Super Secondary Structures of Proteins with Post-Translational Modifications in Colon Cancer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Protein Structure: Data Bases and Classification
Protein Structure: Data Bases and Classification Ingo Ruczinski Department of Biostatistics, Johns Hopkins University Reference Bourne and Weissig Structural Bioinformatics Wiley, 2003 More References 1 Structural Proteins Membrane Proteins Globular Proteins 2 Terminology • Primary Structure • Secondary Structure • Tertiary Structure • Quatenary Structure • Supersecondary Structure • Domain • Fold Hierarchy of Protein Structure Helices α 3.10 π Amino acids/turn: 3.6 3.0 4.4 Frequency ~97% ~3% rare H-bonding i, i+4 i, i+3 i, i+5 3 α-helices α-helices α-helices have handedness: α-helices have a dipole: β-sheets 4 β-sheets Have a right-handed twist! β-sheets Can form higher level structures! Super Secondary Structure Motifs 5 What is a Domain? Richardson (1981): W ithin a single subunit [polypeptide chain], contiguous portions of the polypeptide chain frequently fold into compact, local semi-independent units called domains. More About Domains • Independent folding units. • Lots of within contacts, few outside. • Domains create their own hydrophobic core. • Regions usually conserved during recombination. • Different domains of the same protein can have different functions. • Domains of the same protein may or may not interact. Why Look for Domains? Domains are the currency of protein function! 6 Domain Size • Domains can be between 25 and 500 residues long. • Most are less than 200 residues. • Domains can be smaller than 50 residues, but these need to be stabilized. Examples are the zinc finger and a scorpion toxin. Two Very Small Domains A Humdinger of a Domain 7 What’s the Domain? (Part 1) What’s the Domain? (Part 2) Homology and Analogy • Homology: Similarity in characteristics resulting from shared ancestry. -

Table S1. List of Proteins in the BAHD1 Interactome
Table S1. List of proteins in the BAHD1 interactome BAHD1 nuclear partners found in this work yeast two-hybrid screen Name Description Function Reference (a) Chromatin adapters HP1α (CBX5) chromobox homolog 5 (HP1 alpha) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins (20-23) HP1β (CBX1) chromobox homolog 1 (HP1 beta) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins HP1γ (CBX3) chromobox homolog 3 (HP1 gamma) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins MBD1 methyl-CpG binding domain protein 1 Binds methylated CpG dinucleotide and chromatin-associated proteins (22, 24-26) Chromatin modification enzymes CHD1 chromodomain helicase DNA binding protein 1 ATP-dependent chromatin remodeling activity (27-28) HDAC5 histone deacetylase 5 Histone deacetylase activity (23,29,30) SETDB1 (ESET;KMT1E) SET domain, bifurcated 1 Histone-lysine N-methyltransferase activity (31-34) Transcription factors GTF3C2 general transcription factor IIIC, polypeptide 2, beta 110kDa Required for RNA polymerase III-mediated transcription HEYL (Hey3) hairy/enhancer-of-split related with YRPW motif-like DNA-binding transcription factor with basic helix-loop-helix domain (35) KLF10 (TIEG1) Kruppel-like factor 10 DNA-binding transcription factor with C2H2 zinc finger domain (36) NR2F1 (COUP-TFI) nuclear receptor subfamily 2, group F, member 1 DNA-binding transcription factor with C4 type zinc finger domain (ligand-regulated) (36) PEG3 paternally expressed 3 DNA-binding transcription factor with -

Water in Protein Structure Prediction
Water in protein structure prediction Garegin A. Papoian†‡, Johan Ulander†‡§, Michael P. Eastwood†¶, Zaida Luthey-Schultenʈ, and Peter G. Wolynes†,†† †Department of Chemistry and Biochemistry and Center for Theoretical Biological Physics, University of California at San Diego, 9500 Gilman Drive, La Jolla, CA 92093-0371; and ʈDepartment of Chemistry, University of Illinois at Urbana–Champaign, Urbana, IL 61801 Contributed by Peter G. Wolynes, December 4, 2003 Proteins have evolved to use water to help guide folding. A interactions play an important role not only in binding interfaces physically motivated, nonpairwise-additive model of water-medi- but in folding of monomeric proteins. ated interactions added to a protein structure prediction Hamilto- We use the associative memory (AM) Hamiltonian molecular nian yields marked improvement in the quality of structure pre- dynamics model as a starting point (14–16). This Hamiltonian diction for larger proteins. Free energy profile analysis suggests has two principal components: general polymer physics-based that long-range water-mediated potentials guide folding and terms that are sequence independent, collectively called ‘‘back- smooth the underlying folding funnel. Analyzing simulation tra- bone,’’ and sequence-dependent knowledge-based distance- jectories gives direct evidence that water-mediated interactions dependent additive potentials, collectively denoted as AM͞C facilitate native-like packing of supersecondary structural ele- (AM͞contact). The AM part describes interactions between all ments. Long-range pairing of hydrophilic groups is an integral part pairs of residues that are separated in sequence between 3 and of protein architecture. Specific water-mediated interactions are a 12 residues. It uses a set of nonhomologous memory proteins to universal feature of biomolecular recognition landscapes in both build a funneled energy landscape by matching fragments. -

Covalent Flexible Peptide Docking in Rosetta
bioRxiv preprint doi: https://doi.org/10.1101/2021.05.06.441297; this version posted May 6, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Covalent Flexible Peptide Docking in Rosetta Barr Tivon1,#, Ronen Gabizon1,#, Bente A. Somsen2, Peter J. Cossar2, Christian Ottmann2 , Nir London1,* 1 Department of Chemical and Structural Biology, The Weizmann Institute of Science, Rehovot, 7610001, Israel 2 Laboratory of Chemical Biology, Department of Biomedical Engineering and Institute for Complex Molecular Systems, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands # equal contribution * Corresponding author: [email protected] Keywords: Covalent peptides; peptide docking; CovPepDock; FlexPepDock; 14-3-3; Electrophilic peptides; bioRxiv preprint doi: https://doi.org/10.1101/2021.05.06.441297; this version posted May 6, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Abstract Electrophilic peptides that form an irreversible covalent bond with their target have great potential for binding targets that have been previously considered undruggable. However, the discovery of such peptides remains a challenge. Here, we present CovPepDock, a computational pipeline for peptide docking that incorporates covalent binding between the peptide and a receptor cysteine. We applied CovPepDock retrospectively to a dataset of 115 disulfide-bound peptides and a dataset of 54 electrophilic peptides, for which it produced a top-five scoring, near-native model, in 89% and 100% of the cases, respectively. -

A Global Review on Short Peptides: Frontiers and Perspectives †
molecules Review A Global Review on Short Peptides: Frontiers and Perspectives † Vasso Apostolopoulos 1 , Joanna Bojarska 2,* , Tsun-Thai Chai 3 , Sherif Elnagdy 4 , Krzysztof Kaczmarek 5 , John Matsoukas 1,6,7, Roger New 8,9, Keykavous Parang 10 , Octavio Paredes Lopez 11 , Hamideh Parhiz 12, Conrad O. Perera 13, Monica Pickholz 14,15, Milan Remko 16, Michele Saviano 17, Mariusz Skwarczynski 18, Yefeng Tang 19, Wojciech M. Wolf 2,*, Taku Yoshiya 20 , Janusz Zabrocki 5, Piotr Zielenkiewicz 21,22 , Maha AlKhazindar 4 , Vanessa Barriga 1, Konstantinos Kelaidonis 6, Elham Mousavinezhad Sarasia 9 and Istvan Toth 18,23,24 1 Institute for Health and Sport, Victoria University, Melbourne, VIC 3030, Australia; [email protected] (V.A.); [email protected] (J.M.); [email protected] (V.B.) 2 Institute of General and Ecological Chemistry, Faculty of Chemistry, Lodz University of Technology, Zeromskiego˙ 116, 90-924 Lodz, Poland 3 Department of Chemical Science, Faculty of Science, Universiti Tunku Abdul Rahman, Kampar 31900, Malaysia; [email protected] 4 Botany and Microbiology Department, Faculty of Science, Cairo University, Gamaa St., Giza 12613, Egypt; [email protected] (S.E.); [email protected] (M.A.) 5 Institute of Organic Chemistry, Faculty of Chemistry, Lodz University of Technology, Zeromskiego˙ 116, 90-924 Lodz, Poland; [email protected] (K.K.); [email protected] (J.Z.) 6 NewDrug, Patras Science Park, 26500 Patras, Greece; [email protected] 7 Department of Physiology and Pharmacology, -

Inactive USP14 and Inactive UCHL5 Cause Accumulation of Distinct Ubiquitinated Proteins In
bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Inactive USP14 and inactive UCHL5 cause accumulation of distinct ubiquitinated proteins in mammalian cells Jayashree Chadchankar, Victoria Korboukh, Peter Doig, Steve J. Jacobsen, Nicholas J. Brandon, Stephen J. Moss, Qi Wang AstraZeneca Tufts Laboratory for Basic and Translational Neuroscience, Tufts University, Boston, MA (J.C., S.J.M.) Neuroscience, IMED Biotech Unit, AstraZeneca, Boston, MA (S.J.J., N.J.B., Q.W.) Discovery Sciences, IMED Biotech Unit, AstraZeneca, Boston, MA (V.K., P.D.) Department of Neuroscience, Tufts University School of Medicine, Boston, MA (S.J.M.) Department of Neuroscience, Physiology and Pharmacology, University College, London, WC1E, 6BT, UK (S.J.M.) 1 bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Running title: Effects of inactive USP14 and UCHL5 in mammalian cells Keywords: USP14, UCHL5, deubiquitinase, proteasome, ubiquitin, β‐catenin Corresponding author: Qi Wang Address: Neuroscience, IMED Biotech Unit, AstraZeneca, Boston, MA 02451 Email address: [email protected] 2 bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. -

1 Design and Production of Specifically and with High Affinity
1 Design and Production of Specifically and with High Affinity Reacting Peptides (SHARP®-s) by Jan C Biro HOMULUS FOUNDATION, 612 S. Flower Str., #1220, 90017 CA, USA [email protected] www.janbiro.com 2 Abstract Background A partially random target selection method was developed to design and produce affinity reagents (target) to any protein query. It is based on the recent concept of Proteomic Code (for review see Biro, 2007 [1]) which suggests that significant number of amino acids in specifically interacting proteins are coded by partially complementary codons. It means that the 1st and 3rd residues of codons coding many co-locating amino acids are complementary but the 2nd may but not necessarily complementary: like 5’-AXG-3’/3’-CXT-5’ codon pair, where X is any nucleotide. Results A mixture of 45 residue long, reverse, partially complementary oligonucleotide sequences (target pool) were synthesized to selected epitopes of query mRNA sequences. The 2nd codon residues were randomized. The target oligonucleotide pool was inserted into vectors, expressed and the protein products were screened for affinity to the query in Bacterial Two-Hybrid System. The best clones were used for larger-scale protein syntheses and characterization. It was possible to design and produce specific and with high affinity reacting (Kd: ~100 nM) oligopeptide reagents to GAL4 query oligopeptides. Conclusions Second codon residue randomization is a promising method to design and produce affinity peptides to any protein sequences. The method has the potential to be a rapid, inexpensive, high throughput, non-immunoglobulin based alternative to recent in vivo antibody generating procedures. -

Proteomic and Bioinformatic Pipeline to Screen the Ligands of S
www.nature.com/scientificreports OPEN Proteomic and bioinformatic pipeline to screen the ligands of S. pneumoniae interacting Received: 15 September 2017 Accepted: 14 March 2018 with human brain microvascular Published: xx xx xxxx endothelial cells Irene Jiménez-Munguía1, Lucia Pulzova1, Evelina Kanova1, Zuzana Tomeckova1, Petra Majerova2, Katarina Bhide1, Lubos Comor1, Ivana Sirochmanova1, Andrej Kovac2 & Mangesh Bhide1,2 The mechanisms by which Streptococcus pneumoniae penetrates the blood-brain barrier (BBB), reach the CNS and causes meningitis are not fully understood. Adhesion of bacterial cells on the brain microvascular endothelial cells (BMECs), mediated through protein-protein interactions, is one of the crucial steps in translocation of bacteria across BBB. In this work, we proposed a systematic workfow for identifcation of cell wall associated ligands of pneumococcus that might adhere to the human BMECs. The proteome of S. pneumoniae was biotinylated and incubated with BMECs. Interacting proteins were recovered by afnity purifcation and identifed by data independent acquisition (DIA). A total of 44 proteins were identifed from which 22 were found to be surface-exposed. Based on the subcellular location, ontology, protein interactive analysis and literature review, fve ligands (adhesion lipoprotein, endo-β-N-acetylglucosaminidase, PhtA and two hypothetical proteins, Spr0777 and Spr1730) were selected to validate experimentally (ELISA and immunocytochemistry) the ligand- BMECs interaction. In this study, we proposed a high-throughput approach to generate a dataset of plausible bacterial ligands followed by systematic bioinformatics pipeline to categorize the protein candidates for experimental validation. The approach proposed here could contribute in the fast and reliable screening of ligands that interact with host cells. -

A Deep Learning Approach for Protein-Ligand Interaction Prediction
bioRxiv preprint doi: https://doi.org/10.1101/2019.12.20.884841; this version posted September 20, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. SSnet: A Deep Learning Approach for Protein-Ligand Interaction Prediction Niraj Verma,y,x Xingming Qu,z,x Francesco Trozzi,y,x Mohamed Elsaied,{,x Nischal Karki,y,x Yunwen Tao,y,x Brian Zoltowski,y,x Eric C. Larson,z,x and Elfi Kraka∗,y,x yDepartment of Chemistry, Southern Methodist University, Dallas TX USA zDepartment of Computer Science, Southern Methodist University, Dallas TX USA {Department of Engineering Management and Information System, Southern Methodist University, Dallas TX USA xSouthern Methodist University E-mail: [email protected] Abstract Computational prediction of Protein-Ligand Interaction (PLI) is an important step in the modern drug discovery pipeline as it mitigates the cost, time, and resources re- quired to screen novel therapeutics. Deep Neural Networks (DNN) have recently shown excellent performance in PLI prediction. However, the performance is highly dependent on protein and ligand features utilized for the DNN model. Moreover, in current mod- els, the deciphering of how protein features determine the underlying principles that govern PLI is not trivial. In this work, we developed a DNN framework named SSnet that utilizes secondary structure information of proteins extracted as the curvature and torsion of the protein backbone to predict PLI. We demonstrate the performance of SSnet by comparing against a variety of currently popular machine and non-machine learning models using various metrics. -

Identification and the Significance of Selective Proteins in Bile And
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 12-2014 Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health- compromised Chickens Balamurugan Packialakshmi University of Arkansas, Fayetteville Follow this and additional works at: http://scholarworks.uark.edu/etd Part of the Analytical Chemistry Commons, Animal Diseases Commons, and the Poultry or Avian Science Commons Recommended Citation Packialakshmi, Balamurugan, "Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health- compromised Chickens" (2014). Theses and Dissertations. 2083. http://scholarworks.uark.edu/etd/2083 This Dissertation is brought to you for free and open access by ScholarWorks@UARK. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected], [email protected]. Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health-compromised Chickens Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health-compromised Chickens A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cell and Molecular Biology by Balamurugan Packialakshmi Tamilnadu Agricultural University, Bachelor of Technology in Agricultural Biotechnology, 2007 Govind Ballabh Pant University of Agriculture and Technology, Master of Science in Molecular Biology and Biotechnology, 2009 December 2014 University of Arkansas This dissertation is approved for the recommendation to the graduate council. _____________________ Dr. Narayan. C. Rath Dissertation Director _____________________ _____________________ Dr. Jackson O. Lay, Jr. Dr. Robert F. Wideman, Jr. Committee member Committee member ____________________ Dr. -
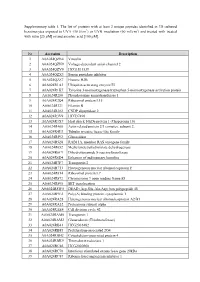
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31 -

Deep Time-Resolved Proteomic and Phosphoproteomic Profiling Of
Deep time-resolved proteomic and phosphoproteomic profiling of cigarette smoke-induced chronic obstructive pulmonary disease David Skerrett-Byrne BSc Biochem & Mol Bio (Hons)(UCD) MSc Biotech (UU) 25th March 2019 Supervisors: Professor Phil Hansbro, Dr. Matt Dun, Laureate Professor Rodney Scott, Professor Peter Wark, Professor Darryl Knight, Laureate Professor Paul Foster Discipline of Immunology and Microbiology and Priority Research Centre for Healthy Lungs School of Biomedical Science and Pharmacy Faculty of Health and Medicine University of Newcastle and Hunter Medical Research Institute Newcastle, NSW, Australia Submitted in fulfilment of the requirements for the award of a Doctor of Philosophy Declaration Statement of Originality I hereby certify that the work embodied in the thesis is my own work, conducted under normal supervision. The thesis contains no material which has been accepted, or is being examined, for the award of any other degree or diploma in any university or other tertiary institution and, to the best of my knowledge and belief, contains no material previously published or written by another person, except where due reference has been made. I give consent to the final version of my thesis being made available worldwide when deposited in the University’s Digital Repository, subject to the provisions of the Copyright Act 1968 and any approved embargo. ________________________ David Skerrett-Byrne 25/03/2019 Acknowledgment of Authorship I hereby certify that the work embodied in this thesis contains scholarly work of which I am a joint author. I have included as part of the thesis a written declaration endorsed in writing by my supervisor, attesting to my contribution to the joint scholarly work.