Introduction to High-Performance Computing Using Clusters to Speed up Your Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Managing Many Files with Disk Archiver (DAR)
Intro Manual demos Function demos Summary Managing many files with Disk ARchiver (DAR) ALEX RAZOUMOV [email protected] WestGrid webinar - ZIP file with slides and functions http://bit.ly/2GGR9hX 2019-May-01 1 / 16 Intro Manual demos Function demos Summary To ask questions Websteam: email [email protected] Vidyo: use the GROUP CHAT to ask questions Please mute your microphone unless you have a question Feel free to ask questions via audio at any time WestGrid webinar - ZIP file with slides and functions http://bit.ly/2GGR9hX 2019-May-01 2 / 16 Intro Manual demos Function demos Summary Parallel file system limitations Lustre object storage servers (OSS) can get overloaded with lots of small requests I /home, /scratch, /project I Lustre is very different from your laptop’s HDD/SSD I a bad workflow will affect all other users on the system Avoid too many files, lots of small reads/writes I use quota command to see your current usage I maximum 5 × 105 files in /home, 106 in /scratch, 5 × 106 in /project (1) organize your code’s output (2) use TAR or another tool to pack files into archives and then delete the originals WestGrid webinar - ZIP file with slides and functions http://bit.ly/2GGR9hX 2019-May-01 3 / 16 Intro Manual demos Function demos Summary TAR limitations TAR is the most widely used archiving format on UNIX-like systems I first released in 1979 Each TAR archive is a sequence of files I each file inside contains: a header + some padding to reach a multiple of 512 bytes + file content I EOF padding (some zeroed blocks) at the end of the -

Hydraspace: Computational Data Storage for Autonomous Vehicles
HydraSpace: Computational Data Storage for Autonomous Vehicles Ruijun Wang, Liangkai Liu and Weisong Shi Wayne State University fruijun, liangkai, [email protected] Abstract— To ensure the safety and reliability of an The current vehicle data logging system is designed autonomous driving system, multiple sensors have been for capturing a wide range of signals of traditional CAN installed in various positions around the vehicle to elim- bus data, including temperature, brakes, throttle settings, inate any blind point which could bring potential risks. Although the sensor data is quite useful for localization engine, speed, etc. [4]. However, it cannot handle sensor and perception, the high volume of these data becomes a data because both the data type and the amount far burden for on-board computing systems. More importantly, exceed its processing capability. Thus, it is urgent to the situation will worsen with the demand for increased propose efficient data computing and storage methods for precision and reduced response time of self-driving appli- both CAN bus and sensed data to assist the development cations. Therefore, how to manage this massive amount of sensed data has become a big challenge. The existing of self-driving techniques. As it refers to the installed vehicle data logging system cannot handle sensor data sensors, camera and LiDAR are the most commonly because both the data type and the amount far exceed its used because the camera can show a realistic view processing capability. In this paper, we propose a computa- of the surrounding environment while LiDAR is able tional storage system called HydraSpace with multi-layered to measure distances with laser lights quickly [5], [6]. -

Backing up Linux - Ii
BACKING UP LINUX - II 1 Software recommendations, disrecommendations and examples This chapter describes some details and examples of a number or programs. Please note that there are far more backup programs in existence than the ones I mention here. The reason I mention these, is because these are the ones I have a lot experience with, and it shows how to apply or consider the concepts described above, in practice. Sometimes as specifically refer to the GNU version of an application, the standard version on Linux installations, which can be fundamentally different than the classic version, so keep that in mind. 1.1. Dar First a word of caution. It's highly recommended that you use version 2.3.3 (most recent stable release at the time of writing) or newer because it contains a major bugfix. Read the announcement on Dar's news list for more info. Dar is very well thought through and has solutions for classic pitfalls. For example, it comes with a statically compiled binary which you can copy on (the first disk of) your backup. It supports automatic archive slicing, and has an option to set the size of the first slice separately, so you have some space on the first disk left for making a boot CD, for example. It also lets you run a command between each slice, so you can burn it on CD, or calculate parity information on it, etc. And, very importantly, its default options are well chosen. Well, that is, except for the preservation of atimes (see atime-preserveration above). -

TO: Charles F. Bolden, Jr. Administrator December 17,2012 FROM: Paul K. Martin (79- Inspector General SUBJECT: NASA's Efforts To
National Aeronautics and Space Administration Office of Inspector General N~~, J. Washington, DC 20546-0001 December 17,2012 TO: Charles F. Bolden, Jr. Administrator FROM: Paul K. Martin (79- Inspector General SUBJECT: NASA's Efforts to Encrypt its Laptop Computers On October 31, 2012, a NASA-issued laptop was stolen from the vehicle ofa NASA Headquarters employee. The laptop contained hundreds of files and e-mails with the Social Security numbers and other forms of personally identifiable information (PH) for more than 10,000 current and former NASA employees and contractors. Although the laptop was password protected, neither the laptop itself nor the individual files were encrypted. l As a result of this loss, NASA contracted with a company to provide credit monitoring services to the affected individuals. NASA estimates that these services will cost between $500,000 and $700,000. This was not the first time NASA experienced a significant loss of PH or other sensitive but unclassified (SBU) data as a result of the theft of an unencrypted Agency laptop. For example, in March 2012 a bag containing a government-issued laptop, NASA access badge, and a token used to enable remote-access to a NASA network was stolen from a car parked in the driveway of a Kennedy Space Center employee. A review by information technology (IT) security officials revealed that the stolen computer contained the names, Social Security numbers, and other PH information for 2,400 NASA civil servants, as well as two files containing sensitive information related to a NASA program. As a result of the theft, NASA incurred credit monitoring expenses of approximately $200,000. -

Proceedings of the 17 Large Installation Systems Administration
USENIX Association Proceedings of the 17th Large Installation Systems Administration Conference San Diego, CA, USA October 26–31, 2003 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION © 2003 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Further Torture: More Testing of Backup and Archive Programs Elizabeth D. Zwicky ABSTRACT Every system administrator depends on some set of programs for making secondary copies of data, as backups for disaster recovery or as archives for long term storage. These programs, like all other programs, have bugs. The important thing for system administrators to know is where those bugs are. Some years ago I did testing on backup and archive programs, and found that failures were extremely common and that the documented limitations of programs did not match their actual limitations. Curious to see how the situation had changed, I put together a new set of tests, and found that programs had improved significantly, but that undocumented failures were still common. In the previous tests, almost every program crashed outright at some point, and dump significantly out-performed all other contenders. In addition, many programs other than the backup and archive programs failed catastrophically (most notably fsck on many platforms, and the kernel on one platform). -

New Media and Arts Education Using Email to Conduct a Survey
Higher Learning - Technology Serving Education New Media and Arts Education Using Email to Conduct a Survey The Challenge of Distance Education Sept/Oct. 2002 contentsCONTENTS FEATURES Book Review . 18 Courses and Programs . 8 Steal These Ideas Please! Great Marketing • MIT’s Java Revolution Reaches Eight New Media and Arts Education . 19 Ideas for Continuing Education Sub-Saharan Countries What can new media tell us about Edited by Susan Goewey Carey • UBC’s New Master of Educational Technology how we teach the arts? • UCCB Joins With Intel Canada By Ana Serrano DEPARTMENTS • UMass Announces New Information Technology Minor The Challenge of Distance Education . 23 Higher Notes . 3 • UMUC Designs Courses in Network Security Problems that distance educators and their students •A letter from the editor • UNC-CH Will Offer North Carolina’s First face, and possible solutions for both. Information Science Degree By Cable Starlings News . 5 •A Digital Repository for Faculty Research Technology Supplement . 24 SPOTLIGHT • Blackboard’s Multi-Language Edition Caters • Books to Staff and Students Around the World • Software Adobe Looks to the Library . 10 • Cornell Plans to Digitize Entire Library •Web Adobe gives libraries new options for managing Card Catalog System their digital collections with Content Server 3. • Department of Computer Science Projects . 27 HIGHER LEARNING -Contents By Jennifer Kavur Becomes a School • Electronic Publishing and Online Databases • Free Recruiting System for Co-ops Across Canada •McGraw-Hill-Microsoft Press Using Email to Conduct a Survey . 11 contents How UC Davis and Simon Fraser University •New Documentary Explores How Digital use email to conduct their research. Media Affects Learning By Jennifer Kavur • University of San Francisco Launches Digital Campus REVIEWS Summer Software Review (Part 2) . -

Sistema De Entradas BFA Vía Servicio
Características técnicas para llamada a Servicio de entradas (v. 1.0.0) Versiones: Fecha Autor Versión Comentario respecto a cambio producido 05/05/20 Lantik S.A.M.P. 1.0.0 Versión inicial Servicio_Entradas_descripcion_tecnica_LLAMADA_V_1_0.DOCX 07/05/2020 2/13 ÍNDICE 1 INTRODUCCIÓN ....................................................................................................... 4 1.1 Objeto del documento ................................................................................................. 4 1.2 Referencias ..................................................................................................................... 4 1.3 Actores involucrados .................................................................................................... 5 1.4 Periodo de validez ......................................................................................................... 5 2 DEFINICIÓN DE LA LLAMADA AL SERVICIO DE ENTRADAS ...................... 6 2.1 Introducción ................................................................................................................... 6 2.2 URL del servicio de entradas ....................................................................................... 6 2.3 Tipo de método de llamada admitida ........................................................................ 6 2.4 Llamada con certificado digital ................................................................................... 6 2.5 Definición cabecera HTTP de llamada al servicio entradas ................................. -

Actualización Del Software Del Televisor
2 Haga clic en [PC] . ACTUALIZACIÓN 3 Haga clic con el botón derecho del ratón en el icono de unidad fl ash USB y, DEL SOFTWARE seguidamente, haga clic en [Formatear…] . DEL TELEVISOR » Aparece una ventana [Formatear] . 4 Haga clic en el cuadro [Sistema de archivos] y después en [FAT32] . Philips mejora constantemente sus 5 Haga clic en [Iniciar] y después en productos. Para asegurarse de que el [Aceptar] para confi rmar el formato. televisor está actualizado con los arreglos y características más recientes, le recomendamos encarecidamente que actualice el televisor Dar formato a la unidad fl ash USB en con el software más reciente. Puede conseguir Macintosh OS X® actualizaciones de software a través de su distribuidor o en www.philips.com/support . 1 Inserte la unidad fl ash USB en un puerto USB de su ordenador. 2 Abra el programa [Utilidad de discos] en [Aplicaciones] > [Utilidades] . Qué necesita 3 Seleccione la unidad fl ash USB en la lista Antes de actualizar el software del televisor, de unidades conectadas al ordenador. compruebe que dispone de lo siguiente: 4 En [Formato de volumen] , haga clic en • Una unidad fl ash USB vacía con al menos [MS-DOS (FAT)] . 256 MB de espacio libre. La unidad fl ash 5 Haga clic en [Borrar] y, después, otra vez USB debe estar formateada en FAT o en [Borrar] para confi rmar el formato. MS-DOS y tener desactivada la protección contra escritura. No utilice una unidad de disco duro USB para actualizar el software. • Un ordenador con acceso a Internet. PASO 1: COMPROBAR • Un programa informático de archivo LA VERSIÓN ACTUAL compatible con el formato "ZIP" (por DEL SOFTWARE DE SU ejemplo, WinZip® para Microsoft® TELEVISOR Windows® o StuffIt® para Macintosh®). -

FHWS SCIENCE JOURNAL Jahrgang 1 (2013) - Ausgabe 2
FHWS SCIENCE JOURNAL Jahrgang 1 (2013) - Ausgabe 2 Data Compacti on and Compression Frank Ebner Analysis of Web Data Compression and its Impact on Traffi c Volker Schneider and Energy Consumpti on Electromobility and Energy Engineering Ansgar Ackva Umrichter in Hybridstruktur als Entwicklungswerkzeug und Bernd Dreßel Prüfsystem für elektrische Antriebe Julian Endres Rene Illek Kombinati on von Produkteentwicklung, Kunststofft echnik Stefan Kellner und Tribologie für neue Werkstoffk onzepte Karsten Faust in fördertechnischen Anwendungen Andreas Krämer Modellierung und Simulati on von nichtlinearen Reibungs- Joachim Kempkes eff ekten bei der Lageregelung von Servomotoren Fabian Schober Oil Conducti vity - An Important Quanti ty for the Design and Andreas Küchler the Conditi on Assessment of HVDC Insulati on Systems Christoph Krause Sebasti an Sturm Ermitt lung der Widerstandsverluste in einem Johannes Paulus Energieseekabel mitt els FEM Joachim Kempkes Christoph Wolz Nichtlineare Berechnung von permanentmagneterregten Joachim Kempkes Gleichstrom-motoren mit konzentrierten Wicklungen Ansgar Ackva Uwe Schäfer Interacti on Design SCIENCE JOURNAL JOURNAL SCIENCE 2 AUSGABE - (2013) 1 JAHRGANG Fabian Weyerstall Vergleich der Multi touch-Steuerung mit Melanie Saul berührungslosen Gesten scj.fhws.de www.fh ws.de Herausgeber Prof. Dr. Robert Grebner Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt Herausgeberassistenz und Ansprechpartner Prof. Dr. Karsten Huffstadt Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt [email protected] Gutachter Prof. Dr.-‐Ing. Abid Ali Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt Prof. Dr. Jürgen Hartmann Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt Prof. Dr. Isabel John Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt Prof. Dr.-‐Ing. Joachim Kempkes Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt Prof. Dr.-‐Ing. Andreas Küchler Hochschule für angewandte Wissenschaften Würzburg-‐Schweinfurt Prof. -
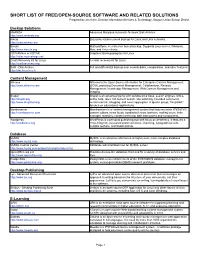
SHORT LIST of FREE/OPEN-SOURCE SOFTWARE and RELATED SOLUTIONS Prepared by Jim Klein, Director Information Services & Technology, Saugus Union School District
SHORT LIST OF FREE/OPEN-SOURCE SOFTWARE AND RELATED SOLUTIONS Prepared by Jim Klein, Director Information Services & Technology, Saugus Union School District Backup Solutions AMANDA Advanced Maryland Automatic Network Disk Archiver http://www.amanda.org Arkeia Enterprise-class network backup for Linux and Unix networks. http://www.arkeia.com Bacula Multi-platform, client/server based backup. Supports Linux server, Windows, http://www.bacula.org Mac, and Linux clients. CDTARchive or CDTAR Graphical Backup program for Linux http://cdtar.sourceforge.net Crash Recovery Kit for Linux A crash recovery kit for Linux http://crashrecovery.org DAR - Disk Archive Full and differential backup over several disks, compression, and other features http://dar.linux.free.fr Content Management Alfresco Alfresco is the Open Source Alternative for Enterprise Content Management http://www.alfresco.com (ECM), providing Document Management, Collaboration, Records Management, Knowledge Management, Web Content Management and Imaging. Drupal Drupal is an advanced portal with collaborative book, search engines, URLs, http://drupal.org online help, roles, full content search, site watching, threaded comments, http://www.drupaled.org version control, blogging, and news aggregator. A special group, “Drupaled,” focuses on educational applications. Mamboserver Mamboserver is a content management system that features inline WYSIWYG http://mamboserver.com content editors, news feeds, syndicated news, banners, mailing users, links manager, statistics, content archiving, date bamodules and components. Wordpress WordPress is a personal publishing tool with focus on aesthetics. It features a http://wordpress.org cross-blog tool, password protected posts, importing, typographical aids, multiple authors, and bookmarklets. Database MySQL MySQL is an attractive alternative to higher-cost, more complex database http://www.mysql.com technology. -

NASA Technical Reports Server
1989017910 "r PB89-159701 AtmospheRelevantric to PropaOpticgaationl CommunIssicautioes ns _ i (U.S.) National Oceanic and Atmospheric _i Administration, Boulder, CO i Jan 89 I ........................_i989017910-002 _U89-159701 _£_T OF"Cl NOAA Technical Memorandum ERL _TL-159 * 1_[ * %,o--=_ / ATHOSPHERIC PROPAGATION ISSUES RELEVANT TO OPTICAL COI_IUNICATIONS James H. Churnside Kamran Shatk Wave Propagation Laboratory Boulder, Colorado January 1989 noaa-----ATMOIM_IRIC ADMINISTRATION I'-La-borMori"-_" REPROOUCEDBY U,$, DEPARTMENT OF COMMERCE NATIONALTECHNICALINFORMATIONSERVICE SPRiNGFiELD,VA.22161 I IIIII .... _ '.............. 1989017910-003 BIBLIOGRAPHIC INFORMATION PB89-159701 Report Nos: NOAA-TR-ERL-WPL-159 Title: Atmospheric Propagation Issues Relevant to Optical Communications. Date: Jan 89 Authors: J. H. Churnside, and K. Shalk. : Performing Organization: National Oceanic and Atmospheric Administration, Boulder, CO. Wave Propagation Lab.**Jet Propulsion Lab., Pasadena, CA. Type of Report and Period Covered: Technical memo., L gupp!emenrary Notes: Prepared in cooperation with Jet Propulsion Lab., Pasadena, CA. NTIS Field/Group Codes: 45C, 84B Price: PC A04/HF A01 Availability: Available from the National Technical Information Service, Springfield, VA. 22161 Number of Pages: 57p Keywords: *Spacecraft communication, *Atmospheric scattering, *Optical communication, Light transmission, Detection, Atmospheric refraction, Turbulence, i Lasers, Attenuation, Fog, Haze, Wavelength, Molecular spectra, Adsorption, Irradiance, Space flight, Mathematical models, Particulates. Abstract: Atmospheric propagation issues relevant to space-to-ground optical ! communications for near-earth applications are studied. Propagation effects, current optical communication activities, potential applications, and communication techniques are surveyed. It is concluded that a direct-detection space-to-ground llnk using redundant receiver sites and temporal encoding is likely to be employed to transmit earth-senslng satel.ite data to the ground some time in the future. -

Efficient Lidar Data Compression for Embedded V2I Or V2V Data Handling
Efficient LiDAR data compression for embedded V2I or V2V data handling Paul CAILLET1 and Yohan DUPUIS2 Abstract— LiDAR are increasingly being used in intelligent format named LAS for practical exchange of LiDAR data vehicles (IV) or intelligent transportation systems (ITS). Storage without the limitations of vendor-specific binary formats and transmission of data generated by LiDAR sensors are one of [1]. Isenburg presented in 2012 LASzip, a lossless, non- the most challenging aspects of their deployment. In this paper we present a method that can be used to efficiently compress progressive data compressor for the LAS format [2] which LiDAR data in order to facilitate storage and transmission in allow for dynamic decompression of specific parts of the V2V or V2I applications. This method can be used to perform dataset. lossless or lossy compression and is specifically designed for For lossy compression, an intermediate representation of embedded applications with low processing power. This method is also designed to be easily applicable to existing processing the point cloud is often used. Tree-like data structure and chains by keeping the structure of the data stream intact. depth maps are the most commonly used representations. We benchmarked our method using several publicly available Meagher presented in 1982 a way to encode arbitrary 3- datasets and compared it with state-of-the-art LiDAR data D objects with an arbitrary resolution using an octree [3]. compression methods from the literature. et al Index Terms— LiDAR, embedded systems, roadside measure- Hornung . [5] used an octree to develop a probabilis- ment, compression. tic mapping framework, which allow for live mapping of the environment and constant updating of its probabilistic I.