Java Bytecode to Native Code Translation: the Caffeine Prototype and Preliminary Results
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Database Licensing Information, 11G Release 2 (11.2) E10594-26
Oracle® Database Licensing Information 11g Release 2 (11.2) E10594-26 July 2012 Oracle Database Licensing Information, 11g Release 2 (11.2) E10594-26 Copyright © 2004, 2012, Oracle and/or its affiliates. All rights reserved. Contributor: Manmeet Ahluwalia, Penny Avril, Charlie Berger, Michelle Bird, Carolyn Bruse, Rich Buchheim, Sandra Cheevers, Leo Cloutier, Bud Endress, Prabhaker Gongloor, Kevin Jernigan, Anil Khilani, Mughees Minhas, Trish McGonigle, Dennis MacNeil, Paul Narth, Anu Natarajan, Paul Needham, Martin Pena, Jill Robinson, Mark Townsend This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. -

The Performance Paradox of the JVM: Why More Hardware Means More
Expert Tip The Performance Paradox of the JVM: Why More Hardware Means More As computer hardware gets cheaper and faster, administrators managing Java based servers are frequently encountering serious problems when managing their runtime environments. JVM handles the task of garbage collection for the developer - cleaning up the space a developer has allocated for objects once an instance no longer has any references pointing to it. Some garbage collection is done quickly and invisibly. But certain sanitation tasks, which fortunately occur with minimal frequency, take significantly longer, causing the JVM to pause, and raising the ire of end users and administrators alike. Read this TheServerSide.com Expert Tip to better understand the JVM performance problem, how the JVM manages memory and how best to approach JVM Performance. Sponsored By: TheServerSide.com Expert Tip The Performance Paradox of the JVM: Why More Hardware Means More Expert Tip The Performance Paradox of the JVM: Why More Hardware Means More Table of Contents The Performance Paradox of the JVM: Why More Hardware Means More Failures Resources from Azul Systems Sponsored By: Page 2 of 8 TheServerSide.com Expert Tip The Performance Paradox of the JVM: Why More Hardware Means More The Performance Paradox of the JVM: Why More Hardware Means More Failures By Cameron McKenzie The Problem of the Unpredictable Pause As computer hardware gets cheaper and faster, administrators managing Java based servers are frequently encountering serious problems when managing their runtime environments. While our servers are getting decked out with faster and faster hardware, the Java Virtual Machines (JVMs) that are running on them can't effectively leverage the extra hardware without hitting a wall and temporarily freezing. -

Java (Programming Langua a (Programming Language)
Java (programming language) From Wikipedia, the free encyclopedialopedia "Java language" redirects here. For the natural language from the Indonesian island of Java, see Javanese language. Not to be confused with JavaScript. Java multi-paradigm: object-oriented, structured, imperative, Paradigm(s) functional, generic, reflective, concurrent James Gosling and Designed by Sun Microsystems Developer Oracle Corporation Appeared in 1995[1] Java Standard Edition 8 Update Stable release 5 (1.8.0_5) / April 15, 2014; 2 months ago Static, strong, safe, nominative, Typing discipline manifest Major OpenJDK, many others implementations Dialects Generic Java, Pizza Ada 83, C++, C#,[2] Eiffel,[3] Generic Java, Mesa,[4] Modula- Influenced by 3,[5] Oberon,[6] Objective-C,[7] UCSD Pascal,[8][9] Smalltalk Ada 2005, BeanShell, C#, Clojure, D, ECMAScript, Influenced Groovy, J#, JavaScript, Kotlin, PHP, Python, Scala, Seed7, Vala Implementation C and C++ language OS Cross-platform (multi-platform) GNU General Public License, License Java CommuniCommunity Process Filename .java , .class, .jar extension(s) Website For Java Developers Java Programming at Wikibooks Java is a computer programming language that is concurrent, class-based, object-oriented, and specifically designed to have as few impimplementation dependencies as possible.ble. It is intended to let application developers "write once, run ananywhere" (WORA), meaning that code that runs on one platform does not need to be recompiled to rurun on another. Java applications ns are typically compiled to bytecode (class file) that can run on anany Java virtual machine (JVM)) regardless of computer architecture. Java is, as of 2014, one of tthe most popular programming ng languages in use, particularly for client-server web applications, witwith a reported 9 million developers.[10][11] Java was originallyy developed by James Gosling at Sun Microsystems (which has since merged into Oracle Corporation) and released in 1995 as a core component of Sun Microsystems'Micros Java platform. -

The Java® Language Specification Java SE 8 Edition
The Java® Language Specification Java SE 8 Edition James Gosling Bill Joy Guy Steele Gilad Bracha Alex Buckley 2015-02-13 Specification: JSR-337 Java® SE 8 Release Contents ("Specification") Version: 8 Status: Maintenance Release Release: March 2015 Copyright © 1997, 2015, Oracle America, Inc. and/or its affiliates. 500 Oracle Parkway, Redwood City, California 94065, U.S.A. All rights reserved. Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners. The Specification provided herein is provided to you only under the Limited License Grant included herein as Appendix A. Please see Appendix A, Limited License Grant. To Maurizio, with deepest thanks. Table of Contents Preface to the Java SE 8 Edition xix 1 Introduction 1 1.1 Organization of the Specification 2 1.2 Example Programs 6 1.3 Notation 6 1.4 Relationship to Predefined Classes and Interfaces 7 1.5 Feedback 7 1.6 References 7 2 Grammars 9 2.1 Context-Free Grammars 9 2.2 The Lexical Grammar 9 2.3 The Syntactic Grammar 10 2.4 Grammar Notation 10 3 Lexical Structure 15 3.1 Unicode 15 3.2 Lexical Translations 16 3.3 Unicode Escapes 17 3.4 Line Terminators 19 3.5 Input Elements and Tokens 19 3.6 White Space 20 3.7 Comments 21 3.8 Identifiers 22 3.9 Keywords 24 3.10 Literals 24 3.10.1 Integer Literals 25 3.10.2 Floating-Point Literals 31 3.10.3 Boolean Literals 34 3.10.4 Character Literals 34 3.10.5 String Literals 35 3.10.6 Escape Sequences for Character and String Literals 37 3.10.7 The Null Literal 38 3.11 Separators -

Third-Party License Acknowledgments
Symantec Privileged Access Manager Third-Party License Acknowledgments Version 3.4.3 Symantec Privileged Access Manager Third-Party License Acknowledgments Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. Copyright © 2021 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. 2 Symantec Privileged Access Manager Third-Party License Acknowledgments Contents Activation 1.1.1 ..................................................................................................................................... 7 Adal4j 1.1.2 ............................................................................................................................................ 7 AdoptOpenJDK 1.8.0_282-b08 ............................................................................................................ 7 Aespipe 2.4e aespipe ........................................................................................................................ -

Bibliography of Concrete Abstractions: an Introduction To
Out of print; full text available for free at http://www.gustavus.edu/+max/concrete-abstractions.html Bibliography [1] Harold Abelson, Gerald J. Sussman, and friends. Computer Exercises to Accom- pany Structure and Interpretation of Computer Programs. New York: McGraw- Hill, 1988. [2] Harold Abelson and Gerald Jay Sussman. Structure and Interpretation of Com- puter Programs. Cambridge, MA: The MIT Press and New York: McGraw-Hill, 2nd edition, 1996. [3] Alfred V. Aho and Jeffrey D. Ullman. Foundations of Computer Science.New York: Computer Science Press, 1992. [4] Ronald E. Anderson, Deborah G. Johnson, Donald Gotterbarn, and Judith Perville. Using the new ACM code of ethics in decision making. Communica- tions of the ACM, 36(2):98±107, February 1993. [5] Ken Arnold and James Gosling. The Java Programming Language. Reading, MA: Addison-Wesley, 2nd edition, 1998. [6] Henk Barendregt. The impact of the lambda calculus in logic and computer science. The Bulletin of Symbolic Logic, 3(2):181±215, June 1997. [7] Grady Booch. Object-oriented Analysis and Design with Applications.Menlo Park, CA: Benjamin/Cummings, 2nd edition, 1994. [8] Charles L. Bouton. Nim, a game with a complete mathematical theory. The Annals of Mathematics, 3:35±39, 1901. Series 2. [9] Mary Campione and Kathy Walrath. The Java Tutorial: Object-Oriented Pro- gramming for the Internet. Reading, MA: Addison-Wesley, 2nd edition, 1998. Excerpted from Concrete Abstractions; copyright © 1999 by Max Hailperin, Barbara Kaiser, and Karl Knight 649 650 Bibliography [10] Canadian Broadcasting Company. Quirks and quarks. Radio program, Decem- ber 19, 1992. Included chocolate bar puzzle posed by Dr. -
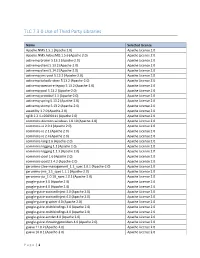
TLC 7.3.0 Use of Third Party Libraries
TLC 7.3.0 Use of Third Party Libraries Name Selected License Apache.NMS 1.5.1 (Apache 2.0) Apache License 2.0 Apache.NMS.ActiveMQ 1.5.6 (Apache 2.0) Apache License 2.0 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.13.2 (Apache-2.0) Apache License 2.0 activemq-stomp 5.13.2 (Apache-2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 cglib 2.2.1-v20090111 (Apache 2.0) Apache License 2.0 commons-daemon-windows 1.0.10 (Apache-2.0) Apache License 2.0 commons-io 2.0.1 (Apache 2.0) Apache License 2.0 commons-io 2.1 (Apache 2.0) Apache License 2.0 commons-io 2.4 (Apache 2.0) Apache License 2.0 commons-lang 2.6 (Apache-2.0) Apache License 2.0 commons-logging 1.1 (Apache 2.0) Apache License 2.0 commons-logging 1.1.3 (Apache 2.0) Apache License 2.0 commons-pool 1.6 (Apache 2.0) Apache License 2.0 commons-pool2 2.4.2 (Apache-2.0) Apache License 2.0 geronimo-j2ee-management_1.1_spec 1.0.1 (Apache-2.0) Apache License 2.0 geronimo-jms_1.1_spec 1.1.1 (Apache-2.0) Apache License 2.0 geronimo-jta_1.0.1B_spec 1.0.1 (Apache-2.0) Apache License 2.0 google-guice 3.0 (Apache 2.0) Apache License 2.0 google-guice 4.0 (Apache -

MARIMBA PROMOTES SIMON WYNN to CHIEF TECHNOLOGY OFFICER Submitted By: Axicom Monday, 30 April 2001
MARIMBA PROMOTES SIMON WYNN TO CHIEF TECHNOLOGY OFFICER Submitted by: AxiCom Monday, 30 April 2001 Arthur van Hoff to Head Newly-Formed Marimba Advanced Development Laboratory to Promote Technology Innovation Marimba, Inc, a leading provider of systems management solutions built for e-business, today announced the appointment of Simon Wynn to the post of chief technology officer (CTO), reporting directly to Marimba president and CEO, John Olsen. Mr. Wynn assumes the position from Arthur van Hoff, a co-founder of Marimba. Van Hoff, along with senior engineers and fellow co-founders, Sami Shaio and Jonathan Payne, will be part of Marimba's newly-formed Advanced Development Laboratory, and van Hoff will continue to report directly to Olsen. This distinguished team of engineers will focus on technology innovation designed to bring new, leading-edge products to market quickly. Van Hoff, Shaio and Payne are well known as original members of the Sun Microsystems Java team. As CTO, Wynn will be responsible for all technical aspects of Marimba's product vision, including software development, product deployment, strategic planning, new business opportunity assessment, as well as industry standards. "I am pleased to announce the promotion of Simon Wynn to the position of CTO, and we welcome him as a member of our executive team," said Olsen. "This appointment acknowledges Simon's past contributions and reflects his leadership role within the company. Simon has been instrumental in helping to secure Marimba's leadership position in the systems management market." Wynn previously held consecutive positions of director of engineering, engineering manager, and staff software engineer. -

Java (Software Platform) from Wikipedia, the Free Encyclopedia Not to Be Confused with Javascript
Java (software platform) From Wikipedia, the free encyclopedia Not to be confused with JavaScript. This article may require copy editing for grammar, style, cohesion, tone , or spelling. You can assist by editing it. (February 2016) Java (software platform) Dukesource125.gif The Java technology logo Original author(s) James Gosling, Sun Microsystems Developer(s) Oracle Corporation Initial release 23 January 1996; 20 years ago[1][2] Stable release 8 Update 73 (1.8.0_73) (February 5, 2016; 34 days ago) [±][3] Preview release 9 Build b90 (November 2, 2015; 4 months ago) [±][4] Written in Java, C++[5] Operating system Windows, Solaris, Linux, OS X[6] Platform Cross-platform Available in 30+ languages List of languages [show] Type Software platform License Freeware, mostly open-source,[8] with a few proprietary[9] compo nents[10] Website www.java.com Java is a set of computer software and specifications developed by Sun Microsyst ems, later acquired by Oracle Corporation, that provides a system for developing application software and deploying it in a cross-platform computing environment . Java is used in a wide variety of computing platforms from embedded devices an d mobile phones to enterprise servers and supercomputers. While less common, Jav a applets run in secure, sandboxed environments to provide many features of nati ve applications and can be embedded in HTML pages. Writing in the Java programming language is the primary way to produce code that will be deployed as byte code in a Java Virtual Machine (JVM); byte code compil ers are also available for other languages, including Ada, JavaScript, Python, a nd Ruby. -

Open Source Used in Cisco UCS Director 5.5
Open Source Used In Cisco UCS Director 5.5 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-116574787 Open Source Used In Cisco UCS Director 5.5 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-116574787 The product also uses the Linux operating system, Centos Full 6.7. Information on this distribution is available at http://vault.centos.org/6.7/os/Source/SPackages/. The full source code for this distribution, including copyright and license information, is available on request from [email protected]. Mention that you would like the Linux distribution source archive, and quote the following reference number for this distribution: 118610896-116574787. Contents 1.1 activemq-all 5.2.0 1.1.1 Available under license 1.2 Amazon AWS Java SDK 1.1.1 1.2.1 Available under license 1.3 ant 1.9.3 :2build1 1.3.1 Available under license 1.4 aopalliance version 1.0 repackaged as a module 2.3.0-b10 1.4.1 Available under license 1.5 Apache -

Object Oriented Programming 2016-2017
OBJECT ORIENTED PROGRAMMING 2016-2017 Bachelor Degree: Mathematics 701G Course title: Object oriented programming 828 Year/Semester: 2/1S ECTS Credits: 6 DEPARTMENT Address: CCT Building, C/ Madre de Dios 53 City: Logroño Province: La Rioja Postal code: 26007 Phone number: 941299452 Email address: ENGLISH-FRIENDLY FACULTY Name: Jesús María Aransay Azofra Phone number: 941299438 Email address: [email protected] Office: 3245 Building: CCT Name: Jónathan Heras Vicente Phone number: 941299673 Email address: [email protected] Office: 3232 Building: CCT CONTENTS 1. Objects and classes in Object Oriented programming 1.1 Representing information by means of objects 1.2 Attributes or state 1.3 Methods or behavior 1.4 Abstracting objects into classes 1.5 The need and relevance of class constructors: default constructor, user defined constructors 1.6 Access methods and how to modify the state of an object 1.7 Static or class attributes and methods 1.8 Access modifiers: the need for public and private modifiers 1.9 Information hiding: different ways to represent an object without modifying its behavior 1.10 Introduction to UML: representation of objects and classes 1.11 C++: class declaration and object construction 1.12 Java: classes declaration 2. Relations among classes. Class inheritance 2.1 Communication among classes 2.2 Classes containing objects as attributes: some well-known examples 2.3 Specialisation/generalisation relationships 2.4 Definition of class inheritance 2.5 Advantages of using inheritance: code reuse and polymorphism 2.6 Redefinition of methods in subclasses 2.7 Access modifier “protected”: use cases 2.8 Representing class inheritance in UML 2.9 Programming in Java and C++ inheritance relationships 3. -

Scala: How to Make Best Use of Functions and Objects
Scala: How to make best use of functions and objects Philipp Haller Lukas Rytz Martin Odersky EPFL ACM Symposium on Applied Computing Tutorial Where it comes from Scala has established itself as one of the main alternative languages on the JVM. Prehistory: 1996 – 1997: Pizza 1998 – 2000: GJ, Java generics, javac ( “make Java better” ) Timeline: 2003 – 2006: The Scala “Experiment” 2006 – 2009: An industrial strength programming language ( “make a better Java” ) 2 3 Why Scala? 4 Scala is a Unifier Agile, with lightweight syntax Object-Oriented Scala Functional Safe and performant, with strong static typing 5 What others say: 6 “If I were to pick a language to use today other than Java, it would be Scala.” - James Gosling, creator of Java “Scala, it must be stated, is the current heir apparent to the Java throne. No other language on the JVM seems as capable of being a "replacement for Java" as Scala, and the momentum behind Scala is now unquestionable. While Scala is not a dynamic language, it has many of the characteristics of popular dynamic languages, through its rich and flexible type system, its sparse and clean syntax, and its marriage of functional and object paradigms.” - Charles Nutter, creator of JRuby “I can honestly say if someone had shown me the Programming in Scala book by Martin Odersky, Lex Spoon & Bill Venners back in 2003 I'd probably have never created Groovy.” - James Strachan, creator of Groovy. 7 Let’s see an example: 8 A class ... public class Person { public final String name; public final int age; Person(String name, int age) { ..