Maat: Automatically Analyzing Virustotal for Accurate Labeling and Effective Malware Detection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Testing Anti-Virus in Linux: How Effective Are the Solutions Available for Desktop Computers?
Royal Holloway University of London ISG MSc Information Security thesis series 2021 Testing anti-virus in Linux: How effective are the solutions available for desktop computers? Authors Giuseppe Raffa, MSc (Royal Holloway, 2020) Daniele Sgandurra, Huawei, Munich Research Center. (Formerly ISG, Royal Holloway.) Abstract Anti-virus (AV) programs are widely recognized as one of the most important defensive tools available for desktop computers. Regardless of this, several Linux users consider AVs unnec- essary, arguing that this operating system (OS) is “malware-free”. While Windows platforms are undoubtedly more affected by malicious software, there exist documented cases of Linux- specific malware. In addition, even though the estimated market share of Linux desktop sys- tems is currently only at 2%, it is certainly possible that it will increase in the near future. Considering all this, and the lack of up-to-date information about Linux-compatible AV solutions, we evaluated the effectiveness of some anti-virus products by using local installations, a well- known on-line malware scanning service (VirusTotal) and a renowned penetration testing tool (Metasploit). Interestingly, in our tests, the average detection rate of the locally-installed AV programs was always above 80%. However, when we extended our analysis to the wider set of anti-virus solutions available on VirusTotal, we found out that the average detection rate barely reached 60%. Finally, when evaluating malicious files created with Metasploit, we verified that the AVs’ heuristic detection mechanisms performed very poorly, with detection rates as low as 8.3%.a aThis article is published online by Computer Weekly as part of the 2021 Royal Holloway informa- tion security thesis series https://www.computerweekly.com/ehandbook/Royal-Holloway-Testing-antivirus- efficacy-in-Linux. -

Page 1 of 3 Virustotal
VirusTotal - Free Online Virus, Malware and URL Scanner Page 1 of 3 VT Community Sign in ▼ Languages ▼ Virustotal is a service that analyzes suspicious files and URLs and facilitates the quick detection of viruses, worms, trojans, and all kinds of malware detected by antivirus engines. More information... 0 VT Community user(s) with a total of 0 reputation credit(s) say(s) this sample is goodware. 0 VT Community VT Community user(s) with a total of 0 reputation credit(s) say(s) this sample is malware. File name: wsusoffline71.zip Submission date: 2011-11-01 08:16:44 (UTC) Current status: finished not reviewed Result: 0 /40 (0.0%) Safety score: - Compact Print results Antivirus Version Last Update Result AhnLab-V3 2011.10.31.00 2011.10.31 - AntiVir 7.11.16.225 2011.10.31 - Antiy-AVL 2.0.3.7 2011.11.01 - Avast 6.0.1289.0 2011.11.01 - AVG 10.0.0.1190 2011.11.01 - BitDefender 7.2 2011.11.01 - CAT-QuickHeal 11.00 2011.11.01 - ClamAV 0.97.3.0 2011.11.01 - Commtouch 5.3.2.6 2011.11.01 - Comodo 10625 2011.11.01 - Emsisoft 5.1.0.11 2011.11.01 - eSafe 7.0.17.0 2011.10.30 - eTrust-Vet 36.1.8650 2011.11.01 - F-Prot 4.6.5.141 2011.11.01 - F-Secure 9.0.16440.0 2011.11.01 - Fortinet 4.3.370.0 2011.11.01 - GData 22 2011.11.01 - Ikarus T3.1.1.107.0 2011.11.01 - Jiangmin 13.0.900 2011.10.31 - K7AntiVirus 9.116.5364 2011.10.31 - Kaspersky 9.0.0.837 2011.11.01 - McAfee 5.400.0.1158 2011.11.01 - McAfee-GW-Edition 2010.1D 2011.10.31 - Microsoft 1.7801 2011.11.01 - NOD32 6591 2011.11.01 - Norman 6.07.13 2011.10.31 - nProtect 2011-10-31.01 2011.10.31 - http://www.virustotal.com/file -scan/report.html?id=874d6968eaf6eeade19179712d53 .. -
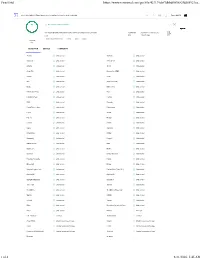
Virustotal Scan on 2020.08.21 for Pbidesktopsetup 2
VirusTotal https://www.virustotal.com/gui/file/423139def3dbbdf0f5682fdd88921ea... 423139def3dbbdf0f5682fdd88921eaface84ff48ef2e2a8d20e4341ca4a4364 Patch My PC No engines detected this file 423139def3dbbdf0f5682fdd88921eaface84ff48ef2e2a8d20e4341ca4a4364 269.49 MB 2020-08-21 11:39:09 UTC setup Size 1 minute ago invalid-rich-pe-linker-version overlay peexe signed Community Score DETECTION DETAILS COMMUNITY Acronis Undetected Ad-Aware Undetected AegisLab Undetected AhnLab-V3 Undetected Alibaba Undetected ALYac Undetected Antiy-AVL Undetected SecureAge APEX Undetected Arcabit Undetected Avast Undetected AVG Undetected Avira (no cloud) Undetected Baidu Undetected BitDefender Undetected BitDefenderTheta Undetected Bkav Undetected CAT-QuickHeal Undetected ClamAV Undetected CMC Undetected Comodo Undetected CrowdStrike Falcon Undetected Cybereason Undetected Cyren Undetected eScan Undetected F-Secure Undetected FireEye Undetected Fortinet Undetected GData Undetected Ikarus Undetected Jiangmin Undetected K7AntiVirus Undetected K7GW Undetected Kaspersky Undetected Kingsoft Undetected Malwarebytes Undetected MAX Undetected MaxSecure Undetected McAfee Undetected Microsoft Undetected NANO-Antivirus Undetected Palo Alto Networks Undetected Panda Undetected Qihoo-360 Undetected Rising Undetected Sangfor Engine Zero Undetected SentinelOne (Static ML) Undetected Sophos AV Undetected Sophos ML Undetected SUPERAntiSpyware Undetected Symantec Undetected TACHYON Undetected Tencent Undetected TrendMicro Undetected TrendMicro-HouseCall Undetected VBA32 Undetected -

An Analysis of Domain Classification Services
Mis-shapes, Mistakes, Misfits: An Analysis of Domain Classification Services Pelayo Vallina Victor Le Pochat Álvaro Feal IMDEA Networks Institute / imec-DistriNet, KU Leuven IMDEA Networks Institute / Universidad Carlos III de Madrid Universidad Carlos III de Madrid Marius Paraschiv Julien Gamba Tim Burke IMDEA Networks Institute IMDEA Networks Institute / imec-DistriNet, KU Leuven Universidad Carlos III de Madrid Oliver Hohlfeld Juan Tapiador Narseo Vallina-Rodriguez Brandenburg University of Universidad Carlos III de Madrid IMDEA Networks Institute/ICSI Technology ABSTRACT ACM Reference Format: Domain classification services have applications in multiple areas, Pelayo Vallina, Victor Le Pochat, Álvaro Feal, Marius Paraschiv, Julien including cybersecurity, content blocking, and targeted advertising. Gamba, Tim Burke, Oliver Hohlfeld, Juan Tapiador, and Narseo Vallina- Rodriguez. 2020. Mis-shapes, Mistakes, Misfits: An Analysis of Domain Yet, these services are often a black box in terms of their method- Classification Services. In ACM Internet Measurement Conference (IMC ’20), ology to classifying domains, which makes it difficult to assess October 27ś29, 2020, Virtual Event, USA. ACM, New York, NY, USA, 21 pages. their strengths, aptness for specific applications, and limitations. In https://doi.org/10.1145/3419394.3423660 this work, we perform a large-scale analysis of 13 popular domain classification services on more than 4.4M hostnames. Our study empirically explores their methodologies, scalability limitations, 1 INTRODUCTION label constellations, and their suitability to academic research as The need to classify websites became apparent in the early days well as other practical applications such as content filtering. We of the Web. The first generation of domain classification services find that the coverage varies enormously across providers, ranging appeared in the late 1990s in the form of web directories. -

Ten Strategies of a World-Class Cybersecurity Operations Center Conveys MITRE’S Expertise on Accumulated Expertise on Enterprise-Grade Computer Network Defense
Bleed rule--remove from file Bleed rule--remove from file MITRE’s accumulated Ten Strategies of a World-Class Cybersecurity Operations Center conveys MITRE’s expertise on accumulated expertise on enterprise-grade computer network defense. It covers ten key qualities enterprise- grade of leading Cybersecurity Operations Centers (CSOCs), ranging from their structure and organization, computer MITRE network to processes that best enable effective and efficient operations, to approaches that extract maximum defense Ten Strategies of a World-Class value from CSOC technology investments. This book offers perspective and context for key decision Cybersecurity Operations Center points in structuring a CSOC and shows how to: • Find the right size and structure for the CSOC team Cybersecurity Operations Center a World-Class of Strategies Ten The MITRE Corporation is • Achieve effective placement within a larger organization that a not-for-profit organization enables CSOC operations that operates federally funded • Attract, retain, and grow the right staff and skills research and development • Prepare the CSOC team, technologies, and processes for agile, centers (FFRDCs). FFRDCs threat-based response are unique organizations that • Architect for large-scale data collection and analysis with a assist the U.S. government with limited budget scientific research and analysis, • Prioritize sensor placement and data feed choices across development and acquisition, enteprise systems, enclaves, networks, and perimeters and systems engineering and integration. We’re proud to have If you manage, work in, or are standing up a CSOC, this book is for you. served the public interest for It is also available on MITRE’s website, www.mitre.org. more than 50 years. -

Measuring and Modeling the Label Dynamics of Online Anti-Malware Engines
Measuring and Modeling the Label Dynamics of Online Anti-Malware Engines Shuofei Zhu1, Jianjun Shi1,2, Limin Yang3 Boqin Qin1,4, Ziyi Zhang1,5, Linhai Song1, Gang Wang3 1The Pennsylvania State University 2Beijing Institute of Technology 3University of Illinois at Urbana-Champaign 4Beijing University of Posts and Telecommunications 5University of Science and Technology of China 1 VirusTotal • The largest online anti-malware scanning service – Applies 70+ anti-malware engines – Provides analysis reports and rich metadata • Widely used by researchers in the security community report API scan API Metadata Submitter Sample Reports 2 Challenges of Using VirusTotal • Q1: When VirusTotal labels are trustworthy? McAfee ✔️ ⚠️ ⚠️ ✔️ ✔️ Day 1 2 3 4 5 6 Time Sample 3 Challenges of Using VirusTotal • Q1: When VirusTotal labels are trustworthy? • Q2: How to aggregate labels from different engines? • Q3: Are different engines equally trustworthy? Engines Results McAfee ⚠️ ⚠️ Microsoft ✔️ ✔️ Kaspersky ✔️ Avast ⚠️ … 3 Challenges of Using VirusTotal • Q1: When VirusTotal labels are trustworthy? • Q2: How to aggregate labels from different engines? • Q3: Are different engines equally trustworthy? Equally trustworthy? 3 Literature Survey on VirusTotal Usages • Surveyed 115 top-tier conference papers that use VirusTotal • Our findings: – Q1: rarely consider label changes – Q2: commonly use threshold-based aggregation methods – Q3: often treat different VirusTotal engines equally Consider Label Changes Threshold-Based Method Reputable Engines Yes Yes No Yes -

ESET THREAT REPORT Q3 2020 | 2 ESET Researchers Reveal That Bugs Similar to Krøøk Affect More Chip Brands Than Previously Thought
THREAT REPORT Q3 2020 WeLiveSecurity.com @ESETresearch ESET GitHub Contents Foreword Welcome to the Q3 2020 issue of the ESET Threat Report! 3 FEATURED STORY As the world braces for a pandemic-ridden winter, COVID-19 appears to be losing steam at least in the cybercrime arena. With coronavirus-related lures played out, crooks seem to 5 NEWS FROM THE LAB have gone “back to basics” in Q3 2020. An area where the effects of the pandemic persist, however, is remote work with its many security challenges. 9 APT GROUP ACTIVITY This is especially true for attacks targeting Remote Desktop Protocol (RDP), which grew throughout all H1. In Q3, RDP attack attempts climbed by a further 37% in terms of unique 13 STATISTICS & TRENDS clients targeted — likely a result of the growing number of poorly secured systems connected to the internet during the pandemic, and possibly other criminals taking inspiration from 14 Top 10 malware detections ransomware gangs in targeting RDP. 15 Downloaders The ransomware scene, closely tracked by ESET specialists, saw a first this quarter — an attack investigated as a homicide after the death of a patient at a ransomware-struck 17 Banking malware hospital. Another surprising twist was the revival of cryptominers, which had been declining for seven consecutive quarters. There was a lot more happening in Q3: Emotet returning 18 Ransomware to the scene, Android banking malware surging, new waves of emails impersonating major delivery and logistics companies…. 20 Cryptominers This quarter’s research findings were equally as rich, with ESET researchers: uncovering 21 Spyware & backdoors more Wi-Fi chips vulnerable to KrØØk-like bugs, exposing Mac malware bundled with a cryptocurrency trading application, discovering CDRThief targeting Linux VoIP softswitches, 22 Exploits and delving into KryptoCibule, a triple threat in regard to cryptocurrencies. -

Technical Report RHUL–ISG–2021–3 10 March 2021
Testing Antivirus in Linux: An Investigation on the Effectiveness of Solutions Available for Desktop Computers Giuseppe Raffa Technical Report RHUL–ISG–2021–3 10 March 2021 Information Security Group Royal Holloway University of London Egham, Surrey, TW20 0EX United Kingdom Student Number: 100907703 Giuseppe Raffa Testing Antivirus in Linux: An Investigation on the Effectiveness of Solutions Available for Desktop Computers Supervisor: Daniele Sgandurra Submitted as part of the requirements for the award of the MSc in Information Security at Royal Holloway, University of London. I declare that this assignment is all my own work and that I have acknowledged all quotations from published or unpublished work of other people. I also declare that I have read the statements on plagiarism in Section 1 of the Regulations Governing Examination and Assessment Offences, and in accordance with these regulations I submit this project report as my own work. Signature: Giuseppe Raffa Date: 24th August 2020 Table of Contents 1 Introduction.....................................................................................................................7 1.1 Motivation.......................................................................................................................................7 1.2 Objectives........................................................................................................................................8 1.3 Methodology...................................................................................................................................8 -

The Adventures of Av and the Leaky Sandbox
THE ADVENTURES OF AV AND THE LEAKY SANDBOX A SafeBreach Labs research paper by Amit Klein, VP Security Research, SafeBreach and Itzik Kotler, co-founder and CTO, SafeBreach July 2017 1 ABSTRACT We describe and demonstrate a novel technique for exfiltrating data from highly secure enterprises which employ strict egress filtering - that is, endpoints have no direct Internet connection, or the endpoints’ connection to the Internet is restricted to hosts required by their legitimately installed software. Assuming the endpoint has a cloud-enhanced anti-virus product installed, we show that if the anti-virus (AV) product employs an Internet-connected sandbox as part of its cloud service, it actually facilitates such exfiltration. We release the tool we developed to implement the exfiltration technique, and we provide real-world results from several prominent AV products (by Avira, ESET, Kaspersky and Comodo). Our technique revolves around exfiltrating the data inside an executable file which is created on the endpoint (by the main malware process), detected by the AV agent, uploaded to the cloud for further inspection, and executed in an Internet connected sandbox. We also provide data and insights on those AV in-the-cloud sandboxes. We generalize our findings to cover on-premise sandboxes, use of cloud-based/online scanning and malware categorization services, and sample sharing at large. Lastly, we address the issues of how to further enhance the attack, and how cloud-based AV vendors can mitigate it. INTRODUCTION Exfiltration of sensitive data from a well-protected enterprise is a major goal for cyber attackers. Network-wise, our reference scenario is an enterprise whose endpoints are not allowed direct communication with the Internet, or an enterprise whose endpoints are only allowed Internet connections to a closed set of external hosts (such as Microsoft update servers, AV update servers, etc.). -

Comodo Valkyrie
Hi rat Comodo Valkyrie Software Version 1.42 User Guide Guide Version 1.42.010620 Comodo Security Solutions 1255 Broad Street Clifton, NJ 07013 Comodo Valkyrie User Guide Table of Contents 1 Introduction to Comodo Valkyrie............................................................................................................................3 2 Create a Valkyrie Account........................................................................................................................................5 2.1 Log into Valkyrie..............................................................................................................................................8 3 Upload Files for Analysis ......................................................................................................................................11 4 Valkyrie Analysis Results.......................................................................................................................................13 4.1 Valkyrie Dashboard........................................................................................................................................16 4.2 Recent Analysis Requests............................................................................................................................23 4.3 Kill Chain Report............................................................................................................................................35 4.4 My Analysis Statistics...................................................................................................................................43 -

Does Anti-Virus Software Do All That It Promises?
Does Anti-Virus Software Do All That It Promises? Probably Not. An Analysis of Antivirus Software Christina King Tufts University COMP 116 | Prof. Ming Chow December 13, 2019 Abstract A virus is a type of malware, but ‘anti-virus software’ is a misnomer because these systems now claim to protect against many types of malware. Most security professionals recommend using some software of this kind, but does it actually protect users from all types of malware? Is it better than nothing at all? Some experts claim that it can actually make your computer less safe. As we explore these topics in this paper, I will discuss signature- and heuristic-based anti-virus software, how well each works, and what else you can do to ensure security of your data. Thesis Anti-virus software is all but useless, and people cannot depend on it to protect their devices and data. Although, the spread of this information could make people feel less safe, the public deserves to know that their security is at risk. The only way anything will change is if it is common knowledge that there is a problem here. To the Community The effectivity and value of antivirus is a topic that I am very curious about. Why do people use this software and how well does it really work? Personally, I have never used an antivirus software to protect my computer from malware, and I used to embarrassed by this. It felt like I was leaving my computer unprotected by judging whether links and downloads were safe myself, but I never made the time to download or research this software until now. -

Towards Building Active Defense for Software Applications Zara Perumal
Towards Building Active Defense for Software Applications by Zara Perumal Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Masters of Engineering in Electrical Engineering and Computer Science at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY January 2018 c Massachusetts Institute of Technology 2018. All rights reserved. Author.............................................................. Department of Electrical Engineering and Computer Science January 19, 2018 Certified by. Kalyan Veeramchaneni Principle Research Scientist Thesis Supervisor Accepted by . Christopher Terman Chairman, Masters of Engineering Thesis Committee 2 Towards Building Active Defense for Software Applications by Zara Perumal Submitted to the Department of Electrical Engineering and Computer Science on January 19, 2018, in partial fulfillment of the requirements for the degree of Masters of Engineering in Electrical Engineering and Computer Science Abstract Over the last few years, cyber attacks have become increasingly sophisticated. In an effort to defend themselves, corporations often look to machine learning, aiming to use the large amount of data collected on cyber attacks and software systems to defend systems at scale. Within the field of machine learning in cybersecurity, PDF malware is a popular target of study, as the difficulty of classifying malicious files makes it a continuously effective method of attack. The obstacles are many: Datasets change over time as attackers change their behavior, and the deployment of a malware detection system in a resource-constrained environment has minimum throughput requirements, meaning that an accurate but time-consuming classifier cannot be deployed. Recent work has also shown how automated malicious file cre- ation methods are being used to evade classification.