Comparison of Protein and Mrna Profiles of Escherichia Coli: Data Visualization and Analysis of Specific Gene Groups
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Table S1. List of Proteins in the BAHD1 Interactome
Table S1. List of proteins in the BAHD1 interactome BAHD1 nuclear partners found in this work yeast two-hybrid screen Name Description Function Reference (a) Chromatin adapters HP1α (CBX5) chromobox homolog 5 (HP1 alpha) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins (20-23) HP1β (CBX1) chromobox homolog 1 (HP1 beta) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins HP1γ (CBX3) chromobox homolog 3 (HP1 gamma) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins MBD1 methyl-CpG binding domain protein 1 Binds methylated CpG dinucleotide and chromatin-associated proteins (22, 24-26) Chromatin modification enzymes CHD1 chromodomain helicase DNA binding protein 1 ATP-dependent chromatin remodeling activity (27-28) HDAC5 histone deacetylase 5 Histone deacetylase activity (23,29,30) SETDB1 (ESET;KMT1E) SET domain, bifurcated 1 Histone-lysine N-methyltransferase activity (31-34) Transcription factors GTF3C2 general transcription factor IIIC, polypeptide 2, beta 110kDa Required for RNA polymerase III-mediated transcription HEYL (Hey3) hairy/enhancer-of-split related with YRPW motif-like DNA-binding transcription factor with basic helix-loop-helix domain (35) KLF10 (TIEG1) Kruppel-like factor 10 DNA-binding transcription factor with C2H2 zinc finger domain (36) NR2F1 (COUP-TFI) nuclear receptor subfamily 2, group F, member 1 DNA-binding transcription factor with C4 type zinc finger domain (ligand-regulated) (36) PEG3 paternally expressed 3 DNA-binding transcription factor with -

Inactive USP14 and Inactive UCHL5 Cause Accumulation of Distinct Ubiquitinated Proteins In
bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Inactive USP14 and inactive UCHL5 cause accumulation of distinct ubiquitinated proteins in mammalian cells Jayashree Chadchankar, Victoria Korboukh, Peter Doig, Steve J. Jacobsen, Nicholas J. Brandon, Stephen J. Moss, Qi Wang AstraZeneca Tufts Laboratory for Basic and Translational Neuroscience, Tufts University, Boston, MA (J.C., S.J.M.) Neuroscience, IMED Biotech Unit, AstraZeneca, Boston, MA (S.J.J., N.J.B., Q.W.) Discovery Sciences, IMED Biotech Unit, AstraZeneca, Boston, MA (V.K., P.D.) Department of Neuroscience, Tufts University School of Medicine, Boston, MA (S.J.M.) Department of Neuroscience, Physiology and Pharmacology, University College, London, WC1E, 6BT, UK (S.J.M.) 1 bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Running title: Effects of inactive USP14 and UCHL5 in mammalian cells Keywords: USP14, UCHL5, deubiquitinase, proteasome, ubiquitin, β‐catenin Corresponding author: Qi Wang Address: Neuroscience, IMED Biotech Unit, AstraZeneca, Boston, MA 02451 Email address: [email protected] 2 bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. -

Proteomic and Bioinformatic Pipeline to Screen the Ligands of S
www.nature.com/scientificreports OPEN Proteomic and bioinformatic pipeline to screen the ligands of S. pneumoniae interacting Received: 15 September 2017 Accepted: 14 March 2018 with human brain microvascular Published: xx xx xxxx endothelial cells Irene Jiménez-Munguía1, Lucia Pulzova1, Evelina Kanova1, Zuzana Tomeckova1, Petra Majerova2, Katarina Bhide1, Lubos Comor1, Ivana Sirochmanova1, Andrej Kovac2 & Mangesh Bhide1,2 The mechanisms by which Streptococcus pneumoniae penetrates the blood-brain barrier (BBB), reach the CNS and causes meningitis are not fully understood. Adhesion of bacterial cells on the brain microvascular endothelial cells (BMECs), mediated through protein-protein interactions, is one of the crucial steps in translocation of bacteria across BBB. In this work, we proposed a systematic workfow for identifcation of cell wall associated ligands of pneumococcus that might adhere to the human BMECs. The proteome of S. pneumoniae was biotinylated and incubated with BMECs. Interacting proteins were recovered by afnity purifcation and identifed by data independent acquisition (DIA). A total of 44 proteins were identifed from which 22 were found to be surface-exposed. Based on the subcellular location, ontology, protein interactive analysis and literature review, fve ligands (adhesion lipoprotein, endo-β-N-acetylglucosaminidase, PhtA and two hypothetical proteins, Spr0777 and Spr1730) were selected to validate experimentally (ELISA and immunocytochemistry) the ligand- BMECs interaction. In this study, we proposed a high-throughput approach to generate a dataset of plausible bacterial ligands followed by systematic bioinformatics pipeline to categorize the protein candidates for experimental validation. The approach proposed here could contribute in the fast and reliable screening of ligands that interact with host cells. -

Identification and the Significance of Selective Proteins in Bile And
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 12-2014 Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health- compromised Chickens Balamurugan Packialakshmi University of Arkansas, Fayetteville Follow this and additional works at: http://scholarworks.uark.edu/etd Part of the Analytical Chemistry Commons, Animal Diseases Commons, and the Poultry or Avian Science Commons Recommended Citation Packialakshmi, Balamurugan, "Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health- compromised Chickens" (2014). Theses and Dissertations. 2083. http://scholarworks.uark.edu/etd/2083 This Dissertation is brought to you for free and open access by ScholarWorks@UARK. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected], [email protected]. Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health-compromised Chickens Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health-compromised Chickens A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cell and Molecular Biology by Balamurugan Packialakshmi Tamilnadu Agricultural University, Bachelor of Technology in Agricultural Biotechnology, 2007 Govind Ballabh Pant University of Agriculture and Technology, Master of Science in Molecular Biology and Biotechnology, 2009 December 2014 University of Arkansas This dissertation is approved for the recommendation to the graduate council. _____________________ Dr. Narayan. C. Rath Dissertation Director _____________________ _____________________ Dr. Jackson O. Lay, Jr. Dr. Robert F. Wideman, Jr. Committee member Committee member ____________________ Dr. -
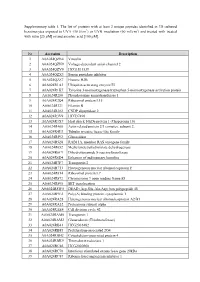
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31 -

Cross-Talk Between Overlap Interactions in Biomolecules: a Case Study of the Β-Turn Motif
molecules Article Cross-Talk between Overlap Interactions in Biomolecules: A Case Study of the b-Turn Motif Jayashree Nagesh Solid State and Structural Chemistry Unit, Indian Institute of Science Bangalore, Bengaluru 560012, Karnataka, India; [email protected] Abstract: Noncovalent interactions play a pivotal role in regulating protein conformation, stability and dynamics. Among the quantum mechanical (QM) overlap-based noncovalent interactions, n ! p∗ is the best understood with studies ranging from small molecules to b-turns of model proteins such as GB1. However, these investigations do not explore the interplay between multiple overlap interactions in contributing to local structure and stability. In this work, we identify and characterize all noncovalent overlap interactions in the b-turn, an important secondary structural element that facilitates the folding of a polypeptide chain. Invoking a QM framework of natural bond orbitals, we demonstrate the role of several additional interactions such as n ! s∗ and p ! p∗ that are energetically comparable to or larger than n ! p∗. We find that these interactions are sensitive to changes in the side chain of the residues in the b-turn of GB1, suggesting that the n ! p∗ may not be the only component in dictating b-turn conformation and stability. Furthermore, a database search of n ! s∗ and p ! p∗ in the PDB reveals that they are prevalent in most proteins and have significant interaction energies (∼1 kcal/mol). This indicates that all overlap interactions must be taken into account to obtain a comprehensive picture of their contributions to protein structure and energetics. Lastly, based on the extent of QM overlaps and interaction energies, we propose geometric criteria using which these additional interactions can be efficiently tracked in broad database searches. -

Biological Recognition of Graphene Nanoflakes
ARTICLE DOI: 10.1038/s41467-018-04009-x OPEN Biological recognition of graphene nanoflakes V. Castagnola1, W. Zhao1, L. Boselli1, M.C. Lo Giudice 1, F. Meder1, E. Polo 1, K.R. Paton2, C. Backes2, J.N. Coleman2 & K.A. Dawson1 The systematic study of nanoparticle–biological interactions requires particles to be repro- ducibly dispersed in relevant fluids along with further development in the identification of biologically relevant structural details at the materials–biology interface. Here, we develop a biocompatible long-term colloidally stable water dispersion of few-layered graphene nano- 1234567890():,; flakes in the biological exposure medium in which it will be studied. We also report the study of the orientation and functionality of key proteins of interest in the biolayer (corona) that are believed to mediate most of the early biological interactions. The evidence accumulated shows that graphene nanoflakes are rich in effective apolipoprotein A-I presentation, and we are able to map specific functional epitopes located in the C-terminal portion that are known to mediate the binding of high-density lipoprotein to binding sites in receptors that are abundant in the liver. This could suggest a way of connecting the materials' properties to the biological outcomes. 1 Centre for BioNano Interactions, School of Chemistry, University College Dublin, Belfield Dublin 4, Ireland. 2 School of Physics, CRANN and AMBER, Trinity College Dublin, Dublin 2, Ireland. Correspondence and requests for materials should be addressed to V.C. (email: [email protected]) or to K.A.D. (email: [email protected]) NATURE COMMUNICATIONS | (2018) 9:1577 | DOI: 10.1038/s41467-018-04009-x | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | DOI: 10.1038/s41467-018-04009-x ecent years have seen very active interest in understanding Results the factors that influence nanoparticle interactions with Graphene nanoflakes protein corona composition. -

USE of CLUSTERING TECHNIQUES for PROTEIN DOMAIN ANALYSIS Eric Rodene University of Nebraska - Lincoln, [email protected]
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Computer Science and Engineering: Theses, Computer Science and Engineering, Department of Dissertations, and Student Research Summer 7-29-2016 USE OF CLUSTERING TECHNIQUES FOR PROTEIN DOMAIN ANALYSIS Eric Rodene University of Nebraska - Lincoln, [email protected] Follow this and additional works at: http://digitalcommons.unl.edu/computerscidiss Part of the Biochemistry, Biophysics, and Structural Biology Commons, Bioinformatics Commons, Computer Engineering Commons, and the Computer Sciences Commons Rodene, Eric, "USE OF CLUSTERING TECHNIQUES FOR PROTEIN DOMAIN ANALYSIS" (2016). Computer Science and Engineering: Theses, Dissertations, and Student Research. 109. http://digitalcommons.unl.edu/computerscidiss/109 This Article is brought to you for free and open access by the Computer Science and Engineering, Department of at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Computer Science and Engineering: Theses, Dissertations, and Student Research by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. USE OF CLUSTERING TECHNIQUES FOR PROTEIN DOMAIN ANALYSIS by Eric T. Rodene A THESIS Presented to the Faculty of The Graduate College at the University of Nebraska In Partial Fulfillment of Requirements For the Degree of Master of Science Major: Computer Science Under the Supervision of Professors Stephen D. Scott and Etsuko N. Moriyama Lincoln, Nebraska July 2016 USE OF CLUSTERING TECHNIQUES FOR PROTEIN DOMAIN ANALYSIS Eric Rodene, M.S. University of Nebraska, 2016 Advisors: Stephen Scott, Etsuko Moriyama Next-generation sequencing has allowed many new protein sequences to be identified. However, this expansion of sequence data limits the ability to determine the structure and function of most of these newly-identified proteins. -

Biochemical Aspects of Seeds from Cannabis Sativa L. Plants Grown In
www.nature.com/scientificreports OPEN Biochemical aspects of seeds from Cannabis sativa L. plants grown in a mountain environment Chiara Cattaneo1*, Annalisa Givonetti1, Valeria Leoni2,3, Nicoletta Guerrieri4, Marcello Manfredi5, Annamaria Giorgi2,3 & Maria Cavaletto1 Cannabis sativa L. (hemp) is a versatile plant which can adapt to various environmental conditions. Hempseeds provide high quality lipids, mainly represented by polyunsaturated acids, and highly digestible proteins rich of essential aminoacids. Hempseed composition can vary according to plant genotype, but other factors such as agronomic and climatic conditions can afect the presence of nutraceutic compounds. In this research, seeds from two cultivars of C. sativa (Futura 75 and Finola) grown in a mountain environment of the Italian Alps were analyzed. The main purpose of this study was to investigate changes in the protein profle of seeds obtained from such environments, using two methods (sequential and total proteins) for protein extraction and two analytical approaches SDS-PAGE and 2D-gel electrophoresis, followed by protein identifcation by mass spectrometry. The fatty acids profle and carotenoids content were also analysed. Mountain environments mainly afected fatty acid and protein profles of Finola seeds. These changes were not predictable by the sole comparison of certifed seeds from Futura 75 and Finola cultivars. The fatty acid profle confrmed a high PUFA content in both cultivars from mountain area, while protein analysis revealed a decrease in the protein content of Finola seeds from the experimental felds. Cannabis sativa L. (hemp) is an annual plant belonging to the family of Cannabaceae. C. sativa is naturally dioe- cious, however this plant has been domesticated by humans since the prehistoric era and monoecious varieties have been selected to obtain higher quality fbers and to optimize seed harvest procedures1. -
![Viewed in (104)]](https://docslib.b-cdn.net/cover/1427/viewed-in-104-3121427.webp)
Viewed in (104)]
The Role in Translation of Editing and Multi-Synthetase Complex Formation by Aminoacyl-tRNA Synthetases Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Medha Vijay Raina, M.Sc. Ohio State Biochemistry Graduate Program The Ohio State University 2014 Dissertation Committee: Dr. Michael Ibba, Advisor Dr. Juan Alfonzo Dr. Irina Artsimovitch Dr. Kurt Fredrick Dr. Karin Musier-Forsyth Copyright by Medha Vijay Raina 2014 ABSTRACT Aminoacyl-tRNA synthetases (aaRSs) catalyze the first step of translation, aminoacylation. These enzymes attach amino acids (aa) to their cognate tRNAs to form aminoacyl-tRNA (aa-tRNA), an important substrate in protein synthesis, which is delivered to the ribosome as a ternary complex with translation elongation factor 1A (EF1A) and GTP. All aaRSs have an aminoacylation domain, which is the active site that recognizes the specific amino acid, ATP, and the 3′ end of the bound tRNA to catalyze the aminoacylation reaction. Apart from the aminoacylation domain, some aaRSs have evolved additional domains that are involved in interacting with other proteins, recognizing and binding the tRNA anticodon, and editing misacylated tRNA thereby expanding their role in and beyond translation. One such function of the aaRS is to form a variety of complexes with each other and with other factors by interacting via additional N or C terminal extensions. For example, several archaeal and eukaryotic aaRSs are known to associate with EF1A or other aaRSs forming higher order complexes, although the role of these multi-synthetase complexes (MSC) in translation remains largely unknown. -

Scholarworks @ UVM
University of Vermont ScholarWorks @ UVM Graduate College Dissertations and Theses Dissertations and Theses 2014 A Novel Approach For The deI ntification of Cytoskeletal and Adhesion A-Kinase Anchoring Proteins Laura Taylor Director University of Vermont Follow this and additional works at: https://scholarworks.uvm.edu/graddis Part of the Medical Cell Biology Commons, and the Molecular Biology Commons Recommended Citation Director, Laura Taylor, "A Novel Approach For The deI ntification of Cytoskeletal and Adhesion A-Kinase Anchoring Proteins" (2014). Graduate College Dissertations and Theses. 264. https://scholarworks.uvm.edu/graddis/264 This Thesis is brought to you for free and open access by the Dissertations and Theses at ScholarWorks @ UVM. It has been accepted for inclusion in Graduate College Dissertations and Theses by an authorized administrator of ScholarWorks @ UVM. For more information, please contact [email protected]. A NOVEL APPROACH FOR THE IDENTIFICATION OF CYTOSKELETAL AND ADHESION A-KINASE ANCHORING PROTEINS A Thesis Presented by Laura Taylor Director to The Faculty of the Graduate College of The University of Vermont In Partial Fulfillment of the Requirements for the Degree of Master of Science, Specializing in Cellular and Molecular Biology October, 2014 Accepted by the Faculty of the Graduate College, The University of Vermont, in partial fulfillment of the requirements for the degree of Master of Science, specializing in Cellular and Molecular Biology. Thesis Examination Committee: ____________________________________ Advisor Alan K. Howe, Ph.D. ____________________________________ Jason Stumpff, Ph.D. ____________________________________ Chairperson Bryan Ballif, Ph. D. ____________________________________ Dean, Graduate College Cynthia J. Forehand, Ph.D. June 13th, 2014 ABSTRACT A-kinase anchoring proteins (AKAPs) are signaling scaffolds which provide spatial and temporal organization of signaling pathways in discrete subcellular compartments. -

Fractional Precipitation of Plasma Proteome by Ammonium Sulphate
ics om & B te i ro o P in f f o o r l m a Journal of a n t r i Saha et al., J Proteomics Bioinform 2012, 5:8 c u s o J DOI: 10.4172/jpb.1000230 ISSN: 0974-276X Proteomics & Bioinformatics Research Article Article OpenOpen Access Access Fractional Precipitation of Plasma Proteome by Ammonium Sulphate: Case Studies in Leukemia and Thalassemia Sutapa Saha1, Suchismita Halder1, Dipankar Bhattacharya1, Debasis Banerjee2 and Abhijit Chakrabarti1* 1Structural Genomics Division, Saha Institute of Nuclear Physics, 1/AF, Bidhannagar, Kolkata-700064, India 2Hematology Unit, Ramakrishna Mission Seva Prathisthan, Kolkata 700026, India Abstract Human plasma proteome is a comprehensive source of disease biomarkers. However, the >10 orders-wide dynamic concentration range of its constituent proteins necessitates depletion of abundant proteins from plasma prior to biomarker discovery. Our objective has been to develop a simple method that would deplete the most abundant proteins e.g. albumin and immunoglobulins, effectively facilitating identification of differentially regulated proteins in plasma samples. We employed ammonium sulphate based pre-fractionation of plasma followed by two- dimensional gel electrophoresis (2DGE) for comparison of normal proteins with those from the plasma samples of the patients, after identification of proteins by MALDI-TOF/TOF tandem mass spectrometry. Fractional precipitation of the plasma samples by 20% ammonium sulphate from raw plasma doubled the number of protein spots after 2DGE and led to identification of 87 unique proteins, including several low-abundance proteins. Case studies done with fractional precipitation of the plasma samples of patients suffering from hematological diseases e.g.