KEPS 2017 Proceedings of the Workshop on Knowledge Engineering for Planning and Scheduling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In Honolulu's Christ Church in Kailua, Which Will Repeat Next Hemenway Theatre, UH Manoa Campus: Wed
5 The Fear Factor 8 Pritchett !ICalendar 13 Book Bonanza l!IStraight Dope Volume 3, Number 45, November 10, 1993 FREE Interview by JOHN WYTHE WHITE State Representative DaveHagino has spent 15 years fighting the system he's a partof- and theparty he belongs to. !JiORDERS BOOKS & MUSIC· BORDERS BOOKS & MUSIC· BORDERS BOOKS & MUSIC· BORDERS BOOKS & MUSIC· BORDERS BOOKS & MUSIC· BORDERS BOOKS & MUSIC· BORDERS BOOKS 8 ,,,, :,..: ;o 0 0 � �L � w ffi 8 Cl 0 ;,<; 0::: w 0 il,1.. � SELECTION: w 2 No Comparison 00 Cl 0::: i0 co co 0 ;o 0 -- -- co�:. 0 0 7' $�··· C nw oco ;o· · 0 m � co 0 0 w7' ::c: :::: C w 0:co 0 ;o 0 m � co 0 0 ci: � $ C w Borders® Books &Music. n ;o8 0 m The whole idea behind Finda book or music store the new Borders Books w;o co .- Borders Books & Music is to &Music. 0 with more titles and 0 w7' create an appealing place with Welcome to the new � $ we'll shop there. C more selection. So we brought Borders Books &Music. w () 100,000 in over book titles, more times the average store. Borders co 0 than 5 times the average bookstore. especially excels in classical and ;o It 0 CD m .r::;"' � OJ ;o What that means is that Borders jazz recordings. 0 E w (.) "' i co .r::; 'l' CD I 0 E 0 offersmore history, more com Borders also carries the area's (!) 0 """' 7' H-1 Fwy. w puters, more cooking. More of broadest selection of videotapes, � Waikele/Waipahu Exit 7 ::::: C everything, not just more copies including classic and foreign films. -

WV Graded Music List 2011
2011 WV Graded Music List, p. 1 2011 West Virginia Graded Music List Grade 1 Grade 2 Grade 3 Grade 4 Grade 5 Grade 6 Grade Artist Arranger Title Publisher 1 - Higgins, John Suo Gan HL 1 - McGinty Japanese Folk Trilogy QU 1 - McGinty, Anne Elizabethan Songbook, An KJ 1 - Navarre, Randy Ngiele, Ngiele NMP 1 - Ployhar Along the Western Trail BE 1 - Ployhar Minka BE 1 - Ployhar Volga Boat Song BE 1 - Smith, R.W. Appalachian Overture BE Variant on an Old English 1 - Smith, R.W. BE Carol 1 - Story A Jubilant Carol BE 1 - Story Classic Bits and Pieces BE 1 - Story Patriotic Bits and Pieces BE 1 - Swearingen Three Chorales for Band BE 1 - Sweeney Shenandoah HL 1 Adams Valse Petite SP 1 Akers Berkshire Hills BO 1 Akers Little Classic Suite CF 1 Aleicheim Schaffer Israeli Folk Songs PO 1 Anderson Ford Forgotten Dreams BE 1 Anderson Ford Sandpaper Ballet BE 1 Arcadelt Whiting Ave Maria EM 1 Arensky Powell The Cuckoo PO 1 Bach Gardner Little Bach Suite ST Grand Finale from Cantata 1 Bach Gordon BO #207 1 Bach Walters Celebrated Air RU 1 Bain, James L. M Wagner Brother James' Air BE 1 Balent Bold Adventure WB Drummin' With Reuben And 1 Balent BE Rachel 1 Balent Lonesome Tune WB 1 Balmages Gettysburg FJ 2011 WV Graded Music List, p. 2 1 Balmages Majestica FJ 1 Barnes Ivory Towers of Xanadu SP 1 Bartok Castle Hungarian Folk Suite AL 1 Beethoven Clark Theme From Fifth Symphony HL 1 Beethoven Foulkes Creation's Hymn PO 1 Beethoven Henderson Hymn to Joy PO 1 Beethoven Mitchell Ode To Joy CF 1 Beethoven Sebesky Three Beethoven Miniatures Al 1 Beethoven Tolmage -

Naples, 1781-1785 New Evidence of Queenship at Court
QUEENSHIP AND POWER THE DIARY OF QUEEN MARIA CAROLINA OF NAPLES, 1781-1785 New Evidence of Queenship at Court Cinzia Recca Queenship and Power Series Editors Charles Beem University of North Carolina, Pembroke Pembroke , USA Carole Levin University of Nebraska-Lincoln Lincoln , USA Aims of the Series This series focuses on works specializing in gender analysis, women's studies, literary interpretation, and cultural, political, constitutional, and diplomatic history. It aims to broaden our understanding of the strategies that queens-both consorts and regnants, as well as female regents-pursued in order to wield political power within the structures of male-dominant societies. The works describe queenship in Europe as well as many other parts of the world, including East Asia, Sub-Saharan Africa, and Islamic civilization. More information about this series at http://www.springer.com/series/14523 Cinzia Recca The Diary of Queen Maria Carolina of Naples, 1781–1785 New Evidence of Queenship at Court Cinzia Recca University of Catania Catania , Italy Queenship and Power ISBN 978-3-319-31986-5 ISBN 978-3-319-31987-2 (eBook) DOI 10.1007/978-3-319-31987-2 Library of Congress Control Number: 2016947974 © The Editor(s) (if applicable) and The Author(s) 2017 This work is subject to copyright. All rights are solely and exclusively licensed by the Publisher, whether the whole or part of the material is concerned, specifi cally the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfi lms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. -

Creolizing Contradance in the Caribbean
Peter Manuel 1 / Introduction Contradance and Quadrille Culture in the Caribbean region as linguistically, ethnically, and culturally diverse as the Carib- bean has never lent itself to being epitomized by a single music or dance A genre, be it rumba or reggae. Nevertheless, in the nineteenth century a set of contradance and quadrille variants flourished so extensively throughout the Caribbean Basin that they enjoyed a kind of predominance, as a common cultural medium through which melodies, rhythms, dance figures, and per- formers all circulated, both between islands and between social groups within a given island. Hence, if the latter twentieth century in the region came to be the age of Afro-Caribbean popular music and dance, the nineteenth century can in many respects be characterized as the era of the contradance and qua- drille. Further, the quadrille retains much vigor in the Caribbean, and many aspects of modern Latin popular dance and music can be traced ultimately to the Cuban contradanza and Puerto Rican danza. Caribbean scholars, recognizing the importance of the contradance and quadrille complex, have produced several erudite studies of some of these genres, especially as flourishing in the Spanish Caribbean. However, these have tended to be narrowly focused in scope, and, even taken collectively, they fail to provide the panregional perspective that is so clearly needed even to comprehend a single genre in its broader context. Further, most of these pub- lications are scattered in diverse obscure and ephemeral journals or consist of limited-edition books that are scarcely available in their country of origin, not to mention elsewhere.1 Some of the most outstanding studies of individual genres or regions display what might seem to be a surprising lack of familiar- ity with relevant publications produced elsewhere, due not to any incuriosity on the part of authors but to the poor dissemination of works within (as well as 2 Peter Manuel outside) the Caribbean. -

Northern Junket, Index
CTT3 I —•\ I •—I I I N D E I I X Digitized by the Internet Archive in 2011 with funding from Boston Library Consortium Member Libraries http://www.archive.org/details/northernjunketinOOpage I ND O NORTHERN JUNKI VOLUME 1. - NUMBER 1. THROUGH VOLUME 14.- NUMBER 9 APRIL 1949. THROUGH JULY 1984. RALPH PAGE - EDITOR AND PUBLISHER. INDEX Compiled and Published by Roger Knox INDEX TO NORTHERN JUNKET COPYRIGHT 1985 by Roger C. Knox Roger C. Knox 702 North Tioga Street Ithaca, NY 14850 TO THE MEMORY OF RALPH PAGE THIS WORK IS RESPECTFULLY AND AFFECTIONATELY DEDICATED "He was a very special human being." (Dave Fuller) "It was a sad day for the dance world when he passed on. He left thousands of friends, and probably hundreds of his-taught Contra-callers who will perpetuate his memory for some time to come." (Beverly B. Wilder Jr.) "All who knew him have suffered a great loss." (Lannie McQuaide) "About very few can it be truly said that 'He was a legend in his own time,' but Ralph certainly was and is such a legend. The world of dance is a richer place because he was here." (Ed Butenhof) ACKNOWLEDGEMENTS There is a danger when one starts naming those who helped in a task that someone may have been left off the "Honor Roll." To avoid that problem 1 wish to thank everyone who gave me any encouragement, advice, orders for the Index, or anything else one can imagine. I wish specifically to thank several people who played an important role in this endeavor and I will risk the wrath of someone I may have missed but who will nevertheless live in my heart forever. -

Northern Junket, Vol. 13, No. 8
rr. (MEM) Q mm // \ VOL. 13 60""-p MOB jjina Article Pare Take It Or Leave It - 1 Contradance - World's Best Bluesbreaker - 2 I Must Dance - - - 5 Smoothness In Square Dancing - - 8 Callerlab Convention - - - 13 Shop Talk - 19 News - - Zk Contra Dance - Salutation 25 Square Dance - Happy Sounds Quadrille - 26 Book & Record Reviews - - 27 Whatever Became Of Old-Time Patter? 31 Wednesday Night Fever 32 Money Musk - - 33 It 1 a Fun To Hunt - - 36 What They S^y In New Hampshire - 43 Told In The Hills - - - - **4 The Lighter Side Of Folklore *J? Family Receipts - - -53 Kitchen Snooping - - 52 m STTOJ ZALPH has a Large Selection of Folk Dance Records. Same Day Service On Mail Orders. Send for his free catalog Steve Zalph's Folk Dance Shop 101 W. 31st St. New York, N.Y. 10001 it* TAH IT OR ,<SP3S xf,---^ LEAVE IT v •! Elsewhere in this issue you. will (J\ \\ Jt'Jrhll ) \ find an account of the recent con- f-rw \,J vention in Miami of CALMIAB I98O. r*. It's difficult to find the proper words to compliment them on an extremely well convention. Somebody really did their 1 homework, J I The officers went out of their way to see that we had a good time. We didl Our thanks to Jim Mayo and the Bob Brundages for all they did for us* Attending the Convention enabled me to see at first hand trials & tribulations that CALL^RLAB is going through in order to preserve a bit sanity in square dancing, I approve of what they're trying to do but believe that it is a hope- less + ask# The whole modern square dance movement is ba<- snd on complete artificiallity! . -

Yamaha – Pianosoft Solo 29
YAMAHA – PIANOSOFT SOLO 29 SOLO COLLECTIONS ARTIST SERIES JOHN ARPIN – SARA DAVIS “A TIME FOR LOVE” BUECHNER – MY PHILIP AABERG – 1. A Time for Love 2. My Foolish FAVORITE ENCORES “MONTANA HALF LIGHT” Heart 3. As Time Goes By 4.The 1. Jesu, Joy Of Man’s Desiring 1. Going to the Sun 2. Montana Half Light 3. Slow Dance More I See You 5. Georgia On 2. “Bach Goes to Town” 4.Theme for Naomi 5. Marias River Breakdown 6.The Big My Mind 6. Embraceable You 3. Chanson 4. Golliwog’s Cake Open 7. Madame Sosthene from Belizaire the Cajun 8. 7. Sophisticated Lady 8. I Got It Walk 5. Contradance Diva 9. Before Barbed Wire 10. Upright 11. The Gift Bad and That Ain’t Good 9. 6. La Fille Aux Cheveux De Lin 12. Out of the Frame 13. Swoop Make Believe 10.An Affair to Remember (Our Love Affair) 7. A Giddy Girl 8. La Danse Des Demoiselles 00501169 .................................................................................$34.95 11. Somewhere Along the Way 12. All the Things You Are 9. Serenade Op. 29 10. Melodie Op. 8 No. 3 11. Let’s Call 13.Watch What Happens 14. Unchained Melody the Whole Thing Off A STEVE ALLEN 00501194 .................................................................................$34.95 00501230 .................................................................................$34.95 INTERLUDE 1. The Song Is You 2. These DAVID BENOIT – “SEATTLE MORNING” SARA DAVIS Foolish Things (Remind Me of 1. Waiting for Spring 2. Kei’s Song 3. Strange Meadowlard BUECHNER PLAYS You) 3. Lover Man (Oh Where 4. Linus and Lucy 5. Waltz for Debbie 6. Blue Rondo a la BRAHMS Can You Be) 4. -

7. Reception of Nineteenth-Century Couple Dances in Hungary 179
WALTZING THROUGH EUROPE B ALTZING HROUGH UROPE Attitudes towards Couple Dances in the AKKA W T E Long Nineteenth-Century Attitudes towards Couple Dances in the Long Nineteenth-Century EDITED BY EGIL BAKKA, THERESA JILL BUCKLAND, al. et HELENA SAARIKOSKI AND ANNE VON BIBRA WHARTON From ‘folk devils’ to ballroom dancers, this volume explores the changing recep� on of fashionable couple dances in Europe from the eighteenth century onwards. A refreshing interven� on in dance studies, this book brings together elements of historiography, cultural memory, folklore, and dance across compara� vely narrow but W markedly heterogeneous locali� es. Rooted in inves� ga� ons of o� en newly discovered primary sources, the essays aff ord many opportuni� es to compare sociocultural and ALTZING poli� cal reac� ons to the arrival and prac� ce of popular rota� ng couple dances, such as the Waltz and the Polka. Leading contributors provide a transna� onal and aff ec� ve lens onto strikingly diverse topics, ranging from the evolu� on of roman� c couple dances in Croa� a, and Strauss’s visits to Hamburg and Altona in the 1830s, to dance as a tool of T cultural preserva� on and expression in twen� eth-century Finland. HROUGH Waltzing Through Europe creates openings for fresh collabora� ons in dance historiography and cultural history across fi elds and genres. It is essen� al reading for researchers of dance in central and northern Europe, while also appealing to the general reader who wants to learn more about the vibrant histories of these familiar dance forms. E As with all Open Book publica� ons, this en� re book is available to read for free on the UROPE publisher’s website. -

American Square Dance Vol. 40, No. 5
AMERICAN SIJURREORNCE, Single Copy $1.00 MAV Annual $9.00 DIXIE DAISY THE STORE WHERE SQUARE DANCERS LIKE TO SHOP No. 125 White Blouse with White Lace DANCER Trim. Adjustable Ideal for Round Dancers; 1 Heel, Drawstring, S.M All Leather, Cushioned Insole for L.XL, $16.50 Comfort. 5.10 Narrow; 4.10 Medium; 5.10 Wide. Additional Color Cords-50c White/Black $32.50 Red/NavylBrown $32.50 Silver/Gold 535.00 WESTERN STYLE SHIRTS FOR MEN AND WOMEN $14.50 And Up WESTERN DRESS PANTS BY "RANCH" $28.50 THE FOUR B'S MAJESTIC 1" heel, steel shank, glove leather, BOOTS lined. 5 thru 12 Narrow. 4 lhru 12 Med BELTS 5.10 Wide, Hall Sizes. BUCKLES Black/White 528.50 Red/Navy/Brown $28.50 BOLOS Gold/Silver $30.00 N•21 N24 Cotton/Poly Nylon Mid thigh length Shorty length S.M-L.XL S.M.L•XL 510.00 510.00 SCOOP N•20 SISSY Nylon heel, steel shank, glove leather. N-29 SISSY Cotton-Poly lined, sizes 4 thru 10 Med., 5 thru 10 S.M-L-XL Narrow, also Wide. Hall Sizes. S875 Black/White $30.00 Red/Navy/Brown $30.00 $1.85 postage Gold/Silver $30.50 & handling NAME DIXIE DAISY ADDRESS CITY STATE_ ZIP 1351 Odenton Rd. NAME & NO. OF ITEMS Price Odenton MD 21113 SHIPPING & HANDLING Maryland Residents add 5% tax. TOTAL AMERICAN CO VOLUME 40, Number 5 SQURRE DANCE MAY 1985 THE NATIONAL MAGAZINE 40th ANNIVERSARY YEAR WITH THE SWINGING LINES PA PA PA PA PA PA RA PA PA RA PA PA PA PA PA PA PA PA PA PA PA IUI PA RA Man PA • ASD FEATURES FOR ALL ROUNDS 23 Vine-Sense 4 Co-Editorial 51 Cue Tips 7 Meanderings 53 Facing the L.O.D. -
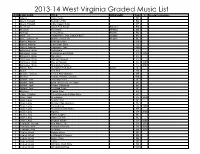
2013-14 West Virginia Graded Music List LEVEL COMPOSER TITLE ARRANGER Pub
2013-14 West Virginia Graded Music List LEVEL COMPOSER TITLE ARRANGER Pub. © Special Instuctions 1 Adams Valse Petite SP 1 Akers, Howard Berkshire Hills BO 1 Akers, Howard Little Classic Suite CF 1 Aleicheim Israeli Folk Songs Schaffer PO 1 Arcadelt Ave Maria Whiting EM 1 Arensky The Cuckoo Powell PO 1 Bach, J.S. Grand Finale from Cantata #207 Gordon BO 1 Bain, James L. M Brother James' Air Wagner BE 1 Balent, Andrew Bold Adventure WB 1 Balent, Andrew Little Brazil Suite LU 1 Balent, Andrew Lonesome Tune WB 1 Balmages, Brian Gettysburg FJ 1 Balmages, Brian Incantation and Ritual FJ 2004 1 Balmages, Brian Majestica FJ 1 Balmages, Brian Midnight Mission FJ 1 Balmages, Brian Rite of Passage FJ 2000 1 Balmages, Brian Starsplitter Fanfare FJ 2009 1 Bartok, Bela Hungarian Folk Suite Castle AL 1 Braun Cha Cha YM 1 Broege, Timothy Theme And Variation MB 1 Buchtel Fortune Promise Overture WB 1 Bullock, Jack Amazing Grace BE 1 Bullock, Jack Ev'ry Time I Feel The Spirit BE 1 Bullock, Jack Festive Variations BE 1 Bullock, Jack The Bald Eagle BE 1 Burgess Capital Ship PO 1 Carter, Charles Three Pieces in Antique Style CF 1 Clark, Clark Shockwave CF 2008 1 Clark, Larry Autumn Mist BE 1 Clark, Larry Breckenridge Overture HL 1 Clark, Larry Contredanse AL 1998 1 Clark, Larry Declaration And Dance BE 1 Clark, Larry Magma CF 2006 1 Clark, Larry Mystic Legacy BE 1 Clark, Larry Paseo Del Rio HL 1 Clark, Larry Scottish Bobber CF 2006 1 Compello, Joseph Red Planet, The CF 2011 1 Conaway, Matt Dreams of Victory BA 2011 1 Conaway, Matt Eventide BA 2011 1 Conley, Lloyd Dakota Hymn SP 1 Conley, Lloyd In Midnight's Silence KE 1 Conley, Lloyd Kemo, Kimo KE 1 Conley, Lloyd Lullay SP 1 Conley, Lloyd Miniature Bach Suite KN 1 Conley, Lloyd On Land And Sea MW 2013-14 West Virginia Graded Music List LEVEL COMPOSER TITLE ARRANGER Pub. -

Calamus Document
Verlag Doh r Köl n Gesamtverzeichnis 201 5 Vorbemerkungen Redaktionsschluss dieses Verzeichnisses: 21. Januar 2015. Sämtliche Preise sind in EURO angegeben und beinhalten die jeweilige deutsche Mehrwertsteuer. Mit Inkrafttreten dieses Gesamtverzeichnisses 2015 (1. Februar 2015) werden alle frühe- ren Preisangaben ungültig. Noten und Bücher des Verlages Dohr unterliegen, soweit es sich um Kaufausgaben handelt, der Ladenpreisbindung. Dieses Verzeichnis enthält alle lieferbaren Ausgaben; Bestellun- genwerdeninnerhalbvon24StundennachEingangbeimVerlag bearbeitet und lieferbare Titel auf dem Postwege abgesandt; es erscheinen monatlich neue Titel. Über diese Neuerscheinungen informieren Sie unser NOVA-Dienst und unsere Website unter www.dohr.de/nova.htm Preisangabe: **,-- = in Vorbereitung Verlag Dohr im Internet: Das kontinuierlich aktualisierte Ver- lagsprogramm mit detaillierten Informationen zu vielen Werken und zu allen Autoren findet sich im Internet unter www.dohr.de ISBN-Stamm: 3-925366; 3-936655; 3-86846 ISMN-Stamm: M-2020; M-50024 Verkehrs-Nr.: 12827 BAG Auslieferung an den Fachhandel durch Verlag Christoph Dohr − „Haus Eller“ Sindorfer Straße 19 − D-50127 Bergheim Tel.: +49 (0) 2271 / 70 72 05 Fax: +49 (0) 2271 / 70 72 07 Internet: http://www.dohr.de E-Mail: [email protected] Exclusive distribution to UK and Ireland by UE London; non-exclusive distribution to all other non-German-speaking countries by UE London. Der Bezug für den Fachhandel ist direkt bei der Auslieferung Abkürzungen: des Verlages Dohr, über die Musikgroßsortimente und Umbreit, aktuelle Buchtitel zudem über KNV möglich. ChP Chorpartitur P. Pa rt it u r Bei Liefer- und Bezugsproblemen wenden Sie sich bitte KlA Klavierauszug unmittelbar an den Verlag Dohr. Wir liefern täglich aus. SpP Spielpartitur Preisänderung und Irrtum vorbehalten. -

Louis Moreau Gottschalk (1829-1869): the Role of Early Exposure to African-Derived Musics in Shaping an American Musical Pioneer from New Orleans
LOUIS MOREAU GOTTSCHALK (1829-1869): THE ROLE OF EARLY EXPOSURE TO AFRICAN-DERIVED MUSICS IN SHAPING AN AMERICAN MUSICAL PIONEER FROM NEW ORLEANS A dissertation submitted to the College of the Arts of Kent State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy by Amy Elizabeth Unruh December, 2009 © Amy Elizabeth Unruh, 2009 Dissertation written by Amy Elizabeth Unruh B.A., Bowling Green State University, 1998 B.F.A., Bowling Green State University, 1998 M.M., Bowling Green State University, 2000 Ph.D., Kent State University, 2009 Approved by ________________________ , Co-Chair, Doctoral Dissertation Committee Terry E. Miller ________________________ , Co-Chair, Doctoral Dissertation Committee John M. Lee ________________________ , Members, Doctoral Dissertation Committee Richard O. Devore ________________________ , Richard Feinberg Accepted by ________________________ , Interim Director, School of Music Denise A. Seachrist ________________________ , Interim Dean, College of the Arts John Crawford ii TABLE OF CONTENTS TABLE OF CONTENTS ................................................................................................... iii LIST OF FIGURES ........................................................................................................... vi PREFACE ........................................................................................................................ viii CHAPTER I. INTRODUCTION .............................................................................................1