Extracting Glossary Sentences from Scholarly Articles: a Comparative Evaluation of Pattern Bootstrapping and Deep Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Discovering Semantic Links Between Synonyms, Hyponyms and Hypernyms Ricardo Avila, Gabriel Lopes, Vania Vidal, Jose Macedo
World Academy of Science, Engineering and Technology International Journal of Computer and Systems Engineering Vol:13, No:6, 2019 Discovering Semantic Links Between Synonyms, Hyponyms and Hypernyms Ricardo Avila, Gabriel Lopes, Vania Vidal, Jose Macedo Abstract—This proposal aims for semantic enrichment between Other approaches have been proposed to identify such glossaries using the Simple Knowledge Organization System (SKOS) mappings (see Section IV), but they are still far from perfect. vocabulary to discover synonyms, hyponyms and hyperonyms In general, previous studies have tried to directly identify semiautomatically, in Brazilian Portuguese, generating new semantic relationships based on WordNet. To evaluate the quality of this different types of relationships, usually with the help of proposed model, experiments were performed by the use of two sets dictionaries such as WordNet. On the other hand, we propose containing new relations, being one generated automatically and the an enrichment strategy using a two-step approach. In the first other manually mapped by the domain expert. The applied evaluation step, we apply the use of a crawler to collect synonyms, metrics were precision, recall, f-score, and confidence interval. The hyponyms, and hyperonyms to generate an XML file, then results obtained demonstrate that the applied method in the field of Oil Production and Extraction (E&P) is effective, which suggests that we generate new relationships between the instances and it can be used to improve the quality of terminological mappings. determine the initial ontology mapping with approximate The procedure, although adding complexity in its elaboration, can be matches of equality. Then, using a unified lexical ontology reproduced in others domains. -

Glossary and Bibliography for Vocabularies 1 the Codes (For Example, the Dewey Decimal System Number 735.942)
Glossary and Bibliography for Controlled Vocabularies Glossary AACR2 (Anglo-American Cataloging Rules, 2nd edition) A content standard published by the American Library Association (ALA), Canadian Library Association (CLA), and Chartered Institute of Library and Information Professionals (CILIP). It is being replaced by RDA. abbreviation A shortened form of a name or term (for example, Mr. for Mister). See also acronym and initialism. access point An entry point to a systematic arrangement of information, specifically an indexed field or heading in a work record, vocabulary record, or other content object that is formatted and indexed in order to provide access to the information in the record. acronym An abbreviation or word formed from the initial letters of a compound term or phrase (for example, MoMA, for Museum of Modern Art). See also initialism and abbreviation. ad hoc query Also called a direct query. A query or report that is constructed when required and that directly accesses data files and fields that are selected only when the query is created. It differs from a predefined report or querying a database through a user interface. administrative entity In the context of a geographic vocabulary, a political or other administrative body defined by administrative boundaries and conditions, including inhabited places, nations, empires, nations, states, districts, and townships. administrative data In the context of cataloging art, information having to do with the administrative history and care of the work and the history of the catalog record (for example, insurance value, conservation history, and revision history of the catalog record). See also descriptive data. algorithm A formula or procedure for solving a problem or carrying out a task. -

GLOSSARY of USAGE Presbyterian College English Department a A, an Use a Before a Consonant Sound, an Before a Vowel Sound
GLOSSARY OF USAGE Presbyterian College English Department A a, an Use a before a consonant sound, an before a vowel sound. a heavy load, a nap, a sound; an island, an honest man, an umpire. accept, except As a verb, accept means "to receive"; except means "to exclude." Except as a preposition also means "but." Every senator except Mr. Browning refused to accept the bribe. We will except (exclude) this novel from the list of those to be read. advice, advise Advice is a noun; advise is a verb. I advise you to follow Estelle's advice. affect, effect Affect is a verb meaning "to act upon, to influence, or to imitate." Effect may be either a verb or a noun. Effect as a verb means "to cause or to bring about"; effect as a noun means "a result or a consequence." The patent medicine did not affect (influence) the disease. Henry affected the manner of an Oxford student. (imitated) Henry effected a change in his schedule. (brought about) The effect (result) of this change was that he had no Friday classes. aggravate Aggravate means "to make more grave, to worsen." A problem or condition is aggravated. A person is not aggravated; a person is annoyed. CORRECT: The heavy rains aggravated the slippery roads. CORRECT: The drivers were annoyed by the slippery roads. INCORRECT: The drivers were aggravated by the slippery roads. CORRECT: Her headache was aggravated by the damp weather. INCORRECT: She was aggravated by driving in the heavy traffic. CORRECT: She was annoyed by driving in the heavy traffic. -

Glossary of Linguistic Terms
Glossary of Linguistic Terms accent Often used to refer to distinctive pronuncia tions which differ from that of Received Pronunciation It differs from dialect which includes syn tax and vocabulary as well acronym A word formed from the initial letters of the words which make up a name, e.g. NATO (from North Atlantic Treaty Organisation) active A clause in which the subject is the actor of the verb; in a passive clause the actor is not the grammatical subject; seep. 14 addressee The person being addressed or spoken to in any form of discourse adjective In traditional grammar a word which de scribes a noun, as happy in 'the happy man'; an adjective phrase is a group of one or more words fulfilling the function of an adjective; seep. 11 adverb In t:r:aditional grammar a word which de scribes a verb; in 'he ran slowly', slowly describes how he ran An adverb phrase is a group of one or more words fulfilling the function of an adverb; see p. 11 affix A morpheme which is attached to another word as an inflection or for derivation Affixes include prefixes at the beginning of a word and suffixes at the end of a word, e.g. un-god-ly with prefix un- and suffix -ly A derivational affix is used to form a new word, e.g. the suffix -less with hope gives the new word hopeless; an inflectional affix marks grammatical relations, in comes, the -s marks third person singular present indicative 159 160 Glossary alliteration The repetition of the same sound at the beginning of two or more words in close proximity, e.g. -
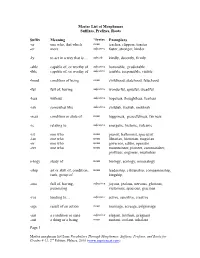
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Bilingualized Dictionaries with Special Reference to the Chinese EFL Context Yuzhen Chen, Department of Foreign Languages, Putian University, Fujian, P.R.C
Bilingualized Dictionaries with Special Reference to the Chinese EFL Context Yuzhen Chen, Department of Foreign Languages, Putian University, Fujian, P.R.C. ([email protected]) Abstract: As a type of dictionary with huge popularity among EFL learners in China, the bilin- gualized dictionary (BLD) deserves more academic and pedagogical attention than it receives nowadays. This article gives an overview of the BLD within the framework of dictionary research, including dictionary history, dictionary typology, dictionary criticism and dictionary use. It first traces, with a special reference to the Chinese EFL context, the origin and historical development of this type of dictionary, and then proposes several approaches to its classification. The strengths and weaknesses of the BLD are evaluated and its role in language pedagogy discussed, followed by an extensive review of the empirical studies of BLD use. Finally, further areas of BLD research are also suggested. It is hoped that such an overview would kindle more research interest in BLDs which is relevant to language pedagogy, dictionary use instruction and lexicographic practices. Keywords: LEXICOGRAPHY, BILINGUALIZED DICTIONARIES, MONOLINGUAL DIC- TIONARIES, BILINGUAL DICTIONARIES, ORIGIN, HISTORICAL DEVELOPMENT, DICTION- ARY TYPOLOGY, DICTIONARY CRITICISM, DICTIONARY USE, CHINESE EFL CONTEXT Opsomming: Verklarende woordeboeke met 'n tweetalige dimensie met spesiale verwysing na die Chinese EVT-konteks. As 'n tipe woordeboek wat enorme gewildheid geniet by EVT-aanleerders in China, verdien die verklarende woordeboek met verta- lings (bilingualized dictionary of BLD) meer akademiese en opvoedkundige aandag as wat dit dees- dae ontvang. Hierdie artikel gee 'n oorsig van die BLD binne die raamwerk van woordeboeknavor- sing, insluitende die geskiedenis van woordeboeke, woordeboektipologie, woordeboekkritiek en woordeboekgebruik. -

Igor Burkhanov. Lexicography: a Dictionary of Basic Terminology. 1998, 285 Pp
Resensies / Reviews 320 Igor Burkhanov. Lexicography: A Dictionary of Basic Terminology. 1998, 285 pp. ISBN 83-87288-56-X. Rzeszów: Wyższa Szkoła Pedagogiczna. Price 16 PLN. A long-awaited dictionary has at last been published, going beyond a glossary of lexicographic terms (cf. Robinson 1984) or a dictionary of a particular aspect of lexicography (cf. Cluver 1989). It is the first dictionary of basic lexicography terms. In 265 pages Burkhanov gives us a balanced view of the state of the art in dictionary form. It comprises terms typical of lexicographic work, including terms originally related to different linguistic disciplines. The selection of the data is founded, as can be inferred from the bibliogra- phy (p. 267-285), on a solid basis. It covers publications over the last twenty years, deals with various aspects of the field and includes the most recent trends from the late eighties and the nineties, e.g. Bergenholtz and Tarp (1995), Bright (1992), Bussmann (1996), Cowie (1987), Cluver (1989), Diab (1990), Fill- more and Atkins (1992), Ilson (1991), Benson, Benson and Ilson (1986), Landau (1989), Hüllen (1990), Snell-Hornby (1990). It is not difficult to find one's way in the dictionary: few symbols are used, most important of which are the ones indicating cross-references within the word-list. In this dictionary, though the arrangement of terms is alphabetical, conceptual relatedness between terms is not lost. Related terms are listed at the end of the explanatory text with the guide words "see also" and "compare". "See also" refers to superordinate and subordinate terms, e.g. -

Dictionary of Ibm & Computing Terminology 1 8307D01a
1 DICTIONARY OF IBM & COMPUTING TERMINOLOGY 8307D01A 2 A AA (ay-ay) n. Administrative Assistant. An up-and-coming employee serving in a broadening assignment who supports a senior executive by arranging meetings and schedules, drafting and coordinating correspondence, assigning tasks, developing presentations and handling a variety of other administrative responsibilities. The AA’s position is to be distinguished from that of the executive secretary, although the boundary line between the two roles is frequently blurred. access control n. In computer security, the process of ensuring that the resources of a computer system can be accessed only by authorized users in authorized ways. acknowledgment 1. n. The transmission, by a receiver, of acknowledge characters as an affirmative response to a sender. 2. n. An indication that an item sent was received. action plan n. A plan. Project management is never satisfied by just a plan. The only acceptable plans are action plans. Also used to mean an ad hoc short-term scheme for resolving a specific and well defined problem. active program n. Any program that is loaded and ready to be executed. active window n. The window that can receive input from the keyboard. It is distinguishable by the unique color of its title bar and window border. added value 1. n. The features or bells and whistles (see) that distinguish one product from another. 2. n. The additional peripherals, software, support, installation, etc., provided by a dealer or other third party. administrivia n. Any kind of bureaucratic red tape or paperwork, IBM or not, that hinders the accomplishment of one’s objectives or goals. -

Detailed Terminographic Analysis of “Glossary of Terminology Used in the Standardization of Geographical Names *
UNITED NATIONS WORKING PAPER GROUP OF EXPERTS ON NO. 38/10 GEOGRAPHICAL NAMES Twenty-eighth session New York, 28 April-2 May 2014 Item 10 of the provisional agenda Activities relating to the Working Group on Toponymic Terminology Detailed Terminographic Analysis of “Glossary of Terminology Used in the Standardization of Geographical Names * Submitted by Poland * Prepared by Marek Łukasik (Department of English Studies, Pomeranian University in Słupsk, Poland; Corpus Linguistics Laboratory, Faculty of Applied Linguistics, University of Warsaw) and Maciej Zych (Commission on Standardization of Geographical Names Outside the Republic of Poland). DETAILED TERMINOGRAPHIC ANALYSIS OF GLOSSARY OF TERMINOLOGY USED IN THE STANDARDIZATION OF GEOGRAPHICAL NAMES (SUMMARY) The Commission on Standardization of Geographical Names Outside the Republic of Poland is planning to publish a new edition of Glossary of Terminology Used in the Standardization of Geographical Names [Polish: Słownik terminów używanych przy standaryzacji nazw geograficznych] (the latest edition was released in 1998). Before commencing any work, the Commission decided to analyze the compositional correctness of the existing dictionary. To this end, an expert lexicographic opinion had been drafted. On account of the fact that the Polish version is in many places a faithful translation of the UNGEGN dictionary, whose main part, i.e. the English version, has not undergone considerable changes since the release of the Polish version, remarks included in the opinion and this paper may, to a great extent, be applicable to the English original. These comments may prove useful for the UNGEGN Working Group on Toponymic Terminology as guidelines before undertaking a revision of the Glossary of Terms for the Standardization of Geographical Names. -

Using Translations to Distinguish Between Homonymy and Polysemy
Using Translations to Distinguish Between Homonymy and Polysemy by Amir Ahmad Habibi A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science Department of Computing Science University of Alberta c Amir Ahmad Habibi, 2020 Abstract Distinguishing between homonymy and polysemy can facilitate word sense dis- ambiguation (WSD), as WSD systems use the standard sense inventories that are excessively fine-grained and include many polysemous senses. We classify words as either homonymous or polysemous by building graphs of word senses as nodes and the semantic relatedness between them as edges. To find these edges, we build upon a previous hypothesis on the role of shared translations in semantic relatedness, and after developing new theorems, we propose methods of obtaining semantic relatedness information from translations of multilin- gual sense inventories. Additionally, we create a new homonym resource, as well as updating an existing one. These resources include lists of homonyms and their short definitions, manually mapped to their corresponding WordNet senses. We evaluate our methods on a balanced dataset of homonymous and polysemous words, and our methods achieve state-of-the-art results in the task of homonym detection. ii Preface The research presented in this dissertation is a joint work with Prof. Grze- gorz Kondrak. The author contributed ideas, implemented the methods, and performed the experiments. The type-A homonym resource presented in this work is the result of a collaborative effort of the NLP group at the University of Alberta, including Bradley Hauer and Yixing Luan. The author was the main contributor, performing the majority of the manual annotations. -

Foundational Literacy Glossary of Terms
Foundational Literacy Glossary of Terms Accuracy The ability to recognize words correctly Advanced Phonics Strategies for decoding multisyllabic words that include morphology and information about the meaning, pronunciation, and parts of speech of words gained from knowledge of prefixes, roots, and suffixes Affixes Affixes are word parts that are "fixed to" either the beginnings of words (prefixes) or the endings of words (suffixes). The word disrespectful has two affixes, a prefix (dis-) and a suffix (-ful) Alphabetic Awareness Knowledge of letters of the alphabet coupled with the understanding that the alphabet represents the sounds of spoken language and the correspondence of spoken sounds to written language Alphabetic Code Sound-symbol relationships to recognize words Alphabetic Principle The concept that letters and letter combinations represent individual phonemes in written words Alphabetic Understanding Understanding that the left-to-right spellings of printed words represent their phonemes from first to last Automaticity The ability to translate letters-to-sounds-to-words fluently, effortlessly Base Word A unit of meaning that can stand alone as a whole word (e.g., friend, pig). Also called a free morpheme. Also called a free morpheme Blend A blend is a consonant sequence before or after a vowel within a syllable, such as cl, br, or st; it is the written language equivalent of consonant cluster Blending The task of combining sounds rapidly to accurately represent the word Chunking A decoding strategy for separating words into -

Glossary Guided Post-Processing for Word Embedding Learning
Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), pages 4726–4730 Marseille, 11–16 May 2020 c European Language Resources Association (ELRA), licensed under CC-BY-NC GGP: Glossary Guided Post-processing for Word Embedding Learning Ruosong Yang, Jiannong Cao, Zhiyuan Wen The Hong Kong Polytechnic University Hong Kong, China fcsryang,csjcao,[email protected] Abstract Word embedding learning is the task to map each word into a low-dimensional and continuous vector based on a large corpus. To enhance corpus based word embedding models, researchers utilize domain knowledge to learn more distinguishable representations via joint optimization and post-processing based models. However, joint optimization based models require much training time. Existing post-processing models mostly consider semantic knowledge so that learned embedding models show less functional information. Compared with semantic knowledge sources, glossary is a comprehensive linguistic resource which contains complete semantics. Previous glossary based post-processing method only processed words occurred in the glossary, and did not distinguish multiple senses of each word. In this paper, to make better use of glossary, we utilize attention mechanism to integrate multiple sense representations which are learned respectively. With measuring similarity between word representation and combined sense representation, we aim to capture more topical and functional information. We propose GGP (Glossary Guided Post-processing word embedding) model which consists of a global post-processing function to fine-tune each word vector, and an auto-encoding model to learn sense representations, furthermore, constrains each post-processed word representation and the composition of its sense representations to be similar.