Deep Reinforcement Learning for Soft Robotic Applications: Brief Overview with Impending Challenges
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Capability by Stacking: the Current Design Heuristic for Soft Robots
biomimetics Review Capability by Stacking: The Current Design Heuristic for Soft Robots Stephen T. Mahon 1 ID , Jamie O. Roberts 1,2, Mohammed E. Sayed 1, Derek Ho-Tak Chun 1,2 ID , Simona Aracri 1, Ross M. McKenzie 1,2, Markus P. Nemitz 1,3 and Adam A. Stokes 1,* 1 School of Engineering, The Institute for Integrated Micro and Nano Systems, The University of Edinburgh, The King’s Buildings, Edinburgh EH9 3LJ, UK; [email protected] (S.T.M.); [email protected] (J.O.R.); [email protected] (M.E.S.); [email protected] (D.H.-T.C.); [email protected] (S.A.); [email protected] (R.M.M.); [email protected] (M.P.N.) 2 Engineering and Physical Sciences Research Council (EPSRC) Centre for Doctoral Training (CDT) in Robotics and Autonomous Systems, School of Informatics, The University of Edinburgh, Edinburgh EH9 3LJ, UK 3 Department of Computer Science and Engineering, University of Michigan, 2260 Hayward St. BBB3737, Ann Arbor, MI 48109, USA * Correspondence: [email protected]; Tel.: +44-131-650-5611 Received: 1 June 2018; Accepted: 10 July 2018; Published: 13 July 2018 Abstract: Soft robots are a new class of systems being developed and studied by robotics scientists. These systems have a diverse range of applications including sub-sea manipulation and rehabilitative robotics. In their current state of development, the prevalent paradigm for the control architecture in these systems is a one-to-one mapping of controller outputs to actuators. -

Design and Evaluation of Modular Robots for Maintenance in Large Scientific Facilities
UNIVERSIDAD POLITÉCNICA DE MADRID ESCUELA TÉCNICA SUPERIOR DE INGENIEROS INDUSTRIALES DESIGN AND EVALUATION OF MODULAR ROBOTS FOR MAINTENANCE IN LARGE SCIENTIFIC FACILITIES PRITHVI SEKHAR PAGALA, MSC 2014 DEPARTAMENTO DE AUTOMÁTICA, INGENIERÍA ELECTRÓNICA E INFORMÁTICA INDUSTRIAL ESCUELA TÉCNICA SUPERIOR DE INGENIEROS INDUSTRIALES DESIGN AND EVALUATION OF MODULAR ROBOTS FOR MAINTENANCE IN LARGE SCIENTIFIC FACILITIES PhD Thesis Author: Prithvi Sekhar Pagala, MSC Advisors: Manuel Ferre Perez, PhD Manuel Armada, PhD 2014 DESIGN AND EVALUATION OF MODULAR ROBOTS FOR MAINTENANCE IN LARGE SCIENTIFIC FACILITIES Author: Prithvi Sekhar Pagala, MSC Tribunal: Presidente: Dr. Fernando Matía Espada Secretario: Dr. Claudio Rossi Vocal A: Dr. Antonio Giménez Fernández Vocal B: Dr. Juan Antonio Escalera Piña Vocal C: Dr. Concepción Alicia Monje Micharet Suplente A: Dr. Mohamed Abderrahim Fichouche Suplente B: Dr. José Maráa Azorín Proveda Acuerdan otorgar la calificación de: Madrid, de de 2014 Acknowledgements The duration of the thesis development lead to inspiring conversations, exchange of ideas and expanding knowledge with amazing individuals. I would like to thank my advisers Manuel Ferre and Manuel Armada for their constant men- torship, support and motivation to pursue different research ideas and collaborations during the course of entire thesis. The team at the lab has not only enriched my professionally life but also in Spanish ways. Thank you all the members of the ROMIN, Francisco, Alex, Jose, Jordi, Ignacio, Javi, Chema, Luis .... This research project has been supported by a Marie Curie Early Stage Initial Training Network Fellowship of the European Community’s Seventh Framework Program "PURESAFE". I wish to thank the supervisors and fellow research members of the project for the amazing support, fruitful interactions and training events. -

Learning for Microrobot Exploration: Model-Based Locomotion, Sparse-Robust Navigation, and Low-Power Deep Classification
Learning for Microrobot Exploration: Model-based Locomotion, Sparse-robust Navigation, and Low-power Deep Classification Nathan O. Lambert1, Farhan Toddywala1, Brian Liao1, Eric Zhu1, Lydia Lee1, and Kristofer S. J. Pister1 Abstract— Building intelligent autonomous systems at any Classification Intelligent, mm scale Fast Downsampling scale is challenging. The sensing and computation constraints Microrobot of a microrobot platform make the problems harder. We present improvements to learning-based methods for on-board learning of locomotion, classification, and navigation of microrobots. We show how simulated locomotion can be achieved with model- Squeeze-and-Excite Hard Activation System-on-chip: based reinforcement learning via on-board sensor data distilled Camera, Radio, Battery into control. Next, we introduce a sparse, linear detector and a Dynamic Thresholding method to FAST Visual Odometry for improved navigation in the noisy regime of mm scale imagery. Locomotion Navigation We end with a new image classifier capable of classification Controller Parameter Unknown Dynamics Original Training Image with fewer than one million multiply-and-accumulate (MAC) Optimization Modeling & Simulator Resulting Map operations by combining fast downsampling, efficient layer Reward structures and hard activation functions. These are promising … … SLIPD steps toward using state-of-the-art algorithms in the power- Ground Truth Estimated Pos. State Space limited world of edge-intelligence and microrobots. Sparse I. INTRODUCTION Local Control PID: K K K Microrobots have been touted as a coming revolution p d i for many tasks, such as search and rescue, agriculture, or Fig. 1: Our vision for microrobot exploration based on distributed sensing [1], [2]. Microrobotics is a synthesis of three contributions: 1) improving data-efficiency of learning Microelectromechanical systems (MEMs), actuators, power control, 2) a more noise-robust and novel approach to visual electronics, and computation. -

Robot Learning
Robot Learning 15-494 Cognitive Robotics David S. Touretzky & Ethan Tira-Thompson Carnegie Mellon Spring 2009 04/06/09 15-494 Cognitive Robotics 1 What Can Robots Learn? ● Parameter tuning, e.g., for a faster walk ● Perceptual learning: ALVINN driving the Navlab ● Map learning, e.g., SLAM algorithms ● Behavior learning; plans and macro-operators – Shakey the Robot (SRI) – Robo-Soar ● Learning from human teachers – Operant conditioning: Skinnerbots – Imitation learning 04/06/09 15-494 Cognitive Robotics 2 Lots of Work on Robot Learning ● IEEE Robotics and Automation Society – Technical Committee on Robot Learning – http://www.learning-robots.de ● Robot Learning Summer School – Lisbon, Portugal; July 20-24, 2009 ● Workshops at major robotics conferences – ICRA 2009 workshop: Approachss to Sensorimotor Learning on Humanoid Robots – Kobe, Japan; May 17, 2009 04/06/09 15-494 Cognitive Robotics 3 Parameter Optimization ● How fast can an AIBO walk? Figures from Kohl & Stone, ICRA 2004, for the ERS-210 model: – CMU (2002) 200 mm/s – German Team 230 mm/s Hand-tuned gaits – UT Austin Villa 245 mm/s – UNSW 254 mm/s – Hornsby (1999) 170 mm/s – UNSW 270 mm/s Learned gaits – UT Austin Villa 291 mm/s 04/06/09 15-494 Cognitive Robotics 4 Walk Parameters 12 parameters to optimize: ● Front locus (height, x pos, ypos) ● Rear locus (height, x pos, y pos) ● Locus length ● Locus skew multiplier (in the x-y plane, for turning) ● Height of front of body ● Height of rear of body From Kohl & Stone (ICRA 2004) ● Foot travel time ● Fraction of time foot is on ground 04/06/09 15-494 Cognitive Robotics 5 Optimization Strategy ● “Policy gradient reinforcement learning”: – Walk parameter assignment = “policy” – Estimate the gradient along each dimension by trying combinations of slight perturbations in all parameters – Measure walking speed on the actual robot – Optimize all 12 parameters simultaneously – Adjust parameters according to the estimated gradient. -

Systematic Review of Research Trends in Robotics Education for Young Children
sustainability Review Systematic Review of Research Trends in Robotics Education for Young Children Sung Eun Jung 1,* and Eun-sok Won 2 1 Department of Educational Theory and Practice, University of Georgia, Athens, GA 30602, USA 2 Department of Liberal Arts Education, Mokwon University, Daejeon 35349, Korea; [email protected] * Correspondence: [email protected]; Tel.: +1-706-296-3001 Received: 31 January 2018; Accepted: 13 March 2018; Published: 21 March 2018 Abstract: This study conducted a systematic and thematic review on existing literature in robotics education using robotics kits (not social robots) for young children (Pre-K and kindergarten through 5th grade). This study investigated: (1) the definition of robotics education; (2) thematic patterns of key findings; and (3) theoretical and methodological traits. The results of the review present a limitation of previous research in that it has focused on robotics education only as an instrumental means to support other subjects or STEM education. This study identifies that the findings of the existing research are weighted toward outcome-focused research. Lastly, this study addresses the fact that most of the existing studies used constructivist and constructionist frameworks not only to design and implement robotics curricula but also to analyze young children’s engagement in robotics education. Relying on the findings of the review, this study suggests clarifying and specifying robotics-intensified knowledge, skills, and attitudes in defining robotics education in connection to computer science education. In addition, this study concludes that research agendas need to be diversified and the diversity of research participants needs to be broadened. To do this, this study suggests employing social and cultural theoretical frameworks and critical analytical lenses by considering children’s historical, cultural, social, and institutional contexts in understanding young children’s engagement in robotics education. -

Concevoir Et Animer Pour L'acceptation De Robots
Concevoir et animer pour l’acceptation de robots zoomorphiques Adrien Gomez To cite this version: Adrien Gomez. Concevoir et animer pour l’acceptation de robots zoomorphiques. Art et histoire de l’art. Université Toulouse le Mirail - Toulouse II, 2018. Français. NNT : 2018TOU20048. tel- 02466318 HAL Id: tel-02466318 https://tel.archives-ouvertes.fr/tel-02466318 Submitted on 4 Feb 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Délivré par Université Toulouse – Jean Jaurès Adrien Gomez Le 30 Août 2018 Concevoir et Animer pour l’Acceptation de Robots Zoomorphiques École doctorale et discipline ou spécialité ED ALLPH@: Études audiovisuelles Unité de recherche LARA (Université Toulouse Jean Jaurès) – LIRMM (Université Montpellier) Directeur(s) de Thèse M. Gilles METHEL M. René Zapata Co-encadrant de Thèse M. Sébastien Druon Jury Chu-Yin Chen, Professeure, université Paris 8 Sylvie Lelandais, Professeure, Université Evry-Val d’Essonnes Gilles Methel, Professeur, Université Toulouse2-Jean Jaurès René Zapata, Professeur, LIRMM Montpellier Sébastien -

Functional Fibers and Fabrics for Soft Robotics, Wearables, and Human–
REVIEW www.advmat.de Functional Fibers and Fabrics for Soft Robotics, Wearables, and Human–Robot Interface Jiaqing Xiong, Jian Chen, and Pooi See Lee* excellent mechanical adaptability to enable Soft robotics inspired by the movement of living organisms, with excellent safe and friendly interactions with human. adaptability and accuracy for accomplishing tasks, are highly desirable for Fiber that has been known for thousands efficient operations and safe interactions with human. With the emerging of years for textile engineering, is a kind of wearable electronics, higher tactility and skin affinity are pursued for safe thin 1D material with large length–diam- eter ratio and softness. Fiber can be fur- and user-friendly human–robot interactions. Fabrics interlocked by fibers ther processed into 1D or 3D yarns and 2D perform traditional static functions such as warming, protection, and or 3D fabrics and can be subjected to well- fashion. Recently, dynamic fibers and fabrics are favorable to deliver active established textile manufacturing tech- stimulus responses such as sensing and actuating abilities for soft-robots niques, such as dyeing, twisting, sewing, [1] and wearables. First, the responsive mechanisms of fiber/fabric actuators and knitting, weaving, braiding, etc. As com- mercially available material, fabric has their performances under various external stimuli are reviewed. Fiber/yarn- been widely used for clothing, bedding, based artificial muscles for soft-robots manipulation and assistance in human or furniture. Such wide-adoption dem- motion are discussed, as well as smart clothes for improving human percep- onstrates fabrics/textiles to be important tion. Second, the geometric designs, fabrications, mechanisms, and functions and adaptable as daily useable material of fibers/fabrics for sensing and energy harvesting from the human body and due to their merits of protection, breatha- [2] environments are summarized. -

Multi-Leapmotion Sensor Based Demonstration for Robotic Refine Tabletop Object Manipulation Task
Available online at www.sciencedirect.com ScienceDirect CAAI Transactions on Intelligence Technology 1 (2016) 104e113 http://www.journals.elsevier.com/caai-transactions-on-intelligence-technology/ Original article Multi-LeapMotion sensor based demonstration for robotic refine tabletop object manipulation task* Haiyang Jin a,b,c, Qing Chen a,b, Zhixian Chen a,b, Ying Hu a,b,*, Jianwei Zhang c a Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China b Chinese University of Hong Kong, Hong Kong, China c University of Hamburg, Hamburg, Germany Available online 2 June 2016 Abstract In some complicated tabletop object manipulation task for robotic system, demonstration based control is an efficient way to enhance the stability of execution. In this paper, we use a new optical hand tracking sensor, LeapMotion, to perform a non-contact demonstration for robotic systems. A Multi-LeapMotion hand tracking system is developed. The setup of the two sensors is analyzed to gain a optimal way for efficiently use the informations from the two sensors. Meanwhile, the coordinate systems of the Mult-LeapMotion hand tracking device and the robotic demonstration system are developed. With the recognition to the element actions and the delay calibration, the fusion principles are developed to get the improved and corrected gesture recognition. The gesture recognition and scenario experiments are carried out, and indicate the improvement of the proposed Multi-LeapMotion hand tracking system in tabletop object manipulation task for robotic demonstration. Copyright © 2016, Chongqing University of Technology. Production and hosting by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/). -
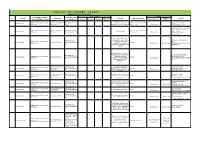
Robotics Laboratory List
Robotics List (ロボット技術関連コースのある大学) Robotics List by University Degree sought English Undergraduate / Graduate Admissions Office No. University Department Professional Keywords Application Deadline Degree in Lab links Schools / Institutes or others Website Bachelor Master’s Doctoral English Admissions Master's English Graduate School of Science and Department of Mechanical http://www.se.chiba- Robotics, Dexterous Doctoral:June and December ○ http://www.em.eng.chiba- 1 Chiba University ○ ○ ○ Engineering Engineering u.jp/en/ Manipulation, Visual Recognition Master's:June (Doctoral only) u.jp/~namiki/index-e.html Laboratory Innovative Therapeutic Engineering directed by Prof. Graduate School of Science and Department of Medical http://www.tms.chiba- Doctoral:June and December ○ 1 Chiba University ○ ○ Surgical Robotics ○ Ryoichi Nakamura Engineering Engineering u.jp/english/index.html Master's:June (Doctoral only) http://www.cfme.chiba- u.jp/~nakamura/ Micro Electro Mechanical Systems, Micro Sensors, Micro Micro System Laboratory (Dohi http://global.chuo- Graduate School of Science and Coil, Magnetic Resonance ○ ○ Lab.) 2 Chuo University Precision Mechanics u.ac.jp/english/admissio ○ ○ October Engineering Imaging, Blood Pressure (Doctoral only) (Doctoral only) http://www.msl.mech.chuo-u.ac.jp/ ns/ Measurement, Arterial Tonometry (Japanese only) Method Assistive Robotics, Human-Robot Communication, Human-Robot Human-Systems Laboratory http://global.chuo- Graduate School of Science and Collaboration, Ambient ○ http://www.mech.chuo- 2 Chuo University -

Design and Control of a Large Modular Robot Hexapod
Design and Control of a Large Modular Robot Hexapod Matt Martone CMU-RI-TR-19-79 November 22, 2019 The Robotics Institute School of Computer Science Carnegie Mellon University Pittsburgh, PA Thesis Committee: Howie Choset, chair Matt Travers Aaron Johnson Julian Whitman Submitted in partial fulfillment of the requirements for the degree of Master of Science in Robotics. Copyright © 2019 Matt Martone. All rights reserved. To all my mentors: past and future iv Abstract Legged robotic systems have made great strides in recent years, but unlike wheeled robots, limbed locomotion does not scale well. Long legs demand huge torques, driving up actuator size and onboard battery mass. This relationship results in massive structures that lack the safety, portabil- ity, and controllability of their smaller limbed counterparts. Innovative transmission design paired with unconventional controller paradigms are the keys to breaking this trend. The Titan 6 project endeavors to build a set of self-sufficient modular joints unified by a novel control architecture to create a spiderlike robot with two-meter legs that is robust, field- repairable, and an order of magnitude lighter than similarly sized systems. This thesis explores how we transformed desired behaviors into a set of workable design constraints, discusses our prototypes in the context of the project and the field, describes how our controller leverages compliance to improve stability, and delves into the electromechanical designs for these modular actuators that enable Titan 6 to be both light and strong. v vi Acknowledgments This work was made possible by a huge group of people who taught and supported me throughout my graduate studies and my time at Carnegie Mellon as a whole. -

Machine Vision for Service Robots & Surveillance
Machine Vision for Service Robots & Surveillance Prof.dr.ir. Pieter Jonker EMVA Conference 2015 Delft University of Technology Cognitive Robotics (text intro) This presentation addresses the issue that machine vision and learning systems will dominate our lives and work in future, notably through surveillance systems and service robots. Pieter Jonker’s specialism is robot vision; the perception and cognition of service robots, more specifically autonomous surveillance robots and butler robots. With robot vision comes the artificial intelligence; if you perceive and understand, than taking sensible actions becomes relative easy. As robots – or autonomous cars, or … - can move around in the world, they encounter various situations to which they have to adapt. Remembering in which situation you adapted to what is learning. Learning comes in three flavors: cognitive learning through Pattern Recognition (association), skills learning through Reinforcement Learning (conditioning) and the combination (visual servoing); such as a robot learning from observing a human how to poor in a glass of beer. But as always in life this learning comes with a price; bad teachers / bad examples. 2 | 16 Machine Vision for Service Robots & Surveillance Prof.dr.ir. Pieter Jonker EMVA Conference Athens 12 June 2015 • Professor of (Bio) Mechanical Engineering Vision based Robotics group, TU-Delft Robotics Institute • Chairman Foundation Living Labs for Care Innovation • CEO LEROVIS BV, CEO QdepQ BV, CTO Robot Care Systems Delft University of Technology Content • -

New Method for Robotic Systems Architecture
NEW METHOD FOR ROBOTIC SYSTEMS ARCHITECTURE ANALYSIS, MODELING, AND DESIGN By LU LI Submitted in partial fulfillment of the requirements For the degree of Master of Science Thesis Advisor: Dr. Roger Quinn Department of Mechanical and Aerospace Engineering CASE WESTERN RESERVE UNIVERSITY August 2019 CASE WESTERN RESERVE UNIVERSITY SCHOOL OF GRADUATE STUDIES We hereby approve the thesis/dissertation of Lu Li candidate for the degree of Master of Science. Committee Chair Dr. Roger Quinn Committee Member Dr. Musa Audu Committee Member Dr. Richard Bachmann Date of Defense July 5, 2019 *We also certify that written approval has been obtained for any proprietary material contained therein. ii Table of Contents Table of Contents ................................................................................................................................................ i List of Tables ....................................................................................................................................................... ii List of Figures .................................................................................................................................................... iii Copyright page .................................................................................................................................................. iv Preface ..................................................................................................................................................................... v Acknowledgements