17. “Judy Is A Punk”* 18. “I Wanna Be Your Boyfriend”* 19. “Chain Saw”* 20. “Now I Wanna Sniff Some Glue”* 21. “I Don’t Wanna Go Down To The Basement”* 22. “Loudmouth”* 23. “Havana Affair”* 24. “Listen To My Heart”* 25. “53rd & 3rd”* 26. “Let’s Dance”* 27. “I Don’t Wanna Walk Around With You”* 28. “Today Your Love, Tomorrow The World”* Disc Two: Single Mixes, Outtakes, and Demos 1. “Blitzkrieg Bop” (Original Stereo Single Version) 2. “Blitzkrieg Bop” (Original Mono Single Version) 3. “I Wanna Be Your Boyfriend” (Original Stereo Single Version) 4. “I Wanna Be Your Boyfriend” (Original Mono Single Version) 5. “Today Your Love, Tomorrow The World” (Original Uncensored Vocals)* 6. “I Don’t Care” (Demo) 7. “53rd & 3rd” (Demo)* 8. “Loudmouth” (Demo)* 9. “Chain Saw” (Demo)* 10. “You Never Should Have Opened That Door” (Demo) 11. “I Wanna Be Your Boyfriend” (Demo)* 12. “I Can’t Be” (Demo) 13. “Today Your Love, Tomorrow The World” (Demo)* 14.