Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions
UC Berkeley UC Berkeley Electronic Theses and Dissertations Title Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions Permalink https://escholarship.org/uc/item/4fw6x5b3 Author Frye, Charles Gearhart Publication Date 2020 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions by Charles Gearhart Frye A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Neuroscience in the Graduate Division of the University of California, Berkeley Committee in charge: Associate Professor Michael R DeWeese, Co-chair Adjunct Assistant Professor Kristofer E Bouchard, Co-chair Professor Bruno A Olshausen Assistant Professor Moritz Hardt Spring 2020 Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions Copyright 2020 by Charles Gearhart Frye 1 Abstract Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions by Charles Gearhart Frye Doctor of Philosophy in Neuroscience University of California, Berkeley Associate Professor Michael R DeWeese, Co-chair Adjunct Assistant Professor Kristofer E Bouchard, Co-chair Despite the fact that the loss functions of deep neural networks are highly non-convex, gradient-based optimization algorithms converge to approximately the same performance from many random initial points. This makes neural networks easy to train, which, com- bined with their high representational capacity and implicit and explicit regularization strategies, leads to machine-learned algorithms of high quality with reasonable computa- tional cost in a wide variety of domains. One thread of work has focused on explaining this phenomenon by numerically character- izing the local curvature at critical points of the loss function, where gradients are zero. -
Accelerated Reader Book List
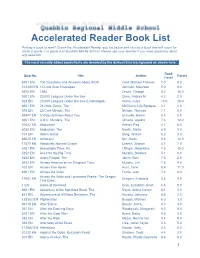
Accelerated Reader Book List Picking a book to read? Check the Accelerated Reader quiz list below and choose a book that will count for credit in grade 7 or grade 8 at Quabbin Middle School. Please see your teacher if you have questions about any selection. The most recently added books/tests are denoted by the darkest blue background as shown here. Book Quiz No. Title Author Points Level 8451 EN 100 Questions and Answers About AIDS Ford, Michael Thomas 7.0 8.0 101453 EN 13 Little Blue Envelopes Johnson, Maureen 5.0 9.0 5976 EN 1984 Orwell, George 8.2 16.0 9201 EN 20,000 Leagues Under the Sea Clare, Andrea M. 4.3 2.0 523 EN 20,000 Leagues Under the Sea (Unabridged) Verne, Jules 10.0 28.0 6651 EN 24-Hour Genie, The McGinnis, Lila Sprague 4.1 2.0 593 EN 25 Cent Miracle, The Nelson, Theresa 7.1 8.0 59347 EN 5 Ways to Know About You Gravelle, Karen 8.3 5.0 8851 EN A.B.C. Murders, The Christie, Agatha 7.6 12.0 81642 EN Abduction! Kehret, Peg 4.7 6.0 6030 EN Abduction, The Newth, Mette 6.8 9.0 101 EN Abel's Island Steig, William 6.2 3.0 65575 EN Abhorsen Nix, Garth 6.6 16.0 11577 EN Absolutely Normal Chaos Creech, Sharon 4.7 7.0 5251 EN Acceptable Time, An L'Engle, Madeleine 7.5 15.0 5252 EN Ace Hits the Big Time Murphy, Barbara 5.1 6.0 5253 EN Acorn People, The Jones, Ron 7.0 2.0 8452 EN Across America on an Emigrant Train Murphy, Jim 7.5 4.0 102 EN Across Five Aprils Hunt, Irene 8.9 11.0 6901 EN Across the Grain Ferris, Jean 7.4 8.0 Across the Wide and Lonesome Prairie: The Oregon 17602 EN Gregory, Kristiana 5.5 4.0 Trail Diary.. -

Music for Guitar
So Long Marianne Leonard Cohen A Bm Come over to the window, my little darling D A Your letters they all say that you're beside me now I'd like to try to read your palm then why do I feel so alone G D I'm standing on a ledge and your fine spider web I used to think I was some sort of gypsy boy is fastening my ankle to a stone F#m E E4 E E7 before I let you take me home [Chorus] For now I need your hidden love A I'm cold as a new razor blade Now so long, Marianne, You left when I told you I was curious F#m I never said that I was brave It's time that we began E E4 E E7 [Chorus] to laugh and cry E E4 E E7 Oh, you are really such a pretty one and cry and laugh I see you've gone and changed your name again A A4 A And just when I climbed this whole mountainside about it all again to wash my eyelids in the rain [Chorus] Well you know that I love to live with you but you make me forget so very much Oh, your eyes, well, I forget your eyes I forget to pray for the angels your body's at home in every sea and then the angels forget to pray for us How come you gave away your news to everyone that you said was a secret to me [Chorus] We met when we were almost young deep in the green lilac park You held on to me like I was a crucifix as we went kneeling through the dark [Chorus] Stronger Kelly Clarkson Intro: Em C G D Em C G D Em C You heard that I was starting over with someone new You know the bed feels warmer Em C G D G D But told you I was moving on over you Sleeping here alone Em Em C You didn't think that I'd come back You know I dream in colour -

Poem for a Friend
the whole wide world (1980-2013) copyright © 2013 by big poppa e book design by big poppa e www.bigpoppae.com all rights reserved. except as permitted under the u.s. copyright act of 1976, no part of this publication may be reproduced, distributed, or transmitted in any form or by any means, or stored in a database or retrieval system, without the prior written permission of big poppa e or his official representatives. any work contained within this publication may be freely performed in front of live audiences without first obtaining permission from big poppa e. furthermore, video and audio recordings of these works by anyone other than big poppa e can be freely posted and distributed on the world wide web or by any other means as long as no profit is generated. video and audio recordings of big poppa e performing his own works, however, may not be reproduced or distributed without the prior written permission of big poppa e. in plain english, it’s totally okay for you to read anything in this book out loud any time you want without permission, and if you record yourself doing the work, no worries, share it with anyone you like. but you are not allowed to record big poppa e reading his work out loud, and you are not allowed to share or sell videos or mp3s of big poppa e doing his work. it’s not that big poppa e doesn’t… okay, you know what, this is me, big poppa e, and i am talking directly to you. -

Final Exam Guide Guide
MATH 408 FINAL EXAM GUIDE GUIDE This exam will consist of three parts: (I) Linear Least Squares, (II) Quadratic Optimization, and (III) Optimality Conditions and Line Search Methods. The topics covered on the first two parts ((I) Linear Least Squares and (II) Quadratic Optimization) are identical in content to the two parts of the midterm exam. Please use the midterm exam study guide to prepare for these questions. A more detailed description of the third part of the final exam is given below. III Optimality Conditions and Line search methods. 1 Theory Question: For this question you will need to review all of the vocabulary words as well as the theorems on the weekly guides for Elements of Multivariable Calculus, Optimality Conditions for Unconstrained Problems, and Line search methods. You may be asked to provide statements of first- and second-order optimality conditions for unconstrained problems. In addition, you may be asked about the role of convexity in optimization, how it is detected, as well as first- and second- order conditions under which it is satisfied. You may be asked to describe what a descent direction is, as well as, what the Newton and the Cauchy (gradient descent) directions are. You need to know what the backtracking line-search is, as well as the convergence guarantees of the line search methods. 2 Computation: All the computation needed for Linear Least Squares and Quadratic Optimization is fair game for this question. Mostly, however, you will be asked to compute gradients and Hessians, locate and classify stationary points for specific optimizations problems, as well as test for the convexity of a problem. -

A Line-Search Descent Algorithm for Strict Saddle Functions with Complexity Guarantees∗
A LINE-SEARCH DESCENT ALGORITHM FOR STRICT SADDLE FUNCTIONS WITH COMPLEXITY GUARANTEES∗ MICHAEL O'NEILL AND STEPHEN J. WRIGHT Abstract. We describe a line-search algorithm which achieves the best-known worst-case com- plexity results for problems with a certain \strict saddle" property that has been observed to hold in low-rank matrix optimization problems. Our algorithm is adaptive, in the sense that it makes use of backtracking line searches and does not require prior knowledge of the parameters that define the strict saddle property. 1 Introduction. Formulation of machine learning (ML) problems as noncon- vex optimization problems has produced significant advances in several key areas. While general nonconvex optimization is difficult, both in theory and in practice, the problems arising from ML applications often have structure that makes them solv- able by local descent methods. For example, for functions with the \strict saddle" property, nonconvex optimization methods can efficiently find local (and often global) minimizers [16]. In this work, we design an optimization algorithm for a class of low-rank matrix problems that includes matrix completion, matrix sensing, and Poisson prinicipal component analysis. Our method seeks a rank-r minimizer of the function f(X), where f : Rn×m ! R. The matrix X is parametrized explicitly as the outer product of two matrices U 2 Rn×r and V 2 Rm×r, where r ≤ min(m; n). We make use throughout of the notation U (1) W = 2 (m+n)×r: V R The problem is reformulated in terms of W and an objective function F as follows: (2) min F (W ) := f(UV T ); where W , U, V are related as in (1). -

Newton Method for Stochastic Control Problems Emmanuel Gobet, Maxime Grangereau
Newton method for stochastic control problems Emmanuel Gobet, Maxime Grangereau To cite this version: Emmanuel Gobet, Maxime Grangereau. Newton method for stochastic control problems. 2021. hal- 03108627 HAL Id: hal-03108627 https://hal.archives-ouvertes.fr/hal-03108627 Preprint submitted on 13 Jan 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Newton method for stochastic control problems ∗ Emmanuel GOBET y and Maxime GRANGEREAU z Abstract We develop a new iterative method based on Pontryagin principle to solve stochastic control problems. This method is nothing else than the Newton method extended to the framework of stochastic controls, where the state dynamics is given by an ODE with stochastic coefficients. Each iteration of the method is made of two ingredients: computing the Newton direction, and finding an adapted step length. The Newton direction is obtained by solving an affine-linear Forward-Backward Stochastic Differential Equation (FBSDE) with random coefficients. This is done in the setting of a general filtration. We prove that solving such an FBSDE reduces to solving a Riccati Backward Stochastic Differential Equation (BSDE) and an affine-linear BSDE, as expected in the framework of linear FBSDEs or Linear-Quadratic stochastic control problems. -

Poetry in the Age of Consumer-Generated Content
Poetry in the Age of Consumer-Generated Content Craig Dworkin “Oh well. Whatever. Nevermind.” —Kurt Cobain1 In the last years of the twentieth century, a soi-disant “conceptual writ- ing” seemed newly relevant because of the way it read against the contem- poraneous emergence of database-driven cultures of surveillance, finance, and communication. Although it was not necessarily published online and did not exploit the advantages of computational analysis or pursue the af- fordances of digital tools, such work could be considered new media poetry because it exhibited the structural logic of the database. Adhering to Lev Manovich’sdefinition of “the new media avant-garde,” this first-phase conceptualism privileged methods of accessing, organizing, and visualiz- ing large quantities of previously accumulated data, rather than creating original material or pioneering novel styles.2 To be sure, the reign of the database is still in the ascendant, but the underlying technical structure of the internet—not to mention its cultural semantics—has changed. Ac- cordingly, one way to map the development of conceptual writing over the Thanks to Virginia Jackson, Ilan Manouach, Simon Morris, Marjorie Perloff, Katie Price, and Jonathan Stalling, who gave me the opportunity to test some of these arguments in pub- lic, and to Amanda Hurtado, Paul Stephens, and Danny Snelson, who continue to encourage and challenge and inform and inspire me. This essay is for Al Filreis, who reminded me to care. Unless otherwise noted, all translations are my own. 1. Nirvana, “Smells Like Teen Spirit,” Nevermind (DGCD-24425, 1991). 2. Quoted in Lev Manovich, “New Media from Borges to HTML,” The New Media Reader, ed. -

A Field Guide to Forward-Backward Splitting with a Fasta Implementation
A FIELD GUIDE TO FORWARD-BACKWARD SPLITTING WITH A FASTA IMPLEMENTATION TOM GOLDSTEIN, CHRISTOPH STUDER, RICHARD BARANIUK Abstract. Non-differentiable and constrained optimization play a key role in machine learn- ing, signal and image processing, communications, and beyond. For high-dimensional mini- mization problems involving large datasets or many unknowns, the forward-backward split- ting method (also known as the proximal gradient method) provides a simple, yet practical solver. Despite its apparent simplicity, the performance of the forward-backward splitting method is highly sensitive to implementation details. This article provides an introductory review of forward-backward splitting with a special emphasis on practical implementation aspects. In particular, issues like stepsize selection, acceleration, stopping conditions, and initialization are considered. Numerical experiments are used to compare the effectiveness of different approaches. Many variations of forward-backward splitting are implemented in a new solver called FASTA (short for Fast Adaptive Shrinkage/Thresholding Algorithm). FASTA provides a simple interface for applying forward-backward splitting to a broad range of problems ap- pearing in sparse recovery, logistic regression, multiple measurement vector (MMV) prob- lems, democratic representations, 1-bit matrix completion, total-variation (TV) denoising, phase retrieval, as well as non-negative matrix factorization. Contents 1. Introduction2 1.1. Outline 2 1.2. A Word on Notation2 2. Forward-Backward Splitting3 2.1. Convergence of FBS4 3. Applications of Forward-Backward Splitting4 3.1. Simple Applications5 3.2. More Complex Applications7 3.3. Non-convex Problems9 4. Bells and Whistles 11 4.1. Adaptive Stepsize Selection 11 4.2. Preconditioning 12 4.3. Acceleration 13 arXiv:1411.3406v6 [cs.NA] 28 Dec 2016 4.4. -
![Arxiv:2108.10249V1 [Math.OC] 23 Aug 2021 Adepoints](https://docslib.b-cdn.net/cover/3993/arxiv-2108-10249v1-math-oc-23-aug-2021-adepoints-3693993.webp)
Arxiv:2108.10249V1 [Math.OC] 23 Aug 2021 Adepoints
NEW Q-NEWTON’S METHOD MEETS BACKTRACKING LINE SEARCH: GOOD CONVERGENCE GUARANTEE, SADDLE POINTS AVOIDANCE, QUADRATIC RATE OF CONVERGENCE, AND EASY IMPLEMENTATION TUYEN TRUNG TRUONG Abstract. In a recent joint work, the author has developed a modification of Newton’s method, named New Q-Newton’s method, which can avoid saddle points and has quadratic rate of conver- gence. While good theoretical convergence guarantee has not been established for this method, experiments on small scale problems show that the method works very competitively against other well known modifications of Newton’s method such as Adaptive Cubic Regularization and BFGS, as well as first order methods such as Unbounded Two-way Backtracking Gradient Descent. In this paper, we resolve the convergence guarantee issue by proposing a modification of New Q-Newton’s method, named New Q-Newton’s method Backtracking, which incorporates a more sophisticated use of hyperparameters and a Backtracking line search. This new method has very good theoretical guarantees, which for a Morse function yields the following (which is unknown for New Q-Newton’s method): Theorem. Let f : Rm → R be a Morse function, that is all its critical points have invertible Hessian. Then for a sequence {xn} constructed by New Q-Newton’s method Backtracking from a random initial point x0, we have the following two alternatives: i) limn→∞ ||xn|| = ∞, or ii) {xn} converges to a point x∞ which is a local minimum of f, and the rate of convergence is quadratic. Moreover, if f has compact sublevels, then only case ii) happens. As far as we know, for Morse functions, this is the best theoretical guarantee for iterative optimization algorithms so far in the literature. -

CS260: Machine Learning Algorithms Lecture 3: Optimization
CS260: Machine Learning Algorithms Lecture 3: Optimization Cho-Jui Hsieh UCLA Jan 14, 2019 Optimization Goal: find the minimizer of a function min f (w) w For now we assume f is twice differentiable Machine learning algorithm: find the hypothesis that minimizes training error Convex function n A function f : R ! R is a convex function , the function f is below any line segment between two points on f : 8x1; x2; 8t 2 [0; 1]; f (tx1 + (1 − t)x2) ≤ tf (x1) + (1 − t)f (x2) Convex function n A function f : R ! R is a convex function , the function f is below any line segment between two points on f : 8x1; x2; 8t 2 [0; 1]; f (tx1 + (1 − t)x2)≤tf (x1) + (1 − t)f (x2) Strict convex: f (tx1 + (1 − t)x2) < tf (x1) + (1 − t)f (x2) Convex function Another equivalent definition for differentiable function: T f is convex if and only if f (x) ≥ f (x0) + rf (x0) (x − x0); 8x; x0 Convex function Convex function: (for differentiable function) rf (w ∗) = 0 , w ∗ is a global minimum If f is twice differentiable ) f is convex if and only if r2f (w) is positive semi-definite Example: linear regression, logistic regression, ··· Convex function Strict convex function: rf (w ∗) = 0 , w ∗ is the unique global minimum most algorithms only converge to gradient= 0 Example: Linear regression when X T X is invertible Convex vs Nonconvex Convex function: rf (w ∗) = 0 , w ∗ is a global minimum Example: linear regression, logistic regression, ··· Non-convex function: rf (w ∗) = 0 , w ∗ is Global min, local min, or saddle point (also called stationary points) most algorithms only -

Composing Scalable Nonlinear Algebraic Solvers
COMPOSING SCALABLE NONLINEAR ALGEBRAIC SOLVERS PETER R. BRUNE∗, MATTHEW G. KNEPLEYy , BARRY F. SMITH∗, AND XUEMIN TUz Abstract. Most efficient linear solvers use composable algorithmic components, with the most common model being the combination of a Krylov accelerator and one or more preconditioners. A similar set of concepts may be used for nonlinear algebraic systems, where nonlinear composition of different nonlinear solvers may significantly improve the time to solution. We describe the basic concepts of nonlinear composition and preconditioning and present a number of solvers applicable to nonlinear partial differential equations. We have developed a software framework in order to easily explore the possible combinations of solvers. We show that the performance gains from using composed solvers can be substantial compared with gains from standard Newton-Krylov methods. AMS subject classifications. 65F08, 65Y05, 65Y20, 68W10 Key words. iterative solvers; nonlinear problems; parallel computing; preconditioning; software 1. Introduction. Large-scale algebraic solvers for nonlinear partial differential equations (PDEs) are an essential component of modern simulations. Newton-Krylov methods [23] have well-earned dominance. They are generally robust and may be built from preexisting linear solvers and preconditioners, including fast multilevel preconditioners such as multigrid [5, 7, 9, 67, 73] and domain decomposition methods [55, 63, 64, 66]. Newton's method starts from whole-system linearization. The linearization leads to a large sparse linear system where the matrix may be represented either explicitly by storing the nonzero coefficients or implicitly by various \matrix-free" approaches [11, 42]. However, Newton's method has a number of drawbacks as a stand-alone solver. The repeated construction and solution of the linearization cause memory bandwidth and communication bottlenecks to come to the fore with regard to performance.