TITLE: Computer Science II (Algorithms) SPEAKER: Paolo Ferragina, University of Pisa Bocconi University Ph.D. in Statistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Academic Profiles of Conference Speakers
Academic Profiles of Conference Speakers 1. Cavazza, Marta, Associate Professor of the History of Science in the Facoltà di Scienze della Formazione (University of Bologna) Professor Cavazza’s research interests encompass seventeenth- and eighteenth-century Italian scientific institutions, in particular those based in Bologna, with special attention to their relations with the main European cultural centers of the age, namely the Royal Society of London and the Academy of Sciences in Paris. She also focuses on the presence of women in eighteenth- century Italian scientific institutions and the Enlightenment debate on gender, culture and society. Most of Cavazza’s published works on these topics center on Laura Bassi (1711-1778), the first woman university professor at Bologna, thanks in large part to the patronage of Benedict XIV. She is currently involved in the organization of the rich program of events for the celebration of the third centenary of Bassi’s birth. Select publications include: Settecento inquieto: Alle origini dell’Istituto delle Scienze (Bologna: Il Mulino, 1990); “The Institute of science of Bologna and The Royal Society in the Eighteenth century”, Notes and Records of The Royal Society, 56 (2002), 1, pp. 3- 25; “Una donna nella repubblica degli scienziati: Laura Bassi e i suoi colleghi,” in Scienza a due voci, (Firenze: Leo Olschki, 2006); “From Tournefort to Linnaeus: The Slow Conversion of the Institute of Sciences of Bologna,” in Linnaeus in Italy: The Spread of a Revolution in Science, (Science History Publications/USA, 2007); “Innovazione e compromesso. L'Istituto delle Scienze e il sistema accademico bolognese del Settecento,” in Bologna nell'età moderna, tomo II. -

WUDR Biology
www.cicerobook.com Biology 2021 TOP-500 Double RankPro 2021 represents universities in groups according to the average value of their ranks in the TOP 500 of university rankings published in a 2020 World University Country Number of universities Rank by countries 1-10 California Institute of Technology Caltech USA 1-10 Harvard University USA Australia 16 1-10 Imperial College London United Kingdom Austria 2 1-10 Massachusetts Institute of Technology USA Belgium 7 1-10 Stanford University USA Brazil 1 1-10 University College London United Kingdom Canada 12 1-10 University of California, Berkeley USA China 14 1-10 University of Cambridge United Kingdom Czech Republic 1 1-10 University of Oxford United Kingdom Denmark 4 1-10 Yale University USA Estonia 1 11-20 Columbia University USA Finland 4 11-20 Cornell University USA France 9 11-20 ETH Zürich-Swiss Federal Institute of Technology Zurich Switzerland Germany 26 11-20 Johns Hopkins University USA Greece 1 11-20 Princeton University USA Hong Kong 3 11-20 University of California, Los Angeles USA Ireland 4 11-20 University of California, San Diego USA Israel 4 11-20 University of Pennsylvania USA Italy 11 11-20 University of Toronto Canada Japan 6 11-20 University of Washington USA Netherlands 9 21-30 Duke University USA New Zealand 2 21-30 Karolinska Institutet Sweden Norway 3 21-30 Kyoto University Japan Portugal 2 21-30 Ludwig-Maximilians University of Munich Germany Rep.Korea 5 21-30 National University of Singapore Singapore Saudi Arabia 2 21-30 New York University USA Singapore 2 21-30 -

1 Curriculum Vitae of Andrea Vezzulli (March 2018)
Curriculum vitae of Andrea Vezzulli (March 2018) PERSONAL DETAILS: First Name: Andrea Family Name: Vezzulli Gender: Male Place and date of birth: Codogno (LO), Italy. July 19th, 1975 Nationality: Italian Residence address: Via Campagna, 51 26865 San Rocco al Porto (LO) - Italy. Phone: +390377569412(home) +393393541281(mobile) Email: [email protected] EDUCATION: (2006) PhD in Economics, University of Milan, Milan. Thesis title: Bayesian Estimation of Zero Inflated Count Panel Data Models. Methodological Issues and an application to Academic Patenting. Thesis advisor: Prof. Matteo Manera. Examining Committee: Prof. Massimiliano Marcellino, Prof. Eliana La Ferrara, Prof. Alessandra Venturini. (2002) Laurea (MA) in Political Science (major in Economics and Statistics), University of Milan, Milan. Dissertation title: Analysis of a Temporary Work Agency database using Data Mining Techniques. Grade: 106/110. Advisors: Prof. Stefano Maria Iacus, Prof. Giuseppe Porro, Prof. Daniele Checchi. RESEARCH INTERESTS: Banking, innovation and technology transfer, SMEs financing, econometrics. CURRENT POSITION: (December 2016 – present) Assistant Professor (RTDb), Department of Economics, University of Insubria (IT). (April 2013 – present) Research Affiliate (external), ICRIOS – Bocconi University (IT). PREVIOUS POSITIONS: (October 2016 – December 2016) Contract Agent, European Commission Joint Research Centre (JRC), Unit I.1 – Modelling, Indicators and Impact Evaluation - Competence Centre on Composite Indicators and Scoreboards (CC-COIN). (August 2015 – September 2016) Post-Doc Researcher, Department of Economics and Management, University of Pisa (IT). (March 2010 – March 2015) Research Associate (Investigador Auxiliar), UECE/ISEG – University of Lisbon – Lisbon (PT). (March 2009 – March 2010) Post-Doc Research Fellow, Department of Management, University of Bologna, Bologna (IT). (January 2006 – January 2009) Post-Doc Fellow, KITeS/CESPRI – Bocconi University, Milan (IT). -

Annual Report 2019
ANNUAL REPORT 2019 SAR Italy is a partnership between Italian higher education institutions and research centres and Scholars at Risk, an international network of higher education institutions aimed at fostering the promotion of academic freedom and protecting the fundamental rights of scholars across the world. In constituting SAR Italy, the governance structures of adhering institutions, as well as researchers, educators, students and administrative personnel send a strong message of solidarity to scholars and institutions that experience situations whereby their academic freedom is at stake, and their research, educational and ‘third mission’ activities are constrained. Coming together in SAR Italy, the adhering institutions commit to concretely contributing to the promotion and protection of academic freedom, alongside over 500 other higher education institutions in 40 countries in the world. Summary Launch of SAR Italy ...................................................................................................................... 3 Coordination and Networking ....................................................................................................... 4 SAR Italy Working Groups ........................................................................................................... 5 Sub-national Networks and Local Synergies ................................................................................ 6 Protection .................................................................................................................... -

URA Visiting Scholar Awardees
URA Visiting Scholar Awardees Spring 2008 • Emanuela Barberis, Northeastern University • Marcela Carena and Harry Cheung, Fermilab (group award organized for selected participants from URA member universities) • Benjamin Carls, University of Illinois at Urbana-Champaign • Charles Cox and David Cox, University of California, Davis • Andre De Gouvea, Northwestern University • Richard Evans, University of Illinois at Urbana-Champaign • Patrick Fox and Graham Kribs, University of Oregon (for selected participants from URA member universities for a workshop at Fermilab) • Elvira Gamiz Sanchez, University of Illinois at Urbana-Champaign • Davide Gerbaudo, Princeton University • Igor Gorelov and Sally Seidel, University of New Mexico • Michael Kordosky, College of William and Mary • Marek Szymon Kos, Syracuse University • Jeffrey Nelson, College of William and Mary • Robert Shrock, State University of New York at Stony Brook • Pavel Snopok, University of California, Riverside • Marco Trovato, University of Pisa • Shannon Zelitch, University of Virginia • Guo Quan (Jack) Zhang, University of New Mexico Fall 2008 • Dante Amidei, University of Michigan • Durdana Balakishiyeva, University of Florida • Patrick Fox, Peter Skands, and Benjamin Kilminster, Fermilab (group award organized for selected participants from URA member universities) • Cecilia Gerber, University of Illinois at Chicago • Joseph Grange, University of Florida • Zijn Guo, Johns Hopkins University • Kristian Hahn, Massachusetts Institute of Technology • Klaus Honscheid, Ohio State -

Department of Political Science 2016 Conference Presentations And
DEPARTMENT OF POLITICAL SCIENCE 2016 CONFERENCE PRESENTATIONS AND INVITED LECTURES ARASH ABIZADEH Conferences: “The Promise of Sortition.”, Roundtable, American Political Science Association, Philadelphia, Sept. 1–4, 2016 “Hobbes’s Theory of the Good: Felicity by Anticipatory Pleasure.”, Department of Politics, University of York, June 16, 2016 “Hobbes’s Theory of the Good: Felicity by Anticipatory Pleasure.”, Just World Institute, University of Edinburgh, June 15, 2016 “Subjectivism, Instrumentalism, and Prudentialism about Reasons: On the Normativity of Instrumental Transmission.”, Foundations of Normativity Workshop, University of Edinburgh, June 13–14, 2016 “The Special-Obligations Challenge to More Open Borders.”, Nathanson Centre, Osgoode Hall, Feb. 5, 2016 “Hobbes’s Theory of the Good: Felicity by Anticipatory Pleasure.”, UCLA Political Theory Workshop, Jan. 29, 2016 Workshops: “Representation, Bicameralism, and Sortition: Reconstituting the Senate as a Randomly Selected Citizen Assembly”, Centre for the Study of Democratic Citizenship, workshop on Representation, Bicameralism, and Sortition: With Application to the Canadian Senate, 2016 LEONARDO BACCINI Conferences: APSA, Philadelphia, September 2016 IPES, Duke University, November 2016 Political Economy of Reforms, University of Mannheim, December 2016 Workshops: Workshop organized by International Organization, University of Pennsylvania, June 2016 Workshop on international organizations, Rice University, November 2016 Seminar in Political Economy, Yale University, -

Librettospring 2018
Rutgers Department of Italian - Spring 2018 The Rutgers LibrettoSpring 2018 A letter from the chair... uring this past academic year we have had a very busy scholarly agenda, D with two conferences in the fall (one organized by Rhiannon Welch, one the traditional biannual graduate students’ conference), several lectures, one roundtable, and our department colloquia “Food for Thought” twice a semester. You can read about all of this more in detail in the pages ahead. Following the principle of rotation, there will be some changes in the department officers starting next year. I have completed my second term as Chair and Andrea Baldi will take over on July 1. Paola Gambarota will be on leave next year and I will be Graduate Program Director for the next three years. Rhiannon Welch has been renewed and will continue to serve as Undergraduate Program Director for another three years (while being replaced in the fall by Carmela Scala as Acting UGD). Serving as Chair for six years has had its challenges, especially at a time when humanities departments across the country are being plagued by drastic drops in enrollments, to the point of causing identity crises and shattering traditional ways of relating teaching to our research. I want to congratulate my colleagues for being very proactive and coming up with original and successful ideas from very early on, when figuring out what strategies we needed to adopt in order to attract students in different and unprecedented ways. We have completely overhauled our undergraduate curriculum, created new courses in English aimed at reaching out to students, who would otherwise never take Italian, Table of Contents • Marchetta Family History, p. -
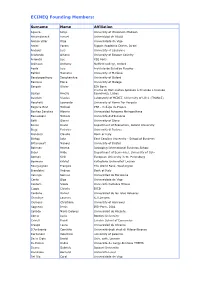
Founding Members
ECINEQ Founding Members: Surname Name Affiliation Aguero Jorge University of Wisconsin-Madison Ahramdanech Ismael Universidad de Alcalá Alonso Villar Olga Universidade de Vigo Amiel Yoram Ruppin Academic Center, Israel Angeles Luis University of Lausanne Aristondo Oihana University of Basque Country Arrondel Luc PSE París Atkinson Anthony Nuffield College, Oxford Ayala Luis Instituto de Estudios Fiscales Baldini Massimo University of Modena Bandyopadhyay Sanghamitra University of Oxford Barcena Elena University of Malaga Bargain Olivier IZA Bonn Centro de Matemática Aplicada à Previsão e Decisão Bastos Amélia Económica, Lisboa Bauduin Nicolas Laboratory of MEDEE. University of Lille1 (FRANCE) Becchetti Leonardo University of Rome Tor Vergata Begorre Bret Michael PSE - Collège de France Benitez Sanchez Alberto Universidad Autooma Metropolitana Bernasconi Michele Università dell'Insubria Betti Gianni University of Siena Bevan David Department of Economics, Oxford University Biagi Federico Università di Padova Biancotti Claudia Bank of Italy Bishop John East Carolina University - School of Business Bittencourt Manoel University of Bristol Bohman Helena Jonkoping International Business School Bojer Hilde Department of Economics, University of Oslo Borisov Kirill European University in St. Petersburg Bosmans Kristof Katholieke Universiteit Leuven Bourguignon François The World Bank, Washington Brandolini Andrea Bank of Italy Calonge Samuel Universidad de Barcelona Canto Olga Universidade de Vigo Cantore Nicola Università Cattolica Milano Cappa Claudia IUED Cardona Daniel Universidad de las Islas Baleares Cherchye Laurens K.U.Leuven Clemens Christiane University of Hannover Cogneau Denis IRD-Paris, DIAL Collado Maria Dolores Universidad de Alicante Corno Lucia Bocconi University Cowell Frank London School of Economics Crespo Laura Universidad de Alicante D'Ambrosio Conchita Universitá degli studi di Milano-Bicocca Dardanoni Valentino univeristy of palermo De la Croix David Univ. -

Open Access in Italy: Report 2009
Open Access in Italy: report 2009 Open Access in Italy Report 2009 Update December 2009 Created by: Paola Gargiulo [email protected] Maria Cassella [email protected] Version 01/2009 Rome, 31/12/2009 Page 1 of 19 Open Access in Italy: report 2009 CONTENTS 1. Open Access in Italy: an overview…………………………………………..3 2. Institutional repositories and disciplinary based repositories in Italy………………………………………………………………………………………… 2.1 Institutional repositories 2.2 Repositories content 2.3 OA mandates in Italy 2.4 Disciplinary based repositories 3. Infrastructure and services provided by supercomputing consortia……………………………………………………………………………………….. 3.1 PLEIADI 3.2 SURPlus 4. Italian peer-reviewed journals 4.1 OA Journals…………………………………………………………………. 4.2 OS software for OA journals 5. OA monographs in Italy 6. Future challenges and conclusions Page 2 of 19 Open Access in Italy: report 2009 1. Open Access in Italy: an overview In Italy the OA movement has mainly pursued a “ bottom up approach”. Librarians, IT professionals, senior researchers, early adopters in individual universities and research centres have been actively involved in promoting awareness on OA issues, in implementing repositories, in planning projects, writing policies, developing tools. Initially, the academic institutional hierarchies failed to take any clear stand on the issue. No specific national funding has been allocated for open access initiatives and in most cases the implementation of the Open Archive was financed with ordinary budget expenditures. In a limited number of cases (i.e. University of Cagliari, University of Naples Parthenope, University of Sassari, and University of Trieste) the repositories were successfully funded under Regional spending. To date neither the government nor the Ministry of Education and Research have made any recommendations on this matter or provided any funding. -

Unipi.Veringlese-Web
The City of Pisa Pisa is world famous for its Leaning Tower, Cathedral, botanical garden (founded in 1543 making it the oldest in Europe) and many other historical monuments. It is located in Tuscany, in the centre of the Italian peninsula, near the coast of the Mediterranean Sea. Its multicul- tural population totals around 100,000 people, in addi- tion to the many thousands of students who enliven the city. Its cultural life revolves around museums, cultural associations, cinemas and theatres, making Pisa a great place to live and study. Application Process To enrol at the University of Pisa, students who hold a foreign high school diploma must have attended school for at least 12 years. In order to apply for a Master’s de- gree programme, the university must first evaluate the student’s academic qualifications and see whether s/he Università di Pisa fulfils the requirements based on the university degree, Lungarno Pacinotti 43-44 study programme and exams taken abroad. Different rules apply depending on whether students are EU or I-56126 Pisa non-EU citizens: Italy www.unipi.it/eu-student-enrolment www.unipi.it/noneu-student-enrolment Fees and scholarships www.unipi.it University fees depend on the student’s country of ori- [email protected] gin and can vary from €250 up to around €2,300. Stu- dents can apply for a scholarship provided by the DSU (Regional “Right to Study” programme) and be granted tuition waivers or reductions based on family income. The annual call for DSU grants is published in the month of July at the DSU Toscana website www.dsu.toscana.it. -

4Th VPDE–BRICK WORKSHOP
Call for papers for the 4th VPDE–BRICK WORKSHOP for doctoral students in Economics of Innovation, Complexity and Knowledge Collegio Carlo Alberto, Moncalieri, Turin December 15-16, 2016 The Vilfredo Pareto Doctorate program of the University of Turin and the BRICK, Collegio Carlo Alberto, are pleased to announce the 4th Doctoral Workshop in Economics of Innovation, Complexity and Knowledge. The aim of the workshop is to bring together PhD students from all over the world working in the broad fields of Economics of Innovation, Complexity and Knowledge. The Workshop will provide participants with a great opportunity to network with peers researching on similar topics and to receive feedbacks from both junior and senior scholars. We invite PhD students to submit an extended abstract (max 1000 words) of their medium or advanced stage paper on the following topics: Diffusion of Innovation Green Innovation Innovation & Employment Innovation & Migration Biased Technological Change Innovation Policy Entrepreneurship & Firm Dynamics Knowledge Exchange and Co-creation Research Networks and Collaborations Scientific Careers and Mobility Agent-based Models for Economic Analysis Network Analysis for Economic Purposes We also welcome papers on the above topics that adopt historical analysis as methodological approach. Outline The workshop will cover two days (December 15-16, 2016) and will take place at the Collegio Carlo Alberto (Moncalieri, Turin). Each PhD student paper will be assigned to a junior (a fellow PhD student) and to a senior -

University Master Degree in Implant Dentistry
19th - 23rd April 2021 | 20th - 24th September 2021 | 10th - 14th January 2022 | 04th - 08th April 2022 | 12th - 16th September 2022 | 14th - 18th November 2022 Lido di Camaiore (LU) 90 ECTS Prof. Ugo Covani, Dr. Simone Marconcini, Prof. Annamaria Genovesi, Dr. Shawqi Al-Hashemi, Dr. Aman Bharti, Prof. Andrea Bianchi, Prof. Roberto Crespi, Dr. Kishore Kumar, Prof. Giovanni Battista Menchini Fabris, Dr. Luigi Rubino, Dr. Signorini Luca, Dr. Angelo Sisti University Master Degree In Implant Dentistry LUCCA Istituto Stomatologico Toscano Versilia Hospital 55041 Lido di Camaiore LU Tel. 0584 618414 SPEAKERS | Prof. Ugo Covani, MD DDS Professor Medicine Doctor - Certified in Surgery and in Stomatology President of Istituto Stomatologico Toscano c/o Versilia general Hospital Former Full Professor of Dentistry – University of Pisa Visiting Professor – Dept. Oral and Maxillo-facial Surgery – State University of New York at Buffalo (USA) Past-President della Società Italiana di Chirurgia Orale, dell’European Board of Oral Surgery e dell’Italian Academy of Osseointegration Author of about 300 publicazions, half of them in international peer reviewed journals and 5 books and as many book chapters. Dr. Simone Marconcini, DDS PhD MSc Responsible for the Scientific Research at the Tuscan Stomatologic Institute – research fundation - http://www.istitutostomatologicotoscano.it/ (Lido di Camaiore, Italy), Doctor of Philosophy in Nanotechnology at the University of Genova, MSc in Bone Reconstruction, award-winning specialist in oral surgery and implantology (University of Pisa), with over 10 years experience of research in oral health. Strong communication and leadership skills that helped expanding the scientific network of the Tuscan Stomatologic Institute. National scientific qualification as associate professor in stomatology with experience in teaching at the University of Pisa in graduate and post-graduate courses.