Freebasic-Einsteigerhandbuch
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Beginner's Guide to Freebasic
A Beginner’s Guide to FreeBasic Richard D. Clark Ebben Feagan A Clark Productions / HMCsoft Book Copyright (c) Ebben Feagan and Richard Clark. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". The source code was compiled under version .17b of the FreeBasic compiler and tested under Windows 2000 Professional and Ubuntu Linux 6.06. Later compiler versions may require changes to the source code to compile successfully and results may differ under different operating systems. All source code is released under version 2 of the Gnu Public License (http://www.gnu.org/copyleft/gpl.html). The source code is provided AS IS, WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. Microsoft Windows®, Visual Basic® and QuickBasic® are registered trademarks and are copyright © Microsoft Corporation. Ubuntu is a registered trademark of Canonical Limited. 2 To all the members of the FreeBasic community, especially the developers. 3 Acknowledgments Writing a book is difficult business, especially a book on programming. It is impossible to know how to do everything in a particular language, and everyone learns something from the programming community. I have learned a multitude of things from the FreeBasic community and I want to send my thanks to all of those who have taken the time to post answers and examples to questions. -

Screenshot Showcase 1
Volume 125 June, 2017 VirtualBox: Going Retro On PCLinuxOS Inkscape Tutorial: Creating Tiled Clones, Part Three An Un-feh-gettable Image Viewer Game Zone: Sunless Sea PCLinuxOS Family Member Spotlight: arjaybe GOG's Gems: Star Trek 25th Anniversary Tip Top Tips: HDMI Sound On Encrypt VirtualBox Virtual Machines PCLinuxOS Recipe Corner PCLinuxOS Magazine And more inside ... Page 1 In This Issue... 3 From The Chief Editor's Desk... Disclaimer 4 Screenshot Showcase 1. All the contents of The PCLinuxOS Magazine are only for general information and/or use. Such contents do not constitute advice 5 An Un-feh-gettable Image Viewer and should not be relied upon in making (or refraining from making) any decision. Any specific advice or replies to queries in any part of the magazine is/are the person opinion of such 8 Screenshot Showcase experts/consultants/persons and are not subscribed to by The PCLinuxOS Magazine. 9 Inkscape Tutorial: Create Tiled Clones, Part Three 2. The information in The PCLinuxOS Magazine is provided on an "AS IS" basis, and all warranties, expressed or implied of any kind, regarding any matter pertaining to any information, advice 11 ms_meme's Nook: Root By Our Side or replies are disclaimed and excluded. 3. The PCLinuxOS Magazine and its associates shall not be liable, 12 PCLinuxOS Recipe Corner: Skillet Chicken With Orzo & Olives at any time, for damages (including, but not limited to, without limitation, damages of any kind) arising in contract, rot or otherwise, from the use of or inability to use the magazine, or any 13 VirtualBox: Going Retro On PCLinuxOS of its contents, or from any action taken (or refrained from being taken) as a result of using the magazine or any such contents or for any failure of performance, error, omission, interruption, 30 Screenshot Showcase deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorized access to, alteration of, or use of information 31 Tip Top Tips: HDMI Sound On contained on the magazine. -

Programmierung Unter GNU/Linux Für Einsteiger
Programmierung unter GNU/Linux fur¨ Einsteiger Edgar 'Fast Edi' Hoffmann Community FreieSoftwareOG [email protected] 7. September 2016 Programmierung (von griechisch pr´ogramma Vorschrift\) bezeichnet die T¨atigkeit, " Computerprogramme zu erstellen. Dies umfasst vor Allem die Umsetzung (Implementierung) des Softwareentwurfs in Quellcode sowie { je nach Programmiersprache { das Ubersetzen¨ des Quellcodes in die Maschinensprache, meist unter Verwendung eines Compilers. Programmierung Begriffserkl¨arung 2 / 35 Dies umfasst vor Allem die Umsetzung (Implementierung) des Softwareentwurfs in Quellcode sowie { je nach Programmiersprache { das Ubersetzen¨ des Quellcodes in die Maschinensprache, meist unter Verwendung eines Compilers. Programmierung Begriffserkl¨arung Programmierung (von griechisch pr´ogramma Vorschrift\) bezeichnet die T¨atigkeit, " Computerprogramme zu erstellen. 2 / 35 Programmierung Begriffserkl¨arung Programmierung (von griechisch pr´ogramma Vorschrift\) bezeichnet die T¨atigkeit, " Computerprogramme zu erstellen. Dies umfasst vor Allem die Umsetzung (Implementierung) des Softwareentwurfs in Quellcode sowie { je nach Programmiersprache { das Ubersetzen¨ des Quellcodes in die Maschinensprache, meist unter Verwendung eines Compilers. 2 / 35 Programme werden unter Verwendung von Programmiersprachen formuliert ( kodiert\). " In eine solche Sprache ubersetzt\¨ der Programmierer die (z. B. im Pflichtenheft) " vorgegebenen Anforderungen und Algorithmen. Zunehmend wird er dabei durch Codegeneratoren unterstutzt,¨ die zumindest -

Freebasic-Einsteigerhandbuch
FreeBASIC-Einsteigerhandbuch Grundlagen der Programmierung in FreeBASIC von S. Markthaler Stand: 11. Mai 2015 Einleitung 1. Über das Buch Dieses Buch ist für Programmieranfänger gedacht, die sich mit der Sprache FreeBASIC beschäftigen wollen. Es setzt keine Vorkenntnisse über die Computerprogrammierung voraus. Sie sollten jedoch wissen, wie man einen Computer bedient, Programme installiert und startet, Dateien speichert usw. Wenn Sie bereits mit Q(uick)BASIC gearbeitet haben, finden Sie in Kapitel 1.3 eine Zusammenstellung der Unterschiede zwischen beiden Sprachen. Sie erfahren dort auch, wie Sie Q(uick)BASIC-Programme für FreeBASIC lauffähig machen können. Wenn Sie noch über keine Programmiererfahrung verfügen, empfiehlt es sich, die Kapitel des Buches in der vorgegebenen Reihenfolge durchzuarbeiten. Wenn Ihnen einige Konzepte bereits bekannt sind, können Sie auch direkt zu den Kapiteln springen, die Sie interessieren. 2. In diesem Buch verwendete Konventionen In diesem Buch tauchen verschiedene Elemente wie Variablen, Schlüsselwörter und besondere Textabschnitte auf. Damit Sie sich beim Lesen schnell zurechtfinden, werden diese Elemente kurz vorgestellt. Befehle und Variablen, die im laufenden Text auftauchen, werden in nichtproportionaler Schrift dargestellt. Schlüsselwörter wie PRINT werden in Fettdruck geschrieben, während für andere Elemente wie variablenname die normale Schriftstärke eingesetzt wird. Quelltexte werden vollständig in nichtproportionaler Schrift gesetzt und mit einem Begrenzungsrahmen dargestellt. Auch hier werden Schlüsselwörter fett gedruckt. Der Dateiname des Programms wird oberhalb des Quelltextes angezeigt. Quelltext 1.1: Hallo Welt ’ Kommentar: Ein gewoehnliches Hallo-Welt-Programm CLS PRINT "Hallo FreeBASIC-Welt!" SLEEP 5 END ii Einleitung Es empfiehlt sich, die Programme abzutippen und zu testen. Die meisten Programme sind sehr kurz und können schnell abgetippt werden – auf der anderen Seite werden Sie Codebeispiele, die Sie selbst getippt haben, leichter behalten. -

An ECMA-55 Minimal BASIC Compiler for X86-64 Linux®
Computers 2014, 3, 69-116; doi:10.3390/computers3030069 OPEN ACCESS computers ISSN 2073-431X www.mdpi.com/journal/computers Article An ECMA-55 Minimal BASIC Compiler for x86-64 Linux® John Gatewood Ham Burapha University, Faculty of Informatics, 169 Bangsaen Road, Tambon Saensuk, Amphur Muang, Changwat Chonburi 20131, Thailand; E-mail: [email protected] Received: 24 July 2014; in revised form: 17 September 2014 / Accepted: 1 October 2014 / Published: 1 October 2014 Abstract: This paper describes a new non-optimizing compiler for the ECMA-55 Minimal BASIC language that generates x86-64 assembler code for use on the x86-64 Linux® [1] 3.x platform. The compiler was implemented in C99 and the generated assembly language is in the AT&T style and is for the GNU assembler. The generated code is stand-alone and does not require any shared libraries to run, since it makes system calls to the Linux® kernel directly. The floating point math uses the Single Instruction Multiple Data (SIMD) instructions and the compiler fully implements all of the floating point exception handling required by the ECMA-55 standard. This compiler is designed to be small, simple, and easy to understand for people who want to study a compiler that actually implements full error checking on floating point on x86-64 CPUs even if those people have little programming experience. The generated assembly code is also designed to be simple to read. Keywords: BASIC; compiler; AMD64; INTEL64; EM64T; x86-64; assembly 1. Introduction The Beginner’s All-purpose Symbolic Instruction Code (BASIC) language was invented by John G. -

Xfont Documentation
XFont Lib for FreeBASIC Introduction XFont is Object Oriented Programming (OOP) library designed for drawing smooth font text. This lib support 1, 2, 4, 8, 15/16, 24/32 bpp depth. Some of the most exciting features: - Support alpha blending. This works in 15/16 and 24/32 bpp depths. - Alpha mask for drawing smooth font text. - 8 fonts slot can be loaded with x-font file format. - Included with internal standard font. - Easy to use. - No initialize needed between switching screen mode. - No ScreenLock/ScreenUnlock switch needed (For FB 0.20.0b or above only). - Unicode support (ISO 10646). About XFont Lib was developed by Victor Phoa. Copyright 2008-2010 © Xaviorsoft Studios. All Rights Reserved. Note All example code written is designed for FB 0.20.0 or above. FB 0.18.x user should add ScreenLock/ScreenUnlock switch manually to make example code working correctly. Keywords List (Arrange by mostly used order) DrawString Syntax Declare Sub DrawString Overload (ByVal Target As Any Ptr=0, ByRef Text As wString Ptr, ByVal X As Short, _ ByVal Y As Short, ByVal ScaleX As Single=1, ByVal ScaleY As Single=1, _ ByVal Direction As uByte=0) Declare Sub DrawString Overload (ByVal Target As Any Ptr=0, ByRef Text As String, ByVal X As Short, _ ByVal Y As Short, ByVal ScaleX As Single=1, ByVal ScaleY As Single=1, _ ByVal Direction As uByte=0) Declare Sub DrawString Overload (ByVal Target As Any Ptr=0, ByRef Text As uInteger Ptr, ByVal X As Short, _ ByVal Y As Short, ByVal ScaleX As Single=1, ByVal ScaleY As Single=1, _ ByVal Direction As uByte=0) Usage Drawstring [target], text, x, y, [scalex], [scaley], [direction] Description Displays text at x, y in graphics modes. -
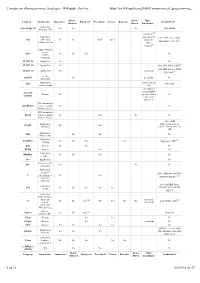
Comparison of Programming Languages - Wikipedia, the Free
Comparison of programming languages - Wikipedia, the free ... https://en.wikipedia.org/wiki/Comparison_of_programming_... Object- Event- Other Language Intended use Imperative Functional Procedural Generic Reflective Standardized? Oriented Driven Paradigm(s) Application, ActionScript 3.0 Yes Yes Yes 1996, ECMA client-side, Web concurrent,[4] [5] Application, distributed, 1983, 2005, 2012, ANSI, Ada embedded, Yes Yes Yes[2] Yes[3] imperative ISO, GOST 27831-88[7] realtime, system object- oriented[6] Highly domain- specific, Aldor Yes Yes Yes No symbolic computing ALGOL 58 Application Yes No ALGOL 60 Application Yes 1960, IFIP WG 2.1, ISO[8] 1968, IFIP WG 2.1, GOST ALGOL 68 Application Yes concurrent 27974-88,[9] Parallel Ateji PX Yes pi calculus No application Application, array-oriented, APL 1989, ISO data processing tacit any, syntax is usually highly Assembly General Yes specific, related No language to the target processor GUI automation AutoHotkey (macros), highly Yes No domain-specific GUI automation AutoIt (macros), highly Yes Yes Yes No domain-specific 1983, ANSI Application, (http://portal.acm.org BASIC Yes Yes education /citation.cfm?id=988221), ISO Application, BBj Yes Yes No business, Web Application, BeanShell Yes Yes Yes Yes [10] scripting In progress, JCP BitC System Yes Yes No BLISS System Yes No Application, BlitzMax Yes Yes Yes No game Boo Application No domain-specific, Bro Yes Yes No application Application, [11] system, 1989, ANSI C89, ISO C90, C general purpose, Yes Yes ISO C99, ISO C11[12] low-level operations 1998, ISO/IEC -

Purebasic Vs Freepascal
Purebasic vs freepascal click here to download Most mentioned BASIC dialects are not as multi platform as Lazarus or even Freepascal except Purebasic and Realbasic. Logged. Today I downloaded and installed Lazarus (based on Free Pascal) just to . Most of these extra libs for PureBasic are created in C/C++ or are Read DirectUIHWND class window and. But, if you want write native applications, not requiring a third-party dlls and platforms, or native and cross- platform applications, you can't use. I downloaded both Lazarus & PureBasic and tried both and they look OK. I can not decide I love the Laz IDE, it's much faster than www.doorway.ru and. If I could just install a file (like a mdb, or maybe a Firebird DB file), thats use this for its awesome platform support - have a look at PureBasic. There is a language out there called pure basic, which is actually the . just like I can see why people liked Delphi or FreePascal; it's a nicer. Today I'm writing about PureBasic, a portable programming language, that works on Compared to Lazarus which uses freepascal this is small. just use out of the box, e.g. Threading, DLL creation (or sharedobjects), XML, JSON, Sqlite. The following tables list notable software packages that are nominal IDEs; standalone tools . PureBasic · Fantaisie Software · Proprietary, Yes, Yes, Yes, AmigaOS .. Free Pascal IDE, Volunteers, / February 15, , Yes, Yes, Yes . PyQt · GPLv3 "or later", Yes, until version and since version , Yes, since. In my honest opinion, there is not any language which is the easiest to start with, you could start with C++ or with PureBasic, or with C. -

Freebasic (Autore: Vittorio Albertoni)
FreeBASIC (autore: Vittorio Albertoni) Premessa Il linguaggio BASIC nasce nel 1964 presso l’Università di Dartmouth, ad opera di John Keme- ney e Thomas Kurtz, per facilitare l’accesso al mainframe GE-225 anche a utenti non particolar- mente dotati di conoscenze informatiche: tant’è vero che il nome del linguaggio è l’acronimo di Beginner’s All-purpose Symbolic Instruction Code (codice di istruzione simbolica di uso generale per principiante). Nel 1975, quando viene messo in vendita il primo computer da tavolo ad uso personale, il MITS Altair 8800, Bill Gates e Paul Allen creano il linguaggio Altair BASIC per programmarlo, derivandolo dal BASIC di Dartmouth. Il successo è tale che, nello stesso anno, i due danno vita alla Microsoft e l’Altair BASIC diviene Microsoft BASIC, proprietà intellettuale della Microsoft. Anche i primi adattamenti sviluppati dalla Commodore (per VIC 20 e Commodore 64) e dalla Apple avvengono su licenza Microsoft. Altra ondata di successo coincide con il lancio del PC IBM 5150 del 1981, che incorpora un dialetto del BASIC chiamato BASICA: subito dopo, nel 1983, partendo da BASICA la Microsoft sviluppa una nuova versione del BASIC, chiamata GW-BASIC, che decreta il predominio del BASIC Microsoft per la programmazione dei personal computer1. Al GW-BASIC fanno seguito rilasci di altre versioni, sempre da parte di Microsoft. Nel 1985 esce QuickBASIC, che, per la prima volta nella storia del BASIC, incorpora un com- pilatore per eseguibili DOS. Tutte le versioni precedenti richiedono un interprete per essere eseguite. Nel 1991 esce QBASIC, versione ridotta di QuickBASIC, senza compilatore ma, nel frattempo, viene rilasciata la prima versione di Visual BASIC, cavallo di battaglia della Microsoft fino alla versione 6 del 1998 ed è tuttora possibile programmare in Visual BASIC su Visual Studio per il nuovo ambiente .NET Framework. -
Text Editing
eFTE2 user and reference manual By Alfredo Fernández Díaz November, 2017 Last revision: 2017-11-01 Table of Contents • What is eFTE2? • Installation ◦ Compatibility with old FTE installs ◦ Base files ◦ On OS/2 / eCS / ArcaOS ◦ On Windows ◦ On Linux ◦ List of Configuration Files ▪ Main/Global configuration ▪ User interface color definitions and schemes ▪ HTML character sets and conversion tools selectable from menus (incomplete) ▪ Mode specific text highlighting ▪ User interface styles ▪ Experimental (incomplete) expansions of the UI (included as a base for further development) ▪ Mode-specific keyboard hotkey definitions ▪ Abbreviation expansion for various modes ▪ Default Menus (Normally English but can be any at user discretion) ▪ Internationalized menus where xx is the country code (optional) • Using eFTE2: out of the box ◦ Manual conventions ◦ Command line options ▪ Options ▪ Examples ◦ Standard 'plain' text editing ▪ Text vs Plain mode ▪ Status line ▪ Keys, menus and tasks ▪ File ▪ Edit ▪ Block ▪ Search ▪ Fold ▪ Options ▪ Local (pop-up) editing menu ◦ Non-editing tasks ▪ Window ▪ Routines: parts of a file ▪ Buffers ▪ Directory ▪ Help ▪ EventMapView ◦ Editing files to be used with other programs ▪ Output messages from external applications ▪ Tools: standard external programs ◦ Regular expressions ▪ Introduction ▪ Regular expressions in action ▪ Regular expressions in eFTE2 ◦ Editing modes (example: HTML) ▪ New colors schemes ▪ New editing functions ▪ New and tailored tools ◦ Alternate editing modes included • Customizing and extending -

Howto: Rapid GUI Creation with Freebasic and Glade/Gtk by Klaus Siebke
Howto: Rapid GUI creation with FreeBasic and glade/Gtk by Klaus Siebke, www.siebke.com Preface For a longer time I was looking for a programming environment that offers both: easy to use and platform independent. Some weeks ago I found FreeBasic to fulfill these requirements perfectly. Just code your program once and run it in native mode under MS Windows and Linux (and if you like you can still run it under DOS). Additionally FreeBasic in combination with glade/Gtk offers a simple framework to create identical GUI applications for Windows and for Linux. The only lack so far is a tool to simplify the GUI program creation with glade/Gtk. So I wrote a small utility named “glade2bas“ which will help you to realize your own GUI application with FreeBasic and glade/Gtk. What you need 1. First of all you need the FreeBasic compiler for your preferred OS which can be downloaded from: http://www.freebasic.net/. 2. Then you need to install Gtk. If you are using Linux it's already included in your distribution (at least in Ubuntu/Kubuntu or openSuSE). Just go to your package manager (apt or yast) and select it. If you are using MS Windows, download the latest binary from the official server: ftp://ftp.gtk.org/pub/gtk/ and install it. 3. The next component you need is glade, the user interface builder. For Linux users it's the same as for Gtk: install the package with your package manager – that's it. Users working with MS Windows should go to http://gladewin32.sourceforge.net/, download the latest version of glade and install it. -

Hello, ABAP Calling
Tricktresor Hello, Library Calling – Nutzung dynamischer Bibliotheken mit ABAP® Hello, Library Calling von Stefan Schnell Oftmals besteht der Wunsch oder sogar die Notwendigkeit mit einem ABAP®-Programm von einem SAP®- Applikationsserver auf dem Präsentationsserver mit dem Betriebssystem Microsoft® Windows® Operationen auszuführen. Zu diesem Zweck bieten ABAP® und der SAP® GUI für Windows® einige Möglichkeiten an, die jedoch nicht alle Wege bereitstellen. So ist beispielsweise ein direkter Zugriff auf dynamische Bibliotheken, auch als DLLs bekannt, und eine Kommunikation mit dem GUI, sobald das ABAP®-Programm im Hintergrund ausgeführt wird, nicht vorgesehen. Im Folgenden wird beschrieben wie mit der Programmiersprache FreeBASIC eine DLL erstellt und diese mittels DynamicWrapperX mit einem ABAP®-Programm verwendet werden kann. Weiterhin wird aufgezeigt wie dieses Szenario mit Background Light auch in Hintergrundprozessen verwendet werden kann. Die Wahl der Programmiersprache zur Erstellung OutputDebugString Text End Sub einer DLL ist frei. Prinzipiell spielt es keine Rolle welche Sprache verwendet wird. Hier fiel die Wahl '-Function MsgBox----------------------------------- Function MsgBox Alias "MsgBox" _ exemplarisch auf FreeBASIC, jedoch hätte ebenso (ByVal Text As String, _ ein anderer BASIC-, Pascal- oder C-Dialekt gewählt ByVal Caption As String, _ ByVal Style As Integer) As Integer Export werden können. MsgBox = MessageBox(NULL, Text, Caption, Style) End Function Wir sprechen FreeBASIC '-Function CircleArea------------------------------- Function CircleArea Alias "CircleArea" _ FreeBASIC ist ein frei verfügbarer 32-bit x86- (ByVal Diameter As Single) _ ® Compiler für Windows und Linux. Die ursprüng- As Single Export liche Idee hinter dieser Sprache ist die Fortführung Const Pi As Double = 3.1415926535897932 CircleArea = Pi * (Sqr(Diameter) / 4) ® eines Ansatzes mit hoher Microsoft QuickBASIC- End Function Kompatibilität.