UAX #44: Unicode Character Database
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

View Ball from the Barrel
ICONIC HONG KONG +44 (0)7866 424 803 [email protected] runjeetsingh.com INTRODUCTION I’m excited to say that this is my first time exhibiting at Fine Art Asia and I’m looking forward to displaying a diverse group of exceptional objects from China, Tibet, Korea and India. Many of these pieces have formed important parts of collections in the West and been treasured for many decades. Several are decorated with powerful Buddhist themes—testament to the importance placed upon them by their makers and owners. It will be a great pleasure to bring them to the Hong Kong Convention and Exhibition Centre and share them with the collecting world. I would like to offer a sincere message of appreciation to the numerous colleagues and friends who contributed to the research and production of this publication and the accompanying exhibition. I also thank my family for their endless love, patience and support. 30 Sept – 3 Oct 2017 Hong Kong Convention and Exhibition Centre Stand A13 CONTENTS Daggers 08 Swords 28 Polearms 38 Firearms 42 Archery 44 Equestrian 48 Armour 56 Helmets 60 Written by Runjeet Singh September 2017 All prices on request 9 1 SAWASA KNIFE This is a highly unusual Chinese Two further mounts in the form Notes eating knife with mounts of Sawasa of bats (Chinese symbols of good Knives were highly important to (a term applied to a group of black luck) are decorated in contrasting CHINA, QING DYNASTY the Manchus. Emperor Qianglong lacquered and gilt artefacts made techniques. The upper bat has a 18TH – 19TH CENTURY erected a tablet in front of the Jian from a copper alloy with gold, silver black body, silver wings and gold on Ting (the Archery Pavilion in the and arsenic). -

African Literacies
African Literacies African Literacies: Ideologies, Scripts, Education Edited by Kasper Juffermans, Yonas Mesfun Asfaha and Ashraf Abdelhay African Literacies: Ideologies, Scripts, Education, Edited by Kasper Juffermans, Yonas Mesfun Asfaha and Ashraf Abdelhay This book first published 2014 Cambridge Scholars Publishing 12 Back Chapman Street, Newcastle upon Tyne, NE6 2XX, UK British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Copyright © 2014 by Kasper Juffermans, Yonas Mesfun Asfaha, Ashraf Abdelhay and contributors All rights for this book reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owner. ISBN (10): 1-4438-5833-1, ISBN (13): 978-1-4438-5833-5 For Caroline and Inca; Soliana and Aram; Lina and Mahgoub TABLE OF CONTENTS Foreword .................................................................................................... ix Marilyn Martin-Jones Acknowledgements .................................................................................. xiv Chapter One ................................................................................................. 1 African Literacy Ideologies, Scripts and Education Ashraf Abdelhay Yonas Mesfun Asfaha and Kasper Juffermans Chapter Two .............................................................................................. 63 Lessons -

Ancient and Other Scripts
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Iso/Iec Jtc1/Sc2/Wg2 N4488 L2/13-191
ISO/IEC JTC1/SC2/WG2 N4488 L2/13-191 2013-10-28 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Preliminary proposal for encoding the Adlam script in the SMP of the UCS Source: UC Berkeley Script Encoding Initiative (Universal Scripts Project) Author: Michael Everson Status: Liaison Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2012-10-28 1. Introduction. An alphabetic script for the Fulani language began to be devised in the 1980s by brothers Ibrahima Barry and Abdoulaye Barry, when they were children in Guinea. One of them asked their father why they could not write their language, and when their father wrote a few words in Fulani in Arabic script, he said “That’s not our script. We should have our own.” Some time later the boys proved to their father that they had devised by engaging in blind testing—similar to the way in which Sequoyah proved the efficacy of the Cherokee syllabary to his colleagues. One wrote a text and left the room; his brother came in and read it aloud, and then wrote down something else that he was told to write. Then he left the room and his sister, who had learned the script, came in to read what he had written. Over the next few years the Adlam script continued development. It is currently in use in Guinea and in other countries, and its use is increasing. 2. Structure. Adlam is a casing script with right-to-left directionality. -

Universal Multiple-Octet Coded Character
Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2 N4375R ISO/IEC JTC 1/SC 2/WG 2 N4604R Date: 2014-10-30 Source: WG 2 meeting 63, Hotel Taj Samudra, Colombo, Sri Lanka; 2014-09-29/10-03 Title: Recommendations from WG 2 meeting 63 Action: For approval by SC 2 and for information to WG 2 Status: Adopted at meeting 63 of WG 2 Distribution: ISO/IEC JTC 1/SC 2 and WG 2 Experts accredited by the national bodies or liaison organizations for Canada, China, Ireland, IRG, Japan, JTC1/SC35 (Liaison), Korea (Republic of), SEI - UC Berkeley (Liaison), Sri Lanka, TCA (Liaison), the United Kingdom, the Unicode Consortium (Liaison), and the USA were present when the following recommendations were adopted (see attached attendance list). Character count 120585 in 4th edition 101 additions in DAM1 to the 4th edition 6741 for future amendment 2 (end of meeting 62) Character count 127427 (total allocated till end of meeting 62) Recommendation M63.01 (Disposition of DAM1 ballot comments): Unanimous WG2 accepts the disposition of ballot comments for DAM1 to the 4th edition in document N4615. All the comments being editorial, WG2 further recommends that the updated text of DAM1 be sent to SC2 to forward to ITTF for publication. count: 101 additions in Amendment 1(unchanged) Recommendation M63.02 (Amendment 2 additions since meeting 62): Unanimous WG2 notes that in addition to the total of 6741 characters listed under resolutions M62.14 (in document N4454) the following additions were included in the PDAM2 ballot document SC2/N4340 (preliminary charts in N4585): a. -
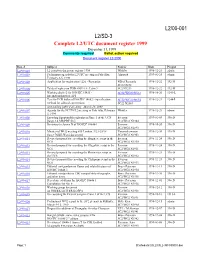
L2/00-001 L2/SD-3 Complete L2/UTC Document Register 1999 December 31, 1999 Comments Required Ballot Action Required Document Register L2-2000
L2/00-001 L2/SD-3 Complete L2/UTC document register 1999 December 31, 1999 Comments required Ballot action required Document register L2-2000 Doc. # Subject Source Date Project L2/99-001 L2 complete document register 1998 Winkler 1998-12-21 admin L2/99-002 Preliminary agenda for L2/UTC meeting in Palo Alto, Aliprand 1999-01-25 admin February 3-5, 1998 L2/99-003 Application for registration #226 - Romanian NB of Romania 1998-12-22 392-M SC2 N3232 L2/99-004 Table of replies on FDIS 8859-15 - Latin 9 SC2 N3233 1998-12-22 392-M L2/99-005 Working draft #2 for ISO/IEC 15435 - SC22/WG20 N612 1998-10-20 1241-L Internationalization API L2/99-006 Text for FCD ballot of ISO/IEC 14652 - Specification SC22/WG20 N634 1998-12-21 1244-L method for cultural conventions SC22 N2869 next mailing [after Palo Alto] - March 10, 1999 L2/99-007 Agenda for the NCITS/L2 meeting in Palo Alto, February Winkler 1998-12-29 admin 5, 1999 L2/99-008 Encoding Egyptian Hieroglyphs in Plane 1 of the UCS Everson 1999-01-09 396-D [large 3.4 MB PDF file] SC2/WG2 N1944 L2/99-009 Revisions to Annex N of ISO/IEC 10646-1 Everson 1998-10-20 396-D SC2/WG2 N1893 L2/99-010 Minutes of WG2 meeting #35 London, 9/21-25/98 Umamaheswaran 1998-12-30 396-D [large 760kB Word document] SC2/WG2 N1903 L2/99-011 Revised proposal for encoding the Buginese script in the Everson 1998-11-24 396-D UCS SC2/WG2 N1930 L2/99-012 Revised proposal for encoding the Glagolitic script in the Everson 1998-11-24 396-D UCS SC2/WG2 N1931 L2/99-013 Revised proposal for encoding the Phoenician script in Everson 1998-11-23 396-D the UCS SC2/WG2 N1932 L2/99-014 Revised proposal for encoding the Philippine script in the Everson 1998-11-23 396-D UCS SC2/WG2 N1933 L2/99-015 Editorial corrigendum on Zones and related features of Bruce Paterson 1998-11-11 396-D ISO/IEC 10646-1 SC2/WG2 N1934 L2/99-016 Editorial corrigenda on CJK compatibility ideographs, Bruce Paterson 1998-11-30 396-D and other items SC2/WG2 N1935 L2/99-017 Repertoire additions for ISO/IEC 10646-1 Bruce Paterson 1998-12-01 396-D Cumulative list No. -

Fonts & Encodings
Fonts & Encodings Yannis Haralambous To cite this version: Yannis Haralambous. Fonts & Encodings. O’Reilly, 2007, 978-0-596-10242-5. hal-02112942 HAL Id: hal-02112942 https://hal.archives-ouvertes.fr/hal-02112942 Submitted on 27 Apr 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ,title.25934 Page iii Friday, September 7, 2007 10:44 AM Fonts & Encodings Yannis Haralambous Translated by P. Scott Horne Beijing • Cambridge • Farnham • Köln • Paris • Sebastopol • Taipei • Tokyo ,copyright.24847 Page iv Friday, September 7, 2007 10:32 AM Fonts & Encodings by Yannis Haralambous Copyright © 2007 O’Reilly Media, Inc. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (safari.oreilly.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or [email protected]. Printing History: September 2007: First Edition. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. Fonts & Encodings, the image of an axis deer, and related trade dress are trademarks of O’Reilly Media, Inc. -

Iso/Iec Jtc 1/Sc 2/Wg 2 N4605-A
ISO/IEC JTC 1/SC 2/WG 2 N4605-A DATE: 2014-10-02 Tentative Agenda – Meeting # 63 Topic (Document No.) Proposed Outcome 1. Opening and roll call (N4551) Update Distribution List 2. Approval of the agenda (N4605-A) Approved agenda 3. Approval of minutes of meeting 62 (N4553) Approved Minutes 4. Review action items from previous meeting (N4553-AI) Updated Action Item List 5. JTC1 and ITTF matters FYI 5.1 Results of Voting: ISO/IEC FDIS 10646 4th ed (N4586) Published 2014-09-01 – SC2 N4358/WG2 N4618 6. SC2 matters: 6.1. SC2 Notification of approval of subdivision of work (N4578) FYI 6.2. Notification of SC2 approval of SC2 N4319, request from FYI the Unicode Consortium for changing the category of liaison from C to A (N4577 ) 6.3. Summary of Voting on 10646: DAM1 (Ed 4) Review and progress (N4611, N4611-BSI) 6.4. Proposed Disposition of Ballot Comments DAM1 (N4615) Approve and progress 7. WG2 matters 7.1 Possible ad hoc meetings – Nushu (N4647 ad hoc report) (8:30 Wed), Tangut (post close on Monday) Consider (Tangut - N4642) 7.2 Summary of Voting on 10646 4th edition PDAM2 (N4614) FYI (N4614 Commentfiles PDAM2) 7.3 Proposed Disposition of Ballot Comments on PDAM2 Approve and progress 10646 4th ed (N4616) 7.4 Roadmap Snapshot (N4617) Adoption 8. IRG status and reports 8.1 IRG No. 42 Resolutions – Qindao, China (N4582) FYI 8.2 IRG No. 42 Summary Report (N4581) Adoption 8.3 IRG Principles and Procedures version 7.5 (N4579) FYI 8.4 Report of Inaccurate Source Reference for Twelve FYI HKSCS Compatibility characters(N4598) 9. -

Preliminary Agenda
ISO/IEC JTC 1/SC 2/WG 2 N4505-A DATE: 2014-02-23 ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) - ISO/IEC 10646 Secretariat: ANSI DOC TYPE: Preliminary Agenda TITLE: Preliminary Agenda Meeting # 62 SOURCE: Mike Ksar, Convener PROJECT: JTC 1.02.18 – ISO/IEC 10646 STATUS: ACTION ID: ACT – Review preliminary agenda in document N4505-A and provide feedback to Convener DUE DATE: 2014-02-18 DISTRIBUTION: SC2/WG2 members and Liaison organizations MEDIUM: Electronic NO. OF PAGES: 4 Below is a copy of the preliminary agenda for the upcoming meeting 62 of JTC1/SC2/WG2. Please review and provide feedback. Mike Ksar ISO/IEC/JTC 1/SC 2/WG 2 Convener Phone: +1 408 255-1217 22680 Alcalde Rd. e-mail: [email protected] Cupertino, CA 95014 – U. S. A. ISO/IEC JTC 1/SC 2/WG 2 N4505-A DATE: 2014-02-23 Preliminary Agenda – Meeting # 62 Topic (Document No.) Proposed Outcome 1. Opening and roll call (N4401) Update Distribution List 2. Approval of the agenda (N4505-A) Approved agenda 3. Approval of minutes of meeting 61 (N4403) Approved Minutes 4. Review action items from previous meeting (N4403-AI) Updated Action Item List 5. JTC1 and ITTF matters 6. SC2 matters: 6.1. SC2 Program of Work FYI 6.2. FDAM2 Results of 3rd edition – 100% approved (N4532) FYI 6.3. Results of PDAM1 subdivision proposal (N4531) FYI 6.4. Summary of Voting DIS – 4th edition (N4524 & N4524-A) Consider and progress 6.5. Draft additional Repertoire DIS – 4th edition (N4459) Consider and Progress 6.6. -

The Fontspec Package Font Selection for X LE ATEX and Lualatex
The fontspec package Font selection for X LE ATEX and LuaLATEX WILL ROBERTSON With contributions by Khaled Hosny, Philipp Gesang, Joseph Wright, and others. http://wspr.io/fontspec/ 2020/02/21 v2.7i Contents I Getting started 5 1 History 5 2 Introduction 5 2.1 Acknowledgements ............................... 5 3 Package loading and options 6 3.1 Font encodings .................................. 6 3.2 Maths fonts adjustments ............................ 6 3.3 Configuration .................................. 6 3.4 Warnings ..................................... 6 4 Interaction with LATEX 2ε and other packages 7 4.1 Commands for old-style and lining numbers ................. 7 4.2 Italic small caps ................................. 7 4.3 Emphasis and nested emphasis ......................... 7 4.4 Strong emphasis ................................. 7 II General font selection 8 1 Main commands 8 2 Font selection 9 2.1 By font name ................................... 9 2.2 By file name ................................... 10 2.3 By custom file name using a .fontspec file . 11 2.4 Querying whether a font ‘exists’ ........................ 12 1 3 Commands to select font families 13 4 Commands to select single font faces 13 4.1 More control over font shape selection ..................... 14 4.2 Specifically choosing the NFSS family ...................... 15 4.3 Choosing additional NFSS font faces ....................... 16 4.4 Math(s) fonts ................................... 17 5 Miscellaneous font selecting details 18 III Selecting font features 19 1 Default settings 19 2 Working with the currently selected features 20 2.1 Priority of feature selection ........................... 21 3 Different features for different font shapes 21 4 Selecting fonts from TrueType Collections (TTC files) 23 5 Different features for different font sizes 23 6 Font independent options 24 6.1 Colour ..................................... -

Translating the Lord's Prayer Into Finnish and the Komi Languages: A
Translating the Lord’s Prayer into Finnish and the Komi languages: A construction analytic view Перевод молитвы «Отче наш» на финский и коми языки: анализ конструкций Ahlholm M., Kuosmanen A. Алхольм М., Куосманен А. This article presents translations of the Lord’s Prayer in three Finno- Ugric languages with long literary traditions: Finnish, Komi-Zyrian, and Komi-Permyak, starting with a short overview of the history of the Prayer in the three languages. The theoretical framework combines semantic priming as defined by Anna Wierzbicka and construction analysis as presented by Adele Goldberger. The lexical and constructional choices of the translations are scrutinized phrase by phrase, placing the semantic exegesis alongside the history of translating the Prayer into the three languages. The results show a cross-analysis of the simple core message of the Prayer versus the oral and literal language-specific histories of prayer constructions in these three related but autonomous Finno-Ugric languages. Keywords: Lord’s Prayer translations, liturgical texts, Finnish, Komi-Zyrian, Komi-Permyak В данной статье анализируются переводы молитвы «Отче наш» на три финно-угорских языка с давними литературными традициями: финский, коми-зырянский и коми-пермяцкий, делается их краткий исторический обзор. Теоретическая база исследования объединяет семантические примитивы, предложенные Анной Вежбицкой, и анализ конструкций, представленный Аделью Голдбергер. Выбор лексики и конструкций в переводных текстах тщательно исследу- ется фраза за фразой, семантические толкования рассматриваются Родной язык 1, 2019 Translating the Lord’s Prayer… 147 параллельно с историей перевода молитвы на три языка. Результаты показывают кросс-анализ простого основного послания молитвы в сравнении с устными и буквальными лингвоспецифическими историями конструкций Молитвы в трех родственных, но само- стоятельных финно-угорских языках. -
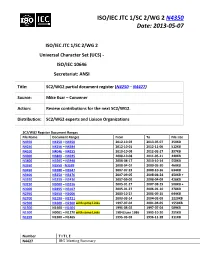
ISO/IEC JTC 1/SC 2/WG 2 N4350 Date: 2013-05-07
ISO/IEC JTC 1/SC 2/WG 2 N4350 Date: 2013-05-07 ISO/IEC JTC 1/SC 2/WG 2 Universal Character Set (UCS) - ISO/IEC 10646 Secretariat: ANSI Title: SC2/WG2 partial document register (N4250 – N4427) Source: Mike Ksar – Convener Action: Review contributions for the next SC2/WG2. Distribution: SC2/WG2 experts and Liaison Organizations SC2/WG2 Register Document Ranges File Name Document Ranges From To File size N4350 N4250 – N4350 2012-10-03 2013-05-07 350KB N4250 N4256 – N4384 2012-10-01 2012-11-06 512KB N4100 N4046 – N4255 2010-10-08 2012-02-27 397KB N4000 N3800 – N4045 2008-10-08 2011-05-11 440KB N3800 N3505 – N3948 2008-08-17 2010-10-14 550KB N3550 N3550 - N3599 2008-04-07 2009-03-30 460KB N3450 N3288 – N3547 2007-07-23 2008-10-16 634KB N3400 N3250 – N3476 2007-09-05 2008-04-24 450KB + N3350 N3250 – N3436 2007-09-05 2008-04-09 428KB N3250 N3000 – N3316 2005-01-27 2007-08-29 508KB + N3000 N2855 – N3107 2005-01-27 2006-01-10 278KB N2950 N2650 – N3006 2003-10-27 2005-09-15 644KB N2700 N2190 – N2721 2003-03-14 2004-02-09 1220KB N2300 N1600 – N2360 with some Links 1997-07-04 2001-04-05 1550KB N1500 N1400 – N1604 1996-08-02 1997-07-04 589KB N1300 N0001 – N1270 with some Links 1984/June 1986 1995-10-20 255KB N1299 N1200 – N1465 1995-05-03 1996-11-28 311KB Number T I T L E Source Date N4427 IRG Meeting Summary Lu Qin Pending N4426 IRG Meeting No.