Towards Building Active Defense for Software Applications Zara Perumal
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

VYSOKÁ ŠKOLA POLYTECHNICKÁ JIHLAVA Katedra Technických Studií
VYSOKÁ ŠKOLA POLYTECHNICKÁ JIHLAVA Katedra technických studií Návrh bezpečnostní politiky filtrování webového provozu ve školním prostředí bakalářská práce Autor práce: Radek Kudrna Vedoucí práce: Mgr. Antonín Přibyl Jihlava 2020 ZADÁNÍ BAKALÁŘSKÉ PRÁCE Autor práce: Radek Kudrna Studijní program: Elektrotechnika a informatika Obor: Aplikovaná informatika Název práce: Návrh bezpečnostní politiky filtrování webového provozu ve školním prostředí Cíl práce: V teoretické části diskutujte návrh bezpečného přístupu k Internetu pro žáky škol včetně návrhu monitoringu přístupů, na druhou stranu je potřeba zvážit politiku nefiltrovaného přístupu k Internetu. Diskutujte právní fakt nemožnosti delegace právní odpovědnosti na nezletilé žáky, která souvisí s provozem školních (bezdrátových) sítí. V praktické části bude provedeno nasazení Kerio Control s Active Directory pro filtrování provozu na MŠ a ZŠ Brtnice. Mgr. Antonín Přibyl doc. Ing. Zdeněk Horák, Ph.D. vedoucí bakalářské práce vedoucí katedry Katedra technických studií Abstrakt Tato bakalářská práce se zabývá problémem přístupu k internetu pro školy, zejména pro základní školy. Při nefiltrovaném obsahu jsou nezletilí žáci vystaveni určitým rizikům. Jedná se především o přístup na stránky se závadným obsahem, možností stát se kybernetickou obětí, nebo k samotné možnosti páchání trestné činnosti přes školní internet. Pro zamezení těchto činností je nutnost zavést určitou bezpečnostní politiku v podobě filtrování webových stránek. Právě jednotlivé možnosti blokování stránek jsou v práci popsány. Součástí je i ukázka a popis řešení v nástroji Kerio Control, který je nasazen na filtrování provozu na základní a mateřské škole Brtnice. Klíčová slova filtrování provozu; Kerio Control; monitoring; nezletilí žáci; webový filtr Abstract This bachelor thesis deals with the problem of Internet access for schools, especially for primary schools. -

Comodo Internet Security Essentials User Guide | © 2018 Comodo Security Solutions Inc
Comodo Internet Security Essentials Software Version 1.3 User Guide Guide Version 1.3.120318 Comodo Security Solutions 1255 Broad Street Clifton, NJ, 07013 United States Comodo Internet Security Essentials- User Guide Table of Contents Comodo Internet Security Essentials.......................................................................................................................................... 3 What is Comodo Internet Security Essentials?.......................................................................................................................... 3 How do I install Comodo Internet Security Essentials?.............................................................................................................4 What is a man-in-the-middle attack?......................................................................................................................................... 6 How does Comodo Internet Security Essentials protect me from a man-in-the-middle attack?................................................7 What is the install location of Comodo Internet Security Essentials?........................................................................................8 How do I update CISE?............................................................................................................................................................. 8 Understanding alerts and configuring exceptions....................................................................................................................14 -

360 Antivirus for Pc Free Download Full Version
360 Antivirus For Pc Free Download Full Version 360 Antivirus For Pc Free Download Full Version 1 / 3 2 / 3 Windows Defender is improving, but you still shouldn't rely on Windows 10's security ... Kaspersky Security Cloud Free offers full-scale malware protection and even some ... Bitdefender Antivirus Free Edition includes the same core antivirus ... The free Qihoo 360 Total Security 8.6 comes with a ton of bonus tools, but its core .... Integrating award winning antivirus systems including 360 QVMII, 360 Cloud Engine, Avira or BitDefender to offer you with the ultimate in virus detection and .... 360 Total Security Download Free Antivirus Cloud-based technology this software can detect most of the new virus ... Total Security Download Full Version ... This software is a complete security package for your PC, laptop or mobile device.. Download 360 Total Security 10.6.0.1223. Keep your PC safe with five antivirus engines. Protecting your PC is a day-to-day essential, as it's becoming ever .... 360 Total Security is an unified solution for your PC security and performance. ... 360 Total Security - Free Antivirus & Internet Security Software for PC 8.0.0.1046 ... With Full Check, you can examine the overall condition of your computer within ... Starting from version 9, users of 360 Total Security are able to upgrade to .... Download 360 Total Security Premium 10.6.0.1223 for Windows. Fast downloads of the latest free software! ... QIHU 360(Full Version) ... edge antivirus protection, which is powered by 360 Heuristic Engine, 360 Cloud Engine .... Download 360 Total Security 2020 offline installers for free and safe for your Windows PC. -

Comodo Internet Security Quick Start Guide | © 2020 Comodo Security Solutions Inc
Comodo Internet Security Software Version 12.2 Quick Start Guide Guide Version 12.2.050520 Comodo Security Solutions 1255 Broad Street Clifton, NJ, 07013 United States Comodo Internet Security - Quick Start Guide Comodo Internet Security - Quick Start Guide This tutorial explains how to use Comodo Internet Security (CIS). Please use the following links to go straight to the section that you need help with: • Installation • The main interface • Scan and clean your computer • Run an instant antivirus scan on selected items • Set up the Firewall for maximum security and usability • Set up HIPS for maximum security and usability • Run untrusted programs in the container • Browse the internet and run untrusted programs inside the Virtual Desktop • Renew or upgrade licenses • More Help Installation • If you haven't done so already, please download the CIS setup file from https://www.comodo.com/home/internet-security/security-software.php • Before beginning installation, please ensure you have uninstalled any other antivirus and firewall products that are on your computer. More specifically, remove any other products of the same type as those Comodo products you plan to install. • Double click the CIS setup file to start the installation wizard. • Click 'Options' if you wish to configure advanced options. • After finishing the wizard, CIS runs an initial scan • You will be asked to choose your type of internet connection • On completion of scanning, the scan results are shown. You can choose the action to be taken on the threats found, if any. • You need to reboot your computer to complete installation. A more detailed description of the options available during installation can be found in the installation guide at https://help.comodo.com/topic-72-1-772-9552-CIS-Installation.html The Main Interface The CIS interface is designed to be as clean and informative as possible while letting you carry out tasks with the minimum of fuss. -

Testing Anti-Virus in Linux: How Effective Are the Solutions Available for Desktop Computers?
Royal Holloway University of London ISG MSc Information Security thesis series 2021 Testing anti-virus in Linux: How effective are the solutions available for desktop computers? Authors Giuseppe Raffa, MSc (Royal Holloway, 2020) Daniele Sgandurra, Huawei, Munich Research Center. (Formerly ISG, Royal Holloway.) Abstract Anti-virus (AV) programs are widely recognized as one of the most important defensive tools available for desktop computers. Regardless of this, several Linux users consider AVs unnec- essary, arguing that this operating system (OS) is “malware-free”. While Windows platforms are undoubtedly more affected by malicious software, there exist documented cases of Linux- specific malware. In addition, even though the estimated market share of Linux desktop sys- tems is currently only at 2%, it is certainly possible that it will increase in the near future. Considering all this, and the lack of up-to-date information about Linux-compatible AV solutions, we evaluated the effectiveness of some anti-virus products by using local installations, a well- known on-line malware scanning service (VirusTotal) and a renowned penetration testing tool (Metasploit). Interestingly, in our tests, the average detection rate of the locally-installed AV programs was always above 80%. However, when we extended our analysis to the wider set of anti-virus solutions available on VirusTotal, we found out that the average detection rate barely reached 60%. Finally, when evaluating malicious files created with Metasploit, we verified that the AVs’ heuristic detection mechanisms performed very poorly, with detection rates as low as 8.3%.a aThis article is published online by Computer Weekly as part of the 2021 Royal Holloway informa- tion security thesis series https://www.computerweekly.com/ehandbook/Royal-Holloway-Testing-antivirus- efficacy-in-Linux. -

Forescout Counteract® Endpoint Support Compatibility Matrix Updated: October 2018
ForeScout CounterACT® Endpoint Support Compatibility Matrix Updated: October 2018 ForeScout CounterACT Endpoint Support Compatibility Matrix 2 Table of Contents About Endpoint Support Compatibility ......................................................... 3 Operating Systems ....................................................................................... 3 Microsoft Windows (32 & 64 BIT Versions) ...................................................... 3 MAC OS X / MACOS ...................................................................................... 5 Linux .......................................................................................................... 6 Web Browsers .............................................................................................. 8 Microsoft Windows Applications ...................................................................... 9 Antivirus ................................................................................................. 9 Peer-to-Peer .......................................................................................... 25 Instant Messaging .................................................................................. 31 Anti-Spyware ......................................................................................... 34 Personal Firewall .................................................................................... 36 Hard Drive Encryption ............................................................................. 38 Cloud Sync ........................................................................................... -

CODASPY'17 ~ Decompression Quines and Anti-Viruses
Decompression Quines and Anti-Viruses Margaux Canet Amrit Kumar Cédric Lauradoux Inria Inria Inria Univ. Grenoble Alpes Univ. Grenoble Alpes Mary-Andréa Reihaneh Safavi-Naini Rakotomanga University of Calgary Inria Univ. Grenoble Alpes ABSTRACT compression bombs also known as the zip of death exploit Data compression is ubiquitous to any information and com- the efficiency of compression algorithms to mount denial- munication system. It often reduces resources required to of-service (DoS) attacks. They often target web servers store and transmit data. However, the efficiency of com- and anti-viruses. Unfortunately, despite the fact that these pression algorithms also makes them an obvious target for threats have been known for years, some security products hackers to mount denial-of-service attacks. In this work, still remain vulnerable [9, 13]. we consider decompression quines, a specific class of com- The common definition of a decompression bomb found in pressed files that decompress to themselves. We analyze all the NIST guide [10] or the textbook [11] considers a small innocuous compressed file that decompresses to a gigantic the known decompression quines by studying their struc- 1 tures, and their impact on anti-viruses. Our analysis reveals file. A typical example of a decompression bomb is 42.zip that most of the anti-viruses do not have a suitable architec- (≈ 42 Kilobytes) that expands to 4.5 Petabytes. When a ture in place to detect decompression quines. Even worse, software attempts to naively decompress such a file, it con- some of them are vulnerable to denial-of-service attacks ex- sumes all the available memory and eventually crashes. -

A Large-Scale Empirical Study on Industrial Fake Apps
A Large-Scale Empirical Study on Industrial Fake Apps Chongbin Tang∗, Sen Chen∗, Lingling Fan∗, Lihua Xuy, Yang Liuz, Zhushou Tangx, Liang Dou∗ ∗East China Normal University, China yNew York University Shanghai, China zNanyang Technological University, Singapore xPwnzen Infotech Inc., China Abstract—While there have been various studies towards of app searching and downloading is greatly affected by the Android apps and their development, there is limited discussion fake apps in real world. of the broader class of apps that fall in the fake area. Fake Even worse, as the doorsill to develop an app has been set apps and their development are distinct from official apps and belong to the mobile underground industry. Due to the lack of low, the cost to develop a fake app is much lower than what it knowledge of the mobile underground industry, fake apps, their takes to develop a desktop program, providing an ideal hotbed ecosystem and nature still remain in mystery. for the underground industry to thrive on [3]. Moreover, the To fill the blank, we conduct the first systematic and com- flexibility of Android app implementation [4] contributes the prehensive empirical study on a large-scale set of fake apps. fake apps’ complexity. Over 150,000 samples related to the top 50 popular apps are collected for extensive measurement. In this paper, we present Despite the ubiquity, little is known about fake apps and discoveries from three different perspectives, namely fake sample their ecosystem – their common characteristics, the number characteristics, quantitative study on fake samples and fake au- of fake apps at large, their production process and speed, thors’ developing trend. -

Hostscan 4.8.01064 Antimalware and Firewall Support Charts
HostScan 4.8.01064 Antimalware and Firewall Support Charts 10/1/19 © 2019 Cisco and/or its affiliates. All rights reserved. This document is Cisco public. Page 1 of 76 Contents HostScan Version 4.8.01064 Antimalware and Firewall Support Charts ............................................................................... 3 Antimalware and Firewall Attributes Supported by HostScan .................................................................................................. 3 OPSWAT Version Information ................................................................................................................................................. 5 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.890.0 for Windows .................................................. 5 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.890.0 for Windows ........................................................ 44 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.824.0 for macos .................................................... 65 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.824.0 for macOS ........................................................... 71 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.730.0 for Linux ...................................................... 73 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.730.0 for Linux .............................................................. 76 ©201 9 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. -

Page 1 of 3 Virustotal
VirusTotal - Free Online Virus, Malware and URL Scanner Page 1 of 3 VT Community Sign in ▼ Languages ▼ Virustotal is a service that analyzes suspicious files and URLs and facilitates the quick detection of viruses, worms, trojans, and all kinds of malware detected by antivirus engines. More information... 0 VT Community user(s) with a total of 0 reputation credit(s) say(s) this sample is goodware. 0 VT Community VT Community user(s) with a total of 0 reputation credit(s) say(s) this sample is malware. File name: wsusoffline71.zip Submission date: 2011-11-01 08:16:44 (UTC) Current status: finished not reviewed Result: 0 /40 (0.0%) Safety score: - Compact Print results Antivirus Version Last Update Result AhnLab-V3 2011.10.31.00 2011.10.31 - AntiVir 7.11.16.225 2011.10.31 - Antiy-AVL 2.0.3.7 2011.11.01 - Avast 6.0.1289.0 2011.11.01 - AVG 10.0.0.1190 2011.11.01 - BitDefender 7.2 2011.11.01 - CAT-QuickHeal 11.00 2011.11.01 - ClamAV 0.97.3.0 2011.11.01 - Commtouch 5.3.2.6 2011.11.01 - Comodo 10625 2011.11.01 - Emsisoft 5.1.0.11 2011.11.01 - eSafe 7.0.17.0 2011.10.30 - eTrust-Vet 36.1.8650 2011.11.01 - F-Prot 4.6.5.141 2011.11.01 - F-Secure 9.0.16440.0 2011.11.01 - Fortinet 4.3.370.0 2011.11.01 - GData 22 2011.11.01 - Ikarus T3.1.1.107.0 2011.11.01 - Jiangmin 13.0.900 2011.10.31 - K7AntiVirus 9.116.5364 2011.10.31 - Kaspersky 9.0.0.837 2011.11.01 - McAfee 5.400.0.1158 2011.11.01 - McAfee-GW-Edition 2010.1D 2011.10.31 - Microsoft 1.7801 2011.11.01 - NOD32 6591 2011.11.01 - Norman 6.07.13 2011.10.31 - nProtect 2011-10-31.01 2011.10.31 - http://www.virustotal.com/file -scan/report.html?id=874d6968eaf6eeade19179712d53 .. -
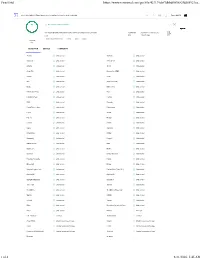
Virustotal Scan on 2020.08.21 for Pbidesktopsetup 2
VirusTotal https://www.virustotal.com/gui/file/423139def3dbbdf0f5682fdd88921ea... 423139def3dbbdf0f5682fdd88921eaface84ff48ef2e2a8d20e4341ca4a4364 Patch My PC No engines detected this file 423139def3dbbdf0f5682fdd88921eaface84ff48ef2e2a8d20e4341ca4a4364 269.49 MB 2020-08-21 11:39:09 UTC setup Size 1 minute ago invalid-rich-pe-linker-version overlay peexe signed Community Score DETECTION DETAILS COMMUNITY Acronis Undetected Ad-Aware Undetected AegisLab Undetected AhnLab-V3 Undetected Alibaba Undetected ALYac Undetected Antiy-AVL Undetected SecureAge APEX Undetected Arcabit Undetected Avast Undetected AVG Undetected Avira (no cloud) Undetected Baidu Undetected BitDefender Undetected BitDefenderTheta Undetected Bkav Undetected CAT-QuickHeal Undetected ClamAV Undetected CMC Undetected Comodo Undetected CrowdStrike Falcon Undetected Cybereason Undetected Cyren Undetected eScan Undetected F-Secure Undetected FireEye Undetected Fortinet Undetected GData Undetected Ikarus Undetected Jiangmin Undetected K7AntiVirus Undetected K7GW Undetected Kaspersky Undetected Kingsoft Undetected Malwarebytes Undetected MAX Undetected MaxSecure Undetected McAfee Undetected Microsoft Undetected NANO-Antivirus Undetected Palo Alto Networks Undetected Panda Undetected Qihoo-360 Undetected Rising Undetected Sangfor Engine Zero Undetected SentinelOne (Static ML) Undetected Sophos AV Undetected Sophos ML Undetected SUPERAntiSpyware Undetected Symantec Undetected TACHYON Undetected Tencent Undetected TrendMicro Undetected TrendMicro-HouseCall Undetected VBA32 Undetected -

An Analysis of Domain Classification Services
Mis-shapes, Mistakes, Misfits: An Analysis of Domain Classification Services Pelayo Vallina Victor Le Pochat Álvaro Feal IMDEA Networks Institute / imec-DistriNet, KU Leuven IMDEA Networks Institute / Universidad Carlos III de Madrid Universidad Carlos III de Madrid Marius Paraschiv Julien Gamba Tim Burke IMDEA Networks Institute IMDEA Networks Institute / imec-DistriNet, KU Leuven Universidad Carlos III de Madrid Oliver Hohlfeld Juan Tapiador Narseo Vallina-Rodriguez Brandenburg University of Universidad Carlos III de Madrid IMDEA Networks Institute/ICSI Technology ABSTRACT ACM Reference Format: Domain classification services have applications in multiple areas, Pelayo Vallina, Victor Le Pochat, Álvaro Feal, Marius Paraschiv, Julien including cybersecurity, content blocking, and targeted advertising. Gamba, Tim Burke, Oliver Hohlfeld, Juan Tapiador, and Narseo Vallina- Rodriguez. 2020. Mis-shapes, Mistakes, Misfits: An Analysis of Domain Yet, these services are often a black box in terms of their method- Classification Services. In ACM Internet Measurement Conference (IMC ’20), ology to classifying domains, which makes it difficult to assess October 27ś29, 2020, Virtual Event, USA. ACM, New York, NY, USA, 21 pages. their strengths, aptness for specific applications, and limitations. In https://doi.org/10.1145/3419394.3423660 this work, we perform a large-scale analysis of 13 popular domain classification services on more than 4.4M hostnames. Our study empirically explores their methodologies, scalability limitations, 1 INTRODUCTION label constellations, and their suitability to academic research as The need to classify websites became apparent in the early days well as other practical applications such as content filtering. We of the Web. The first generation of domain classification services find that the coverage varies enormously across providers, ranging appeared in the late 1990s in the form of web directories.