Original Article Integrative Analysis of Somatic Mutations and Differential Expression Profiles in Glioblastoma Based on Aging Acceleration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mutations in DCPS and EDC3 in Autosomal Recessive Intellectual
Human Molecular Genetics, 2015, Vol. 24, No. 11 3172–3180 doi: 10.1093/hmg/ddv069 Advance Access Publication Date: 20 February 2015 Original Article Downloaded from ORIGINAL ARTICLE Mutations in DCPS and EDC3 in autosomal recessive intellectual disability indicate a crucial role for mRNA http://hmg.oxfordjournals.org/ decapping in neurodevelopment Iltaf Ahmed1,2,†, Rebecca Buchert3,†, Mi Zhou5,†, Xinfu Jiao5,†, Kirti Mittal1, Taimoor I. Sheikh1, Ute Scheller3, Nasim Vasli1, Muhammad Arshad Rafiq1, 6 1 7 2 M. Qasim Brohi , Anna Mikhailov , Muhammad Ayaz , Attya Bhatti , at Universitaet Erlangen-Nuernberg, Wirtschafts- und Sozialwissenschaftliche Z on August 15, 2016 Heinrich Sticht4, Tanveer Nasr8,9, Melissa T. Carter10, Steffen Uebe3, André Reis3, Muhammad Ayub7,11, Peter John2, Megerditch Kiledjian5,*, John B. Vincent1,12,13,* and Rami Abou Jamra3,* 1Molecular Neuropsychiatry and Development Lab, Campbell Family Mental Health Research Institute, Centre for Addiction and Mental Health, 250 College Street, Toronto, Ontario, Canada M5T 1R8, 2Atta-ur-Rehman School of Applied Biosciences (ASAB), National University of Sciences and Technology (NUST), Islamabad 44000, Pakistan, 3Institute of Human Genetics and 4Bioinformatics, Institute of Biochemistry, Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen 91054, Germany, 5Department of Cell Biology and Neuroscience, Rutgers University, Piscataway, NJ 08854, USA, 6Sir Cowasji Jehangir Institute of Psychiatry, Hyderabad, Sindh 71000, Pakistan, 7Lahore Institute of Research and Development, -

Multiple Interactions Between an Arf/GEF Complex and Charged Lipids Determine Activation Kinetics on the Membrane
Multiple interactions between an Arf/GEF complex and charged lipids determine activation kinetics on the membrane Deepti Karandura,b,1, Agata Nawrotekc,d,1, John Kuriyana,b,2, and Jacqueline Cherfilsc,d,2 aDepartment of Molecular and Cell Biology, University of California, Berkeley, CA 94720; bHoward Hughes Medical Institute, University of California, Berkeley, CA 94720; cLaboratoire de Biologie et Pharmacologie Appliquée, CNRS, Cachan 94235, France; and dEcole Normale Supérieure Paris-Saclay, Cachan 94235, France Edited by Satyajit Mayor, National Centre for Biological Sciences, Bangalore, India, and approved August 28, 2017 (received for review May 15, 2017) Lipidated small GTPases and their regulators need to bind to which is surrounded by an assortment of regulatory domains (9). membranes to propagate actions in the cell, but an integrated Sec7-assisted nucleotide exchangeoccursinastep-by-step manner, understanding of how the lipid bilayer exerts its effect has whereby the Sec7 domain binds to the switch 1 and switch 2 regions remained elusive. Here we focused on ADP ribosylation factor of Arf to remodel the interswitch and inserts an invariant gluta- (Arf) GTPases, which orchestrate a variety of regulatory functions mate into the nucleotide-binding site to displace GDP (6, 7, 10). in lipid and membrane trafficking, and their activation by the In metazoans, Arf GTPases are activated at the plasma mem- guanine-nucleotide exchange factor (GEF) Brag2, which controls brane and on endosomes by members of three ArfGEF subfamilies: integrin endocytosis and cell adhesion and is impaired in cancer cytohesins, EFA6, and Brag/IQSEC. These ArfGEFs share a com- and developmental diseases. Biochemical and structural data are mon organization in which the Sec7 domain is immediately followed available that showed the exceptional efficiency of Arf activation by a pleckstrin homology (PH) domain that binds phosphoinositide by Brag2 on membranes. -

Regulation of Cdc42 and Its Effectors in Epithelial Morphogenesis Franck Pichaud1,2,*, Rhian F
© 2019. Published by The Company of Biologists Ltd | Journal of Cell Science (2019) 132, jcs217869. doi:10.1242/jcs.217869 REVIEW SUBJECT COLLECTION: ADHESION Regulation of Cdc42 and its effectors in epithelial morphogenesis Franck Pichaud1,2,*, Rhian F. Walther1 and Francisca Nunes de Almeida1 ABSTRACT An overview of Cdc42 Cdc42 – a member of the small Rho GTPase family – regulates cell Cdc42 was discovered in yeast and belongs to a large family of small – polarity across organisms from yeast to humans. It is an essential (20 30 kDa) GTP-binding proteins (Adams et al., 1990; Johnson regulator of polarized morphogenesis in epithelial cells, through and Pringle, 1990). It is part of the Ras-homologous Rho subfamily coordination of apical membrane morphogenesis, lumen formation and of GTPases, of which there are 20 members in humans, including junction maturation. In parallel, work in yeast and Caenorhabditis elegans the RhoA and Rac GTPases, (Hall, 2012). Rho, Rac and Cdc42 has provided important clues as to how this molecular switch can homologues are found in all eukaryotes, except for plants, which do generate and regulate polarity through localized activation or inhibition, not have a clear homologue for Cdc42. Together, the function of and cytoskeleton regulation. Recent studies have revealed how Rho GTPases influences most, if not all, cellular processes. important and complex these regulations can be during epithelial In the early 1990s, seminal work from Alan Hall and his morphogenesis. This complexity is mirrored by the fact that Cdc42 can collaborators identified Rho, Rac and Cdc42 as main regulators of exert its function through many effector proteins. -

Dcps Is a Transcript-Specific Modulator of RNA in Mammalian Cells
Downloaded from rnajournal.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press DcpS is a transcript-specific modulator of RNA in mammalian cells MI ZHOU,1 SOPHIE BAIL,1 HEATHER L. PLASTERER,2 JAMES RUSCHE,2 and MEGERDITCH KILEDJIAN1 1Department of Cell Biology and Neuroscience, Rutgers University, Piscataway, New Jersey 08854, USA 2Repligen Corporation, Waltham, Massachusetts 02453, USA ABSTRACT The scavenger decapping enzyme DcpS is a multifunctional protein initially identified by its property to hydrolyze the resulting cap structure following 3′ end mRNA decay. In Saccharomyces cerevisiae, the DcpS homolog Dcs1 is an obligate cofactor for the 5′-3′ exoribonuclease Xrn1 while the Caenorhabditis elegans homolog Dcs-1, facilitates Xrn1 mediated microRNA turnover. In both cases, this function is independent of the decapping activity. Whether DcpS and its decapping activity can affect mRNA steady state or stability in mammalian cells remains unknown. We sought to determine DcpS target genes in mammalian cells using a cell-permeable DcpS inhibitor compound, RG3039 initially developed for therapeutic treatment of spinal muscular atrophy. Global mRNA levels were examined following DcpS decapping inhibition with RG3039. The steady-state levels of 222 RNAs were altered upon RG3039 treatment. Of a subset selected for validation, two transcripts that appear to be long noncoding RNAs HS370762 and BC011766, were dependent on DcpS and its scavenger decapping catalytic activity and referred to as DcpS-responsive noncoding transcripts (DRNT) 1 and 2, respectively. Interestingly, only the increase in DRNT1 transcript was accompanied with an increase of its RNA stability and this increase was dependent on both DcpS and Xrn1. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
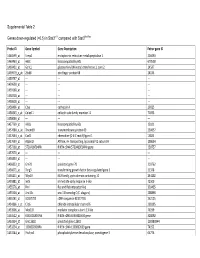
0.5) in Stat3∆/∆ Compared with Stat3flox/Flox
Supplemental Table 2 Genes down-regulated (<0.5) in Stat3∆/∆ compared with Stat3flox/flox Probe ID Gene Symbol Gene Description Entrez gene ID 1460599_at Ermp1 endoplasmic reticulum metallopeptidase 1 226090 1460463_at H60c histocompatibility 60c 670558 1460431_at Gcnt1 glucosaminyl (N-acetyl) transferase 1, core 2 14537 1459979_x_at Zfp68 zinc finger protein 68 24135 1459747_at --- --- --- 1459608_at --- --- --- 1459168_at --- --- --- 1458718_at --- --- --- 1458618_at --- --- --- 1458466_at Ctsa cathepsin A 19025 1458345_s_at Colec11 collectin sub-family member 11 71693 1458046_at --- --- --- 1457769_at H60a histocompatibility 60a 15101 1457680_a_at Tmem69 transmembrane protein 69 230657 1457644_s_at Cxcl1 chemokine (C-X-C motif) ligand 1 14825 1457639_at Atp6v1h ATPase, H+ transporting, lysosomal V1 subunit H 108664 1457260_at 5730409E04Rik RIKEN cDNA 5730409E04Rik gene 230757 1457070_at --- --- --- 1456893_at --- --- --- 1456823_at Gm70 predicted gene 70 210762 1456671_at Tbrg3 transforming growth factor beta regulated gene 3 21378 1456211_at Nlrp10 NLR family, pyrin domain containing 10 244202 1455881_at Ier5l immediate early response 5-like 72500 1455576_at Rinl Ras and Rab interactor-like 320435 1455304_at Unc13c unc-13 homolog C (C. elegans) 208898 1455241_at BC037703 cDNA sequence BC037703 242125 1454866_s_at Clic6 chloride intracellular channel 6 209195 1453906_at Med13l mediator complex subunit 13-like 76199 1453522_at 6530401N04Rik RIKEN cDNA 6530401N04 gene 328092 1453354_at Gm11602 predicted gene 11602 100380944 1453234_at -

Incorrect Dosage of IQSEC2, a Known Intellectual Disability and Epilepsy Gene, Disrupts Dendritic Spine Morphogenesis
OPEN Citation: Transl Psychiatry (2017) 7, e1110; doi:10.1038/tp.2017.81 www.nature.com/tp ORIGINAL ARTICLE Incorrect dosage of IQSEC2, a known intellectual disability and epilepsy gene, disrupts dendritic spine morphogenesis SJ Hinze1,2, MR Jackson1,2, S Lie1, L Jolly1,2, M Field3, SC Barry2, RJ Harvey4 and C Shoubridge1,2 There is considerable genetic and phenotypic heterogeneity associated with intellectual disability (ID), specific learning disabilities, attention-deficit hyperactivity disorder, autism and epilepsy. The intelligence quotient (IQ) motif and SEC7 domain containing protein 2 gene (IQSEC2) is located on the X-chromosome and harbors mutations that contribute to non-syndromic ID with and without early-onset seizure phenotypes in both sexes. Although IQ and Sec7 domain mutations lead to partial loss of IQSEC2 enzymatic activity, the in vivo pathogenesis resulting from these mutations is not known. Here we reveal that IQSEC2 has a key role in dendritic spine morphology. Partial loss-of-function mutations were modeled using a lentiviral short hairpin RNA (shRNA) approach, which achieved a 57% knockdown of Iqsec2 expression in primary hippocampal cell cultures from mice. Investigating gross morphological parameters after 8 days of in vitro culture (8DIV) identified a 32% reduction in primary axon length, in contrast to a 27% and 31% increase in the number and complexity of dendrites protruding from the cell body, respectively. This increase in dendritic complexity and spread was carried through dendritic spine development, with a 34% increase in the number of protrusions per dendritic segment compared with controls at 15DIV. Although the number of dendritic spines had normalized by 21DIV, a reduction was noted in the number of immature spines. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

TITLE PAGE Oxidative Stress and Response to Thymidylate Synthase
Downloaded from molpharm.aspetjournals.org at ASPET Journals on October 2, 2021 -Targeted -Targeted 1 , University of of , University SC K.W.B., South Columbia, (U.O., Carolina, This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. -

The Kinesin-8 Member Kif19 Alters Microtubule Dynamics, Suppresses
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.04.282657; this version posted September 4, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 2 3 4 The kinesin-8 member Kif19 alters microtubule dynamics, suppresses cell adhesion, and 5 promotes cancer cell invasion 6 Short title: Kif19, microtubule dynamics, cell adhesion, and cancer invasion 7 8 Samuel C. Eisenberg1, Abhinav Dey2, Rayna Birnbaum1, David J. Sharp1* 9 10 11 12 1 Physiology and Biophysics, Albert Einstein College of Medicine, Bronx, New York, United 13 States of America 14 2 MicroCures, Albert Einstein College of Medicine, Bronx, New York, United States of America 15 16 17 * Corresponding Author 18 Email: [email protected] (DJS) 19 20 21 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.09.04.282657; this version posted September 4, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 22 Abstract 23 Metastasis is one of the deadliest aspects of cancer. Initial Metastatic spread is 24 dependent on the detachment and dissemination of cells from a parent tumor, and invasion into 25 the surrounding tissue. In this study, we characterize the kinesin-8 member Kif19 as a promoter 26 of cancer cell invasion that suppresses cell-cell adherens junctions and cell-matrix focal 27 adhesions. -

High Throughput Strategies Aimed at Closing the GAP in Our Knowledge of Rho Gtpase Signaling
cells Review High Throughput strategies Aimed at Closing the GAP in Our Knowledge of Rho GTPase Signaling Manel Dahmene 1, Laura Quirion 2 and Mélanie Laurin 1,3,* 1 Oncology Division, CHU de Québec–Université Laval Research Center, Québec, QC G1V 4G2, Canada; [email protected] 2 Montréal Clinical Research Institute (IRCM), Montréal, QC H2W 1R7, Canada; [email protected] 3 Université Laval Cancer Research Center, Québec, QC G1R 3S3, Canada * Correspondence: [email protected] Received: 21 May 2020; Accepted: 7 June 2020; Published: 9 June 2020 Abstract: Since their discovery, Rho GTPases have emerged as key regulators of cytoskeletal dynamics. In humans, there are 20 Rho GTPases and more than 150 regulators that belong to the RhoGEF, RhoGAP, and RhoGDI families. Throughout development, Rho GTPases choregraph a plethora of cellular processes essential for cellular migration, cell–cell junctions, and cell polarity assembly. Rho GTPases are also significant mediators of cancer cell invasion. Nevertheless, to date only a few molecules from these intricate signaling networks have been studied in depth, which has prevented appreciation for the full scope of Rho GTPases’ biological functions. Given the large complexity involved, system level studies are required to fully grasp the extent of their biological roles and regulation. Recently, several groups have tackled this challenge by using proteomic approaches to map the full repertoire of Rho GTPases and Rho regulators protein interactions. These studies have provided in-depth understanding of Rho regulators specificity and have contributed to expand Rho GTPases’ effector portfolio. Additionally, new roles for understudied family members were unraveled using high throughput screening strategies using cell culture models and mouse embryos. -

Whole Exome Sequencing in Families at High Risk for Hodgkin Lymphoma: Identification of a Predisposing Mutation in the KDR Gene
Hodgkin Lymphoma SUPPLEMENTARY APPENDIX Whole exome sequencing in families at high risk for Hodgkin lymphoma: identification of a predisposing mutation in the KDR gene Melissa Rotunno, 1 Mary L. McMaster, 1 Joseph Boland, 2 Sara Bass, 2 Xijun Zhang, 2 Laurie Burdett, 2 Belynda Hicks, 2 Sarangan Ravichandran, 3 Brian T. Luke, 3 Meredith Yeager, 2 Laura Fontaine, 4 Paula L. Hyland, 1 Alisa M. Goldstein, 1 NCI DCEG Cancer Sequencing Working Group, NCI DCEG Cancer Genomics Research Laboratory, Stephen J. Chanock, 5 Neil E. Caporaso, 1 Margaret A. Tucker, 6 and Lynn R. Goldin 1 1Genetic Epidemiology Branch, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 2Cancer Genomics Research Laboratory, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 3Ad - vanced Biomedical Computing Center, Leidos Biomedical Research Inc.; Frederick National Laboratory for Cancer Research, Frederick, MD; 4Westat, Inc., Rockville MD; 5Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; and 6Human Genetics Program, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD, USA ©2016 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol.2015.135475 Received: August 19, 2015. Accepted: January 7, 2016. Pre-published: June 13, 2016. Correspondence: [email protected] Supplemental Author Information: NCI DCEG Cancer Sequencing Working Group: Mark H. Greene, Allan Hildesheim, Nan Hu, Maria Theresa Landi, Jennifer Loud, Phuong Mai, Lisa Mirabello, Lindsay Morton, Dilys Parry, Anand Pathak, Douglas R. Stewart, Philip R. Taylor, Geoffrey S. Tobias, Xiaohong R. Yang, Guoqin Yu NCI DCEG Cancer Genomics Research Laboratory: Salma Chowdhury, Michael Cullen, Casey Dagnall, Herbert Higson, Amy A.