Optimized Client-Server Distribution of Ajax Web Applications Research Internship Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Expanding the Power of Csound with Integrated Html and Javascript
Michael Gogins. Expanding the Power of Csound with Intergrated HTML and JavaScript EXPANDING THE POWER OF CSOUND WITH INTEGRATED HTML AND JAVA SCRIPT Michael Gogins [email protected] https://michaelgogins.tumblr.com http://michaelgogins.tumblr.com/ This paper presents recent developments integrating Csound [1] with HTML [2] and JavaScript [3, 4]. For those new to Csound, it is a “MUSIC N” style, user- programmable software sound synthesizer, one of the first yet still being extended, written mostly in the C language. No synthesizer is more powerful. Csound can now run in an interactive Web page, using all the capabilities of current Web browsers: custom widgets, 2- and 3-dimensional animated and interactive graphics canvases, video, data storage, WebSockets, Web Audio, mathematics typesetting, etc. See the whole list at HTML5 TEST [5]. Above all, the JavaScript programming language can be used to control Csound, extend its capabilities, generate scores, and more. JavaScript is the “glue” that binds together the components and capabilities of HTML5. JavaScript is a full-featured, dynamically typed language that supports functional programming and prototype-based object- oriented programming. In most browsers, the JavaScript virtual machine includes a just- in-time compiler that runs about 4 times slower than compiled C, very fast for a dynamic language. JavaScript has limitations. It is single-threaded, and in standard browsers, is not permitted to access the local file system outside the browser's sandbox. But most musical applications can use an embedded browser, which bypasses the sandbox and accesses the local file system. HTML Environments for Csound There are two approaches to integrating Csound with HTML and JavaScript. -
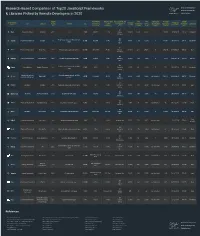
Research-Based Comparison of Top20 Javascript Frameworks & Libraries Picked by Remote Developers in 2020
Research-Based Comparison of Top20 JavaScript Frameworks & Libraries Picked by Remote Developers in 2020 Original # of Websites # of Devs Used Top 3 Countries with # of # of Ranking on # of Open Average JS Frameworks/ # of Stars Average Dev Type Founded by Release Ideal for Size Powered by a It (2019, the Highest % of Contributors Forks on Stack Overflow Vacancies on Hourly Rate Learnability Libraries on GitHub Salary (USA) Year Framework Worldwide) Usage on GitHub GitHb (2019) LinkedIn (USA) US React JavaScript library Facebook 2011 UI 133KB 380,164 71.7% Russia 146,000 1,373 28,300 1 130,300 $91,000.00 $35.19 Moderate Germany US Single-page apps and dynamic web Angular Front-end framework Google 2016 566KB 706,489 21.9% UK 59,000 1,104 16,300 2 94,282 $84,000.00 $39.14 Moderate apps Brazil US Vue.js Front-end framework Evan You 2014 UI and single-page applications 58.8KB 241,б615 40.5% Russia 161,000 291 24,300 5 27,395 $116,562.00 $42.08 Easy Germany US Ember.js Front-end framework Yehuda Katz 2011 Scalable single-page web apps 435KB 20,985 3.6% Germany 21,400 782 4,200 8 3,533 $105,315.00 $51.00 Difficult UK US Scalable web, mobile and desktop Meteor App platform Meteor Software 2012 4.2MB 8,674 4% Germany 41,700 426 5,100 7 256 $96,687.00 $27.92 Moderate apps France US JavaScript runtime Network programs, such as Web Node.js Ryan Dahl 2009 141KB 1,610,630 49.9% UK 69,000 2,676 16,600 not included 52,919 $104,964.00 $33.78 Moderate (server) environment servers Germany US Polymer JS library Google 2015 Web apps using web components -

Readme for 3Rd Party Software FIN Framework
Smart Infrastructure Note to Resellers: Please pass on this document to your customer to avoid license breach and copyright infringements. Third-Party Software Information for FIN Framework 5.0.7 J2 Innovations Inc. is a Siemens company and is referenced herein as SIEMENS. This product, solution or service ("Product") contains third-party software components listed in this document. These components are Open Source Software licensed under a license approved by the Open Source Initiative (www.opensource.org) or similar licenses as determined by SIEMENS ("OSS") and/or commercial or freeware software components. With respect to the OSS components, the applicable OSS license conditions prevail over any other terms and conditions covering the Product. The OSS portions of this Product are provided royalty-free and can be used at no charge. If SIEMENS has combined or linked certain components of the Product with/to OSS components licensed under the GNU LGPL version 2 or later as per the definition of the applicable license, and if use of the corresponding object file is not unrestricted ("LGPL Licensed Module", whereas the LGPL Licensed Module and the components that the LGPL Licensed Module is combined with or linked to is the "Combined Product"), the following additional rights apply, if the relevant LGPL license criteria are met: (i) you are entitled to modify the Combined Product for your own use, including but not limited to the right to modify the Combined Product to relink modified versions of the LGPL Licensed Module, and (ii) you may reverse-engineer the Combined Product, but only to debug your modifications. -

Secrets of the Javascript Ninja
Secrets of the JavaScript Ninja JOHN RESIG BEAR BIBEAULT MANNING SHELTER ISLAND For online information and ordering of this and other Manning books, please visit www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact Special Sales Department Manning Publications Co. 20 Baldwin Road PO Box 261 Shelter Island, NY 11964 Email: [email protected] ©2013 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Recognizing also our responsibility to conserve the resources of our planet, Manning books are printed on paper that is at least 15 percent recycled and processed without the use of elemental chlorine. Manning Publications Co. Development editors: Jeff Bleiel, Sebastian Stirling 20 Baldwin Road Technical editor: Valentin Crettaz PO Box 261 Copyeditor: Andy Carroll Shelter Island, NY 11964 Proofreader: Melody Dolab Typesetter: Dennis Dalinnik Cover designer: Leslie Haimes ISBN: 978-1-933988-69-6 Printed in the United States of America 1 2 3 4 5 6 7 8 9 10 – MAL – 18 17 16 15 14 13 12 brief contents PART 1 PREPARING FOR TRAINING. -

John Resig About Me
Coder Day of Service John Resig About Me • Lots of Open Source work • jQuery, Processing.js, other projects! • Worked at Mozilla (Non-profit, Open Source) • Working at Khan Academy (Non-profit, free content, some Open Source) jQuery Beginnings • Library for making JavaScript easier to write. • Created it in 2005 • While I was in college! • I hated cross-browser inconsistencies • Also really dis-liked the DOM jQuery’s Growth • Released in 2006 • Slowly grew for many years • Started to explode in 2009 • Drupal, Microsoft, Wordpress, Adobe all use jQuery • Currently used by 70% of the top 10,000 web sites on the web. Full-time • From 2009 to 2011 got funding from Mozilla (my employer) • Worked on jQuery full-time! • Built up the jQuery Foundation (non-profit) Letting Go • Decided to step down to focus on building applications • Moved to Khan Academy! • jQuery Foundation runs everything now • They do a really good job :) Open Source/Open Data Tips Don’t be try to be perfect. Non-code things are just as important as code. Your community will mimic you. Benefits of Open Source/Open Data You use Open Source, why not give back? People will do projects you don’t have time for. You’ll attract interesting developers. ...which can lead to hiring good developers! Khan Academy Stats • 3 million problems practiced per day • 300 million lessons delivered • 100,000 educators around the world • 10 million students per month Khan API • Access to all data and user info • (with proper authentication) • You can access: • Videos + video data • All nicely organized • Exercise data • Student logs Data Analysis iPhone Application Exercises Exercises Exercise Racer Museums and Libraries Museums and Libraries • Cultural institutions • (Typically) Free for all • (Typically) Non-profits • They can use our help! Ukiyo-e.org Helping Public Institutions • Brooklyn Museum • New York Public Library • Digital Public Library of America • ...and many more! • All have public, free, open, APIs!. -

Secrets of the Javascript Ninja.Pdf
MEAP Edition Manning Early Access Program Copyright 2008 Manning Publications For more information on this and other Manning titles go to www.manning.com Contents Preface Part 1 JavaScript language Chapter 1 Introduction Chapter 2 Functions Chapter 3 Closures Chapter 4 Timers Chapter 5 Function prototype Chapter 6 RegExp Chapter 7 with(){} Chapter 8 eval Part 2 Cross-browser code Chapter 9 Strategies for cross-browser code Chapter 10 CSS Selector Engine Chapter 11 DOM modification Chapter 12 Get/Set attributes Chapter 13 Get/Set CSS Chapter 14 Events Chapter 15 Animations Part 3 Best practices Chapter 16 Unit testing Chapter 17 Performance analysis Chapter 18 Validation Chapter 19 Debugging Chapter 20 Distribution 1 Introduction Authorgroup John Resig Legalnotice Copyright 2008 Manning Publications Introduction In this chapter: Overview of the purpose and structure of the book Overview of the libraries of focus Explanation of advanced JavaScript programming Theory behind cross-browser code authoring Examples of test suite usage There is nothing simple about creating effective, cross-browser, JavaScript code. In addition to the normal challenge of writing clean code you have the added complexity of dealing with obtuse browser complexities. To counter-act this JavaScript developers frequently construct some set of common, reusable, functionality in the form of JavaScript library. These libraries frequently vary in content and complexity but one constant remains: They need to be easy to use, be constructed with the least amount of overhead, and be able to work in all browsers that you target. It stands to reason, then, that understanding how the very best JavaScript libraries are constructed and maintained can provide great insight into how your own code can be constructed. -

Mechanizing Webassembly Proposals
University of Wisconsin Milwaukee UWM Digital Commons Theses and Dissertations August 2020 Mechanizing Webassembly Proposals Jacob Richard Mischka University of Wisconsin-Milwaukee Follow this and additional works at: https://dc.uwm.edu/etd Part of the Computer Sciences Commons Recommended Citation Mischka, Jacob Richard, "Mechanizing Webassembly Proposals" (2020). Theses and Dissertations. 2565. https://dc.uwm.edu/etd/2565 This Thesis is brought to you for free and open access by UWM Digital Commons. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of UWM Digital Commons. For more information, please contact [email protected]. MECHANIZING WEBASSEMBLY PROPOSALS by Jacob Mischka A Dissertation Submitted in Partial Fulfillment of the Requirements for the degree of Master of Science in Computer Science at The University of Wisconsin-Milwaukee August 2020 ABSTRACT MECHANIZING WEBASSEMBLY PROPOSALS by Jacob Mischka The University of Wisconsin-Milwaukee, 2020 Under the Supervision of Professor John Boyland WebAssembly is a modern low-level programming language designed to provide high performance and security. To enable these goals, the language specifies a relatively small number of low-level types, instructions, and lan- guage constructs. The language is proven to be sound with respect to its types and execution, and a separate mechanized formalization of the specifi- cation and type soundness proofs confirms this. As an emerging technology, the language is continuously being developed, with modifications being pro- posed and discussed in the open and on a frequent basis. ii In order to ensure the soundness properties exhibited by the original core language are maintained as WebAssembly evolves, these proposals should too be mechanized and verified to be sound. -

Notices: License License Text Libraries Copyright Notices
This application uses certain open source software. As required by the terms of the open source license applicable to such open source software, we are providing you with the following notices: License License Text Libraries Copyright Notices ISC ISC License Copyright (c) 2004-2010 by Internet abab-1.0.4.tgz Copyright © 2019 W3C and Jeff Carpenter Systems Consortium, Inc. ("ISC") Copyright (c) Isaac Z. Schlueter and Copyright (c) 1995-2003 by Internet Software abbrev-1.1.1.tgz Consortium Contributors Copyright Isaac Z. Schlueter Permission to use, copy, modify, and /or distribute anymatch-2.0.0.tgz Copyright 2014 Elan Shanker this software for any purpose with or without fee is hereby granted, provided that the above copyright notice and this permission notice appear in all Copyright 2019 Elan Shanker, Paul Miller anymatch-3.1.1.tgz copies. (https://paulmillr.com) THE SOFTWARE IS PROVIDED "AS IS" AND ISC DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE INCLUDING aproba-1.2.0.tgz Copyright 2015 Rebecca Turner ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL ISC BE LIABLE FOR ANY are-we-there-yet-1.1.5.tgz Copyright 2015 Rebecca Turner SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, ast-types-flow-0.0.7.tgz Copyright (c) 2018 Kyle Davis NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE. block-stream-0.0.9.tgz Copyright Isaac Z Copyright Isaac -

Bigfix Lifecycle Starter Kit Open Source Licenses and Notices
---------------------------------- BigFix Lifecycle StarterKit 10.0 Jan 2021 ---------------------------------- ------------------------------------------------------------------------- ------------------------------------------------------------------------- The HCL license agreement and any applicable information on the web download page for HCL products refers Licensee to this file for details concerning notices applicable to code included in the products listed above ("the Program"). Notwithstanding the terms and conditions of any other agreement Licensee may have with HCL or any of its related or affiliated entities (collectively "HCL"), the third party code identified below is subject to the terms and conditions of the HCL license agreement for the Program and not the license terms that may be contained in the notices below. The notices are provided for informational purposes. Please note: This Notices file may identify information that is not used by, or that was not shipped with, the Program as Licensee installed it. IMPORTANT: HCL does not represent or warrant that the information in this NOTICES file is accurate. Third party websites are independent of HCL and HCL does not represent or warrant that the information on any third party website referenced in this NOTICES file is accurate. HCL disclaims any and all liability for errors and omissions or for any damages accruing from the use of this NOTICES file or its contents, including without limitation URLs or references to any third party websites. ------------------------------------------------------------------------- -

Client-Server Web Apps with Javascript and Java
Client-Server Web Apps with JavaScript and Java Casimir Saternos Client-Server Web Apps with JavaScript and Java by Casimir Saternos Copyright © 2014 EzGraphs, LLC. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/ institutional sales department: 800-998-9938 or [email protected]. Editors: Simon St. Laurent and Allyson MacDonald Indexer: Judith McConville Production Editor: Kristen Brown Cover Designer: Karen Montgomery Copyeditor: Gillian McGarvey Interior Designer: David Futato Proofreader: Amanda Kersey Illustrator: Rebecca Demarest April 2014: First Edition Revision History for the First Edition: 2014-03-27: First release See http://oreilly.com/catalog/errata.csp?isbn=9781449369330 for release details. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. Client-Server Web Apps with JavaScript and Java, the image of a large Indian civet, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc. was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. -

Single Page Web Applications
JavaScript end-to-end Michael S. Mikowski Josh C. Powell FOREWORD BY Gregory D. Benson SAMPLE CHAPTER MANNING Single Page Web Applications by Michael S. Mikowski and Josh C. Powell Chapter 1 Copyright 2014 Manning Publications brief contents PART 1INTRODUCING SPAS .........................................................1 1 ■ Our first single page application 3 2 ■ Reintroducing JavaScript 23 PART 2THE SPA CLIENT ...........................................................59 3 ■ Develop the Shell 61 4 ■ Add feature modules 95 5 ■ Build the Model 139 6 ■ Finish the Model and Data modules 178 PART 3THE SPA SERVER .........................................................227 7 ■ The web server 229 8 ■ The server database 265 9 ■ Readying our SPA for production 313 vii Part 1 Introducing SPAs In the time it takes to read this page, 35 million person minutes will be spent waiting for traditional website pages to load. That’s enough spinning icon time for the Curiosity Lander to fly to Mars and back 96 times. The productivity cost of traditional websites is astonishing, and the cost to a business can be devastat- ing. A slow website can drive users away from your site—and into the welcoming wallets of smiling competitors. One reason traditional websites are slow is because popular MVC server frameworks are focused on serving page after page of static content to an essen- tially dumb client. When we click a link in a traditional website slideshow, for example, the screen flashes white and everything reloads over several seconds: the navigation, ads, headlines, text, and footer are all rendered again. Yet the only thing that changes is the slideshow image and perhaps the description text. -

Project Report the Design and Implementation of 'Cap': a Compile
Project Report The Design and Implementation of ‘Cap’: A Compile-to-JavaScript Programming Language School of Engineering and Informatics, University of Sussex Student: Ben Gourley Supervisor: Martin Berger 2011-2012 2 Statement of Originality This report is submitted as part requirement for the degree of Internet Computing at the University of Sussex. It is the product of my own labour except where indicated in the text. The report may be freely copied and distributed provided the source is acknowledged. Signed: Date: Ben Gourley Cap: A Compile-to-JavaScript Programming Language 3 Acknowledgements I would like to acknowledge the support of the following people/organisations in relation to this project: Martin Berger Martin acted as project supervisor, offering feedback and guidance throughout the project. His knowledge in the field of programming language design was invaluable. Des Watson Des taught the compilers course that I took in my second year; much of the learning outcomes of which were used directly in this project. Des also provided help in the early stages of my complier implementation. Clock Ltd. Clock employed me as an intern front-end web developer. The experi- ences there gave me the inspiration for this project. Cara Haines I would like to thank my girlfriend for her support during the project. Ben Gourley Cap: A Compile-to-JavaScript Programming Language CONTENTS 4 Contents 1 Introduction 7 1.1 Project Aims . .7 1.2 Report Structure . .7 2 Professional Considerations 8 3 Background 10 3.1 JavaScript . 10 3.1.1 Overview . 10 3.1.2 History and Evolution . 10 3.1.3 Features .