Quixote:Anethack Reinforcement Learning Framework and Agent
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploration and Combat in Nethack
EXPLORATION AND COMBAT IN NETHACK by Jonathan C. Campbell School of Computer Science McGill University, Montréal Monday, April 16, 2018 A THESIS SUBMITTED TO THE FACULTY OF GRADUATE STUDIES AND RESEARCH IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE Copyright ⃝c 2018 Jonathan C. Campbell Abstract Roguelike games share a common set of core game mechanics, each complex and in- volving randomization which can impede automation. In particular, exploration of levels of randomized layout is a critical and yet often repetitive mechanic, while monster combat typically involves careful, detailed strategy, also a challenge for automation. This thesis presents an approach for both exploration and combat systems in the prototypical rogue- like game, NetHack. For exploration we advance a design involving the use of occupancy maps from robotics and related works, aiming to minimize exploration time of a level by balancing area discovery with resource cost, as well as accounting for the existence of se- cret access points. Our combat strategy involves the use of deep Q-learning to selectively match player items and abilities to each opponent. Through extensive experimentation with both approaches on NetHack, we show that each outperforms simpler, baseline approaches. Results are also presented for a combined combat-exploration algorithm on a full NetHack level context. These results point towards better automation of such complex roguelike game environments, facilitating automated testing and design exploration. i Résumé Les jeux du genre roguelike partagent un ensemble commun de systèmes de jeu de base. Ces systèmes sont souvent complexes et impliquent une randomisation qui peut être un obstacle à l’automatisation. -

In This Day of 3D Graphics, What Lets a Game Like ADOM Not Only Survive
Ross Hensley STS 145 Case Study 3-18-02 Ancient Domains of Mystery and Rougelike Games The epic quest begins in the city of Terinyo. A Quake 3 deathmatch might begin with a player materializing in a complex, graphically intense 3D environment, grabbing a few powerups and weapons, and fragging another player with a shotgun. Instantly blown up by a rocket launcher, he quickly respawns. Elapsed time: 30 seconds. By contrast, a player’s first foray into the ASCII-illustrated world of Ancient Domains of Mystery (ADOM) would last a bit longer—but probably not by very much. After a complex process of character creation, the intrepid adventurer hesitantly ventures into a dark cave—only to walk into a fireball trap, killing her. But a perished ADOM character, represented by an “@” symbol, does not fare as well as one in Quake: Once killed, past saved games are erased. Instead, she joins what is no doubt a rapidly growing graveyard of failed characters. In a day when most games feature high-quality 3D graphics, intricate storylines, or both, how do games like ADOM not only survive but thrive, supporting a large and active community of fans? How can a game design seemingly premised on frustrating players through continual failure prove so successful—and so addictive? 2 The Development of the Roguelike Sub-Genre ADOM is a recent—and especially popular—example of a sub-genre of Role Playing Games (RPGs). Games of this sort are typically called “Roguelike,” after the founding game of the sub-genre, Rogue. Inspired by text adventure games like Adventure, two students at UC Santa Cruz, Michael Toy and Glenn Whichman, decided to create a graphical dungeon-delving adventure, using ASCII characters to illustrate the dungeon environments. -

Openbsd Gaming Resource
OPENBSD GAMING RESOURCE A continually updated resource for playing video games on OpenBSD. Mr. Satterly Updated August 7, 2021 P11U17A3B8 III Title: OpenBSD Gaming Resource Author: Mr. Satterly Publisher: Mr. Satterly Date: Updated August 7, 2021 Copyright: Creative Commons Zero 1.0 Universal Email: [email protected] Website: https://MrSatterly.com/ Contents 1 Introduction1 2 Ways to play the games2 2.1 Base system........................ 2 2.2 Ports/Editors........................ 3 2.3 Ports/Emulators...................... 3 Arcade emulation..................... 4 Computer emulation................... 4 Game console emulation................. 4 Operating system emulation .............. 7 2.4 Ports/Games........................ 8 Game engines....................... 8 Interactive fiction..................... 9 2.5 Ports/Math......................... 10 2.6 Ports/Net.......................... 10 2.7 Ports/Shells ........................ 12 2.8 Ports/WWW ........................ 12 3 Notable games 14 3.1 Free games ........................ 14 A-I.............................. 14 J-R.............................. 22 S-Z.............................. 26 3.2 Non-free games...................... 31 4 Getting the games 33 4.1 Games............................ 33 5 Former ways to play games 37 6 What next? 38 Appendices 39 A Clones, models, and variants 39 Index 51 IV 1 Introduction I use this document to help organize my thoughts, files, and links on how to play games on OpenBSD. It helps me to remember what I have gone through while finding new games. The biggest reason to read or at least skim this document is because how can you search for something you do not know exists? I will show you ways to play games, what free and non-free games are available, and give links to help you get started on downloading them. -

Linux Games Page 1 of 7
Linux Games Page 1 of 7 Linux Games INTRODUCTION such as the number of players and the size of the map, then you start the game. Once the game is running clients may Hello. My name is Andrew Howlett. I've been using Linux join the game. Clients connect to the game using TCP/IP, since 1997. In 2000 I cutover to Linux for all my projects, so it is very easy to play multi-player games over the except I dual-booted Windows to play games. I like to play Internet. Like many Free games, clients are available for computer games. About a year ago I stopped dual booting. many platforms, including Windows, Amiga and Now I play computer games under Linux. The games I Macintosh. So there are lots of players out there. If you play can be divided into four groups: Free Games, native don't want to play against other humans, then Freeciv linux commercial games, Windows Emulated games, and includes some nasty AIs. Win4Lin enabled games. This presentation will demonstrate games from each of these four groups. BZFlag Platform BZFlag is a tank combat game along the same lines as the old BattleZone game. Like FreeCiv, BZFlag uses a client/ Before I get started, a little bit about my setup so you can server architecture over TCP/IP networks. Unlike FreeCiv, relate this to whatever you are running. This is a P3 900 the game contains no AIs – you must play this game MHz machine. It has a Crystal Sound 4600 sound card and against other humans (? entities ?) over the Internet. -

Full Circle Magazine #160 Contents ^ Full Circle Magazine Is Neither Affiliated With,1 Nor Endorsed By, Canonical Ltd
Full Circle THE INDEPENDENT MAGAZINE FOR THE UBUNTU LINUX COMMUNITY ISSUE #160 - August 2020 RREEVVIIEEWW OOFF GGAALLLLIIUUMMOOSS 33..11 LIGHTWEIGHT DISTRO FOR CHROMEOS DEVICES full circle magazine #160 contents ^ Full Circle Magazine is neither affiliated with,1 nor endorsed by, Canonical Ltd. HowTo Full Circle THE INDEPENDENT MAGAZINE FOR THE UBUNTU LINUX COMMUNITY Python p.18 Linux News p.04 Podcast Production p.23 Command & Conquer p.16 Linux Loopback p.39 Everyday Ubuntu p.40 Rawtherapee p.25 Ubuntu Devices p.XX The Daily Waddle p.42 My Opinion p.XX Krita For Old Photos p.34 My Story p.46 Letters p.XX Review p.50 Inkscape p.29 Q&A p.54 Review p.XX Ubuntu Games p.57 Graphics The articles contained in this magazine are released under the Creative Commons Attribution-Share Alike 3.0 Unported license. This means you can adapt, copy, distribute and transmit the articles but only under the following conditions: you must attribute the work to the original author in some way (at least a name, email or URL) and to this magazine by name ('Full Circle Magazine') and the URL www.fullcirclemagazine.org (but not attribute the article(s) in any way that suggests that they endorse you or your use of the work). If you alter, transform, or build upon this work, you must distribute the resulting work under the same, similar or a compatible license. Full Circle magazine is entirely independent of Canonical, the sponsor of the Ubuntu projects, and the views and opinions in the magazine should in no way be assumed to have Canonical endorsement. -

Crawl Survey Results
Crawl survey results Survey questions 1. What is your age? 2. What is your country? 3. Do you play locally, on a server, or both? 4. Do you play Tiles, ASCII, or both? 5. OS(es) at home? 6. Roguelikes played before? 7. Where did you learn about Crawl? 8. And when? 9. How many Crawl wins? (If none, you may specify your best game.) 10.If you take part in the tournament, where did you hear about it? 11.Ever recommend Crawl? 12.Which computer game have you played most in the last month? (July) Presentation structure ● Who are our players? ● How do they play? ● How did they arrive at Crawl? ● What is their overall win rate? ● What else are they playing? Who are our players? age distribution 90 83 80 70 64 60 50 49 40 32 30 25 20 10 8 3 4 4 0 14 15-19 20-24 25-29 30-34 35-39 40-44 45-49 50+ Minimum: 14 Maximum: 57 Median: 26 Average: 27.3 most common: 25 (23 times!) Who are our players? Gender 26% 94% N/A 4% 6% 70% Male Female Who are our players? USA 147 Canada UK Germany Finland Russia Poland France Italy Sweden Norway 19 Australia 2 New Zealand 21 22 4 Japan 12 17 2 Thailand 5 3 3 12 9 8 6 Brazil others* * other countries: Argentina, Belgium, China, Croatia, Czech republic, Denmark, Hungary, Iceland, India, Ireland, Israel, Lithuania, Moldova, Mongolia, Netherlands, Singapore, Switzerland, Ukraine, United arab emirates Who are our players? Continents players/populaton 61% 1,6 1,51 1,4 1,2 1 1% North America Europe 0,8 Australia 0,57 0,6 0,5 Asia 0,45 South America 0,4 4% 0,23 0,2 0,12 0,06 6% 0 Canada USA Germany 28% Finland Australia UK -
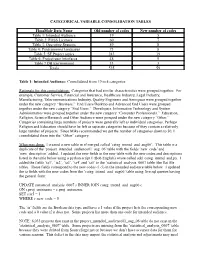
Categorical Variable Consolidation Tables
CATEGORICAL VARIABLE CONSOLIDATION TABLES FlossMole Data Name Old number of codes New number of codes Table 1: Intended Audience 19 5 Table 2: FOSS Licenses 60 7 Table 3: Operating Systems 59 8 Table 4: Programming languages 73 8 Table 5: SF Project topics 243 19 Table 6: Project user interfaces 48 9 Table 7 DB Environment 33 3 Totals 535 59 Table 1: Intended Audience: Consolidated from 19 to 4 categories Rationale for this consolidation: Categories that had similar characteristics were grouped together. For example, Customer Service, Financial and Insurance, Healthcare Industry, Legal Industry, Manufacturing, Telecommunications Industry, Quality Engineers and Aerospace were grouped together under the new category “Business.” End Users/Desktop and Advanced End Users were grouped together under the new category “End Users.” Developers, Information Technology and System Administrators were grouped together under the new category “Computer Professionals.” Education, Religion, Science/Research and Other Audience were grouped under the new category “Other.” Categories containing large numbers of projects were generally left as individual categories. Perhaps Religion and Education should have be left as separate categories because of they contain a relatively large number of projects. Since Mike recommended we get the number of categories down to 50, I consolidated them into the “Other” category. What was done: I created a new table in sf merged called ‘categ_intend_aud_aug06’. This table is a duplicate of the ‘project_intended_audience01_aug_06’ table with the fields ‘new_code’ and ‘new_description’ added. I updated the new fields in the new table with the new codes and descriptions listed in the table below using a python script I (Bob English) wrote called add_categ_intend_aud.py. -

A Nethack Reinforcement Learning Framework and Agent Chandler Watson1 1Department of Mathematics, Stanford University
Quixote: A NetHack Reinforcement Learning Framework and Agent Chandler Watson1 1Department of Mathematics, Stanford University CS 229, Spring 2019 Abstract Objective Model 1: Basic Q-learning Model 3: ε Scheduling In the 1980s, Michael Toy and NetHack: a ”roguelike” Unix game Simple Q-learning model: Random works well—bootstrap off it: Future Directions Glenn Wichman released a new • Permadeath, low win rate • Hard to capture informative enough state • Much exploration needed, then exploitation game that would change the • Sparse “rewards,” large action space Both for framework and for agent: ecosystem of Unix games • Massive number of game mechanics • Much, much more testing! forever: Rogue. Rogue was a • (https://wikimedia.org/api/rest_v1/media/math/render/svg/47fa1e5cf8cf75996a777c11c7b9445dc96d4637) Unpredictable NPCs • Implement deep RL architectures dungeon crawler—a game in • Explore more expressive state reps. which the objective is to • Simple epsilon-greedy strategy • Directions to landmarks explore a dungeon, typically in • Primary reward is delta score • ≈c • Finer auxiliary rewards search of an artifact—which • Retracing penalty, exploration bonus • Use “meta-actions”: go to door, fight enemy would result in many spinoffs, • State representation: including the open-source NetHack, enjoyed by many Figure 4: Stepwise epsilon scheduling. today. NetHack is a game both beloved and reviled for its Results incredible difficulty—finishing the game is seen as a great Rand. QL QL + ε AQL AQL + ε accomplishment. Figure 1: A screenshot of the end of a game of NetHack. (https://www.reddit.com/r/nethack/comments/3ybcce/yay_my_first_360_ascension/) 45.60 44.92 51.96 32.53* 49.52 In this project, we explore the creation of a new NetHack Difficult but interesting environment for RL Figure 6: Possible ”meta-actions” for Quixote. -

Open Source Issues and Opportunities (Powerpoint Slides)
© Practising Law Institute INTELLECTUAL PROPERTY Course Handbook Series Number G-1307 Advanced Licensing Agreements 2017 Volume One Co-Chairs Marcelo Halpern Ira Jay Levy Joseph Yang To order this book, call (800) 260-4PLI or fax us at (800) 321-0093. Ask our Customer Service Department for PLI Order Number 185480, Dept. BAV5. Practising Law Institute 1177 Avenue of the Americas New York, New York 10036 © Practising Law Institute 24 Open Source Issues and Opportunities (PowerPoint slides) David G. Rickerby Boston Technology Law, PLLC If you find this article helpful, you can learn more about the subject by going to www.pli.edu to view the on demand program or segment for which it was written. 2-315 © Practising Law Institute 2-316 © Practising Law Institute Open Source Issues and Opportunities Practicing Law Institute Advanced Licensing Agreements 2017 May 12th 2017 10:45 AM - 12:15 PM David G. Rickerby 2-317 © Practising Law Institute Overview z Introduction to Open Source z Enforced Sharing z Managing Open Source 2-318 © Practising Law Institute “Open” “Source” – “Source” “Open” licensing software Any to available the source makes model that etc. modify, distribute, copy, What is Open Source? What is z 2-319 © Practising Law Institute The human readable version of the code. version The human readable and logic. interfaces, secrets, Exposes trade What is Source Code? z z 2-320 © Practising Law Institute As opposed to Object Code… 2-321 © Practising Law Institute ~185 components ~19 different OSS licenses - most reciprocal Open Source is Big Business ANDROID -Apache 2.0 Declared license: 2-322 © Practising Law Institute Many Organizations 2-323 © Practising Law Institute Solving Problems in Many Industries Healthcare Mobile Financial Services Everything Automotive 2-324 © Practising Law Institute So, what’s the big deal? Why isn’t this just like a commercial license? In many ways they are the same: z Both commercial and open source licenses are based on ownership of intellectual property. -

Analysis and Development of a Game of the Genre Roguelike
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA CURSO DE CIÊNCIA DA COMPUTAÇÃO CIRO GONÇALVES PLÁ DA SILVA Analysis and Development of a Game of the Roguelike Genre Final Report presented in partial fulfillment of the requirements for the degree of Bachelor of Computer Science. Advisor: Prof. Dr. Raul Fernando Weber Porto Alegre 2015 UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL Reitor: Prof. Carlos Alexandre Netto Vice-Reitor: Prof. Rui Vicente Oppermann Pró-Reitor de Graduação: Prof. Sérgio Roberto Kieling Franco Diretor do Instituto de Informática: Prof. Luís da Cunha Lamb Coordenador do Curso de Ciência da Computação: Prof. Raul Fernando Weber Bibliotecária-Chefe do Instituto de Informática: Beatriz Regina Bastos Haro ACKNOWLEDGEMENTS First, I would like to thank my advisor Raul Fernando Weber for his support and crucial pieces of advisement. Also, I'm grateful for the words of encouragement by my friends, usually in the form of jokes about my seemingly endless graduation process. I'm also thankful for my brother Michel and my sister Ana, which, despite not being physically present all the time, were sources of inspiration and examples of hard work. Finally, and most importantly, I would like to thank my parents, Isabel and Roberto, for their unending support. Without their constant encouragement and guidance, this work wouldn't have been remotely possible. ABSTRACT Games are primarily a source of entertainment, but also a substrate for developing, testing and proving theories. When video games started to popularize, more ambitious projects demanded and pushed forward the development of sophisticated algorithmic techniques to handle real-time graphics, persistent large-scale virtual worlds and intelligent non-player characters. -

Learning Combat in Nethack
Proceedings, The Thirteenth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE-17) Learning Combat in NetHack Jonathan Campbell, Clark Verbrugge School of Computer Science McGill University, Montreal´ [email protected] [email protected] Abstract We evaluate our learning-based results on two scenarios, one that isolates the weapon selection problem, and one that Combat in roguelikes involves careful strategy to best match is extended to consider a full inventory context. Our ap- a large variety of items and abilities to a given opponent, and proach shows improvement over a simple (scripted) baseline the significant scripting effort involved can be a major bar- rier to automation. This paper presents a machine learning combat strategy, and is able to learn to choose appropriate approach for a subset of combat in the game of NetHack.We weaponry and take advantage of inventory contents. describe a custom learning approach intended to deal with A learned model for combat eliminates the tedium and the large action space typical of this genre, and show that it is difficulty of hard-coding responses for each monster and able to develop and apply reasonable strategies, outperform- player inventory arrangement. For roguelikes in general, this ing a simpler baseline approach. These results point towards is a major source of complexity, and the ability to learn good better automation of such complex game environments, facil- responses opens up potential for AI bots to act as useful de- itating automated testing and design exploration. sign agents, enabling better game tuning and balance con- trol. Further automation of player actions also has advantage Introduction in allowing players to confidently delegate highly repetitive or routine tasks to game automation, and facilitates players In many game genres combat can require non-trivial plan- operating with reduced interfaces (Sutherland 2017). -

Gender Identity, Roleplay, and Character Gender Selection in Nethack
Gender Identity, Roleplay, and Character Gender Selection in NetHack Soren Bjornstad December 12, 2012 Contents 1 Purpose 2 2 NetHack 2 2.1 NetHack as a Role-Playing Game . 2 2.2 Gender in NetHack . 3 3 Survey Design 4 3.1 Data Sources . 5 3.2 Player Questions . 6 3.3 Character Questions . 6 3.4 Bias . 6 3.5 Mid-Survey Changes . 7 4 Results 7 4.1 Player Demographics . 8 4.2 Overall Character Gender Preference . 9 4.3 Preference By Player Gender . 10 4.4 Preference By Player Gender { Practical Considerations Removed . 10 4.5 Prevalence of Role-Playing Mindset . 12 4.6 Character Gender Preference due to Player Gender Identity . 13 5 Conclusion 13 5.1 Ideas for Further Research . 14 6 Notes 14 7 References 14 1 1 Purpose To determine: a) general demographics of NetHack players; b) if players have practical reasons for choosing the in-game gender they do; c) if not, what other reasons people have, to what extent people role-play by selecting gender, and how many people play a different gender from their real-life self. 2 NetHack NetHack is a roguelike* game in which one descends approximately 50 dungeon levels in search of the legendary Amulet of Yendor. It incorporates elements from various works of literature, historical events, systems of mythology, and popular culture. It is extremely difficult to master; some players claim to have played for ten years or more without ever winning (ascending in NetHack parlance). This is primarily because death is permanent|if a player dies, he or she must start the entire game from the beginning again.