Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
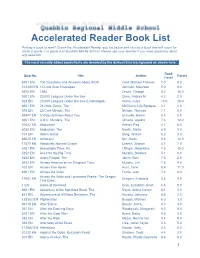
Accelerated Reader Book List
Accelerated Reader Book List Picking a book to read? Check the Accelerated Reader quiz list below and choose a book that will count for credit in grade 7 or grade 8 at Quabbin Middle School. Please see your teacher if you have questions about any selection. The most recently added books/tests are denoted by the darkest blue background as shown here. Book Quiz No. Title Author Points Level 8451 EN 100 Questions and Answers About AIDS Ford, Michael Thomas 7.0 8.0 101453 EN 13 Little Blue Envelopes Johnson, Maureen 5.0 9.0 5976 EN 1984 Orwell, George 8.2 16.0 9201 EN 20,000 Leagues Under the Sea Clare, Andrea M. 4.3 2.0 523 EN 20,000 Leagues Under the Sea (Unabridged) Verne, Jules 10.0 28.0 6651 EN 24-Hour Genie, The McGinnis, Lila Sprague 4.1 2.0 593 EN 25 Cent Miracle, The Nelson, Theresa 7.1 8.0 59347 EN 5 Ways to Know About You Gravelle, Karen 8.3 5.0 8851 EN A.B.C. Murders, The Christie, Agatha 7.6 12.0 81642 EN Abduction! Kehret, Peg 4.7 6.0 6030 EN Abduction, The Newth, Mette 6.8 9.0 101 EN Abel's Island Steig, William 6.2 3.0 65575 EN Abhorsen Nix, Garth 6.6 16.0 11577 EN Absolutely Normal Chaos Creech, Sharon 4.7 7.0 5251 EN Acceptable Time, An L'Engle, Madeleine 7.5 15.0 5252 EN Ace Hits the Big Time Murphy, Barbara 5.1 6.0 5253 EN Acorn People, The Jones, Ron 7.0 2.0 8452 EN Across America on an Emigrant Train Murphy, Jim 7.5 4.0 102 EN Across Five Aprils Hunt, Irene 8.9 11.0 6901 EN Across the Grain Ferris, Jean 7.4 8.0 Across the Wide and Lonesome Prairie: The Oregon 17602 EN Gregory, Kristiana 5.5 4.0 Trail Diary.. -

Music for Guitar
So Long Marianne Leonard Cohen A Bm Come over to the window, my little darling D A Your letters they all say that you're beside me now I'd like to try to read your palm then why do I feel so alone G D I'm standing on a ledge and your fine spider web I used to think I was some sort of gypsy boy is fastening my ankle to a stone F#m E E4 E E7 before I let you take me home [Chorus] For now I need your hidden love A I'm cold as a new razor blade Now so long, Marianne, You left when I told you I was curious F#m I never said that I was brave It's time that we began E E4 E E7 [Chorus] to laugh and cry E E4 E E7 Oh, you are really such a pretty one and cry and laugh I see you've gone and changed your name again A A4 A And just when I climbed this whole mountainside about it all again to wash my eyelids in the rain [Chorus] Well you know that I love to live with you but you make me forget so very much Oh, your eyes, well, I forget your eyes I forget to pray for the angels your body's at home in every sea and then the angels forget to pray for us How come you gave away your news to everyone that you said was a secret to me [Chorus] We met when we were almost young deep in the green lilac park You held on to me like I was a crucifix as we went kneeling through the dark [Chorus] Stronger Kelly Clarkson Intro: Em C G D Em C G D Em C You heard that I was starting over with someone new You know the bed feels warmer Em C G D G D But told you I was moving on over you Sleeping here alone Em Em C You didn't think that I'd come back You know I dream in colour -

Poem for a Friend
the whole wide world (1980-2013) copyright © 2013 by big poppa e book design by big poppa e www.bigpoppae.com all rights reserved. except as permitted under the u.s. copyright act of 1976, no part of this publication may be reproduced, distributed, or transmitted in any form or by any means, or stored in a database or retrieval system, without the prior written permission of big poppa e or his official representatives. any work contained within this publication may be freely performed in front of live audiences without first obtaining permission from big poppa e. furthermore, video and audio recordings of these works by anyone other than big poppa e can be freely posted and distributed on the world wide web or by any other means as long as no profit is generated. video and audio recordings of big poppa e performing his own works, however, may not be reproduced or distributed without the prior written permission of big poppa e. in plain english, it’s totally okay for you to read anything in this book out loud any time you want without permission, and if you record yourself doing the work, no worries, share it with anyone you like. but you are not allowed to record big poppa e reading his work out loud, and you are not allowed to share or sell videos or mp3s of big poppa e doing his work. it’s not that big poppa e doesn’t… okay, you know what, this is me, big poppa e, and i am talking directly to you. -

Poetry in the Age of Consumer-Generated Content
Poetry in the Age of Consumer-Generated Content Craig Dworkin “Oh well. Whatever. Nevermind.” —Kurt Cobain1 In the last years of the twentieth century, a soi-disant “conceptual writ- ing” seemed newly relevant because of the way it read against the contem- poraneous emergence of database-driven cultures of surveillance, finance, and communication. Although it was not necessarily published online and did not exploit the advantages of computational analysis or pursue the af- fordances of digital tools, such work could be considered new media poetry because it exhibited the structural logic of the database. Adhering to Lev Manovich’sdefinition of “the new media avant-garde,” this first-phase conceptualism privileged methods of accessing, organizing, and visualiz- ing large quantities of previously accumulated data, rather than creating original material or pioneering novel styles.2 To be sure, the reign of the database is still in the ascendant, but the underlying technical structure of the internet—not to mention its cultural semantics—has changed. Ac- cordingly, one way to map the development of conceptual writing over the Thanks to Virginia Jackson, Ilan Manouach, Simon Morris, Marjorie Perloff, Katie Price, and Jonathan Stalling, who gave me the opportunity to test some of these arguments in pub- lic, and to Amanda Hurtado, Paul Stephens, and Danny Snelson, who continue to encourage and challenge and inform and inspire me. This essay is for Al Filreis, who reminded me to care. Unless otherwise noted, all translations are my own. 1. Nirvana, “Smells Like Teen Spirit,” Nevermind (DGCD-24425, 1991). 2. Quoted in Lev Manovich, “New Media from Borges to HTML,” The New Media Reader, ed. -

Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions
Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions by Charles Gearhart Frye A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Neuroscience in the Graduate Division of the University of California, Berkeley Committee in charge: Associate Professor Michael R DeWeese, Co-chair Adjunct Assistant Professor Kristofer E Bouchard, Co-chair Professor Bruno A Olshausen Assistant Professor Moritz Hardt Spring 2020 Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions Copyright 2020 by Charles Gearhart Frye 1 Abstract Finding Critical and Gradient-Flat Points of Deep Neural Network Loss Functions by Charles Gearhart Frye Doctor of Philosophy in Neuroscience University of California, Berkeley Associate Professor Michael R DeWeese, Co-chair Adjunct Assistant Professor Kristofer E Bouchard, Co-chair Despite the fact that the loss functions of deep neural networks are highly non-convex, gradient-based optimization algorithms converge to approximately the same performance from many random initial points. This makes neural networks easy to train, which, com- bined with their high representational capacity and implicit and explicit regularization strategies, leads to machine-learned algorithms of high quality with reasonable computa- tional cost in a wide variety of domains. One thread of work has focused on explaining this phenomenon by numerically character- izing the local curvature at critical points of the loss function, where gradients are zero. Such studies have reported that the loss functions used to train neural networks have no local minima that are much worse than global minima, backed up by arguments from random matrix theory. -

Kafaldsbylur
Kafaldsbylur Söngbók búin til á www.guitarparty.com Söngbók búin til á www.guitarparty.com Bls. 2 Efnisyfirlit (Sittin' On) The Dock of the Bay . 17 A Place In The Sun . 18 Aicha . 19 Alelda . 20 All The Pretty Girls . 21 Alone . 22 American Pie . 23 And It Stoned Me . 25 Back in black . 26 Because The Night . 27 Before You Accuse Me . 28 Bittersweet Symphony . 29 Black Hole Sun . 30 Black Magic Woman . 31 Blower’s daughter . 32 Blowing In The Wind . 33 Boulevard of broken dreams . 34 Breaking the Girl . 35 Bridge Over Trouble Water . 36 Bring It On Home To Me . 37 Söngbók búin til á www.guitarparty.com Bls. 3 Brown Eyed Girl . 38 Candy . 39 Can’t take my eyes off you . 40 Cats In The Cradle . 41 Chandelier . 42 Dancing in the dark . 43 Daniel . 44 Das Model . 45 Daylight . 46 De Smukke Unge Mennesker . 47 Dead Flowers . 48 Desperado . 49 Dolphin's Cry . 50 Don't Know Why . 51 Don't stop me now . 52 Donna . 53 Don’t Stop Believing . 54 Down Under . 55 Down to the River to Pray . 56 Electric Avenue . 57 Englishman In New York . 58 Söngbók búin til á www.guitarparty.com Bls. 4 Enjoy The Silence . 59 Every breath you take . 60 Everybody hurts . 61 Exit Music (For a Film) . 62 Falling . 63 Fire Water Burn . 64 Foolish Games . 65 Forever Young . 66 Fortunate Son . 67 Free Bird . 68 Free Fallin' . 69 Freedom . 70 Friday i'm in love . 71 Fuck her gently . 72 Gimme Hope Joanna . -

Interruptingmytrainofthought W
editorial input: scott woods and tim powis cover illustration: karen watts foreword: rob sheffield Copyright © 2014 Phil Dellio All rights reserved. No part of this publication may be reproduced or trans- mitted in any form or by any means, electronic or mechanical, including scanning, photocopying, recording or any information storage and retrieval system, without permission in writing from the publisher. Typesetting and layout by Vaughn Dragland ([email protected]) ISBN: 978-1-5010-7319-9 and your mother, and your dad patricia dellio (1932 – 2009) peter dellio (1934 – 2003) contents foreword i introduction iii the publications v show no traces 1 the last phase of yours and yours and mine 31 whole new kinds of weather 49 some place back there 73 rain gray town 105 long journeys wear me out 123 fragments falling everywhere 159 if anything should happen 201 always window shopping 269 constantly aware of all the changes that occur 291 people always live and die in 4/4 time 331 in and around the lake 361 a friend i’ve never seen 415 appendix 435 acknowledgements 437 foreword The first thing I noticed about Phil Dellio was that he sure liked Neil Diamond. The second thing I noticed was that I liked Neil Diamond a lot better after reading what Phil had to say. I was reading a copy of Phil’s fanzine Radio On for the first time, riding a Charlottesville city bus in early 1991, wondering if my mind was playing tricks on me. This guy had provoc- ative comments on recent hits by C&C Music Factory and the KLF; he also wrote about musty 1960s ballads by Herb Alpert or the Vogues. -
Songbook.Cwk
CHORD TRANSPOSING CHARTS POPULAR MAJOR KEYS 1 2m 3m 4 5 6m 7dim Bb Cm Dm Eb F Gm Adim F Gm Am Bb C Dm Edim C Dm Em F G Am Bdim G Am Bm C D Em F#dim D Em F#m G A Bm C#dim A Bm C#m D E F#m G#dim E F#m G#m A B C#m D#dim EQUIVALENT MINOR KEYS 1m 2dim 3 4m 5m 6 7 Gm Adim Bb Cm Dm Eb F Dm Edim F Gm Am Bb C Am Bdim C Dm Em F G Em F#dim G Am Bm C D Bm C#dim D Em F#m G A F#m G#dim A Bm C#m D E C#m D#dim E F#m G#m A B Using the above major and minor progressions as a template non-diatonic chords can be found. For example b7 indicates a major chord based on the flatted seventh note of a major key (Bb in the key of C, F in the key of G, etc.). #1dim indicates a diminished chord on the raised first degree of a key (C#dim in the key of C, G#dim in the key of G, etc.) Complex chords may be played as major or minor. For example 1+7 (major seventh) or 37 can be played as a simple major chord. 2m7 (minor seventh) may be played as a simple minor chord. (Diminished chords must be played as diminished.) MEASURES AND LINES Songs are in 4/4 time unless indicated. -

I Don't Think We're in Kansas Anymore, Toto! Postmodernism In
Theology Matters A Publication of Presbyterians for Faith, Family and Ministry Vol 5 No 4 • Jul/Aug 1999 I Don’t Think We’re in Kansas Anymore, Toto! Postmodernism in Our Everyday Lives by Dennis L. Okholm Like Dorothy in The Wizard of Oz, some in the church feel The “Modern” in Postmodernism as if they have been spun around in a cultural tornado that If nothing else, postmodernism refers to the fact that we has left them so disoriented that about all they can do is are no longer in the Kansas of modernity anymore. That echo her puzzlement: “I don’t think we’re in Kansas means we must first understand something of “modernity” anymore, Toto!” The term “postmodernism” is often used if we are going to get a handle on postmodernity. to denote the new state in which we find ourselves. And while it occurs in our everyday speech more often than the Modernism takes us back to the Enlightenment, lodged state name “North Dakota,” it was not that long ago that its primarily in the eighteenth century, but stretching from use was confined to a relatively small group of continental seventeenth-century Descartes through Kant to Hegel and philosophers. In fact, the first time I recall seeing it in the Romantics in the nineteenth century. popular print was in an advertisement to describe the movie Pulp Fiction. This period followed the premodern period of “superstition,” blood fanaticism, and religious wars, all Still, the term has been around for some time. Though its based on the excesses and prejudicial commitments of origins are debated, it appears as early as the 1930s. -

Nirvana Never Mind Album
Nirvana Never mind Album Nirvana - Nevermind ********* * Songs * ********* Smells Like Teen Spirit In Bloom Come As You Are Breed Lithium Polly Territorial Pissings Drain You Lounge Act (missing) Stay Away (missing) On A Plain (missing) Something In The Way Endless Nameless ------------------------------------------------------------------- Smells Like Teen Spirit Main line: Riff: 2x w/o distortion. 4x with distortion + chorus) e------------------------------------ ---1------ a------------------------------------ -1-------- d-------------3-3---------------6-6-- ---------- g--3-3-3-xxxx-3-3----6-6-6-xxxx-6-6-- ---------- b--3-3-3-xxxx-1-1----6-6-6-xxxx-4-4-- ---------- E--1-1-1-xxxx--------4-4-4-xxxx------ ---------- "Solo": 2x. e------------------------------------------------------- a--1--4--4/6-----4b6b4--2--1--2--1---------------------- d-------------1---------------------3--1--3b5b3--1--0--- g------------------------------------------------------- b------------------------------------------------------- E------------------------------------------------------- . .to 4x: e-------------------------------- a-------------------------------- d---1-0---1-0---1-0---1p0-------- g---------------------------3---- b-------------------------------- E-------------------------------- Load up on guns, bring your friends It's fun to lose, and to pretend She's over bored, and self assured I know I know, A dirty word hello, hello, hello, hello. .hello, hello, hello, hello, hello, hello, hello, hello. .hello, hello, hello, hello With the lights out it's less dangerous Here we are now, entertain us I feel stupid and contagious Here we are now, entertain us. A mulatto, an albino, a mosquito, my libido, Yea! I'm worse at what I do best, and for this gift I feel blessed. I met a group that's always been And always will until the end. And I forget, just why i taste Oh yes I guess it makes me smile I found it hard. -

Paul Chaat Smith
-- EvERYTHING You KNow ABOUT INDIANS Is WRONG Paul Chaat Smith INDIGENOUS AMERICAS SERIES UNIVERSITY OF MINNESOTA PRESS MINNEAPOLIS. LONDON On Romanticism rother Eagle, Sister Sky: A Message from ChiefSeattle is a beau B tifully illustrated children's book by Susan Jeffers. This pub lication spent more than nineteen weeks on the best-seller lists and was chosen by members of the American Booksellers Associ ation as "the book we most enjoyed selling in 1991." Here's a passage from the text: How can you buy the sky? How can you own the rain and wind? My mother told me every part of this earth is sacred to our people. Every pine needle, every sandy shore. Every mist in the dark woods. Every meadow and humming insect. All are holy in the memory of our people. My father said to me, I know the sap that courses through the trees as I know the blood that flows in my veins We are part of the earth and it is part of us. The perfumed flowers are our sisters. 13 I4 I On Romanticism We love this earth as a newborn loves its mother's heartbeat. If we sell you our land, care for it as we have cared for it. Hold in your mind the memory of the land as it is when you receive it. Preserve the land and the air and the rivers for your children's children and love it as we have loved it. It's a great book with only one problem: it's a fabrication. -

DEREK HYND and the F-F-F-F-FOUNTAIN of YOUTH by Jamie Brisick
DEREK HYND AND THE F-F-F-F-FOUNTAIN OF YOUTH By Jamie Brisick About three years ago a video was posted on YouTube that not only captivated the surf world, but got it scratching its collective chin with what ifs? In it, Australian Derek Hynd takes off on a series of double-, sometimes triple-overhead waves. All appears to be normal at first. He rides in a low crouch, rear hand tickling the wave face. But there’s a subtle drift in effect. The usual traction between surfboard and wave is non-existent. As the clip kicks on we see Derek slip, slide, drift, careen, ride backwards, and spin a fit of dizzying 360s. “About fifteen years ago I watched the Daytona 500 live, and wanted that feeling on the high line,” says Derek. “I got to wonder in less than a second what it’d be like to deliberately lose friction going as fast as I could, but increase the speed. That’s what I got a glimpse into when the leading car lost it with the field up its backside, and for a tiny moment put a gap on the chasers until it flipped multiple times. It lost traction thus friction and went faster for a flash. With the pack less than a yard behind at 200mph high on the speed bank, I saw the shift.” Derek has had a long and colorful ride in surfing. He’s been a pro, a coach, a journalist, a marketing genius, a critic, a test pilot, a historian, an impresario, and now, at age 55, a finless surfer.