The Formalism of Quantum Mechanics Relevant Sections in Text
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Glossary Physics (I-Introduction)
1 Glossary Physics (I-introduction) - Efficiency: The percent of the work put into a machine that is converted into useful work output; = work done / energy used [-]. = eta In machines: The work output of any machine cannot exceed the work input (<=100%); in an ideal machine, where no energy is transformed into heat: work(input) = work(output), =100%. Energy: The property of a system that enables it to do work. Conservation o. E.: Energy cannot be created or destroyed; it may be transformed from one form into another, but the total amount of energy never changes. Equilibrium: The state of an object when not acted upon by a net force or net torque; an object in equilibrium may be at rest or moving at uniform velocity - not accelerating. Mechanical E.: The state of an object or system of objects for which any impressed forces cancels to zero and no acceleration occurs. Dynamic E.: Object is moving without experiencing acceleration. Static E.: Object is at rest.F Force: The influence that can cause an object to be accelerated or retarded; is always in the direction of the net force, hence a vector quantity; the four elementary forces are: Electromagnetic F.: Is an attraction or repulsion G, gravit. const.6.672E-11[Nm2/kg2] between electric charges: d, distance [m] 2 2 2 2 F = 1/(40) (q1q2/d ) [(CC/m )(Nm /C )] = [N] m,M, mass [kg] Gravitational F.: Is a mutual attraction between all masses: q, charge [As] [C] 2 2 2 2 F = GmM/d [Nm /kg kg 1/m ] = [N] 0, dielectric constant Strong F.: (nuclear force) Acts within the nuclei of atoms: 8.854E-12 [C2/Nm2] [F/m] 2 2 2 2 2 F = 1/(40) (e /d ) [(CC/m )(Nm /C )] = [N] , 3.14 [-] Weak F.: Manifests itself in special reactions among elementary e, 1.60210 E-19 [As] [C] particles, such as the reaction that occur in radioactive decay. -

Or Continuous Spectrum and Not to the Line Spectra. in the X-Ray Region, In
662 PHYSICS: W. D UA NE PROC. N. A. S. intensity is greatest close to -80 and that it falls off regularly as the angle departs therefrom. We conclude, therefore, that the momentum of the electron in its orbit uithin the atom does not affect the direction of ejection in the way denanded by the theory of Auger and Perrin. While this does not constitute definite evidence against the physical reality of electronic orbits, it is a serious difficulty for the conception. A detailed discussion of the general question here raised in the light of new experimental results will be published elsewhere. 1 Auger, P., J. Physique Rad., 8, 1927 (85-92). 2 Loughridge, D. H., in press. 3 Bothe, W., Zs. Physik, 26, 1924 (59-73). 4 Auger, P., and Perrin, F., J. Physique Rad., 8, 1927 (93-111). 6 Bothe, W., Zs. Physik, 26,1924 (74-84). 6 Watson, E. C., in press. THE CHARACTER OF THE GENERAL, OR CONTINUOUS SPEC- TRUM RADIA TION By WILLIAM DuANX, DJPARTMSNT OF PHysIcs, HARVARD UNIVERSITY Communicated August 6, 1927 The impacts of electrons against atoms produce two different kinds of radiation-the general, or continuous spectrum and the line spectra. By far the greatest amount of energy radiated belongs to the general, or continuous spectrum and not to the line spectra. In the X-ray region, in particular, the continuous, or general radiation spectrum carries most of the radiated energy. In spite of this, and because the line spectra have an important bearing on atomic structure, the general radiation has received much less attention than the line spectra in the recent de- velopment of fundamental ideas in physical science. -

Discrete-Continuous and Classical-Quantum
Under consideration for publication in Math. Struct. in Comp. Science Discrete-continuous and classical-quantum T. Paul C.N.R.S., D.M.A., Ecole Normale Sup´erieure Received 21 November 2006 Abstract A discussion concerning the opposition between discretness and continuum in quantum mechanics is presented. In particular this duality is shown to be present not only in the early days of the theory, but remains actual, featuring different aspects of discretization. In particular discreteness of quantum mechanics is a key-stone for quantum information and quantum computation. A conclusion involving a concept of completeness linking dis- creteness and continuum is proposed. 1. Discrete-continuous in the old quantum theory Discretness is obviously a fundamental aspect of Quantum Mechanics. When you send white light, that is a continuous spectrum of colors, on a mono-atomic gas, you get back precise line spectra and only Quantum Mechanics can explain this phenomenon. In fact the birth of quantum physics involves more discretization than discretness : in the famous Max Planck’s paper of 1900, and even more explicitly in the 1905 paper by Einstein about the photo-electric effect, what is really done is what a computer does: an integral is replaced by a discrete sum. And the discretization length is given by the Planck’s constant. This idea will be later on applied by Niels Bohr during the years 1910’s to the atomic model. Already one has to notice that during that time another form of discretization had appeared : the atomic model. It is astonishing to notice how long it took to accept the atomic hypothesis (Perrin 1905). -

Spectrum (Functional Analysis) - Wikipedia, the Free Encyclopedia
Spectrum (functional analysis) - Wikipedia, the free encyclopedia http://en.wikipedia.org/wiki/Spectrum_(functional_analysis) Spectrum (functional analysis) From Wikipedia, the free encyclopedia In functional analysis, the concept of the spectrum of a bounded operator is a generalisation of the concept of eigenvalues for matrices. Specifically, a complex number λ is said to be in the spectrum of a bounded linear operator T if λI − T is not invertible, where I is the identity operator. The study of spectra and related properties is known as spectral theory, which has numerous applications, most notably the mathematical formulation of quantum mechanics. The spectrum of an operator on a finite-dimensional vector space is precisely the set of eigenvalues. However an operator on an infinite-dimensional space may have additional elements in its spectrum, and may have no eigenvalues. For example, consider the right shift operator R on the Hilbert space ℓ2, This has no eigenvalues, since if Rx=λx then by expanding this expression we see that x1=0, x2=0, etc. On the other hand 0 is in the spectrum because the operator R − 0 (i.e. R itself) is not invertible: it is not surjective since any vector with non-zero first component is not in its range. In fact every bounded linear operator on a complex Banach space must have a non-empty spectrum. The notion of spectrum extends to densely-defined unbounded operators. In this case a complex number λ is said to be in the spectrum of such an operator T:D→X (where D is dense in X) if there is no bounded inverse (λI − T)−1:X→D. -

Continuous Spectrum—Kirchoff's First
Continuous Spectrum—Kirchoff’s First Law • A hot opaque substance (solid, liquid or gas) gives off a continuous spectrum, that is, a spectrum containing energy at all wavelengths. • Examples where a continuous spectrum will be found: • An incandescent bulb. • A pool of molten iron • Lava flowing from a volcano. • A hot, ionized, opaque gas (such as below the Sun’s atmosphere). • A continuous spectrum approximates a black body spectrum, the spectrum observed from a perfectly black substance heated to a high temperature. No real spectrum is a perfect black body spectrum, but many are good approximations to it. AST 303: Chapter 13 1 Black-body (Continuous) Spectrum • The energy distribution of a black body spectrum looks like this: 1000 Visible 100 10 UV Infrared Intensity (arbitrary units) 1 1000 3000 10000 30000 100000 Wavelength (Ångstroms) AST 303: Chapter 13 2 Wien’s Law—Temperature Dependence (1) • We are familiar with the fact that the color of a heated object changes as its temperature changes. As we heat a substance, it first glows a dull red; then a bright red, then orange, yellow, white, and finally bluish-white. This happens because the distribution of energy with wavelength shifts to predominantly shorter and shorter wavelengths as the temperature rises. • Mathematically, we can calculate the wavelength of maximum emission: 3 !107 Wavelength of Maximum = Å T where T is the temperature in degrees Kelvin. AST 303: Chapter 13 3 How Color Varies with Temperature AST 303: Chapter 13 4 Emission Spectra—Kirchoff’s Second Law • When a transparent gas is heated to a high temperature, one sees an emission spectrum, also known as a bright-line spectrum. -

Continuous Spectrum X-Rays from Thin Targets
RP 60 CONTINUOUS SPECTRUM X RAYS FROM THIN TARGETS * By Warren W. Nicholas 2 Technique is described for the use of thin metal foils as anticathodes in X-ray- tubes. The continuous radiation from these foils is analyzed by a crystal, the intensities being measured by a photographic comparison method. It is indicated that the high-frequency limit of the continuous spectrum from an infinitely thin target consists of a finite discontinuity. (The corresponding thick target spectrum has only a discontinuity of slope.) The energy distributions on a frequency scale are approximately horizontal, for gold and for aluminum, and for ^=40°, 90°, and 140°, where \I/ is the angle between measured X rays and cathode stream; this agrees with Kramer's, but not with Wentzel's, theory. The intensities for these values of \p are roughly 3:2:1, respectively; theories have not yet been constructed for the variation with \p of resolved energy, but it is pointed out that the observations do not support a supposed quantum process in which a single cathode ray, losing energy hv by interaction with a nucleus, radiates a single frequency v in the continuous spectrum. The observations do not support the "absorption" process assumed by Lenard, in which cathode rays, in penetrating a metal, suffered large losses of speed not accompanied by radiation. The manner in which thick target spectra are synthesized from thin is discussed, and empirical laws are formulated describing the dependence on of thick target continuous spectrum energy. A structure for the moving \f/ electron is proposed which explains classically X ray continuous spectrum phenomena, and seems to have application in other fields as well. -

X-Ray Emission Spectrum
X-ray Emission Spectrum Dr. Ahmed Alsharef Farah Dr. Ahmed Alsharef Farah 1 • X-ray photons produced by an X-ray tube are heterogeneous in energy. • The energy spectrum shows a continuous distribution of energies for the bremsstrahlung photons superimposed by characteristic radiation of discrete energies. Dr. Ahmed Alsharef Farah 2 There are two types of X-ray spectrum: 1. Bremsstrahlung or continuous spectrum. 2. Characteristic spectrum. Dr. Ahmed Alsharef Farah 3 • A bremsstrahlung spectrum consists of X- ray photons of all energies up to maximum in a continuous fashion, which is also known as white radiation, because of its similarity to white light. • A characteristic spectrum consists of X-ray photons of few energy, which is also called as line spectrum. • The position of the characteristic radiation depends upon the atomic number of the target. Dr. Ahmed Alsharef Farah 4 Dr. Ahmed Alsharef Farah 5 Characteristic X-ray Spectrum: • The discrete energies of characteristic x- rays are characteristic of the differences between electron binding energies in a particular element. • A characteristic x-ray from tungsten, for example, can have 1 of 15 different energies and no others. Dr. Ahmed Alsharef Farah 6 Characteristic X-rays of Tungsten and Their Effective Energies (keV). Dr. Ahmed Alsharef Farah 7 Characteristic x-ray emission spectrum for tungsten contains 15 different x-ray energies. Dr. Ahmed Alsharef Farah 8 • Such a plot is called the characteristic x-ray emission spectrum. • Five vertical lines representing K x-rays and four vertical lines representing L x-rays are included. • The lower energy lines represent characteristic emissions from the outer electron shells. -

Flexible Learning Approach to Physics (FLAP)
ATOMIC SPECTRA AND THE HYDROGEN ATOM MODULE P8.2 F PAGE P8.2.1 Module P8.2 Atomic spectra and the hydrogen atom 1 Opening items 1 Ready to study? 2 The production of atomic spectra 3 Study comment To study this module you will need to understand the following terms: 2.1 Characteristic emission spectra 3 absolute temperature, angular momentum, angular frequency, atom, Boltzmann’s constant, 2.2 Continuous emission spectra; the centripetal force, circular motion, Coulomb’s law, diffraction grating, dispersion, electric black-body spectrum 4 potential energy, electromagnetic radiation, electromagnetic spectrum (including ultraviolet 2.3 Absorption spectra 4 and infrared), electronvolt, energy conservation, force, frequency the grating relation 2.4 Summary of Section 2 5 λ2 2 1 1θ (n = d sin n), kinetic energy, molecule momentum, momentum conservation, Newton’s 3 The emission spectrum of laws of motion, orders of diffraction, wavelength. In addition, some familiarity with the use atomic hydrogen 5 of basic algebra, exponentials, graph plotting, logarithms and trigonometric functions will 3.1 The visible spectrum of atomic be assumed. If you are uncertain about any of these terms, review them now by reference to hydrogen; Balmer’s formula 6 the Glossary, which will also indicate where in FLAP they are developed. 3.2 The ultraviolet and infrared series of lines for hydrogen 6 Module summary 3.3 Summary of Section 3 7 1 The spectrum of a sample of electromagnetic radiation shows the way in which 4 Bohr’s model for the hydrogen atom 7 the energy carried by that radiation is distributed with respect to wavelength 4.1 The four postulates 7 (or frequency). -

Electromagnetic Radiation Production of Light
Electromagnetic Radiation Production of Light Full window version (looks a little nicer). Click <Back> button to get back to small framed version with content indexes. This material (and images) is copyrighted!. See my copyright notice for fair use practices. When light is passed through a prism or a diffraction grating to produce a spectrum, the type of spectrum you will see depends on what kind of object is producing the light: is it a thick or thin gas, is it hot or cool, is it a gas or a solid? There are two basic types of spectra: continuous spectrum (energy at all wavelengths) and discrete spectrum (energy at only certain wavelengths). Astronomers usually refer to the two types of discrete spectra: emission lines (bright lines) and absorption lines (dark lines in an otherwise continuous spectrum) as different types of spectra. Continuous Spectrum A rainbow is an example of a continuous spectrum. Most continuous spectra are from hot, dense objects like stars, planets, or moons. The continuous spectrum from these kinds of objects is also called a thermal spectrum, because hot, dense objects will emit electromagnetic radiation at all wavelengths or colors. Any solid, liquid and dense (thick) gas at a temperature above absolute zero will produce a thermal spectrum. A thermal spectrum is the simplest type of spectrum because its shape depends on only the temperature. A discrete spectrum is more complex because it depends on temperature and other things like the chemical composition of the object, the gas density, surface gravity, speed, etc. Exotic objects like neutron stars and black holes can produce another type of continuous spectrum called ``synchrotron spectrum'' from charged particles swirling around magnetic fields, but I will discuss them in another chapter later on. -
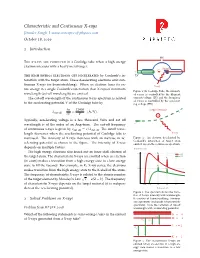
Characteristic and Continuous X-Rays Jitender Singh| October 18, 2019
Characteristic and Continuous X-rays Jitender Singh| www.concepts-of-physics.com October 18, 2019 1 Introduction HV • • The x-rays are produced in a Coolidge tube when a high energy −+ electron interacts with a heavy metal target. Anode e− +−• Cathode • The high energy electrons get decelerated by Coulomb’s in- LV teraction with the target atom. These decelerating electrons emit con- tinuous X-rays (or bremsstrahlung). When an electron loses its en- X-ray tire energy in a single Coulomb’s interaction then X-rays of minimum Figure 1: In Coolidge Tube, the intensity wavelength (cut-off wavelength) are emitted. of x-rays is controlled by the filament The cut-off wavelength of the continuous X-ray spectrum is related current/voltage (LV) and the frequency of x-rays is controlled by the accelerat- to the accelerating potential V of the Coolidge tube by ing voltage (HV). hc 12400 Target Nucleus • − lcut off = ≈ (Å/V). e eV V + Typically, accelerating voltage is a few thousand Volts and cut off • − wavelength is of the order of an Angstrom. The cut-off frequency e of continuous x-rays is given by ncut off = c/lcut off. The cutoff wave- length decreases when the accelerating potential of Coolidge tube is X-ray increased. The intensity of X-rays increases with an increase in ac- Figure 2: An electron decelerated by Coulomb’s interaction of target atom celerating potential as shown in the figure. The intensity of X-rays emits X-rays in the continuous spectrum. depends on multiple factors. Relative Intensity The high energy electrons also knock out an inner shell electron of 1.0 K a 50 kV the target atom. -

The Spectrum of Atomic Hydrogen
The Spectrum of Atomic Hydrogen For almost a century light emitted by the simplest of atoms has been the chief experimental basis for theories of the structure of matter. Exploration of the hydrogen spectrum continues, now aided by lasers by Theodor W. Hansch, Arthur L. Schawlow and George W. Series he spectrum of the hydrogen atom sorbed. glvmg rise to dark lines on a that he could account for the positions has proved to be the Rosetta stone bright background. of all the known lines by applying a sim Tof modern physics: once this pat Hydrogen is the simplest of atoms. be ple empirical formula. The entire set of tern of lines had been deciphered much ing made up of a single electron and a lines has since come to be known as the else could also be understood. Most no nucleus that consists of a single proton. Balmer series. Another group of lines. tably. it was largely the effort to explain and so it can be expected to have the the Lyman series. lies in the far ultravio the spectrum of light emitted by the hy simplest spectrum. The spectrum is not. let. and there are other series at longer drogen atom that inspired the laws of however. an easy one to record. The wavelengths. Within each series the in quantum mechanics. Those laws have most prominent line was detected in dividual lines are designated by Greek since been found to apply not only to 1853 by Anders Jonas Angstrom. (The letters. starting with the line of longest the hydrogen atom but also to other common unit for measuring wave wavelength. -

The Role of the Rigged Hilbert Space in Quantum Mechanics
The role of the rigged Hilbert space in Quantum Mechanics Rafael de la Madrid Departamento de F´ısica Te´orica, Facultad de Ciencias, Universidad del Pa´ıs Vasco, 48080 Bilbao, Spain E-mail: [email protected] Abstract. There is compelling evidence that, when continuous spectrum is present, the natural mathematical setting for Quantum Mechanics is the rigged Hilbert space rather than just the Hilbert space. In particular, Dirac’s bra-ket formalism is fully implemented by the rigged Hilbert space rather than just by the Hilbert space. In this paper, we provide a pedestrian introduction to the role the rigged Hilbert space plays in Quantum Mechanics, by way of a simple, exactly solvable example. The procedure will be constructive and based on a recent publication. We also provide a thorough discussion on the physical significance of the rigged Hilbert space. PACS numbers: 03.65.-w, 02.30.Hq arXiv:quant-ph/0502053v1 9 Feb 2005 The RHS in Quantum Mechanics 2 1. Introduction It has been known for several decades that Dirac’s bra-ket formalism is mathematically justified not by the Hilbert space alone, but by the rigged Hilbert space (RHS). This is the reason why there is an increasing number of Quantum Mechanics textbooks that already include the rigged Hilbert space as part of their contents (see, for example, Refs. [1]-[9]). Despite the importance of the RHS, there is still a lack of simple examples for which the corresponding RHS is constructed in a didactical manner. Even worse, there is no pedagogical discussion on the physical significance of the RHS.