Annotationdbi: How to Use the ”.Db” Annotation Packages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

The Cargo Protein MAP17 (PDZK1IP1) Regulates the Immune Microenvironment
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 58), pp: 98580-98597 Research Paper The cargo protein MAP17 (PDZK1IP1) regulates the immune microenvironment José M. García-Heredia1,2,3 and Amancio Carnero1,3 1Instituto de Biomedicina de Sevilla, IBIS/Hospital Universitario Virgen del Rocío/Universidad de Sevilla/Consejo Superior de Investigaciones Científicas, Seville, Spain 2Department of Vegetal Biochemistry and Molecular Biology, University of Seville, Seville, Spain 3CIBER de Cáncer, Instituto de Salud Carlos III, Madrid, Spain Correspondence to: Amancio Carnero, email: [email protected] Keywords: MAP17; oncogene; inflammation; cancer; inflammatory diseases Received: July 14, 2017 Accepted: August 25, 2017 Published: October 06, 2017 Copyright: García-Heredia et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License 3.0 (CC BY 3.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. ABSTRACT Inflammation is a complex defensive response activated after various harmful stimuli allowing the clearance of damaged cells and initiating healing and regenerative processes. Chronic, or pathological, inflammation is also one of the causes of neoplastic transformation and cancer development. MAP17 is a cargo protein that transports membrane proteins from the endoplasmic reticulum. Therefore, its overexpression may be linked to an excess of membrane proteins that may be recognized as an unwanted signal, triggering local inflammation. Therefore, we analyzed whether its overexpression is related to an inflammatory phenotype. In this work, we found a correlation between MAP17 expression and inflammatory phenotype in tumors and in other inflammatory diseases such as Crohn's disease, Barrett's esophagus, COPD or psoriasis. -

Identification and Validation of a Blood-Based 18-Gene Expression Signature in Colorectal Cancer
Published OnlineFirst March 27, 2013; DOI: 10.1158/1078-0432.CCR-12-3851 Clinical Cancer Imaging, Diagnosis, Prognosis Research Identification and Validation of a Blood-Based 18-Gene Expression Signature in Colorectal Cancer Ye Xu1,4, Qinghua Xu1,6,7, Li Yang1,4, Xun Ye6,7, Fang Liu6,7, Fei Wu6,7, Shujuan Ni1,2,3,5, Cong Tan1,2,3,5, Guoxiang Cai1,4, Xia Meng6,7, Sanjun Cai1,4, and Xiang Du1,2,3,5 Abstract Purpose: The early detection of colorectal cancer (CRC) is crucial for successful treatment and patient survival. However, compliance with current screening methods remains poor. This study aimed to identify an accurate blood-based gene expression signature for CRC detection. Experimental Design: Gene expression in peripheral blood samples from 216 patients with CRC tumors and 187 controls was investigated in the study.Wefirstconductedamicroarrayanalysistoselect candidate genes that were significantly differentially expressed between patients with cancer and con- trols. A quantitative reverse transcription PCR assay was then used to evaluate the expression of selected genes. A gene expression signature was identified using a training set (n ¼ 200) and then validated using an independent test set (n ¼ 160). Results: We identified an 18-gene signature that discriminated the patients with CRC from controls with 92% accuracy, 91% sensitivity, and 92% specificity. The signature performance was further validated in the independent test set with 86% accuracy, 84% sensitivity, and 88% specificity. The area under the receiver operating characteristics curve was 0.94. The signature was shown to be enriched in genes related to immune functions. Conclusions: This study identified an 18-gene signature that accurately discriminated patients with CRC from controls in peripheral blood samples. -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine -

Gene Expression Analysis of Mevalonate Kinase Deficiency
International Journal of Environmental Research and Public Health Article Gene Expression Analysis of Mevalonate Kinase Deficiency Affected Children Identifies Molecular Signatures Related to Hematopoiesis Simona Pisanti * , Marianna Citro , Mario Abate , Mariella Caputo and Rosanna Martinelli * Department of Medicine, Surgery and Dentistry ‘Scuola Medica Salernitana’, University of Salerno, Via Salvatore Allende, 84081 Baronissi (SA), Italy; [email protected] (M.C.); [email protected] (M.A.); [email protected] (M.C.) * Correspondence: [email protected] (S.P.); [email protected] (R.M.) Abstract: Mevalonate kinase deficiency (MKD) is a rare autoinflammatory genetic disorder charac- terized by recurrent fever attacks and systemic inflammation with potentially severe complications. Although it is recognized that the lack of protein prenylation consequent to mevalonate pathway blockade drives IL1β hypersecretion, and hence autoinflammation, MKD pathogenesis and the molecular mechanisms underlaying most of its clinical manifestations are still largely unknown. In this study, we performed a comprehensive bioinformatic analysis of a microarray dataset of MKD patients, using gene ontology and Ingenuity Pathway Analysis (IPA) tools, in order to identify the most significant differentially expressed genes and infer their predicted relationships into biological processes, pathways, and networks. We found that hematopoiesis linked biological functions and pathways are predominant in the gene ontology of differentially expressed genes in MKD, in line with the observed clinical feature of anemia. We also provided novel information about the molecular Citation: Pisanti, S.; Citro, M.; Abate, M.; Caputo, M.; Martinelli, R. mechanisms at the basis of the hematological abnormalities observed, that are linked to the chronic Gene Expression Analysis of inflammation and to defective prenylation. -

MAP17's Up-Regulation, a Crosspoint in Cancer and Inflammatory
García-Heredia and Carnero Molecular Cancer (2018) 17:80 https://doi.org/10.1186/s12943-018-0828-7 REVIEW Open Access Dr. Jekyll and Mr. Hyde: MAP17’s up- regulation, a crosspoint in cancer and inflammatory diseases José M. García-Heredia1,2,3 and Amancio Carnero1,3* Abstract Inflammation is a common defensive response that is activated after different harmful stimuli. This chronic, or pathological, inflammation is also one of the causes of neoplastic transformation and cancer development. MAP17 is a small protein localized to membranes with a restricted pattern of expression in adult tissues. However, its expression is common in destabilized cells, as it is overexpressed both in inflammatory diseases and in cancer. MAP17 is overexpressed in most, if not all, carcinomas and in many tumors of mesenchymal origin, and correlates with higher grade and poorly differentiated tumors. This overexpression drives deep changes in cell homeostasis including increased oxidative stress, deregulation of signaling pathways and increased growth rates. Importantly, MAP17 is associated in tumors with inflammatory cells infiltration, not only in cancer but in various inflammatory diseases such as Barret’s esophagus, lupus, Crohn’s, psoriasis and COPD. Furthermore, MAP17 also modifies the expression of genes connected to inflammation, showing a clear induction of the inflammatory profile. Since MAP17 appears highly correlated with the infiltration of inflammatory cells in cancer, is MAP17 overexpression an important cellular event connecting tumorigenesis and inflammation? Keywords: MAP17, Cancer, Inflammatory diseases Background process ends when the activated cells undergo apoptosis in Inflammatory response is a common defensive process acti- a highly regulated process that finishes after pathogens and vated after different harmful stimuli, constituting a highly cell debris have been phagocytized [9]. -

Targeted Shrna Screening Identified Critical Roles of Pleckstrin-2 in Erythropoiesis
Hematopoiesis SUPPLEMENTARY APPENDIX Targeted shRNA screening identified critical roles of pleckstrin-2 in erythropoiesis Baobing Zhao,1* Ganesan Keerthivasan,1* Yang Mei,1 Jing Yang,1 James McElherne,1 Piu Wong,2 John G. Doench,3 Gang Feng,4 David E. Root,3 and Peng Ji1 1Department of Pathology, Feinberg School of Medicine, Northwestern University, Chicago, IL; 2Whitehead Institute for Biomedical Research, Cambridge, MA; 3Broad Institute of Harvard University and the Massachusetts Institute of Technology, Cambridge, MA; and 4Biomedical Informatics Center, Northwestern University, Chicago, IL, USA *BZ and GK contributed equally to this work. ©2014 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol.2014.105809 Manuscript received on February 12, 2014. Manuscript accepted on April 14, 2014. Correspondence: [email protected] Supplemental Methods Purification and culture of fetal liver cells for targeted screening Fetal liver cells were isolated from E13.5 C57BL/6 embryos and mechanically dissociated by pipetting in PBS containing 10% fetal bovine serum (GIBCO). Single-cell suspensions were prepared by passing the dissociated cells through 40 µm cell strainers (BD Biosciences). Total fetal liver cells were labeled with biotin-conjugated anti-TER119 antibody (1:100) (eBioscience), and TER119 negative cells were purified using EasySep column free cell isolation system according to the manufacturer’s instructions (Stem Cell Technologies). Purified cells were seeded in round bottom 96 well plates at a cell density of 1x103 cells/200µl media/well. The purified cells were infected by distinct lentiviruses encoding shRNAs against selected genes in each well of the 96-well plate. The infection strategies were schematically illustrated in Figure 1A. -
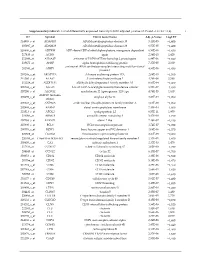
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at -

Overexpression of PDZK1IP1, EEF1A2 and RPL41 Genes in Intrahepatic Cholangiocarcinoma
4786 MOLECULAR MEDICINE REPORTS 13: 4786-4790, 2016 Overexpression of PDZK1IP1, EEF1A2 and RPL41 genes in intrahepatic cholangiocarcinoma GUANGHUA YANG1,2 and HUAJIE ZONG1 1Department of General Surgery, Huashan Hospital Affiliated to Fudan University, Shanghai 200040; 2The First Department of General Surgery, The Seventh People's Hospital Affiliated to Shanghai University of Traditional Chinese Medicine, Shanghai 200137, P.R. China Received May 8, 2015; Accepted February 24, 2016 DOI: 10.3892/mmr.2016.5110 Abstract. Intrahepatic cholangiocarcinoma (iCCA) is an iCCA molecular processes, and will enable characterization of aggressive malignancy in the liver, which is associated with a the complex mechanism underlying the development of iCCA. poor prognosis. However, the molecular pathogenesis of iCCA Numerous microarray studies have identified hundreds of differ- remains unclear. RNA-Seq for tumor and para-tumor sample entially expressed genes (DEGs) in tumor tissues or cell lines pairs enables the characterization of changes in the gene of iCCA when compared with normal intrahepatic bile duct expression profiles of patients with iCCA. The present study epithelia or normal liver tissues (3,4), and a series of genes have analyzed RNA-Seq data of seven iCCA para-tumor and tumor been revealed as potential biomarkers or therapeutic targets for sample pairs. Differential gene expression analysis demon- iCCA. A recent RNA-Seq study determined fusion and muta- strated significant upregulation of PDZK1IP1, EEF1A2 and tion in iCCA para-tumor/tumor sample pairs (5), allowing the RPL41 (ENSG00000279483) genes in the iCCA samples when comparison of gene expression in tumor samples of iCCA. compared with the matched para‑tumor samples. -

Testing for Ancient Selection Using Cross-Population Allele Frequency
bioRxiv preprint doi: https://doi.org/10.1101/017566; this version posted November 19, 2015. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 1 Testing for ancient selection using cross-population allele 2 frequency differentiation 1;∗ 3 Fernando Racimo 4 1 Department of Integrative Biology, University of California, Berkeley, CA, USA 5 ∗ E-mail: [email protected] 6 1 Abstract 7 A powerful way to detect selection in a population is by modeling local allele frequency changes in a 8 particular region of the genome under scenarios of selection and neutrality, and finding which model is 9 most compatible with the data. Chen et al. [2010] developed a composite likelihood method called XP- 10 CLR that uses an outgroup population to detect departures from neutrality which could be compatible 11 with hard or soft sweeps, at linked sites near a beneficial allele. However, this method is most sensitive 12 to recent selection and may miss selective events that happened a long time ago. To overcome this, 13 we developed an extension of XP-CLR that jointly models the behavior of a selected allele in a three- 14 population tree. Our method - called 3P-CLR - outperforms XP-CLR when testing for selection that 15 occurred before two populations split from each other, and can distinguish between those events and 16 events that occurred specifically in each of the populations after the split. -

Transcriptome Sequencing of Malignant Pleural Mesothelioma Tumors
Transcriptome sequencing of malignant pleural mesothelioma tumors David J. Sugarbaker*†‡, William G. Richards*†, Gavin J. Gordon*†, Lingsheng Dong*†, Assunta De Rienzo*†, Gautam Maulik*†, Jonathan N. Glickman§, Lucian R. Chirieac§, Mor-Li Hartman*†, Bruce E. Taillon¶, Lei Du¶, Pascal Bouffard¶, Stephen F. Kingsmoreʈ, Neil A. Millerʈ, Andrew D. Farmerʈ, Roderick V. Jensen**, Steven R. Gullans††, and Raphael Bueno*† *International Mesothelioma Program, †Division of Thoracic Surgery, §Department of Pathology, Brigham and Women’s Hospital and Harvard Medical School, 75 Francis Street, Boston, MA 02115; ¶454 Life Sciences, Inc., 20 Commercial Street, Branford, CT 06405; ʈNational Center for Genome Resources (NCGR), 2935 Rodeo Park Drive East, Santa Fe, NM 87505; **Virginia Bioinformatics Institute, Virginia Polytechnic Institute and State University, Blacksburg, VA 24060; and ††RxGen, Inc., 100 Deepwood Drive, Hamden, CT 06517 Communicated by Elliott D. Kieff, Harvard University, Boston, MA, December 31, 2007 (received for review July 6, 2007) Cancers arise by the gradual accumulation of mutations in multiple (16). Expression profiling with microarrays has supported the genes. We now use shotgun pyrosequencing to characterize RNA general role of inflammation in MPM etiology and has provided mutations and expression levels unique to malignant pleural molecular markers for diagnosis and prognosis (17). More mesotheliomas (MPMs) and not present in control tissues. On extensive genomic analysis, as with deep sequencing of tumors, average, 266 Mb of cDNA were sequenced from each of four MPMs, could identify potential targets for new biological drugs for this from a control pulmonary adenocarcinoma (ADCA), and from devastating cancer. normal lung tissue. Previously observed differences in MPM RNA Newly developed DNA sequencing technologies (18, 19) allow expression levels were confirmed.