Modelling the MIB30 Implied Volatility Surface. Does Market Efficiency Matter?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Up to EUR 3,500,000.00 7% Fixed Rate Bonds Due 6 April 2026 ISIN
Up to EUR 3,500,000.00 7% Fixed Rate Bonds due 6 April 2026 ISIN IT0005440976 Terms and Conditions Executed by EPizza S.p.A. 4126-6190-7500.7 This Terms and Conditions are dated 6 April 2021. EPizza S.p.A., a company limited by shares incorporated in Italy as a società per azioni, whose registered office is at Piazza Castello n. 19, 20123 Milan, Italy, enrolled with the companies’ register of Milan-Monza-Brianza- Lodi under No. and fiscal code No. 08950850969, VAT No. 08950850969 (the “Issuer”). *** The issue of up to EUR 3,500,000.00 (three million and five hundred thousand /00) 7% (seven per cent.) fixed rate bonds due 6 April 2026 (the “Bonds”) was authorised by the Board of Directors of the Issuer, by exercising the powers conferred to it by the Articles (as defined below), through a resolution passed on 26 March 2021. The Bonds shall be issued and held subject to and with the benefit of the provisions of this Terms and Conditions. All such provisions shall be binding on the Issuer, the Bondholders (and their successors in title) and all Persons claiming through or under them and shall endure for the benefit of the Bondholders (and their successors in title). The Bondholders (and their successors in title) are deemed to have notice of all the provisions of this Terms and Conditions and the Articles. Copies of each of the Articles and this Terms and Conditions are available for inspection during normal business hours at the registered office for the time being of the Issuer being, as at the date of this Terms and Conditions, at Piazza Castello n. -

(NSE), India, Using Box Spread Arbitrage Strategy
Gadjah Mada International Journal of Business - September-December, Vol. 15, No. 3, 2013 Gadjah Mada International Journal of Business Vol. 15, No. 3 (September - December 2013): 269 - 285 Efficiency of S&P CNX Nifty Index Option of the National Stock Exchange (NSE), India, using Box Spread Arbitrage Strategy G. P. Girish,a and Nikhil Rastogib a IBS Hyderabad, ICFAI Foundation For Higher Education (IFHE) University, Andhra Pradesh, India b Institute of Management Technology (IMT) Hyderabad, India Abstract: Box spread is a trading strategy in which one simultaneously buys and sells options having the same underlying asset and time to expiration, but different exercise prices. This study examined the effi- ciency of European style S&P CNX Nifty Index options of National Stock Exchange, (NSE) India by making use of high-frequency data on put and call options written on Nifty (Time-stamped transactions data) for the time period between 1st January 2002 and 31st December 2005 using box-spread arbitrage strategy. The advantages of box-spreads include reduced joint hypothesis problem since there is no consideration of pricing model or market equilibrium, no consideration of inter-market non-synchronicity since trading box spreads involve only one market, computational simplicity with less chances of mis- specification error, estimation error and the fact that buying and selling box spreads more or less repli- cates risk-free lending and borrowing. One thousand three hundreds and fifty eight exercisable box- spreads were found for the time period considered of which 78 Box spreads were found to be profit- able after incorporating transaction costs (32 profitable box spreads were identified for the year 2002, 19 in 2003, 14 in 2004 and 13 in 2005) The results of our study suggest that internal option market efficiency has improved over the years for S&P CNX Nifty Index options of NSE India. -

Implied Volatility Modeling
Implied Volatility Modeling Sarves Verma, Gunhan Mehmet Ertosun, Wei Wang, Benjamin Ambruster, Kay Giesecke I Introduction Although Black-Scholes formula is very popular among market practitioners, when applied to call and put options, it often reduces to a means of quoting options in terms of another parameter, the implied volatility. Further, the function σ BS TK ),(: ⎯⎯→ σ BS TK ),( t t ………………………………(1) is called the implied volatility surface. Two significant features of the surface is worth mentioning”: a) the non-flat profile of the surface which is often called the ‘smile’or the ‘skew’ suggests that the Black-Scholes formula is inefficient to price options b) the level of implied volatilities changes with time thus deforming it continuously. Since, the black- scholes model fails to model volatility, modeling implied volatility has become an active area of research. At present, volatility is modeled in primarily four different ways which are : a) The stochastic volatility model which assumes a stochastic nature of volatility [1]. The problem with this approach often lies in finding the market price of volatility risk which can’t be observed in the market. b) The deterministic volatility function (DVF) which assumes that volatility is a function of time alone and is completely deterministic [2,3]. This fails because as mentioned before the implied volatility surface changes with time continuously and is unpredictable at a given point of time. Ergo, the lattice model [2] & the Dupire approach [3] often fail[4] c) a factor based approach which assumes that implied volatility can be constructed by forming basis vectors. Further, one can use implied volatility as a mean reverting Ornstein-Ulhenbeck process for estimating implied volatility[5]. -

11 Option Payoffs and Option Strategies
11 Option Payoffs and Option Strategies Answers to Questions and Problems 1. Consider a call option with an exercise price of $80 and a cost of $5. Graph the profits and losses at expira- tion for various stock prices. 73 74 CHAPTER 11 OPTION PAYOFFS AND OPTION STRATEGIES 2. Consider a put option with an exercise price of $80 and a cost of $4. Graph the profits and losses at expiration for various stock prices. ANSWERS TO QUESTIONS AND PROBLEMS 75 3. For the call and put in questions 1 and 2, graph the profits and losses at expiration for a straddle comprising these two options. If the stock price is $80 at expiration, what will be the profit or loss? At what stock price (or prices) will the straddle have a zero profit? With a stock price at $80 at expiration, neither the call nor the put can be exercised. Both expire worthless, giving a total loss of $9. The straddle breaks even (has a zero profit) if the stock price is either $71 or $89. 4. A call option has an exercise price of $70 and is at expiration. The option costs $4, and the underlying stock trades for $75. Assuming a perfect market, how would you respond if the call is an American option? State exactly how you might transact. How does your answer differ if the option is European? With these prices, an arbitrage opportunity exists because the call price does not equal the maximum of zero or the stock price minus the exercise price. To exploit this mispricing, a trader should buy the call and exercise it for a total out-of-pocket cost of $74. -

Managed Futures and Long Volatility by Anders Kulp, Daniel Djupsjöbacka, Martin Estlander, Er Capital Management Research
Disclaimer: This article appeared in the AIMA Journal (Feb 2005), which is published by The Alternative Investment Management Association Limited (AIMA). No quotation or reproduction is permitted without the express written permission of The Alternative Investment Management Association Limited (AIMA) and the author. The content of this article does not necessarily reflect the opinions of the AIMA Membership and AIMA does not accept responsibility for any statements herein. Managed Futures and Long Volatility By Anders Kulp, Daniel Djupsjöbacka, Martin Estlander, er Capital Management Research Introduction and background The buyer of an option straddle pays the implied volatility to get exposure to realized volatility during the lifetime of the option straddle. Fung and Hsieh (1997b) found that the return of trend following strategies show option like characteristics, because the returns tend to be large and positive during the best and worst performing months of the world equity markets. Fung and Hsieh used lookback straddles to replicate a trend following strategy. However, the standard way to obtain exposure to volatility is to buy an at-the-money straddle. Here, we will use standard option straddles with a dynamic updating methodology and flexible maturity rollover rules to match the characteristics of a trend follower. The lookback straddle captures only one trend during its maturity, but with an effective systematic updating method the simple option straddle captures more than one trend. It is generally accepted that when implementing an options strategy, it is crucial to minimize trading, because the liquidity in the options markets are far from perfect. Compared to the lookback straddle model, the trading frequency for the simple straddle model is lower. -

White Paper Volatility: Instruments and Strategies
White Paper Volatility: Instruments and Strategies Clemens H. Glaffig Panathea Capital Partners GmbH & Co. KG, Freiburg, Germany July 30, 2019 This paper is for informational purposes only and is not intended to constitute an offer, advice, or recommendation in any way. Panathea assumes no responsibility for the content or completeness of the information contained in this document. Table of Contents 0. Introduction ......................................................................................................................................... 1 1. Ihe VIX Index .................................................................................................................................... 2 1.1 General Comments and Performance ......................................................................................... 2 What Does it mean to have a VIX of 20% .......................................................................... 2 A nerdy side note ................................................................................................................. 2 1.2 The Calculation of the VIX Index ............................................................................................. 4 1.3 Mathematical formalism: How to derive the VIX valuation formula ...................................... 5 1.4 VIX Futures .............................................................................................................................. 6 The Pricing of VIX Futures ................................................................................................ -

Futures & Options on the VIX® Index
Futures & Options on the VIX® Index Turn Volatility to Your Advantage U.S. Futures and Options The Cboe Volatility Index® (VIX® Index) is a leading measure of market expectations of near-term volatility conveyed by S&P 500 Index® (SPX) option prices. Since its introduction in 1993, the VIX® Index has been considered by many to be the world’s premier barometer of investor sentiment and market volatility. To learn more, visit cboe.com/VIX. VIX Futures and Options Strategies VIX futures and options have unique characteristics and behave differently than other financial-based commodity or equity products. Understanding these traits and their implications is important. VIX options and futures enable investors to trade volatility independent of the direction or the level of stock prices. Whether an investor’s outlook on the market is bullish, bearish or somewhere in-between, VIX futures and options can provide the ability to diversify a portfolio as well as hedge, mitigate or capitalize on broad market volatility. Portfolio Hedging One of the biggest risks to an equity portfolio is a broad market decline. The VIX Index has had a historically strong inverse relationship with the S&P 500® Index. Consequently, a long exposure to volatility may offset an adverse impact of falling stock prices. Market participants should consider the time frame and characteristics associated with VIX futures and options to determine the utility of such a hedge. Risk Premium Yield Over long periods, index options have tended to price in slightly more uncertainty than the market ultimately realizes. Specifically, the expected volatility implied by SPX option prices tends to trade at a premium relative to subsequent realized volatility in the S&P 500 Index. -

Option Prices Under Bayesian Learning: Implied Volatility Dynamics and Predictive Densities∗
Option Prices under Bayesian Learning: Implied Volatility Dynamics and Predictive Densities∗ Massimo Guidolin† Allan Timmermann University of Virginia University of California, San Diego JEL codes: G12, D83. Abstract This paper shows that many of the empirical biases of the Black and Scholes option pricing model can be explained by Bayesian learning effects. In the context of an equilibrium model where dividend news evolve on a binomial lattice with unknown but recursively updated probabilities we derive closed-form pricing formulas for European options. Learning is found to generate asymmetric skews in the implied volatility surface and systematic patterns in the term structure of option prices. Data on S&P 500 index option prices is used to back out the parameters of the underlying learning process and to predict the evolution in the cross-section of option prices. The proposed model leads to lower out-of- sample forecast errors and smaller hedging errors than a variety of alternative option pricing models, including Black-Scholes and a GARCH model. ∗We wish to thank four anonymous referees for their extensive and thoughtful comments that greatly improved the paper. We also thank Alexander David, Jos´e Campa, Bernard Dumas, Wake Epps, Stewart Hodges, Claudio Michelacci, Enrique Sentana and seminar participants at Bocconi University, CEMFI, University of Copenhagen, Econometric Society World Congress in Seattle, August 2000, the North American Summer meetings of the Econometric Society in College Park, June 2001, the European Finance Association meetings in Barcelona, August 2001, Federal Reserve Bank of St. Louis, INSEAD, McGill, UCSD, Universit´edeMontreal,andUniversity of Virginia for discussions and helpful comments. -

The Impact of Implied Volatility Fluctuations on Vertical Spread Option Strategies: the Case of WTI Crude Oil Market
energies Article The Impact of Implied Volatility Fluctuations on Vertical Spread Option Strategies: The Case of WTI Crude Oil Market Bartosz Łamasz * and Natalia Iwaszczuk Faculty of Management, AGH University of Science and Technology, 30-059 Cracow, Poland; [email protected] * Correspondence: [email protected]; Tel.: +48-696-668-417 Received: 31 July 2020; Accepted: 7 October 2020; Published: 13 October 2020 Abstract: This paper aims to analyze the impact of implied volatility on the costs, break-even points (BEPs), and the final results of the vertical spread option strategies (vertical spreads). We considered two main groups of vertical spreads: with limited and unlimited profits. The strategy with limited profits was divided into net credit spread and net debit spread. The analysis takes into account West Texas Intermediate (WTI) crude oil options listed on New York Mercantile Exchange (NYMEX) from 17 November 2008 to 15 April 2020. Our findings suggest that the unlimited vertical spreads were executed with profits less frequently than the limited vertical spreads in each of the considered categories of implied volatility. Nonetheless, the advantage of unlimited strategies was observed for substantial oil price movements (above 10%) when the rates of return on these strategies were higher than for limited strategies. With small price movements (lower than 5%), the net credit spread strategies were by far the best choice and generated profits in the widest price ranges in each category of implied volatility. This study bridges the gap between option strategies trading, implied volatility and WTI crude oil market. The obtained results may be a source of information in hedging against oil price fluctuations. -

VIX Futures As a Market Timing Indicator
Journal of Risk and Financial Management Article VIX Futures as a Market Timing Indicator Athanasios P. Fassas 1 and Nikolas Hourvouliades 2,* 1 Department of Accounting and Finance, University of Thessaly, Larissa 41110, Greece 2 Department of Business Studies, American College of Thessaloniki, Thessaloniki 55535, Greece * Correspondence: [email protected]; Tel.: +30-2310-398385 Received: 10 June 2019; Accepted: 28 June 2019; Published: 1 July 2019 Abstract: Our work relates to the literature supporting that the VIX also mirrors investor sentiment and, thus, contains useful information regarding future S&P500 returns. The objective of this empirical analysis is to verify if the shape of the volatility futures term structure has signaling effects regarding future equity price movements, as several investors believe. Our findings generally support the hypothesis that the VIX term structure can be employed as a contrarian market timing indicator. The empirical analysis of this study has important practical implications for financial market practitioners, as it shows that they can use the VIX futures term structure not only as a proxy of market expectations on forward volatility, but also as a stock market timing tool. Keywords: VIX futures; volatility term structure; future equity returns; S&P500 1. Introduction A fundamental principle of finance is the positive expected return-risk trade-off. In this paper, we examine the dynamic dependencies between future equity returns and the term structure of VIX futures, i.e., the curve that connects daily settlement prices of individual VIX futures contracts to maturities across time. This study extends the VIX futures-related literature by testing the market timing ability of the VIX futures term structure regarding future stock movements. -
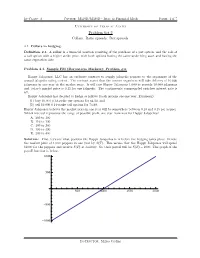
Problem Set 2 Collars
In-Class: 2 Course: M339D/M389D - Intro to Financial Math Page: 1 of 7 University of Texas at Austin Problem Set 2 Collars. Ratio spreads. Box spreads. 2.1. Collars in hedging. Definition 2.1. A collar is a financial position consiting of the purchase of a put option, and the sale of a call option with a higher strike price, with both options having the same underlying asset and having the same expiration date Problem 2.1. Sample FM (Derivatives Markets): Problem #3. Happy Jalape~nos,LLC has an exclusive contract to supply jalape~nopeppers to the organizers of the annual jalape~noeating contest. The contract states that the contest organizers will take delivery of 10,000 jalape~nosin one year at the market price. It will cost Happy Jalape~nos1,000 to provide 10,000 jalape~nos and today's market price is 0.12 for one jalape~no. The continuously compounded risk-free interest rate is 6%. Happy Jalape~noshas decided to hedge as follows (both options are one year, European): (1) buy 10,000 0.12-strike put options for 84.30, and (2) sell 10,000 0.14-strike call options for 74.80. Happy Jalape~nosbelieves the market price in one year will be somewhere between 0.10 and 0.15 per pepper. Which interval represents the range of possible profit one year from now for Happy Jalape~nos? A. 200 to 100 B. 110 to 190 C. 100 to 200 D. 190 to 390 E. 200 to 400 Solution: First, let's see what position the Happy Jalape~nosis in before the hedging takes place. -

WACC and Vol (Valuation for Companies with Real Options)
Counterpoint Global Insights WACC and Vol Valuation for Companies with Real Options CONSILIENT OBSERVER | December 21, 2020 Introduction AUTHORS Twenty-twenty has been extraordinary for a lot of reasons. The global Michael J. Mauboussin pandemic created a major health challenge and an unprecedented [email protected] economic shock, there was plenty of political uncertainty, and the Dan Callahan, CFA stock market’s results were surprising to many.1 The year was also [email protected] fascinating for investors concerned with corporate valuation. Theory prescribes that the value of a company is the present value of future free cash flow. The task of valuing a business comes down to an assessment of cash flows and the opportunity cost of capital. The stock prices of some companies today imply expectations for future cash flows in excess of what seems reasonably achievable. Automatically assuming these companies are mispriced may be a mistake because certain businesses also have real option value. The year 2020 is noteworthy because the weighted average cost of capital (WACC), which is applied to visible parts of the business, is well below its historical average, and volatility (vol), which drives option value, is well above its historical average. Businesses that have real option value benefit from a lower discount rate on their current operations and from the higher volatility of the options available to them. In this report, we define real options, discuss what kinds of businesses are likely to have them, and review the valuation implication of a low cost of capital and high volatility. We finish with a method to incorporate real options analysis into traditional valuation.