Internal and External Mechanisms for Extending Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Database Licensing Information, 11G Release 2 (11.2) E10594-26
Oracle® Database Licensing Information 11g Release 2 (11.2) E10594-26 July 2012 Oracle Database Licensing Information, 11g Release 2 (11.2) E10594-26 Copyright © 2004, 2012, Oracle and/or its affiliates. All rights reserved. Contributor: Manmeet Ahluwalia, Penny Avril, Charlie Berger, Michelle Bird, Carolyn Bruse, Rich Buchheim, Sandra Cheevers, Leo Cloutier, Bud Endress, Prabhaker Gongloor, Kevin Jernigan, Anil Khilani, Mughees Minhas, Trish McGonigle, Dennis MacNeil, Paul Narth, Anu Natarajan, Paul Needham, Martin Pena, Jill Robinson, Mark Townsend This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. -

Third-Party License Acknowledgments
Symantec Privileged Access Manager Third-Party License Acknowledgments Version 3.4.3 Symantec Privileged Access Manager Third-Party License Acknowledgments Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. Copyright © 2021 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. 2 Symantec Privileged Access Manager Third-Party License Acknowledgments Contents Activation 1.1.1 ..................................................................................................................................... 7 Adal4j 1.1.2 ............................................................................................................................................ 7 AdoptOpenJDK 1.8.0_282-b08 ............................................................................................................ 7 Aespipe 2.4e aespipe ........................................................................................................................ -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -

Cross-Platform Language Design
Cross-Platform Language Design THIS IS A TEMPORARY TITLE PAGE It will be replaced for the final print by a version provided by the service academique. Thèse n. 1234 2011 présentée le 11 Juin 2018 à la Faculté Informatique et Communications Laboratoire de Méthodes de Programmation 1 programme doctoral en Informatique et Communications École Polytechnique Fédérale de Lausanne pour l’obtention du grade de Docteur ès Sciences par Sébastien Doeraene acceptée sur proposition du jury: Prof James Larus, président du jury Prof Martin Odersky, directeur de thèse Prof Edouard Bugnion, rapporteur Dr Andreas Rossberg, rapporteur Prof Peter Van Roy, rapporteur Lausanne, EPFL, 2018 It is better to repent a sin than regret the loss of a pleasure. — Oscar Wilde Acknowledgments Although there is only one name written in a large font on the front page, there are many people without which this thesis would never have happened, or would not have been quite the same. Five years is a long time, during which I had the privilege to work, discuss, sing, learn and have fun with many people. I am afraid to make a list, for I am sure I will forget some. Nevertheless, I will try my best. First, I would like to thank my advisor, Martin Odersky, for giving me the opportunity to fulfill a dream, that of being part of the design and development team of my favorite programming language. Many thanks for letting me explore the design of Scala.js in my own way, while at the same time always being there when I needed him. -

Behavioral Types in Programming Languages
Behavioral Types in Programming Languages Behavioral Types in Programming Languages iv Davide Ancona, DIBRIS, Università di Genova, Italy Viviana Bono, Dipartimento di Informatica, Università di Torino, Italy Mario Bravetti, Università di Bologna, Italy / INRIA, France Joana Campos, LaSIGE, Faculdade de Ciências, Universidade de Lisboa, Portugal Giuseppe Castagna, CNRS, IRIF, Univ Paris Diderot, Sorbonne Paris Cité, Paris, France Pierre-Malo Deniélou, Royal Holloway, University of London, UK Simon J. Gay, School of Computing Science, University of Glasgow, UK Nils Gesbert, Université Grenoble Alpes, France Elena Giachino, Università di Bologna, Italy / INRIA, France Raymond Hu, Department of Computing, Imperial College London, UK Einar Broch Johnsen, Institutt for informatikk, Universitetet i Oslo, Norway Francisco Martins, LaSIGE, Faculdade de Ciências, Universidade de Lisboa, Portugal Viviana Mascardi, DIBRIS, Università di Genova, Italy Fabrizio Montesi, University of Southern Denmark Rumyana Neykova, Department of Computing, Imperial College London, UK Nicholas Ng, Department of Computing, Imperial College London, UK Luca Padovani, Dipartimento di Informatica, Università di Torino, Italy Vasco T. Vasconcelos, LaSIGE, Faculdade de Ciências, Universidade de Lisboa, Portugal Nobuko Yoshida, Department of Computing, Imperial College London, UK Boston — Delft Foundations and Trends R in Programming Languages Published, sold and distributed by: now Publishers Inc. PO Box 1024 Hanover, MA 02339 United States Tel. +1-781-985-4510 www.nowpublishers.com [email protected] Outside North America: now Publishers Inc. PO Box 179 2600 AD Delft The Netherlands Tel. +31-6-51115274 The preferred citation for this publication is D. Ancona et al.. Behavioral Types in Programming Languages. Foundations and Trends R in Programming Languages, vol. 3, no. -

Structuring Languages As Object-Oriented Libraries
Structuring Languages as Object-Oriented Libraries Structuring Languages as Object-Oriented Libraries ACADEMISCH PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit van Amsterdam op gezag van de Rector Magnificus prof. dr. ir. K. I. J. Maex ten overstaan van een door het College voor Promoties ingestelde commissie, in het openbaar te verdedigen in de Agnietenkapel op donderdag november , te . uur door Pablo Antonio Inostroza Valdera geboren te Concepción, Chili Promotiecommissie Promotores: Prof. Dr. P. Klint Universiteit van Amsterdam Prof. Dr. T. van der Storm Rijksuniversiteit Groningen Overige leden: Prof. Dr. J.A. Bergstra Universiteit van Amsterdam Prof. Dr. B. Combemale University of Toulouse Dr. C. Grelck Universiteit van Amsterdam Prof. Dr. P.D. Mosses Swansea University Dr. B.C.d.S. Oliveira The University of Hong Kong Prof. Dr. M. de Rijke Universiteit van Amsterdam Faculteit der Natuurwetenschappen, Wiskunde en Informatica The work in this thesis has been carried out at Centrum Wiskunde & Informatica (CWI) under the auspices of the research school IPA (Institute for Programming research and Algorith- mics) and has been supported by NWO, in the context of Jacquard Project .. “Next Generation Auditing: Data-Assurance as a Service”. Contents Introduction .Language Libraries . .Object Algebras . .Language Libraries with Object Algebras . .Origins of the Chapters . .Software Artifacts . .Dissertation Structure . Recaf: Java Dialects as Libraries .Introduction . .Overview.................................... .Statement Virtualization . .Full Virtualization . .Implementation of Recaf . .Case Studies . .Discussion . .Related Work . .Conclusion . Tracing Program Transformations with String Origins .Introduction . .String Origins . .Applications of String Origins . .Implementation . .Related Work . .Conclusion . Modular Interpreters with Implicit Context Propagation .Introduction . .Background . v Contents .Implicit Context Propagation . -
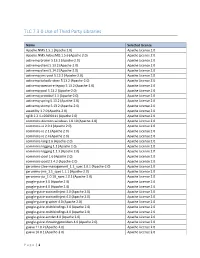
TLC 7.3.0 Use of Third Party Libraries
TLC 7.3.0 Use of Third Party Libraries Name Selected License Apache.NMS 1.5.1 (Apache 2.0) Apache License 2.0 Apache.NMS.ActiveMQ 1.5.6 (Apache 2.0) Apache License 2.0 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.13.2 (Apache-2.0) Apache License 2.0 activemq-stomp 5.13.2 (Apache-2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 cglib 2.2.1-v20090111 (Apache 2.0) Apache License 2.0 commons-daemon-windows 1.0.10 (Apache-2.0) Apache License 2.0 commons-io 2.0.1 (Apache 2.0) Apache License 2.0 commons-io 2.1 (Apache 2.0) Apache License 2.0 commons-io 2.4 (Apache 2.0) Apache License 2.0 commons-lang 2.6 (Apache-2.0) Apache License 2.0 commons-logging 1.1 (Apache 2.0) Apache License 2.0 commons-logging 1.1.3 (Apache 2.0) Apache License 2.0 commons-pool 1.6 (Apache 2.0) Apache License 2.0 commons-pool2 2.4.2 (Apache-2.0) Apache License 2.0 geronimo-j2ee-management_1.1_spec 1.0.1 (Apache-2.0) Apache License 2.0 geronimo-jms_1.1_spec 1.1.1 (Apache-2.0) Apache License 2.0 geronimo-jta_1.0.1B_spec 1.0.1 (Apache-2.0) Apache License 2.0 google-guice 3.0 (Apache 2.0) Apache License 2.0 google-guice 4.0 (Apache -

MARIMBA PROMOTES SIMON WYNN to CHIEF TECHNOLOGY OFFICER Submitted By: Axicom Monday, 30 April 2001
MARIMBA PROMOTES SIMON WYNN TO CHIEF TECHNOLOGY OFFICER Submitted by: AxiCom Monday, 30 April 2001 Arthur van Hoff to Head Newly-Formed Marimba Advanced Development Laboratory to Promote Technology Innovation Marimba, Inc, a leading provider of systems management solutions built for e-business, today announced the appointment of Simon Wynn to the post of chief technology officer (CTO), reporting directly to Marimba president and CEO, John Olsen. Mr. Wynn assumes the position from Arthur van Hoff, a co-founder of Marimba. Van Hoff, along with senior engineers and fellow co-founders, Sami Shaio and Jonathan Payne, will be part of Marimba's newly-formed Advanced Development Laboratory, and van Hoff will continue to report directly to Olsen. This distinguished team of engineers will focus on technology innovation designed to bring new, leading-edge products to market quickly. Van Hoff, Shaio and Payne are well known as original members of the Sun Microsystems Java team. As CTO, Wynn will be responsible for all technical aspects of Marimba's product vision, including software development, product deployment, strategic planning, new business opportunity assessment, as well as industry standards. "I am pleased to announce the promotion of Simon Wynn to the position of CTO, and we welcome him as a member of our executive team," said Olsen. "This appointment acknowledges Simon's past contributions and reflects his leadership role within the company. Simon has been instrumental in helping to secure Marimba's leadership position in the systems management market." Wynn previously held consecutive positions of director of engineering, engineering manager, and staff software engineer. -

A Core Calculus of Metaclasses
A Core Calculus of Metaclasses Sam Tobin-Hochstadt Eric Allen Northeastern University Sun Microsystems Laboratories [email protected] [email protected] Abstract see the problem, consider a system with a class Eagle and Metaclasses provide a useful mechanism for abstraction in an instance Harry. The static type system can ensure that object-oriented languages. But most languages that support any messages that Harry responds to are also understood by metaclasses impose severe restrictions on their use. Typi- any other instance of Eagle. cally, a metaclass is allowed to have only a single instance However, even in a language where classes can have static and all metaclasses are required to share a common super- methods, the desired relationships cannot be expressed. For class [6]. In addition, few languages that support metaclasses example, in such a language, we can write the expression include a static type system, and none include a type system Eagle.isEndangered() provided that Eagle has the ap- with nominal subtyping (i.e., subtyping as defined in lan- propriate static method. Such a method is appropriate for guages such as the JavaTM Programming Language or C#). any class that is a species. However, if Salmon is another To elucidate the structure of metaclasses and their rela- class in our system, our type system provides us no way of tionship with static types, we present a core calculus for a requiring that it also have an isEndangered method. This nominally typed object-oriented language with metaclasses is because we cannot classify both Salmon and Eagle, when and prove type soundness over this core. -

Behavioral Types in Programming Languages
Foundations and Trends R in Programming Languages Vol. 3, No. 2-3 (2016) 95–230 c 2016 D. Ancona et al. DOI: 10.1561/2500000031 Behavioral Types in Programming Languages Davide Ancona, DIBRIS, Università di Genova, Italy Viviana Bono, Dipartimento di Informatica, Università di Torino, Italy Mario Bravetti, Università di Bologna, Italy / INRIA, France Joana Campos, LaSIGE, Faculdade de Ciências, Univ de Lisboa, Portugal Giuseppe Castagna, CNRS, IRIF, Univ Paris Diderot, Sorbonne Paris Cité, France Pierre-Malo Deniélou, Royal Holloway, University of London, UK Simon J. Gay, School of Computing Science, University of Glasgow, UK Nils Gesbert, Université Grenoble Alpes, France Elena Giachino, Università di Bologna, Italy / INRIA, France Raymond Hu, Department of Computing, Imperial College London, UK Einar Broch Johnsen, Institutt for informatikk, Universitetet i Oslo, Norway Francisco Martins, LaSIGE, Faculdade de Ciências, Univ de Lisboa, Portugal Viviana Mascardi, DIBRIS, Università di Genova, Italy Fabrizio Montesi, University of Southern Denmark Rumyana Neykova, Department of Computing, Imperial College London, UK Nicholas Ng, Department of Computing, Imperial College London, UK Luca Padovani, Dipartimento di Informatica, Università di Torino, Italy Vasco T. Vasconcelos, LaSIGE, Faculdade de Ciências, Univ de Lisboa, Portugal Nobuko Yoshida, Department of Computing, Imperial College London, UK Contents 1 Introduction 96 2 Object-Oriented Languages 105 2.1 Session Types in Core Object-Oriented Languages . 106 2.2 Behavioral Types in Java-like Languages . 121 2.3 Typestate . 134 2.4 Related Work . 139 3 Functional Languages 140 3.1 Effects for Session Type Checking . 141 3.2 Sessions and Explicit Continuations . 143 3.3 Monadic Approaches to Session Type Checking . -

Semantic Types for Class-Based Objects
Imperial College London Department of Computing Semantic Types for Class-based Objects Reuben N. S. Rowe July 2012 Supervised by Dr. Steffen van Bakel Submitted in part fulfilment of the requirements for the degree of Doctor of Philosophy in Computing of Imperial College London and the Diploma of Imperial College London 1 Abstract We investigate semantics-based type assignment for class-based object-oriented programming. Our mo- tivation is developing a theoretical basis for practical, expressive, type-based analysis of the functional behaviour of object-oriented programs. We focus our research using Featherweight Java, studying two notions of type assignment:- one using intersection types, the other a ‘logical’ restriction of recursive types. We extend to the object-oriented setting some existing results for intersection type systems. In do- ing so, we contribute to the study of denotational semantics for object-oriented languages. We define a model for Featherweight Java based on approximation, which we relate to our intersection type system via an Approximation Result, proved using a notion of reduction on typing derivations that we show to be strongly normalising. We consider restrictions of our system for which type assignment is decid- able, observing that the implicit recursion present in the class mechanism is a limiting factor in making practical use of the expressive power of intersection types. To overcome this, we consider type assignment based on recursive types. Such types traditionally suffer from the inability to characterise convergence, a key element of our approach. To obtain a se- mantic system of recursive types for Featherweight Java we study Nakano’s systems, whose key feature is an approximation modality which leads to a ‘logical’ system expressing both functional behaviour and convergence. -

Open Source Used in Cisco UCS Director 5.5
Open Source Used In Cisco UCS Director 5.5 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-116574787 Open Source Used In Cisco UCS Director 5.5 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-116574787 The product also uses the Linux operating system, Centos Full 6.7. Information on this distribution is available at http://vault.centos.org/6.7/os/Source/SPackages/. The full source code for this distribution, including copyright and license information, is available on request from [email protected]. Mention that you would like the Linux distribution source archive, and quote the following reference number for this distribution: 118610896-116574787. Contents 1.1 activemq-all 5.2.0 1.1.1 Available under license 1.2 Amazon AWS Java SDK 1.1.1 1.2.1 Available under license 1.3 ant 1.9.3 :2build1 1.3.1 Available under license 1.4 aopalliance version 1.0 repackaged as a module 2.3.0-b10 1.4.1 Available under license 1.5 Apache