Comparing Tcp-Ipv4/ Tcp-Ipv6 Network Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Network/Socket Programming in Java
Network/Socket Programming in Java Rajkumar Buyya Elements of C-S Computing a client, a server, and network Request Client Server Network Result Client machine Server machine java.net n Used to manage: c URL streams c Client/server sockets c Datagrams Part III - Networking ServerSocket(1234) Output/write stream Input/read stream Socket(“128.250.25.158”, 1234) Server_name: “manjira.cs.mu.oz.au” 4 Server side Socket Operations 1. Open Server Socket: ServerSocket server; DataOutputStream os; DataInputStream is; server = new ServerSocket( PORT ); 2. Wait for Client Request: Socket client = server.accept(); 3. Create I/O streams for communicating to clients is = new DataInputStream( client.getInputStream() ); os = new DataOutputStream( client.getOutputStream() ); 4. Perform communication with client Receiive from client: String line = is.readLine(); Send to client: os.writeBytes("Hello\n"); 5. Close sockets: client.close(); For multithreade server: while(true) { i. wait for client requests (step 2 above) ii. create a thread with “client” socket as parameter (the thread creates streams (as in step (3) and does communication as stated in (4). Remove thread once service is provided. } Client side Socket Operations 1. Get connection to server: client = new Socket( server, port_id ); 2. Create I/O streams for communicating to clients is = new DataInputStream( client.getInputStream() ); os = new DataOutputStream( client.getOutputStream() ); 3. Perform communication with client Receiive from client: String line = is.readLine(); Send to client: os.writeBytes("Hello\n"); -

IP Datagram ICMP Message Format ICMP Message Types
ICMP Internet Control Message Protocol ICMP is a protocol used for exchanging control messages. CSCE 515: Two main categories Query message Computer Network Error message Programming Usage of an ICMP message is determined by type and code fields ------ IP, Ping, Traceroute ICMP uses IP to deliver messages. Wenyuan Xu ICMP messages are usually generated and processed by the IP software, not the user process. Department of Computer Science and Engineering University of South Carolina IP header ICMP Message 20 bytes CSCE515 – Computer Network Programming IP Datagram ICMP Message Format 1 byte 1 byte 1 byte 1 byte VERS HL Service Total Length Datagram ID FLAG Fragment Offset 0781516 31 TTL Protocol Header Checksum type code checksum Source Address Destination Address payload Options (if any) Data CSCE515 – Computer Network Programming CSCE515 – Computer Network Programming ICMP Message Types ICMP Address Mask Request and Reply intended for a diskless system to obtain its subnet mask. Echo Request Id and seq can be any values, and these values are Echo Response returned in the reply. Destination Unreachable Match replies with request Redirect 0781516 31 Time Exceeded type(17 or 18) code(0) checksum there are more ... identifier sequence number subnet mask CSCE515 – Computer Network Programming CSCE515 – Computer Network Programming ping Program ICMP Echo Request and Reply Available at /usr/sbin/ping Test whether another host is reachable Send ICMP echo_request to a network host -n option to set number of echo request to send -

The Transport Layer: Tutorial and Survey SAMI IREN and PAUL D
The Transport Layer: Tutorial and Survey SAMI IREN and PAUL D. AMER University of Delaware AND PHILLIP T. CONRAD Temple University Transport layer protocols provide for end-to-end communication between two or more hosts. This paper presents a tutorial on transport layer concepts and terminology, and a survey of transport layer services and protocols. The transport layer protocol TCP is used as a reference point, and compared and contrasted with nineteen other protocols designed over the past two decades. The service and protocol features of twelve of the most important protocols are summarized in both text and tables. Categories and Subject Descriptors: C.2.0 [Computer-Communication Networks]: General—Data communications; Open System Interconnection Reference Model (OSI); C.2.1 [Computer-Communication Networks]: Network Architecture and Design—Network communications; Packet-switching networks; Store and forward networks; C.2.2 [Computer-Communication Networks]: Network Protocols; Protocol architecture (OSI model); C.2.5 [Computer- Communication Networks]: Local and Wide-Area Networks General Terms: Networks Additional Key Words and Phrases: Congestion control, flow control, transport protocol, transport service, TCP/IP 1. INTRODUCTION work of routers, bridges, and communi- cation links that moves information be- In the OSI 7-layer Reference Model, the tween hosts. A good transport layer transport layer is the lowest layer that service (or simply, transport service) al- operates on an end-to-end basis be- lows applications to use a standard set tween two or more communicating of primitives and run on a variety of hosts. This layer lies at the boundary networks without worrying about differ- between these hosts and an internet- ent network interfaces and reliabilities. -

Solutions to Chapter 2
CS413 Computer Networks ASN 4 Solutions Solutions to Assignment #4 3. What difference does it make to the network layer if the underlying data link layer provides a connection-oriented service versus a connectionless service? [4 marks] Solution: If the data link layer provides a connection-oriented service to the network layer, then the network layer must precede all transfer of information with a connection setup procedure (2). If the connection-oriented service includes assurances that frames of information are transferred correctly and in sequence by the data link layer, the network layer can then assume that the packets it sends to its neighbor traverse an error-free pipe. On the other hand, if the data link layer is connectionless, then each frame is sent independently through the data link, probably in unconfirmed manner (without acknowledgments or retransmissions). In this case the network layer cannot make assumptions about the sequencing or correctness of the packets it exchanges with its neighbors (2). The Ethernet local area network provides an example of connectionless transfer of data link frames. The transfer of frames using "Type 2" service in Logical Link Control (discussed in Chapter 6) provides a connection-oriented data link control example. 4. Suppose transmission channels become virtually error-free. Is the data link layer still needed? [2 marks – 1 for the answer and 1 for explanation] Solution: The data link layer is still needed(1) for framing the data and for flow control over the transmission channel. In a multiple access medium such as a LAN, the data link layer is required to coordinate access to the shared medium among the multiple users (1). -

Retrofitting Privacy Controls to Stock Android
Saarland University Faculty of Mathematics and Computer Science Department of Computer Science Retrofitting Privacy Controls to Stock Android Dissertation zur Erlangung des Grades des Doktors der Ingenieurwissenschaften der Fakultät für Mathematik und Informatik der Universität des Saarlandes von Philipp von Styp-Rekowsky Saarbrücken, Dezember 2019 Tag des Kolloquiums: 18. Januar 2021 Dekan: Prof. Dr. Thomas Schuster Prüfungsausschuss: Vorsitzender: Prof. Dr. Thorsten Herfet Berichterstattende: Prof. Dr. Michael Backes Prof. Dr. Andreas Zeller Akademischer Mitarbeiter: Dr. Michael Schilling Zusammenfassung Android ist nicht nur das beliebteste Betriebssystem für mobile Endgeräte, sondern auch ein ein attraktives Ziel für Angreifer. Um diesen zu begegnen, nutzt Androids Sicher- heitskonzept App-Isolation und Zugangskontrolle zu kritischen Systemressourcen. Nutzer haben dabei aber nur wenige Optionen, App-Berechtigungen gemäß ihrer Bedürfnisse einzuschränken, sondern die Entwickler entscheiden über zu gewährende Berechtigungen. Androids Sicherheitsmodell kann zudem nicht durch Dritte angepasst werden, so dass Nutzer zum Schutz ihrer Privatsphäre auf die Gerätehersteller angewiesen sind. Diese Dissertation präsentiert einen Ansatz, Android mit umfassenden Privatsphäreeinstellun- gen nachzurüsten. Dabei geht es konkret um Techniken, die ohne Modifikationen des Betriebssystems oder Zugriff auf Root-Rechte auf regulären Android-Geräten eingesetzt werden können. Der erste Teil dieser Arbeit etabliert Techniken zur Durchsetzung von Sicherheitsrichtlinien -

Application Note Pre-Deployment and Network Readiness Assessment Is
Application Note Contents Title Six Steps To Getting Your Network Overview.......................................................... 1 Ready For Voice Over IP Pre-Deployment and Network Readiness Assessment Is Essential ..................... 1 Date January 2005 Types of VoIP Overview Performance Problems ...... ............................. 1 This Application Note provides enterprise network managers with a six step methodology, including pre- Six Steps To Getting deployment testing and network readiness assessment, Your Network Ready For VoIP ........................ 2 to follow when preparing their network for Voice over Deploy Network In Stages ................................. 7 IP service. Designed to help alleviate or significantly reduce call quality and network performance related Summary .......................................................... 7 problems, this document also includes useful problem descriptions and other information essential for successful VoIP deployment. Pre-Deployment and Network IP Telephony: IP Network Problems, Equipment Readiness Assessment Is Essential Configuration and Signaling Problems and Analog/ TDM Interface Problems. IP Telephony is very different from conventional data applications in that call quality IP Network Problems: is especially sensitive to IP network impairments. Existing network and “traditional” call quality Jitter -- Variation in packet transmission problems become much more obvious with time that leads to packets being the deployment of VoIP service. For network discarded in VoIP -

Ipv6-Ipsec And
IPSec and SSL Virtual Private Networks ITU/APNIC/MICT IPv6 Security Workshop 23rd – 27th May 2016 Bangkok Last updated 29 June 2014 1 Acknowledgment p Content sourced from n Merike Kaeo of Double Shot Security n Contact: [email protected] Virtual Private Networks p Creates a secure tunnel over a public network p Any VPN is not automagically secure n You need to add security functionality to create secure VPNs n That means using firewalls for access control n And probably IPsec or SSL/TLS for confidentiality and data origin authentication 3 VPN Protocols p IPsec (Internet Protocol Security) n Open standard for VPN implementation n Operates on the network layer Other VPN Implementations p MPLS VPN n Used for large and small enterprises n Pseudowire, VPLS, VPRN p GRE Tunnel n Packet encapsulation protocol developed by Cisco n Not encrypted n Implemented with IPsec p L2TP IPsec n Uses L2TP protocol n Usually implemented along with IPsec n IPsec provides the secure channel, while L2TP provides the tunnel What is IPSec? Internet IPSec p IETF standard that enables encrypted communication between peers: n Consists of open standards for securing private communications n Network layer encryption ensuring data confidentiality, integrity, and authentication n Scales from small to very large networks What Does IPsec Provide ? p Confidentiality….many algorithms to choose from p Data integrity and source authentication n Data “signed” by sender and “signature” verified by the recipient n Modification of data can be detected by signature “verification” -

Transport Layer Chapter 6
Transport Layer Chapter 6 • Transport Service • Elements of Transport Protocols • Congestion Control • Internet Protocols – UDP • Internet Protocols – TCP • Performance Issues • Delay-Tolerant Networking Revised: August 2011 CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 The Transport Layer Responsible for delivering data across networks with the desired Application reliability or quality Transport Network Link Physical CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Transport Service • Services Provided to the Upper Layer » • Transport Service Primitives » • Berkeley Sockets » • Socket Example: Internet File Server » CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Services Provided to the Upper Layers (1) Transport layer adds reliability to the network layer • Offers connectionless (e.g., UDP) and connection- oriented (e.g, TCP) service to applications CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Services Provided to the Upper Layers (2) Transport layer sends segments in packets (in frames) Segment Segment CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Transport Service Primitives (1) Primitives that applications might call to transport data for a simple connection-oriented service: • Client calls CONNECT, SEND, RECEIVE, DISCONNECT • Server calls LISTEN, RECEIVE, SEND, DISCONNECT Segment CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice -
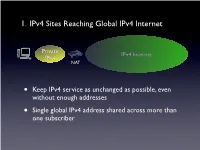
1. Ipv4 Sites Reaching Global Ipv4 Internet
1. IPv4 Sites Reaching Global IPv4 Internet Private IPv4 Internet IPv4 NAT • Keep IPv4 service as unchanged as possible, even without enough addresses • Single global IPv4 address shared across more than one subscriber SP IPv6 Network Private Tunnel for IPv4 (public, private, port-limited, etc....) IPv4 Internet IPv4 • Scenario #2 - Service Providers Running out of Private IPv4 space • IPv4 / IPv6 encapsulations/tunnels • Tunnels setup by DHCP, Routing, etc. between a GW and Router • Wherever the NAT lands, it is important that the user keeps control of it • Provides a path to delivering IPv6 SP IPv6 Network Tunnel for IPv4 (public, private, port-limited, etc....) IPv4 Internet • Scenario #3a “Wireless Greenfield” • IPv4 / IPv6 encapsulations/tunnels • Tunnels setup between a host and a Router • IPv4 binding for host applications, transport over IPv6 • Wherever the NAT lands, it is important that the user keeps control of it 3 - 5 Translation Options IPv6 Internet IPv4 Internet IPv6 IPv4 My IPv6 Network IPv6 Internet IPv4 Internet • “Scenario #3” • NAT64/DNS64.... - Stateful, DNSSEC Challenges, DNS64 location, etc. My IPv6 Network IPv6 Internet IPv4 Internet • “Scenario #5” • IVI - NAT-PT..... Expose only certain IPv6 servers, etc. MY IPv4 Network IPv6 Internet IPv4 Internet • “Scenario #4” • NAT64 - 1:1, Stateless, DNSSEC OK, no DNS64 MY IPv4 Network IPv6 Internet IPv4 Internet • Already solved by existing transition mechanisms?? (teredo, etc). Scenarios 1 - 5 1. IPv4 Sites Reaching Global IPv4 Internet Private IPv4 Internet IPv4 NAT • Keep IPv4 service as unchanged as possible, even without enough addresses • Single global IPv4 address shared across more than one subscriber 2. Service Providers Running out of Private IPv4 space ISP Private IPv4 Private Network IPv4 IPv4 Internet • Service Providers with large, privately addressed, IPv4 networks • Organic growth plus pressure to free global addresses for customer use contribute to the problem • The SP Private networks in question generally do not need to reach the Internet at large 3. -

Latency and Throughput Optimization in Modern Networks: a Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui
READY TO SUBMIT TO IEEE COMMUNICATIONS SURVEYS & TUTORIALS JOURNAL 1 Latency and Throughput Optimization in Modern Networks: A Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui Abstract—Modern applications are highly sensitive to com- On one hand every user likes to send and receive their munication delays and throughput. This paper surveys major data as quickly as possible. On the other hand the network attempts on reducing latency and increasing the throughput. infrastructure that connects users has limited capacities and These methods are surveyed on different networks and surrond- ings such as wired networks, wireless networks, application layer these are usually shared among users. There are some tech- transport control, Remote Direct Memory Access, and machine nologies that dedicate their resources to some users but they learning based transport control, are not very much commonly used. The reason is that although Index Terms—Rate and Congestion Control , Internet, Data dedicated resources are more secure they are more expensive Center, 5G, Cellular Networks, Remote Direct Memory Access, to implement. Sharing a physical channel among multiple Named Data Network, Machine Learning transmitters needs a technique to control their rate in proper time. The very first congestion network collapse was observed and reported by Van Jacobson in 1986. This caused about a I. INTRODUCTION thousand time rate reduction from 32kbps to 40bps [3] which Recent applications such as Virtual Reality (VR), au- is about a thousand times rate reduction. Since then very tonomous cars or aerial vehicles, and telehealth need high different variations of the Transport Control Protocol (TCP) throughput and low latency communication. -

Lab 6: Understanding Traditional TCP Congestion Control (HTCP, Cubic, Reno)
NETWORK TOOLS AND PROTOCOLS Lab 6: Understanding Traditional TCP Congestion Control (HTCP, Cubic, Reno) Document Version: 06-14-2019 Award 1829698 “CyberTraining CIP: Cyberinfrastructure Expertise on High-throughput Networks for Big Science Data Transfers” Lab 6: Understanding Traditional TCP Congestion Control Contents Overview ............................................................................................................................. 3 Objectives............................................................................................................................ 3 Lab settings ......................................................................................................................... 3 Lab roadmap ....................................................................................................................... 3 1 Introduction to TCP ..................................................................................................... 3 1.1 TCP review ............................................................................................................ 4 1.2 TCP throughput .................................................................................................... 4 1.3 TCP packet loss event ........................................................................................... 5 1.4 Impact of packet loss in high-latency networks ................................................... 6 2 Lab topology............................................................................................................... -

Internet Protocol Suite
InternetInternet ProtocolProtocol SuiteSuite Srinidhi Varadarajan InternetInternet ProtocolProtocol Suite:Suite: TransportTransport • TCP: Transmission Control Protocol • Byte stream transfer • Reliable, connection-oriented service • Point-to-point (one-to-one) service only • UDP: User Datagram Protocol • Unreliable (“best effort”) datagram service • Point-to-point, multicast (one-to-many), and • broadcast (one-to-all) InternetInternet ProtocolProtocol Suite:Suite: NetworkNetwork z IP: Internet Protocol – Unreliable service – Performs routing – Supported by routing protocols, • e.g. RIP, IS-IS, • OSPF, IGP, and BGP z ICMP: Internet Control Message Protocol – Used by IP (primarily) to exchange error and control messages with other nodes z IGMP: Internet Group Management Protocol – Used for controlling multicast (one-to-many transmission) for UDP datagrams InternetInternet ProtocolProtocol Suite:Suite: DataData LinkLink z ARP: Address Resolution Protocol – Translates from an IP (network) address to a network interface (hardware) address, e.g. IP address-to-Ethernet address or IP address-to- FDDI address z RARP: Reverse Address Resolution Protocol – Translates from a network interface (hardware) address to an IP (network) address AddressAddress ResolutionResolution ProtocolProtocol (ARP)(ARP) ARP Query What is the Ethernet Address of 130.245.20.2 Ethernet ARP Response IP Source 0A:03:23:65:09:FB IP Destination IP: 130.245.20.1 IP: 130.245.20.2 Ethernet: 0A:03:21:60:09:FA Ethernet: 0A:03:23:65:09:FB z Maps IP addresses to Ethernet Addresses