Bioinformatics: a Revolutionary Way of Using Computer Technology for Evidence Based Medicine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Information Technology Management 14
Information Technology Management 14 Valerie Bryan Practitioner Consultants Florida Atlantic University Layne Young Business Relationship Manager Indianapolis, IN Donna Goldstein GIS Coordinator Palm Beach County School District Information Technology is a fundamental force in • IT as a management tool; reshaping organizations by applying investment in • understanding IT infrastructure; and computing and communications to promote competi- • ȱǯ tive advantage, customer service, and other strategic ęǯȱǻȱǯȱǰȱŗşşŚǼ ȱȱ ȱ¢ȱȱȱ¢ǰȱȱ¢Ȃȱ not part of the steamroller, you’re part of the road. ǻ ȱǼ ȱ ¢ȱ ȱ ȱ ęȱ ȱ ȱ ¢ǯȱȱȱȱȱ ȱȱ ȱ- ¢ȱȱȱȱȱǯȱ ǰȱ What is IT? because technology changes so rapidly, park and recre- ation managers must stay updated on both technological A goal of management is to provide the right tools for ȱȱȱȱǯ ěȱ ȱ ě¢ȱ ȱ ȱ ȱ ȱ ȱ ȱȱȱȱ ȱȱȱǰȱȱǰȱ ȱȱȱȱȱȱǯȱȱȱȱ ǰȱȱȱȱ ȱȱ¡ȱȱȱȱ recreation organization may be comprised of many of terms crucial for understanding the impact of tech- ȱȱȱȱǯȱȱ ¢ȱ ȱ ȱ ȱ ȱ ǯȱ ȱ ȱ ȱ ȱ ȱ ǯȱ ȱ - ȱȱęȱȱȱ¢ȱȱȱȱ ¢ȱǻ Ǽȱȱȱȱ¢ȱ ȱȱȱȱ ǰȱ ȱ ȱ ȬȬ ȱ ȱ ȱ ȱȱǯȱȱȱȱȱ ¢ȱȱǯȱȱ ȱȱȱȱ ȱȱ¡ȱȱȱȱȱǻǰȱŗşŞśǼǯȱ ȱȱȱȱȱȱĞȱȱȱȱ ǻȱ¡ȱŗŚǯŗȱ Ǽǯ ě¢ȱȱȱȱǯ Information technology is an umbrella term Details concerning the technical terms used in this that covers a vast array of computer disciplines that ȱȱȱȱȱȱȬȬęȱ ȱȱ permit organizations to manage their information ǰȱ ȱ ȱ ȱ Ȭȱ ¢ȱ ǯȱ¢ǰȱȱ¢ȱȱȱ ȱȱ ǯȱȱȱȱȱȬȱ¢ȱ a fundamental force in reshaping organizations by applying ȱȱ ȱȱ ȱ¢ȱȱȱȱ investment in computing and communications to promote ȱȱ¢ǯȱ ȱȱȱȱ ȱȱ competitive advantage, customer service, and other strategic ȱ ǻȱ ȱ ŗŚȬŗȱ ęȱ ȱ DZȱ ęȱǻǰȱŗşşŚǰȱǯȱřǼǯ ȱ Ǽǯ ȱ¢ȱǻ Ǽȱȱȱȱȱ ȱȱȱęȱȱȱ¢ȱȱ ȱ¢ǯȱȱȱȱȱ ȱȱ ȱȱ ȱȱȱȱ ȱ¢ȱ ȱȱǯȱ ȱ¢ǰȱ ȱȱ ȱDZ ȱȱȱȱǯȱ ȱȱȱȱǯȱ It lets people learn things they didn’t think they could • ȱȱȱ¢ǵ ȱǰȱȱǰȱȱȱǰȱȱȱȱȱǯȱ • the manager’s responsibilities; ǻȱǰȱȱ¡ȱĜȱȱĞǰȱȱ • information resources; ǷȱǯȱȱȱřŗǰȱŘŖŖŞǰȱ • disaster recovery and business continuity; ȱĴDZȦȦ ǯ ǯǼ Information Technology Management 305 Exhibit 14. -

Bioinformatics 1
Bioinformatics 1 Bioinformatics School School of Science, Engineering and Technology (http://www.stmarytx.edu/set/) School Dean Ian P. Martines, Ph.D. ([email protected]) Department Biological Science (https://www.stmarytx.edu/academics/set/undergraduate/biological-sciences/) Bioinformatics is an interdisciplinary and growing field in science for solving biological, biomedical and biochemical problems with the help of computer science, mathematics and information technology. Bioinformaticians are in high demand not only in research, but also in academia because few people have the education and skills to fill available positions. The Bioinformatics program at St. Mary’s University prepares students for graduate school, medical school or entry into the field. Bioinformatics is highly applicable to all branches of life sciences and also to fields like personalized medicine and pharmacogenomics — the study of how genes affect a person’s response to drugs. The Bachelor of Science in Bioinformatics offers three tracks that students can choose. • Bachelor of Science in Bioinformatics with a minor in Biology: 120 credit hours • Bachelor of Science in Bioinformatics with a minor in Computer Science: 120 credit hours • Bachelor of Science in Bioinformatics with a minor in Applied Mathematics: 120 credit hours Students will take 23 credit hours of core Bioinformatics classes, which included three credit hours of internship or research and three credit hours of a Bioinformatics Capstone course. BS Bioinformatics Tracks • Bachelor of Science -

Information Technology Manager Is a Professional Technical Stand Alone Class
CITY OF GRANTS PASS, OREGON CLASS SPECIFICATION FLSA Status : Exempt Bargaining Unit : Non-Bargaining INFORMATION TECHNOLOGY Salary Grade : UD2 MANAGER CLASS SUMMARY: The Information Technology Manager is a Professional Technical Stand Alone class. Incumbents are responsible for management of specific applications, computer hardware and software, and development of systems based on detailed specifications. Incumbents apply a broad knowledge base of programming code to City issues and work with systems that link to multiple databases involving complex equations. Based upon assignment, incumbents may manage small information technology projects. The Information Technology Manager is responsible for the full range of supervisory duties including directing work, training and coaching, discipline, and performance evaluation. CORE COMPETENCIES: Integrity/Accountability: Conducts oneself in a manner that is ethical, trustworthy and professional; demonstrates transparency with honest, responsive communication; behaves in a manner that supports the needs of Council, the citizens and co-workers; and conducts oneself in manner that supports the vision and goals of the organization taking pride in being engaged in the community. Vision: Actively seeks to discover and create ways of doing things better using resources and skills in an imaginative and innovative manner; encourages others to find solutions and contributes, regardless of responsibilities, to achieve a common goal; and listens and is receptive to different ideas and opinions while solving problems. Leadership/United: Focuses on outstanding results of the betterment of the individual, the organization and the community; consistently seeks opportunities for coordination and collaboration, working together as a team; displays an ability to adjust as needed to accomplish the common goal and offers praise when a job is done well. -

An Academic Discipline
Information Technology – An Academic Discipline This document represents a summary of the following two publications defining Information Technology (IT) as an academic discipline. IT 2008: Curriculum Guidelines for Undergraduate Degree Programs in Information Technology. (Nov. 2008). Association for Computing Machinery (ACM) and IEEE Computer Society. Computing Curricula 2005 Overview Report. (Sep. 2005). Association for Computing Machinery (ACM), Association for Information Systems (AIS), Computer Society (IEEE- CS). The full text of these reports with details on the model IT curriculum and further explanation of the computing disciplines and their commonalities/differences can be found online: http://www.acm.org/education/education/curricula-recommendations) From IT 2008: Curriculum Guidelines for Undergraduate Degree Programs in Information Technology IT programs aim to provide IT graduates with the skills and knowledge to take on appropriate professional positions in Information Technology upon graduation and grow into leadership positions or pursue research or graduate studies in the field. Specifically, within five years of graduation a student should be able to: 1. Explain and apply appropriate information technologies and employ appropriate methodologies to help an individual or organization achieve its goals and objectives; 2. Function as a user advocate; 3. Manage the information technology resources of an individual or organization; 4. Anticipate the changing direction of information technology and evaluate and communicate the likely utility of new technologies to an individual or organization; 5. Understand and, in some cases, contribute to the scientific, mathematical and theoretical foundations on which information technologies are built; 6. Live and work as a contributing, well-rounded member of society. In item #2 above, it should be recognized that in many situations, "a user" is not a homogeneous entity. -

Applications of Social Media in Hydroinformatics: a Survey
Applications of Social Media in Hydroinformatics: A Survey Yufeng Yu, Yuelong Zhu, Dingsheng Wan,Qun Zhao [email protected] College of Computer and Information Hohai University Nanjing, Jiangsu, China Kai Shu, Huan Liu [email protected] School of Computing, Informatics, and Decision Systems Engineering Arizona State University Tempe, Arizona, U.S.A Abstract Floods of research and practical applications employ social media data for a wide range of public applications, including environmental monitoring, water resource managing, disaster and emergency response, etc. Hydroinformatics can benefit from the social media technologies with newly emerged data, techniques and analytical tools to handle large datasets, from which creative ideas and new values could be mined. This paper first proposes a 4W (What, Why, When, hoW) model and a methodological structure to better understand and represent the application of social media to hydroinformatics, then provides an overview of academic research of applying social media to hydroinformatics such as water environment, water resources, flood, drought and water Scarcity management. At last,some advanced topics and suggestions of water-related social media applications from data collection, data quality management, fake news detection, privacy issues , algorithms and platforms was present to hydroinformatics managers and researchers based on previous discussion. Keywords: Social Media, Big Data, Hydroinformatics, Social Media Mining, Water Resource, Data Quality, Fake News 1 Introduction In the past two -

Use of Hydroinformatics Technology in Central and Eastern Europe During Last Decade K
Use of Hydroinformatics technology in Central and Eastern Europe during last decade K. Pryl, T. Metelka, M. Suchanek To cite this version: K. Pryl, T. Metelka, M. Suchanek. Use of Hydroinformatics technology in Central and Eastern Europe during last decade. Novatech 2010 - 7ème Conférence internationale sur les techniques et stratégies durables pour la gestion des eaux urbaines par temps de pluie / 7th International Conference on sustainable techniques and strategies for urban water management, Jun 2010, Lyon, France. pp.3. hal-03296498 HAL Id: hal-03296498 https://hal.archives-ouvertes.fr/hal-03296498 Submitted on 22 Jul 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. NOVATECH 2010 Use of Hydroinformatics technology in Central and Eastern Europe during last decade L’utilisation de la technologie hydro-informatique en Europe centrale et orientale au cours de la dernière décennie Tomas Metelka, Karel Pryl, Milan Suchanek DHI a.s., Na Vrsich 5, Prague 10, 100 00, Czech Republic ([email protected], [email protected], [email protected]) RÉSUMÉ Au cours de la dernière décennie, l’hydro-informatique s’est progressivement développée dans le secteur de l’ingénierie de l’eau, complétée par des méthodes adéquates et des approches qui diffèrent souvent beaucoup des normes largement acceptées. -

Information Systems Foundations Theory, Representation and Reality
Information Systems Foundations Theory, Representation and Reality Information Systems Foundations Theory, Representation and Reality Dennis N. Hart and Shirley D. Gregor (Editors) Workshop Chair Shirley D. Gregor ANU Program Chairs Dennis N. Hart ANU Shirley D. Gregor ANU Program Committee Bob Colomb University of Queensland Walter Fernandez ANU Steven Fraser ANU Sigi Goode ANU Peter Green University of Queensland Robert Johnston University of Melbourne Sumit Lodhia ANU Mike Metcalfe University of South Australia Graham Pervan Curtin University of Technology Michael Rosemann Queensland University of Technology Graeme Shanks University of Melbourne Tim Turner Australian Defence Force Academy Leoni Warne Defence Science and Technology Organisation David Wilson University of Technology, Sydney Published by ANU E Press The Australian National University Canberra ACT 0200, Australia Email: [email protected] This title is also available online at: http://epress.anu.edu.au/info_systems02_citation.html National Library of Australia Cataloguing-in-Publication entry Information systems foundations : theory, representation and reality Bibliography. ISBN 9781921313134 (pbk.) ISBN 9781921313141 (online) 1. Management information systems–Congresses. 2. Information resources management–Congresses. 658.4038 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying or otherwise, without the prior permission of the publisher. Cover design by Brendon McKinley with logo by Michael Gregor Authors’ photographs on back cover: ANU Photography Printed by University Printing Services, ANU This edition © 2007 ANU E Press Table of Contents Preface vii The Papers ix Theory Designing for Mutability in Information Systems Artifacts, Shirley Gregor and Juhani Iivari 3 The Eect of the Application Domain in IS Problem Solving: A Theoretical Analysis, Iris Vessey 25 Towards a Unied Theory of Fit: Task, Technology and Individual, Michael J. -
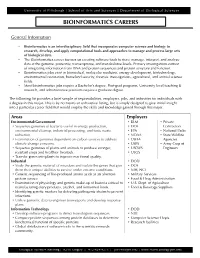
Bioinformatics Careers
University of Pittsburgh | School of Arts and Sciences | Department of Biological Sciences BIOINFORMATICS CAREERS General Information • Bioinformatics is an interdisciplinary field that incorporates computer science and biology to research, develop, and apply computational tools and approaches to manage and process large sets of biological data. • The Bioinformatics career focuses on creating software tools to store, manage, interpret, and analyze data at the genome, proteome, transcriptome, and metabalome levels. Primary investigations consist of integrating information from DNA and protein sequences and protein structure and function. • Bioinformatics jobs exist in biomedical, molecular medicine, energy development, biotechnology, environmental restoration, homeland security, forensic investigations, agricultural, and animal science fields. • Most bioinformatics jobs require a Bachelor’s degree. Post-grad programs, University level teaching & research, and administrative positions require a graduate degree. The following list provides a brief sample of responsibilities, employers, jobs, and industries for individuals with a degree in this major. This is by no means an exhaustive listing, but is simply designed to give initial insight into a particular career field that would employ the skills and knowledge gained through this major. Areas Employers Environmental/Government • BLM • Private • Sequence genomes of bacteria useful in energy production, • DOE Contractors environmental cleanup, industrial processing, and toxic waste • EPA • National Parks reduction. • NOAA • State Wildlife • Examination of genomes dependent on carbon sources to address • USDA Agencies climate change concerns. • USFS • Army Corp of • Sequence genomes of plants and animals to produce stronger, • USFWS Engineers resistant crops and healthier livestock. • USGS • Transfer genes into plants to improve nutritional quality. Industrial • DOD • Study the genetic material of microbes and isolate the genes that give • DOE them their unique abilities to survive under extreme conditions. -

Information Technology and Information Systems: Its Use As a Competitive and Strategic Weapon
Information Technology and Information Systems: Its Use as a Competitive and Strategic Weapon Leslie M. Bobb Peter Harris School of Management, New York Institute of Technology, USA ABSTRACT Most companies today are finding a new dimension for use of their information systems and information technologies. That added dimension is its use as a competitive and strategic weapon. Information systems (IS) and information technologies (IT) had their origins as a data processing aid. Now companies are increasingly finding out that it is not the data that matters, but how that data is managed and utilized. Common themes such as: a clear corporate mission, the utilization of IT as a corporate resource, and a marketing position that advocates IT usage have been identified by successful companies as the foundation for IT use as a competitive and strategic weapon. Three main assets have been identified by successful IT companies as the main reason for their success: • There must be a strong IT staff, • A reusable technology base, and • A partnership between the IT staff and business management Firms must identify their target group correctly and focus their efforts intensely. These target groups may be any or all of their customers, suppliers or competition. In addition, analysis must be done at the firm, industry, and strategy level to best determine the maximum benefits of its IT potential. Use of IT as a competitive and strategic weapon could differentiate a company in today’s global competitive environment. At a time when companies can no longer separate themselves strictly by cost and product differentiation, IT must be the new differentiation tool. -

Representing and Using Ontologies
USC-CIT Technical Report 98-01 1 Representing and Using Ontologies Kuhanandha Mahalingam and Michael N. Huhns January 1998 Center for Information Technology Department of Electrical and Computer Engineering University of South Carolina Columbia, SC, U.S.A. 29208 (803) 777-5921 or [email protected] (803) 777-8045 FAX Keywords: Ontology, Java, Distributed Information Systems Abstract This paper discusses the representation of large ontologies, especially in a graphical format. It describes a tool, developed using Java, that incorporates several abstraction mechanisms that can help manage such ontologies. Furthermore, it briefly analyzes possible point-and-click approaches that can be used to form queries on these ontologies. 1 This research was partially done under a cooperative agreement between the National Institute of Standards and Technology Advanced Technology Program (under the HIIT contract, number 70NANB5H1011) and the Healthcare Open Systems and Trials, Inc. consortium. 1. Introduction The introduction of the World Wide Web (Web) and the consequent growth of other supporting technologies that, without doubt, have driven the Internet’s widespread usage have created many new problems. The most notable problem is how to manage efficiently the volume and heterogeneity of information produced on the Web each day. Further, most of the data produced is no longer just simple text, but also consists of multimedia objects. Multimedia objects require different policies, procedures, and conventions. They originate from and reside on a variety of different operating systems, and, most importantly, are large and complex. There are many approaches for coping with these problems. One of these approaches is to use ontologies for capturing the knowledge represented by the information sources, so that it can be viewed and manipulated declaratively. -

Information Technology Director Class Description
City of South San Francisco Human Resources Department Information Technology Director Class Description Definition Under administrative direction, plans, organizes, and directs the programs and functions of Citywide information systems and services, including engineering and system design services for voice and data telecommunications networks; develops, implement, and coordinate the potential for sustainable innovation by defining community and region-wide opportunities and ideas; evaluates, develops and presents comprehensive programs to secure business growth and modernization in South San Francisco; serves as the chief architect for all City technology services; serves as a member of the City executive team; and performs related duties as assigned. IT Director reports directly to the Assistant City Manager. Distinguishing Characteristics The classification serves as a department head and is responsible for all elements of the City’s information technology program, and supervises and has oversight of all technology staff. It is distinguished from the next lower-level manager classification in that the manager is focused on computer operations, and day-to-day staff supervision. The objective of this position is to attract and retain private-sector business interests in the City, utilizing fluency in information and/or communications technology and create an internal culture, climate and environment that is needed for innovation and removing barriers both real and perceived that hinder innovative growth. Typical and Important Duties 1. Assumes management responsibility for all Information Technology Department services and activities through administration of contract agreements; recommend and administers policies and procedures. 2. Ensures effective delivery of information services to user Departments through continuous interaction with the City’s information services provider and monitor contractor management staff to ensure effective leadership to the City. -

Bioinformatics: Patenting the Bridge Between Information Technology and the Life Sciences
93 BIOINFORMATICS: PATENTING THE BRIDGE BETWEEN INFORMATION TECHNOLOGY AND THE LIFE SCIENCES CHARLES VORNDRAN, Ph.D.* AND ROBERT L. FLORENCE** INTRODUCTION Over the past two decades, advances in the fields of genomics and proteomics have enabled life scientists to amass an enormous amount of complex biological information. The ability to gather such information, however, has surpassed the ability and speed at which it can be interpreted. The growing field of bioinformatics holds great promise for making sense of this biological information through the development of new and innovative computational tools for the management of biological data. As with any developing field, the continued advancement and commercial viability of such innovations often depends on successful patent protection. This article , therefore, discusses the patentability of computer and software related inventions in this unique and evolving field. Part I begins by defining bioinformatics and bioinformatic -tools. A brief discussion of the main segments of the bioinformatics market is provided with examples from each segment. An explanation of how our bodies store and regulate the flow of genetic information is also provided in order to * Associate in the Atlanta office of Troutman Sanders LLP; J.D. 1997, Southern Methodist University; Ph.D. Biological Sciences 1995 concentrating on Cellular/Developmental/Molecular Biology, University of Texas at Austin; B.Sc. Zoology, 1988, University of Texas at Austin. The views and opinions expressed herein are solely those of the authors and not necessarily those of Troutman Sanders LLP. ** J.D. Candidate 2002, Franklin Pierce Law Center; B.Sc. Biology, 1998, University of Utah. Volume 42 — Number 1 94 IDEA — The Journal of Law and Technology demonstrate the usefulness of bioinformatics related inventions.