SAHA-DISSERTATION-2021.Pdf (9.978Mb)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-Like Mouse Models: Tracking the Role of the Hairless Gene
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 5-2006 Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-like Mouse Models: Tracking the Role of the Hairless Gene Yutao Liu University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Life Sciences Commons Recommended Citation Liu, Yutao, "Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino- like Mouse Models: Tracking the Role of the Hairless Gene. " PhD diss., University of Tennessee, 2006. https://trace.tennessee.edu/utk_graddiss/1824 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Yutao Liu entitled "Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-like Mouse Models: Tracking the Role of the Hairless Gene." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy, with a major in Life Sciences. Brynn H. Voy, Major Professor We have read this dissertation and recommend its acceptance: Naima Moustaid-Moussa, Yisong Wang, Rogert Hettich Accepted for the Council: Carolyn R. -

Signalling Between Microvascular Endothelium and Cardiomyocytes Through Neuregulin Downloaded From
Cardiovascular Research (2014) 102, 194–204 SPOTLIGHT REVIEW doi:10.1093/cvr/cvu021 Signalling between microvascular endothelium and cardiomyocytes through neuregulin Downloaded from Emily M. Parodi and Bernhard Kuhn* Harvard Medical School, Boston Children’s Hospital, 300 Longwood Avenue, Enders Building, Room 1212, Brookline, MA 02115, USA Received 21 October 2013; revised 23 December 2013; accepted 10 January 2014; online publish-ahead-of-print 29 January 2014 http://cardiovascres.oxfordjournals.org/ Heterocellular communication in the heart is an important mechanism for matching circulatory demands with cardiac structure and function, and neuregulins (Nrgs) play an important role in transducing this signal between the hearts’ vasculature and musculature. Here, we review the current knowledge regarding Nrgs, explaining their roles in transducing signals between the heart’s microvasculature and cardiomyocytes. We highlight intriguing areas being investigated for developing new, Nrg-mediated strategies to heal the heart in acquired and congenital heart diseases, and note avenues for future research. ----------------------------------------------------------------------------------------------------------------------------------------------------------- Keywords Neuregulin Heart Heterocellular communication ErbB -----------------------------------------------------------------------------------------------------------------------------------------------------------† † † This article is part of the Spotlight Issue on: Heterocellular signalling -

Molecular Mechanisms Underlying Noncoding Risk Variations in Psychiatric Genetic Studies
OPEN Molecular Psychiatry (2017) 22, 497–511 www.nature.com/mp REVIEW Molecular mechanisms underlying noncoding risk variations in psychiatric genetic studies X Xiao1,2, H Chang1,2 and M Li1 Recent large-scale genetic approaches such as genome-wide association studies have allowed the identification of common genetic variations that contribute to risk architectures of psychiatric disorders. However, most of these susceptibility variants are located in noncoding genomic regions that usually span multiple genes. As a result, pinpointing the precise variant(s) and biological mechanisms accounting for the risk remains challenging. By reviewing recent progresses in genetics, functional genomics and neurobiology of psychiatric disorders, as well as gene expression analyses of brain tissues, here we propose a roadmap to characterize the roles of noncoding risk loci in the pathogenesis of psychiatric illnesses (that is, identifying the underlying molecular mechanisms explaining the genetic risk conferred by those genomic loci, and recognizing putative functional causative variants). This roadmap involves integration of transcriptomic data, epidemiological and bioinformatic methods, as well as in vitro and in vivo experimental approaches. These tools will promote the translation of genetic discoveries to physiological mechanisms, and ultimately guide the development of preventive, therapeutic and prognostic measures for psychiatric disorders. Molecular Psychiatry (2017) 22, 497–511; doi:10.1038/mp.2016.241; published online 3 January 2017 RECENT GENETIC ANALYSES OF NEUROPSYCHIATRIC neurodevelopment and brain function. For example, GRM3, DISORDERS GRIN2A, SRR and GRIA1 were known to involve in the neuro- Schizophrenia, bipolar disorder, major depressive disorder and transmission mediated by glutamate signaling and synaptic autism are highly prevalent complex neuropsychiatric diseases plasticity. -

Dual Proteome-Scale Networks Reveal Cell-Specific Remodeling of the Human Interactome
bioRxiv preprint doi: https://doi.org/10.1101/2020.01.19.905109; this version posted January 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Dual Proteome-scale Networks Reveal Cell-specific Remodeling of the Human Interactome Edward L. Huttlin1*, Raphael J. Bruckner1,3, Jose Navarrete-Perea1, Joe R. Cannon1,4, Kurt Baltier1,5, Fana Gebreab1, Melanie P. Gygi1, Alexandra Thornock1, Gabriela Zarraga1,6, Stanley Tam1,7, John Szpyt1, Alexandra Panov1, Hannah Parzen1,8, Sipei Fu1, Arvene Golbazi1, Eila Maenpaa1, Keegan Stricker1, Sanjukta Guha Thakurta1, Ramin Rad1, Joshua Pan2, David P. Nusinow1, Joao A. Paulo1, Devin K. Schweppe1, Laura Pontano Vaites1, J. Wade Harper1*, Steven P. Gygi1*# 1Department of Cell Biology, Harvard Medical School, Boston, MA, 02115, USA. 2Broad Institute, Cambridge, MA, 02142, USA. 3Present address: ICCB-Longwood Screening Facility, Harvard Medical School, Boston, MA, 02115, USA. 4Present address: Merck, West Point, PA, 19486, USA. 5Present address: IQ Proteomics, Cambridge, MA, 02139, USA. 6Present address: Vor Biopharma, Cambridge, MA, 02142, USA. 7Present address: Rubius Therapeutics, Cambridge, MA, 02139, USA. 8Present address: RPS North America, South Kingstown, RI, 02879, USA. *Correspondence: [email protected] (E.L.H.), [email protected] (J.W.H.), [email protected] (S.P.G.) #Lead Contact: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2020.01.19.905109; this version posted January 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. -

Pinin (PNN) Rabbit Polyclonal Antibody – TA337687 | Origene
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TA337687 Pinin (PNN) Rabbit Polyclonal Antibody Product data: Product Type: Primary Antibodies Applications: WB Recommended Dilution: WB Reactivity: Human Host: Rabbit Isotype: IgG Clonality: Polyclonal Immunogen: The immunogen for anti-PNN antibody: synthetic peptide directed towards the N terminal of human PNN. Synthetic peptide located within the following region: MAVAVRTLQEQLEKAKESLKNVDENIRKLTGRDPNDVRPIQARLLALSGP Formulation: Liquid. Purified antibody supplied in 1x PBS buffer with 0.09% (w/v) sodium azide and 2% sucrose. Note that this product is shipped as lyophilized powder to China customers. Purification: Affinity Purified Conjugation: Unconjugated Storage: Store at -20°C as received. Stability: Stable for 12 months from date of receipt. Predicted Protein Size: 81 kDa Gene Name: pinin, desmosome associated protein Database Link: NP_002678 Entrez Gene 5411 Human Q9H307 Background: PNN is the transcriptional activator binding to the E-box 1 core sequence of the E-cadherin promoter gene; the core-binding sequence is 5'CAGGTG-3'. PNN is capable of reversing CTBP1-mediated transcription repression. Component of a splicing-dependent mul Synonyms: DRS; DRSP; memA; SDK3 Note: Immunogen Sequence Homology: Dog: 100%; Pig: 100%; Rat: 100%; Human: 100%; Mouse: 100%; Bovine: 100%; Rabbit: 100%; Zebrafish: 100%; Guinea pig: 100% This product -

Exon Junction Complexes Can Have Distinct Functional Flavours To
www.nature.com/scientificreports OPEN Exon Junction Complexes can have distinct functional favours to regulate specifc splicing events Received: 9 November 2017 Zhen Wang1, Lionel Ballut2, Isabelle Barbosa1 & Hervé Le Hir1 Accepted: 11 June 2018 The exon junction complex (EJC) deposited on spliced mRNAs, plays a central role in the post- Published: xx xx xxxx transcriptional gene regulation and specifc gene expression. The EJC core complex is associated with multiple peripheral factors involved in various post-splicing events. Here, using recombinant complex reconstitution and transcriptome-wide analysis, we showed that the EJC peripheral protein complexes ASAP and PSAP form distinct complexes with the EJC core and can confer to EJCs distinct alternative splicing regulatory activities. This study provides the frst evidence that diferent EJCs can have distinct functions, illuminating EJC-dependent gene regulation. Te Exon Junction Complex (EJC) plays a central role in post-transcriptional gene expression control. EJCs tag mRNA exon junctions following intron removal by spliceosomes and accompany spliced mRNAs from the nucleus to the cytoplasm where they are displaced by the translating ribosomes1,2. Te EJC is organized around a core complex made of the proteins eIF4A3, MAGOH, Y14 and MLN51, and this EJC core serves as platforms for multiple peripheral factors during diferent post-transcriptional steps3,4. Dismantled during translation, EJCs mark a very precise period in mRNA life between nuclear splicing and cytoplasmic translation. In this window, EJCs contribute to alternative splicing5–7, intra-cellular RNA localization8, translation efciency9–11 and mRNA stability control by nonsense-mediated mRNA decay (NMD)12–14. At a physiological level, developmental defects and human pathological disorders due to altered expression of EJC proteins show that the EJC dosage is critical for specifc cell fate determinations, such as specifcation of embryonic body axis in drosophila, or Neural Stem Cells division in the mouse8,15,16. -

Sarcomeres Regulate Murine Cardiomyocyte Maturation Through MRTF-SRF Signaling
Sarcomeres regulate murine cardiomyocyte maturation through MRTF-SRF signaling Yuxuan Guoa,1,2,3, Yangpo Caoa,1, Blake D. Jardina,1, Isha Sethia,b, Qing Maa, Behzad Moghadaszadehc, Emily C. Troianoc, Neil Mazumdara, Michael A. Trembleya, Eric M. Smalld, Guo-Cheng Yuanb, Alan H. Beggsc, and William T. Pua,e,2 aDepartment of Cardiology, Boston Children’s Hospital, Boston, MA 02115; bDepartment of Biostatistics and Computational Biology, Dana-Farber Cancer Institute, Boston, MA 02215; cDivision of Genetics and Genomics, The Manton Center for Orphan Disease Research, Boston Children’s Hospital and Harvard Medical School, Boston, MA 02115; dAab Cardiovascular Research Institute, Department of Medicine, University of Rochester School of Medicine and Dentistry, Rochester, NY 14642; and eHarvard Stem Cell Institute, Harvard University, Cambridge, MA 02138 Edited by Janet Rossant, The Gairdner Foundation, Toronto, ON, Canada, and approved November 24, 2020 (received for review May 6, 2020) The paucity of knowledge about cardiomyocyte maturation is a Mechanisms that orchestrate ultrastructural and transcrip- major bottleneck in cardiac regenerative medicine. In develop- tional changes in cardiomyocyte maturation are beginning to ment, cardiomyocyte maturation is characterized by orchestrated emerge. Serum response factor (SRF) is a transcription factor that structural, transcriptional, and functional specializations that occur is essential for cardiomyocyte maturation (3). SRF directly acti- mainly at the perinatal stage. Sarcomeres are the key cytoskeletal vates key genes regulating sarcomere assembly, electrophysiology, structures that regulate the ultrastructural maturation of other and mitochondrial metabolism. This transcriptional regulation organelles, but whether sarcomeres modulate the signal trans- subsequently drives the proper morphogenesis of mature ultra- duction pathways that are essential for cardiomyocyte maturation structural features of myofibrils, T-tubules, and mitochondria. -
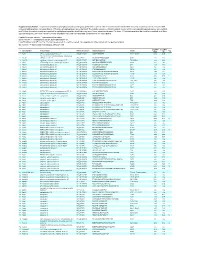
Supplementary Table 1
Supplementary Table 1. Large-scale quantitative phosphoproteomic profiling was performed on paired vehicle- and hormone-treated mTAL-enriched suspensions (n=3). A total of 654 unique phosphopeptides corresponding to 374 unique phosphoproteins were identified. The peptide sequence, phosphorylation site(s), and the corresponding protein name, gene symbol, and RefSeq Accession number are reported for each phosphopeptide identified in any one of three experimental pairs. For those 414 phosphopeptides that could be quantified in all three experimental pairs, the mean Hormone:Vehicle abundance ratio and corresponding standard error are also reported. Peptide Sequence column: * = phosphorylated residue Site(s) column: ^ = ambiguously assigned phosphorylation site Log2(H/V) Mean and SE columns: H = hormone-treated, V = vehicle-treated, n/a = peptide not observable in all 3 experimental pairs Sig. column: * = significantly changed Log 2(H/V), p<0.05 Log (H/V) Log (H/V) # Gene Symbol Protein Name Refseq Accession Peptide Sequence Site(s) 2 2 Sig. Mean SE 1 Aak1 AP2-associated protein kinase 1 NP_001166921 VGSLT*PPSS*PK T622^, S626^ 0.24 0.95 PREDICTED: ATP-binding cassette, sub-family A 2 Abca12 (ABC1), member 12 XP_237242 GLVQVLS*FFSQVQQQR S251^ 1.24 2.13 3 Abcc10 multidrug resistance-associated protein 7 NP_001101671 LMT*ELLS*GIRVLK T464, S468 -2.68 2.48 4 Abcf1 ATP-binding cassette sub-family F member 1 NP_001103353 QLSVPAS*DEEDEVPVPVPR S109 n/a n/a 5 Ablim1 actin-binding LIM protein 1 NP_001037859 PGSSIPGS*PGHTIYAK S51 -3.55 1.81 6 Ablim1 actin-binding -

Dissertation
Regulation of gene silencing: From microRNA biogenesis to post-translational modifications of TNRC6 complexes DISSERTATION zur Erlangung des DOKTORGRADES DER NATURWISSENSCHAFTEN (Dr. rer. nat.) der Fakultät Biologie und Vorklinische Medizin der Universität Regensburg vorgelegt von Johannes Danner aus Eggenfelden im Jahr 2017 Das Promotionsgesuch wurde eingereicht am: 12.09.2017 Die Arbeit wurde angeleitet von: Prof. Dr. Gunter Meister Johannes Danner Summary ‘From microRNA biogenesis to post-translational modifications of TNRC6 complexes’ summarizes the two main projects, beginning with the influence of specific RNA binding proteins on miRNA biogenesis processes. The fate of the mature miRNA is determined by the incorporation into Argonaute proteins followed by a complex formation with TNRC6 proteins as core molecules of gene silencing complexes. miRNAs are transcribed as stem-loop structured primary transcripts (pri-miRNA) by Pol II. The further nuclear processing is carried out by the microprocessor complex containing the RNase III enzyme Drosha, which cleaves the pri-miRNA to precursor-miRNA (pre-miRNA). After Exportin-5 mediated transport of the pre-miRNA to the cytoplasm, the RNase III enzyme Dicer cleaves off the terminal loop resulting in a 21-24 nt long double-stranded RNA. One of the strands is incorporated in the RNA-induced silencing complex (RISC), where it directly interacts with a member of the Argonaute protein family. The miRNA guides the mature RISC complex to partially complementary target sites on mRNAs leading to gene silencing. During this process TNRC6 proteins interact with Argonaute and recruit additional factors to mediate translational repression and target mRNA destabilization through deadenylation and decapping leading to mRNA decay. -

Transcript Isoform Sequencing Reveals Widespread Promoter-Proximal Transcriptional Termination
bioRxiv preprint doi: https://doi.org/10.1101/805853; this version posted October 28, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Title: Transcript isoform sequencing reveals widespread promoter-proximal transcriptional termination Authors: Ryan Ard1*, Quentin Thomas1*, Bingnan Li2, Jingwen Wang2, Vicent Pelechano2, and Sebastian Marquardt1¶ Affiliations: 1 University of Copenhagen, Department of Plant and Environmental Sciences, Copenhagen Plant Science Centre, Frederiksberg, Denmark. 2 SciLifeLab, Department of Microbiology, Tumor and Cell Biology, Karolinska Institutet, Solna, Sweden * These authors contributed equally ¶ Correspondence: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/805853; this version posted October 28, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. SUMMARY Higher organisms achieve optimal gene expression by tightly regulating the transcriptional activity of RNA Polymerase II (RNAPII) along DNA sequences of genes1. RNAPII density across genomes is typically highest where two key choices for transcription occur: near transcription start sites (TSSs) and polyadenylation sites (PASs) at the beginning and end of genes, respectively2,3. Alternative TSSs and PASs amplify the number of transcript isoforms from genes4, but how alternative TSSs connect to variable PASs is unresolved from common transcriptomics methods. -

The Exon Junction Complex Controls Transposable Element Activity by Ensuring Faithful Splicing of the Piwi Transcript
Downloaded from genesdev.cshlp.org on September 25, 2021 - Published by Cold Spring Harbor Laboratory Press The exon junction complex controls transposable element activity by ensuring faithful splicing of the piwi transcript Colin D. Malone,1,2,5 Claire Mestdagh,3,5 Junaid Akhtar,3 Nastasja Kreim,3 Pia Deinhard,3 Ravi Sachidanandam,4 Jessica Treisman,1 and Jean-Yves Roignant3 1Kimmel Center for Biology and Medicine at the Skirball Institute of Biomolecular Medicine, Department of Cell Biology, New York Universtiy School of Medicine, New York, New York 10016, USA; 2Howard Hughes Medical Institute, 3Institute of Molecular Biology (IMB), 55128 Mainz, Germany; 4Department of Oncological Sciences, Icahn School of Medicine at Mount Sinai, New York, New York 10029, USA The exon junction complex (EJC) is a highly conserved ribonucleoprotein complex that binds RNAs during splicing and remains associated with them following export to the cytoplasm. While the role of this complex in mRNA localization, translation, and degradation has been well characterized, its mechanism of action in splicing a subset of Drosophila and human transcripts remains to be elucidated. Here, we describe a novel function for the EJC and its splicing subunit, RnpS1, in preventing transposon accumulation in both Drosophila germline and surrounding somatic follicle cells. This function is mediated specifically through the control of piwi transcript splicing, where, in the absence of RnpS1, the fourth intron of piwi is retained. This intron contains a weak polypyrimidine tract that is sufficient to confer dependence on RnpS1. Finally, we demonstrate that RnpS1-dependent removal of this intron requires splicing of the flanking introns, suggesting a model in which the EJC facilitates the splicing of weak introns following its initial deposition at adjacent exon junctions. -

Transcriptome Analysis of Different Multidrug-Resistant Gastric Carcinoma Cells
in vivo 19: 583-590 (2005) Transcriptome Analysis of Different Multidrug-resistant Gastric Carcinoma Cells STEFFEN HEIM1 and HERMANN LAGE2 1Europroteome AG, Berlin-Hennigsdorf; 2Institute of Pathology, Charité Campus Mitte, Schumannstr. 20/21, D-10117 Berlin, Germany Abstract. Multidrug resistance (MDR) of human cancers is advanced cancer. These therapeutic protocols produce an the major cause of failure of chemotherapy. To better overall response rate of about 20% at best using a single- understand the molecular events associated with the agent, and up to 50% using combination chemotherapy. development of different types of MDR, two different multidrug- Thus, a large number of malignancies are incurable. resistant gastric carcinoma cell lines, the MDR1/P-glycoprotein- Generally, gastrointestinal cancers, including gastric expressing cell line EPG85-257RDB and the MDR1/P- carcinoma, are naturally resistant to many anticancer drugs. glycoprotein-negative cell variant EPG85-257RNOV, as well as Additionally, these tumors are able to develop acquired the corresponding drug-sensitive parental cell line EPG85-257P, drug resistance phenotypes, which include the multidrug were used for analyses of the mRNA expression profiles by resistance (MDR) phenomenon. cDNA array hybridization. Of more than 12,000 genes spotted The MDR phenotype is characterized by simultaneous on the arrays, 156 genes were detected as being significantly resistance of tumor cells to various antineoplastic agents regulated in the cell line EPG85-257RDB in comparison to the which are structurally and functionally unrelated. Besides non-resistant cell variant, and 61 genes were found to be the classical MDR phenotype, mediated by the enhanced differentially expressed in the cell line EPG85-257RNOV.