Comparing Spatial Features of Urban Housing Markets 7
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lions Clubs International Club Membership Register
LIONS CLUBS INTERNATIONAL CLUB MEMBERSHIP REGISTER CLUB MMR MMR FCL YR MEMBERSHI P CHANGES TOTAL IDENT CLUB NAME DIST TYPE NBR RPT DATE RCV DATE OB NEW RENST TRANS DROPS NETCG MEMBERS 4017 020348 KVARNBO 107 A 1 09-2003 10-16-2003 -3 -3 45 0 0 0 -3 -3 42 4017 020363 MARIEHAMN 107 A 1 05-2003 08-11-2003 4017 020363 MARIEHAMN 107 A 1 06-2003 08-11-2003 4017 020363 MARIEHAMN 107 A 1 07-2003 08-11-2003 4017 020363 MARIEHAMN 107 A 1 08-2003 08-11-2003 4017 020363 MARIEHAMN 107 A 1 09-2003 10-21-2003 -1 -1 55 0 0 0 -1 -1 54 4017 041195 ALAND SODRA 107 A 1 08-2003 09-23-2003 24 0 0 0 0 0 24 4017 050840 BRANDO-KUMLINGE 107 A 1 07-2003 06-23-2003 4017 050840 BRANDO-KUMLINGE 107 A 1 08-2003 06-23-2003 4017 050840 BRANDO-KUMLINGE 107 A 1 09-2003 10-16-2003 20 0 0 0 0 0 20 4017 059671 ALAND FREJA 107 A 1 07-2003 09-18-2003 4017 059671 ALAND FREJA 107 A 1 08-2003 09-11-2003 4017 059671 ALAND FREJA 107 A 1 08-2003 10-08-2003 4017 059671 ALAND FREJA 107 A 1 09-2003 10-08-2003 4017 059671 ALAND FREJA 107 A 7 09-2003 10-13-2003 2 2 25 2 0 0 0 2 27 GRAND TOTALS Total Clubs: 5 169 2 0 0 -4 -2 167 Report Types: 1 - MMR 2 - Roster 4 - Charter Report 6 - MMR w/ Roster 7 - Correspondence 8 - Correction to Original MMR 9 - Amended Page 1 of 126 CLUB MMR MMR FCL YR MEMBERSHI P CHANGES TOTAL IDENT CLUB NAME DIST TYPE NBR RPT DATE RCV DATE OB NEW RENST TRANS DROPS NETCG MEMBERS 4019 020334 AURA 107 A 1 07-2003 07-04-2003 4019 020334 AURA 107 A 1 08-2003 06-04-2003 4019 020334 AURA 107 A 1 09-2003 10-06-2003 44 0 0 0 0 0 44 4019 020335 TURKU AURA 107 A 25 0 0 0 -

A Missionary Pictorial
Abilene Christian University Digital Commons @ ACU Stone-Campbell Books Stone-Campbell Resources 1964 A Missionary Pictorial Charles R. Brewer Follow this and additional works at: https://digitalcommons.acu.edu/crs_books Part of the Christian Denominations and Sects Commons, Christianity Commons, and the Missions and World Christianity Commons Recommended Citation Brewer, Charles R., "A Missionary Pictorial" (1964). Stone-Campbell Books. 286. https://digitalcommons.acu.edu/crs_books/286 This Book is brought to you for free and open access by the Stone-Campbell Resources at Digital Commons @ ACU. It has been accepted for inclusion in Stone-Campbell Books by an authorized administrator of Digital Commons @ ACU. ( A MISSIONARYPICTORIAL Biographical sketches and pictures of men and women who have gone from the United States as members of churches of Christ to carry the gospel to other lands. TOGETHER WITH Articles and poems written for the purpose of stirring churches and individuals to greater activity in the effort to preach the gospel to "every creature under ( heaven." • EDITOR CHARLES R. BREWER • P UB LISHED BY WORLD VISION PUBLISHING COMPANY 1033 BELVIDERE DRIVE NASHVILLE, TENNESSEE 1964 ( Preface The divine char ge to take the word of the Lord to the whole world is laid upon all who wear the name of Christ, and God is ple ased with all who have a part, directly or indirectly in carry ing out th -:: great commission . But we feel th at in a special way his blessing descends on those who, forsaking th e ways of ga in and pleasure , give them selves wholly to th e preaching of the word. -

Vesientutkimuslaitoksen Julkaisuja Publications of the Water Research Institute
VESIENTUTKIMUSLAITOKSEN JULKAISUJA PUBLICATIONS OF THE WATER RESEARCH INSTITUTE Matti Melanen & Risto Laukkanen: Quantity of storm runoff water in urban areas Tiivistelmä: Taajama-alueiden hulevesivalunnan määrä 3 Matti Melanen & Heikki Tähtelä: Particle deposition in urban areas Tiivistelmä: Taajama-alueiden ilmaperäinen laskeuma 40 Matti Melanen: Quality of runoff water in urban areas Tiivistelmä: Taajama-alueiden hulevesien laatu 123 VESIHALLITUS—NATIONAL BOARD OF WATERS, FINLAND Helsinki 1981 Tekijät ovat vastuussa julkaisun sisällöstä, eikä siihen voida vedota vesihallituksen virallisena kannanottona. The authors are responsible for the contents of the publication. It may not be referred to as the official view or policy of the National Board of Waters. ISBN 951-46-6066-8 SSN 0355-0982 Helsinki 1982. Valtion painatuskeskus 40 PARTICLE DEPOSITION IN URBAN AREAS Matti Melanen & Heikki Thte1ä MELANEN, M. & TÄHTELÄ, H. 1981. Particle deposition in urban areas. Publications of the Water Research Institute, National Board of “Waters, Finland, No. 42. In experiments carried out at seven urban test sites during 1977—1979, the average deposition rate compared to the one observed in regional background was roughly 100 % higher in respect to total organic carbon, 75 % higher in total phosphorus and the same in the cases of total nitrogen and chloride. In the case of calcium, the deposition rate was the same as the one in regional background in suburban catchments hut 100 % higher in city centres. The corresponding comparative figures for sulphate were 50 % in suburban catchments and 100—200 % in city centres. In suburban catchments, the pH of precipitation was on the average 0.4 units lower than the pH of precipitation in regional background. -

Helsingin Sosiaalivirasto
Itäinen Helsinki Sisältö SOSIAALIVIRASTON PALVELUT .................................. 3 Itäinen sosiaali- ja lähityön yksikkö ............................... 3 Sosiaalityö ................................................................. 4 Lähityö ....................................................................... 4 Omaishoidon tuki ....................................................... 5 Itäinen omaishoidon toimintakeskus .......................... 5 Vanhusten palvelu- ja virkistyskeskukset ..................... 6 Päivätoiminta ................................................................ 7 Palveluasuminen ja ympärivuorokautinen hoito ........... 7 Vammaispalvelut .......................................................... 8 Kuljetuspalvelut ............................................................ 9 Asunnon muutostyöt ................................................... 10 Toimiva Koti ................................................................ 11 Toimeentulotuki .......................................................... 11 TERVEYSKESKUKSEN PALVELUT ............................ 12 Terveysasemat ........................................................... 12 Päivystys .................................................................... 14 Laboratoriot ................................................................ 15 Omahoitotarvikejakelu ................................................ 15 Hammashoitolat ......................................................... 16 Kotihoito .................................................................... -

De Maasbode Verschijnt Dagelijks Des Ochtends En Des Avonds, Uitgezonderd Zon- Dagavond En Maandagochtend
72ste JAARGANG. No. 29071. VRIJDAG 2 FEBRUARI 1940 AVONDBLAD - VIER BLADEN De Maasbode verschijnt dagelijks des ochtends en des avonds, uitgezonderd Zon- dagavond en Maandagochtend. WENNEKER^ ■m SCHIEDAM Mm Abonnementsprijs voor geheel Nederland f 4.50 per kwartaal, f 1 50 per maand, f OJS per week. Losse nummers 9 cent Advertentiën 75 cent per regel. Handels- advertentiën 70 cent per regel Ingezonden Mededeelingen dubbel tarief. Liefdadigheids- advertentiën half tarief. Zaterdagavond en Zondagochtend 10 cent per regel verhooging. MAASBODE regels DE Kabouter-advertentiën groot 5 f 2.—. Uitgave van de NV. de Courant De Maasbode, Groote Markt 30. Rotterdam DAGBLAD VOOR NEDERLAND MET OCHTEND- EN AVOND-EDITIE. |ÜdË OUDE Telefoon 26200 11735. PROEVE? | Postbus 723 — — Giro Het dagblad „Proia", merkt naar aanlei- ding van de Balkan-ententeconferentie op, VOORNAAMSTE NIEUWS. dat de politieke atmosfeer vandaag er op 1 wijst, dat alle Donau- en Balkanstaten vriendschappelijk tegenover gestemd van Italië Melding wordt gemaakt van vier belang- Conferentie zijn. Belgrado rijke punten, op begonnen welke de heden conferentie te Belgrado zouden worden De petroleum-kwestie. aangesneden Pag. L LONDEN, 2 Februari (U.P.) De strtfd om Bij het indienen van de Japansche begroo» heden de Roemeensche petroleum zal betrekkelijk ting heeft de minister van financiën een geopend. de redevoering gehouden Paj}. 2. spoedig tot een einde komen, aldus mee- ning van vooraanstaande personen uit de wereld van de olie-industrie, zoowel als van Een nieuw Russisch offensief aan het front Te moeilijker wordt dit probleem, waar de vooraanstaande diplomaten. in Karelië is tot nu toe op den Finschen te- eene staat (Roemenië) onmiddellijk be- Donderdag vernamen wij uit betrouwbare genstand doodgeloopen Pag. -

Transvaalbuurt (Amsterdam) - Wikipedia
Transvaalbuurt (Amsterdam) - Wikipedia http://nl.wikipedia.org/wiki/Transvaalbuurt_(Amsterdam) 52° 21' 14" N 4° 55' 11"Archief E Philip Staal (http://toolserver.org/~geohack Transvaalbuurt (Amsterdam)/geohack.php?language=nl& params=52_21_14.19_N_4_55_11.49_E_scale:6250_type:landmark_region:NL& pagename=Transvaalbuurt_(Amsterdam)) Uit Wikipedia, de vrije encyclopedie De Transvaalbuurt is een buurt van het stadsdeel Oost van de Transvaalbuurt gemeente Amsterdam, onderdeel van de stad Amsterdam in de Nederlandse provincie Noord-Holland. De buurt ligt tussen de Wijk van Amsterdam Transvaalkade in het zuiden, de Wibautstraat in het westen, de spoorlijn tussen Amstelstation en Muiderpoortstation in het noorden en de Linnaeusstraat in het oosten. De buurt heeft een oppervlakte van 38 hectare, telt 4500 woningen en heeft bijna 10.000 inwoners.[1] Inhoud Kerngegevens 1 Oorsprong Gemeente Amsterdam 2 Naam Stadsdeel Oost 3 Statistiek Oppervlakte 38 ha 4 Bronnen Inwoners 10.000 5 Noten Oorsprong De Transvaalbuurt is in de jaren '10 en '20 van de 20e eeuw gebouwd als stadsuitbreidingswijk. Architect Berlage ontwierp het stratenplan: kromme en rechte straten afgewisseld met pleinen en plantsoenen. Veel van de arbeiderswoningen werden gebouwd in de stijl van de Amsterdamse School. Dit maakt dat dat deel van de buurt een eigen waarde heeft, met bijzondere hoekjes en mooie afwerkingen. Nadeel van deze bouw is dat een groot deel van de woningen relatief klein is. Aan de basis van de Transvaalbuurt stonden enkele woningbouwverenigingen, die er huizenblokken -

Opinnäytetyön Mallipohja
Kustannustehokkuus ISS Viherpalveluissa Case: Kaarelan alueurakka Koskelainen, Riku 2016 Tikkurila Laurea-ammattikorkeakoulu Tikkurilan yksikkö Kustannustehokkuus ISS Viherpalveluissa Case: Kaarelan alueurakka Riku Koskelainen Liiketalouden koulutusohjelma Opinnäytetyö Helmikuu, 2016 Laurea-ammattikorkeakoulu Tiivistelmä Tikkurilan yksikkö Liiketalouden koulutusohjelma Riku Koskelainen Kustannustehokkuus ISS Viherpalveluissa Vuosi 2016 Sivumäärä 55 Tämä opinnäytetyö käsittelee alihankintaa ja alihankintaprosessin kehittämistä. Opinnäyte- työn tavoitteena on tutkia kansainvälistä kiinteistöalan konsernia ja sen alaisuudessa toimivaa yksikköä. Yksikössä tarkoituksena on tutkia sen alihankintaprosessia ja sitä miten alihankinta- prosessia voitaisiin tehostaa. Kaarelan alueurakassa kysymys on tilaajan aloittamasta hankkeesta. Tutkielmassa on pyritty kuvaamaan laajempi prosessi ja tuomaan sitä yhä lähemmäksi ongelmakohtaa: ISS Viherpalve- luiden kustannustehokkuutta. Tutkielman laajin osa käsittelee julkisia hankintoja ja tilaaja- vastuuta Kaarelan alueurakassa. Nämä asiat on käsitelty teoriaosuudessa. Tämän jälkeen tut- kitaan ISS Palveluiden sisäisiä prosesseja ja sitä mihin ISS Viherpalvelut sijoittuu. Tutkimus- menetelmänä tässä kohdassa on käytetty kyselylomaketta Kaarelan alueurakan vastuuhenki- löille. Viimeisenä tutkimusmenetelmänä on käytetty investointilaskelmia ISS Viherpalveluiden sisäisissä prosesseissa. Ongelmakohdiksi on rajattu kolme toimintoa: työkoneiden leasing, niit- tomurskaus ja jääkenttien jäädytys ja hoito. Nämä kolme -

A09 Oostelijke Eilanden / Kadijken Buurtenquête 2016 Stadsdeel Centrum
A09 Oostelijke Eilanden / Kadijken Buurtenquête 2016 Stadsdeel Centrum Onderzoek, Informatie en Statistiek Gemeente Amsterdam Onderzoek, Informatie en Statistiek Buurtenquête stadsdeel Centrum 2016, A09 Oostelijke Eilanden/Kadijken In opdracht van: Stadsdeel Centrum Projectnummer: 16111 Jessica Greven Esther Jakobs Laura de Graaff Willem Bosveld Patricia Jaspers Ivo de Bruijn Marieke Bakker Peter van Hinte Bart Karpe Aram Limpens Anouk Schrijver Bezoekadres: Oudezijds Voorburgwal 300 Telefoon 020 251 0462 Postbus 658, 1000 AR Amsterdam www.ois.amsterdam.nl [email protected] Amsterdam, mei 2016 Foto voorzijde: Uitzicht Westertoren, fotograaf Cecile Obertop (2014) 2 Gemeente Amsterdam Onderzoek, Informatie en Statistiek Buurtenquête stadsdeel Centrum 2016, A09 Oostelijke Eilanden/Kadijken Inhoud Inleiding 5 Resultaten 8 1.1 Profiel van de deelnemers 8 1.2 Algemeen 9 1.2.1 Meest favoriete plek in de buurt 9 1.2.2 Wat de gemeente als eerste aan zou moeten pakken in de buurt 10 1.3 Verkeer 10 1.3.1 Vervoermiddelen 10 1.3.2 Onveilige verkeerssituaties in de buurt 11 1.3.3 Grootste fietsparkeerprobleem in de buurt 12 1.3.4 Gevaarlijke verkeerssituaties voor fietsers in de buurt 13 1.4 Behoud van kwaliteit en optimaal gebruik van de openbare ruimte 15 1.4.1 Belemmerde doorgang 16 1.4.2 Parkeermaatregelen 17 1.5 Bewaken en verbeteren van de functiebalans (wonen, werken en recreëren) 18 1.5.1 Uitgaan 18 1.5.2 Balans tussen wonen, werken en recreëren in de buurt 18 1.5.3 Verhuisplannen 19 1.6 Bewaken en verbeteren van de leefbaarheid 20 1.6.1 -
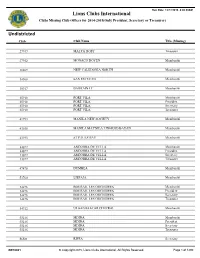
All Clubs Missing Officers 2014-15.Pdf
Run Date: 12/17/2015 8:40:39AM Lions Clubs International Clubs Missing Club Officer for 2014-2015(Only President, Secretary or Treasurer) Undistricted Club Club Name Title (Missing) 27947 MALTA HOST Treasurer 27952 MONACO DOYEN Membershi 30809 NEW CALEDONIA NORTH Membershi 34968 SAN ESTEVAN Membershi 35917 BAHRAIN LC Membershi 35918 PORT VILA Membershi 35918 PORT VILA President 35918 PORT VILA Secretary 35918 PORT VILA Treasurer 41793 MANILA NEW SOCIETY Membershi 43038 MANILA MAYNILA LINGKOD BAYAN Membershi 43193 ST PAULS BAY Membershi 44697 ANDORRA DE VELLA Membershi 44697 ANDORRA DE VELLA President 44697 ANDORRA DE VELLA Secretary 44697 ANDORRA DE VELLA Treasurer 47478 DUMBEA Membershi 53760 LIEPAJA Membershi 54276 BOURAIL LES ORCHIDEES Membershi 54276 BOURAIL LES ORCHIDEES President 54276 BOURAIL LES ORCHIDEES Secretary 54276 BOURAIL LES ORCHIDEES Treasurer 54912 ULAANBAATAR CENTRAL Membershi 55216 MDINA Membershi 55216 MDINA President 55216 MDINA Secretary 55216 MDINA Treasurer 56581 RIFFA Secretary OFF0021 © Copyright 2015, Lions Clubs International, All Rights Reserved. Page 1 of 1290 Run Date: 12/17/2015 8:40:39AM Lions Clubs International Clubs Missing Club Officer for 2014-2015(Only President, Secretary or Treasurer) Undistricted Club Club Name Title (Missing) 57293 RIGA RIGAS LIEPA Membershi 57293 RIGA RIGAS LIEPA President 57293 RIGA RIGAS LIEPA Secretary 57293 RIGA RIGAS LIEPA Treasurer 57378 MINSK CENTRAL Membershi 57378 MINSK CENTRAL President 57378 MINSK CENTRAL Secretary 57378 MINSK CENTRAL Treasurer 59850 DONETSK UNIVERSAL -

Helsinki Alueittain 2015 Helsingfors Områdesvis Helsinki by District
Helsingfors stads faktacentral City of Helsinki Urban Facts HELSINKI ALUEITTAIN Helsingfors områdesvis 2015 Helsinki by District Helsingin kaupungin tietokeskus PL 5500, 00099 Helsingin kaupunki, p. 09 310 1612 Helsingfors stads faktacentral PB 5500, 00099 Helsingfors stad, tel. 09 310 1612 City of Helsinki Urban Facts P.O.Box 5500, FI-00099 City of Helsinki, tel. +358 9 310 1612 www.hel.fi/tietokeskus Tilaukset / jakelu p. 09 310 36293 Käteismyynti Tietokeskuksen kirjasto, Siltasaarenk. 18-20 A Beställningar / distribution tel. 09 310 36293 Direktförsäljning Faktacentralens bibliotek, Broholmsgatan 18-20 A Orders / distribution tel. +358 9 310 36293 Direct sales Library, Siltasaarenkatu 18-20 A S-posti / e-mail [email protected] HELSINKI ALUEITTAIN Helsingfors områdesvis 2015 Helsinki by District Helsingin kaupungin tietokeskus Helsingfors stads faktacentral Helsinki City of Helsinki Urban Facts Helsingfors 2016 Julkaisun toimitus Tea Tikkanen Redigering Editors Käännökset Magnus Gräsbeck Översättningar Translations Taitto Petri Berglund Ombrytning General layout Kansi Tarja Sundström-Alku Pärm Cover Tekninen toteutus Otto Burman Tekniskt utförande Tea Tikkanen Technical Editing Pekka Vuori Valokuvat Kansi - Pärm - Cover: Helsingin kaupungin matkailu- ja kongressitoimiston Foton materiaalipankki / Lauri Rotko, Visit Helsinki / Jussi Hellsten Photos Helsingin kaupungin tietokeskus / Raimo Riski Kartat Pohja-aineistot: Kartor © Helsingin kaupunkimittausosasto, alueen kunnat ja HSY, 2014 Maps © Liikennevirasto / Digiroad 2014 -

Proefschrift Wordt Het Begrip Moderniteit Almere, Gebruikt Om De Spanning En Ambivalentie Van Cergy-Pontoise, De Suburbane Stedelijkheid Te Analyseren
UvA-DARE (Digital Academic Repository) Moderniteit en suburbaniteit in de nieuwe stad: Almere, Cergy-Pontoise, Milton Keynes Nio, I.H.L. Publication date 2016 Document Version Final published version Link to publication Citation for published version (APA): Nio, I. H. L. (2016). Moderniteit en suburbaniteit in de nieuwe stad: Almere, Cergy-Pontoise, Milton Keynes. General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:07 Oct 2021 Almere, Cergy-Pontoise, Milton Keynes Keynes Milton Cergy-Pontoise, Almere, Moderniteit De nieuwe steden Almere, Cergy-Pontoise en Milton Moderniteit Keynes zijn het resultaat van pogingen om een vorm en suburbaniteit van stedelijkheid te creëren die de aantrekkelijkheid van het stedelijke en suburbane wonen combineert. in de nieuwe De combinatie van buiten wonen in een eigen huis met een tuin nabij stedelijke voorzieningen zou de stad kracht van de nieuwe steden uitmaken. -

West Gezond En Wel?
Factsheet Amsterdamse Gezondheidsmonitor 2012 West gezond en wel? Driekwart van de inwoners van West heeft een positief oordeel over de eigen gezondheid, zo blijkt uit de gegevens van de Amsterdamse Gezondheidsmonitor 2012. In de gezondheidsmonitor zijn gegevens verzameld over de gezondheid van Amsterdammers en over factoren die de gezondheid beïnvloeden. Deze factsheet geeft informatie over hoe het is gesteld met een aantal van deze gezondheidsaspecten in West. Een overzicht van de uitkomsten vindt u op pagina 10. De focus ligt op onderwerpen die lokaal beïnvloed kunnen worden. Op deze onderwerpen ondernemen zorg- en welzijnsorganisaties, gemeente, maar ook informele zorg al veel voor de inwoners van West. Amsterdamse Gezondheidsmonitor 2012 1 Colofon tekst GGD Amsterdam, 2014 vormgeving Werf3 drukwerk OBT fotografie Edwin van Eis telefoon: 020-555.5495 e-mail: [email protected] website: www.ggd.amsterdam.nl/agm 2 Lichamelijke gezondheid De Amsterdamse Gezondheidsmonitor De aandoening komt in West even vaak voor bij geeft onder meer inzicht in de lichamelijke mannen als bij vrouwen. Het aandeel inwoners gezondheid van Amsterdammers. Hier met diabetes neemt sterk toe met de leeftijd en bedraagt 19% onder de 65-plussers in leest u over de ervaren gezondheid, West. Stedelijke cijfers laten verder zien dat overgewicht, obesitas en chronische laagopgeleiden en inwoners van niet-westerse aandoeningen. herkomst vaker diabetes hebben. Driekwart inwoners West voelt zich gezond Circa 3.600 inwoners met hart- en vaatziekten De tevredenheid over de eigen gezondheid Drie procent van de inwoners van West lijdt aan is in West met 75% niet verschillend van het hart- en vaatziekten, dat zijn zo’n 3.600 mensen.