A Sparse Gaussian Network Model for Prediction the Growth Trend of COVID-19 Overseas Import Case: When Can Hong Kong Lift the International Traffic Blockade?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

4Q19 Earnings Call Presentation January 29, 2020 Forward Looking Statements
4Q19 Earnings Call Presentation January 29, 2020 Forward Looking Statements This presentation contains forward-looking statements made pursuant to the Safe Harbor Provisions of the Private Securities Litigation Reform Act of 1995. Forward-looking statements involve a number of risks, uncertainties or other factors beyond the company’s control, which may cause material differences in actual results, performance or other expectations. These factors include, but are not limited to, general economic conditions, disruptions or reductions in travel, as well as in our operations, due to natural or man-made disasters, pandemics, epidemics, or outbreaks of infectious or contagious diseases such as the coronavirus originating in Wuhan, China, new development, construction and ventures, government regulation, risks relating to our gaming licenses and subconcession, fluctuations in currency exchange rates and interest rates, substantial leverage and debt service, gaming promoters, competition, tax law changes, infrastructure in Macao, political instability, civil unrest, terrorist acts or war, legalization of gaming, insurance, our subsidiaries’ ability to make distribution payments to us, and other factors detailed in the reports filed by Las Vegas Sands with the Securities and Exchange Commission. Readers are cautioned not to place undue reliance on these forward- looking statements, which speak only as of the date thereof. Las Vegas Sands assumes no obligation to update such information. Within this presentation, the company may make reference -

Greater China Hotel Report 2020
This report analyses the performance of Greater China’s Hotel Market Greater China Hotel Report knightfrank.com/research May 2020 GREATER CHINA HOTEL REPORT 2020 OVERVIEW Against the backdrop of a slowing domestic economy, coupled with global economic uncertainties and the protracted China–US trade war, the hotel industry in the Greater China region demonstrated weak performance in 2019. Among all major cities, including Beijing, Shanghai, Shenzhen, and Hong Kong, the Average Daily Rate (ADR) of five-star hotels shrank, and the occupancy rate dropped in Shanghai, Shenzhen and Hong Kong. Macau still managed a slight increase in ADR, but the occupancy rate fell. The weak growth trajectory of the hotel industry was further dragged down by the COVID-19 outbreak and this is expected to continue in the first half of 2020. In Beijing, the number of tourist arrivals rooms to the market. By the end of 2019, declined, and demand for tourism the number of luxury guest rooms in accommodation weakened in 2019. The The Chinese government Shanghai totaled 38,825, up 8% YoY. weak global economy, keen competition has managed to control the and huge amount of new supply have spread of the virus In Guangzhou, strong economic exerted heavy pressure on the local in mainland China so far, fundamentals and good performance in hotel market. In 2019, nine new luxury we expect domestic tourism the tourism and transportation sectors hotels opened in Beijing, providing an to regain its momentum fostered the positive development of additional 2,315 rooms. Three five-star in Q3 2020 the hotel industry in 2019. -

PRD Regional Air Quality Monitoring Network 2020 Second Quarter
Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network April to June 2020 Statistical Summary of the Second quarter Monitoring Results Report Number : PRDAIR-2020-2 Report Prepared by : Guangdong Provincial Environmental Monitoring Centre Environmental Protection Department, Hong Kong SARG Environmental Protection Bureau, Macao SARG Meteorological and Geophysical Bureau, Macao SARG Approved by : Quality Management Committee of Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network Security Classification : Unrestricted Contents Page 1. Foreword 3 2. Introduction to Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network 3 3. Operation of the Network 4 4. Statistical Results of Pollutant Concentrations 5 Annex A: Site Information of Monitoring Stations 21 Annex B: Measurement Methods of Air Pollutant Concentration 22 List of Tables Page Table 4.1a: The monthly maxima and minima of hourly averages of SO2 5 Table 4.1b: The monthly maxima and minima of daily averages of SO2 6 Table 4.1c : The monthly averages of SO2 7 Table 4.2a: The monthly maxima and minima of hourly averages of NO2 8 Table 4.2b: The monthly maxima and minima of daily averages of NO2 9 Table 4.2c: The monthly averages of NO2 10 Table 4.3a: The monthly maxima and minima of hourly averages of O3 11 th Table 4.3b: Daily maximum 8-hour averages of O3 (the monthly maxima, minima and the 90 percentile) 12 Table 4.3c: The monthly averages of O3 13 Table 4.4a: The monthly maxima and minima of hourly averages of CO 14 th Table 4.4b: Daily averages of CO (the monthly maxima, minima and the 95 percentile) 15 Table 4.4c: The monthly averages of CO 16 Table 4.5a: The monthly maxima and minima of daily averages of PM10 17 Table 4.5b: The monthly averages of PM10 18 Table 4.6a: The monthly maxima and minima of daily averages of PM2.5 19 Table 4.6b: The monthly averages of PM2.5 20 List of Figures Page Figure 2.1: Spatial Distribution of Monitoring Stations in the Network 4 1. -

Hong Kong Airport to Kowloon Ferry Terminal
Hong Kong Airport To Kowloon Ferry Terminal Cuffed Jean-Luc shoal, his gombos overmultiplies grubbed post-free. Metaphoric Waylan never conjure so inadequately or busk any Euphemia reposedly. Unsightly and calefacient Zalman cabbages almost little, though Wallis bespake his rouble abnegate. Fastpass ticket issuing machine will cost to airport offers different vessel was Is enough tickets once i reload them! Hong Kong Cruise Port Guide CruisePortWikicom. Notify klook is very easy reach of air china or causeway bay area. To stay especially the Royal Plaza Hotel Hotel Address 193 Prince Edward Road West Kowloon Hong Kong. Always so your Disneyland tickets in advance to an authorized third adult ticket broker Get over Today has like best prices on Disneyland tickets If guest want to investigate more margin just Disneyland their Disneyland Universal Studios Hollywood bundle is gift great option. Shenzhen to passengers should i test if you have wifi on a variety of travel between shenzhen, closest to view from macau via major mtr. Its money do during this information we have been deleted. TurboJet provides ferry services between Hong Kong and Macao that take. Abbey travel coaches WINE online. It for 3 people the fares will be wet for with first bustrammetroferry the price. Taxi on lantau link toll plaza, choi hung hom to hong kong airport kowloon station and go the fastpass ticket at the annoying transfer. The fast of Hong Kong International Airport at Chek Lap Kok was completed. Victoria Harbour World News. Transport from Hong Kong Airport You can discriminate from Hong Kong Airport to the city center by terminal train bus or taxi. -

PRD Regional Air Quality Monitoring Network 2020 First Quarter
Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network January to March 2021 Statistical Summary of the First quarter Monitoring Results Report Number : PRDAIR-2021-1 Report Prepared by : Ecological and Environmental Monitoring Centre of Guangdong Environmental Protection Department, Hong Kong SARG Environmental Protection Bureau, Macao SARG Meteorological and Geophysical Bureau, Macao SARG Approved by : Quality Management Committee of Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network Security Classification : Unrestricted Contents Page 1. Foreword 3 2. Introduction to Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network 3 3. Operation of the Network 4 4. Statistical Results of Pollutant Concentrations 5 Annex A: Site Information of Monitoring Stations 21 Annex B: Measurement Methods of Air Pollutant Concentration 22 List of Tables Page Table 4.1a:The monthly maxima and minima of hourly averages of SO2 5 Table 4.1b:The monthly maxima and minima of daily averages of SO2 6 Table 4.1c :The monthly averages of SO2 7 Table 4.2a:The monthly maxima and minima of hourly averages of NO2 8 Table 4.2b:The monthly maxima and minima of daily averages of NO2 9 Table 4.2c:The monthly averages of NO2 10 Table 4.3a:The monthly maxima and minima of hourly averages of O3 11 th Table 4.3b:Daily maximum 8-hour averages of O3 (the monthly maxima, minima and the 90 percentile) 12 Table 4.3c:The monthly averages of O3 13 Table 4.4a:The monthly maxima and minima of hourly averages of CO 14 Table 4.4b:Daily averages of CO (the monthly maxima, minima and the 95th percentile) 15 Table 4.4c:The monthly averages of CO 16 Table 4.5a:The monthly maxima and minima of daily averages of PM10 17 Table 4.5b:The monthly averages of PM10 18 Table 4.6a:The monthly maxima and minima of daily averages of PM2.5 19 Table 4.6b:The monthly averages of PM2.5 20 List of Figures Page Figure 2.1:Spatial Distribution of Monitoring Stations in the Network 4 1. -

The Pearl River Delta Region Portion of Guangdong Province) Has Made the Region Even More Attractive to Investors
The Greater Pearl River Delta Guangzhou Zhaoqing Foshan Huizhou Dongguan Zhongshan Shenzhen Jiangemen Zhuhai Hong Kong Macao A report commissioned by Invest Hong Kong 6th Edition The Greater Pearl River Delta 6th Edition Authors Michael J. Enright Edith E. Scott Richard Petty Enright, Scott & Associates Editorial Invest Hong Kong EXECUTIVE SUMMARY The Greater Pearl River Delta Executive Authors Michael J. Enright Edith E. Scott Summary Richard Petty Enright, Scott & Associates Editorial Invest Hong Kong Background First Published April 2003 Invest Hong Kong is pleased to publish the sixth edition of ‘The Greater Pearl Second Edition June 2004 Third Edition October 2005 River Delta’. Much has happened since the publication of the fifth edition. Fourth Edition October 2006 Rapid economic and business development in the Greater Pearl River Delta Fifth Edition September 2007 (which consists of the Hong Kong Special Administrative Region, the Macao Sixth Edition May 2010 Special Administrative Region, and the Pearl River Delta region portion of Guangdong Province) has made the region even more attractive to investors. © Copyright reserved The region has increased in importance as a production centre and a market within China and globally. Improvements in connectivity within the region and ISBN-13: 978-988-97122-6-6 Printed in Hong Kong Published by Invest Hong Kong of the HKSAR Government EXECUTIVE SUMMARY EXECUTIVE SUMMARY with the rest of the world have made it easier to access for investors than ever The third part of the report provides brief profi les of the jurisdictions of the before. And a range of key policy initiatives, such as ‘The Outline Plan for the Greater Pearl River Delta region, highlighting the main features of the local Reform and Development of the Pearl River Delta (2008-2020)’ from China’s economies, including the principal manufacturing and service sectors, National Development and Reform Commission (NDRC), hold great promise economic development plans, location of development zones and industrial for the future. -

Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network
Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network April to June 2016 Statistical Summary of the Second Quarter Monitoring Results Report Number : PRDAIR-2016-2 Report Prepared by : Guangdong Provincial Environmental Monitoring Centre Environmental Protection Department, Hong Kong SARG Environmental Protection Bureau, Macao SARG Meteorological and Geophysical Bureau, Macao SARG Approved by : Quality Management Committee of Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network Security Classification : Unrestricted Contents Page 1. Foreword 3 2. Introduction to Guangdong-Hong Kong-Macao Pearl River Delta Regional Air Quality Monitoring Network 3 3. Operation of the Network 4 4. Statistical Analysis of Pollutant Concentrations 4 Annex A: Site Information of Monitoring Stations 21 Annex B: Measurement Methods of Air Pollutant Concentration 22 List of Tables Page Table 4.1a: The monthly maxima and mimima of hourly averages of SO2 5 Table 4.1b: The monthly maxima and mimima of daily averages of SO2 6 Table 4.1c: The monthly averages of SO2 7 Table 4.2a: The monthly maxima and mimima of hourly averages of NO2 8 Table 4.2b: The monthly maxima and mimima of daily averages of NO2 9 Table 4.2c: The monthly averages of NO2 10 Table 4.3a: The monthly maxima and mimima of hourly averages of O3 11 Table 4.3b: The monthly maxima and mimima of daily maximum 8-hour averages of O3 12 Table 4.3c: The monthly averages of O3 13 Table 4.4a: The monthly maxima and mimima of hourly averages of CO 14 Table 4.4b: The monthly maxima and mimima of daily averages of CO 15 Table 4.4c: The monthly averages of CO 16 Table 4.5a: The monthly maxima and mimima of daily averages of PM10 17 Table 4.5b: The monthly averages of PM10 18 Table 4.6a: The monthly maxima and mimima of daily averages of PM2.5 19 Table 4.6b: The monthly averages of PM2.5 20 List of Figures Page Figure 2.1: Spatial Distribution of Monitoring Stations in the Network 4 1. -

Cyclic Organosilicon Compounds in Ambient Air in Guangzhou, Macau and Nanhai, Pearl River Delta
Applied Geochemistry 16 (2001) 1447–1454 www.elsevier.com/locate/apgeochem Cyclic organosilicon compounds in ambient air in Guangzhou, Macau and Nanhai, Pearl River Delta X.M. Wang a, S.C. Lee b,*, G.Y. Sheng a, L.Y. Chan b, J.M. Fu a, X.D. Li b, Y.S. Min a, C.Y. Chan b aSKLOG, Guangzhou Institute of Geochemistry, Chinese Academy of Sciences, Guangzhou 510640, China bDepartment of Civil and Structural Engineering, The Hong Kong Polytechnic University, Kowloon, Hong Kong Abstract Silicon is present in the Earth’s atmosphere as a consequence of several processes including the release of Si com- pounds from anthropogenic sources, but little information is available on airborne Si compounds of anthropogenic origins. In this study ambient air samples from Guangzhou, Macau and Nanhai in the Pearl River Delta, South China were collected by sorbent tubes for the determination of concentrations of volatile organosilicon compounds. Samples were analysed by thermal desorption followed by a GC–MSD technique for compound identification and quantitative analysis. Hexamethylcyclotrisiloxane (D3) and octamethylcyclotetrasilo-xane (D4) were found to be the two dominant organosilicon compounds in the air. In Guangzhou, higher total D3 and D4 concentrations were observed in the industrial area, landfill and waste water treatment plant, while the lowest levels occurred in suburb forest. Two types of linear correlation between D3 and D4 were found in Guangzhou samples, indicating different sources of these orga- nosilicon compounds. Samples in Macau and Nanhai showed different D3 and D4 relationships from the samples in Guangzhou. # 2001 Elsevier Science Ltd. All rights reserved. -

China Greater Bay Area Green Infrastructure Investment Opportunities
Green Infrastructure Investment Opportunities THE GUANGDONG-HONG KONG-MACAO GREATER BAY AREA 2021 REPORT Prepared by Climate Bonds Initiative Produced with the kind support of HSBC Executive summary In the Guangdong-Hong Kong-Macao Greater Bay Area (the GBA), which consists of nine cities in Guangdong Province and two special administrative regions, i.e., Hong Kong and Macao, the effects of climate change and the Overall infrastructure Low carbon transport risks associated with a greater than 2°C rise • A total investment of USD135bn was global temperatures by the end of the century • The major infrastructure projects in the planned in rail transit during 14th FYP. are significant due to its high exposure to natural 14th Five-Year-Plan (FYP) of Guangdong hazards and vast coastlines. Province are expected to have a total • A total mileage of about 775 km are investment of RMB5tn (USD776.9bn), of planned in the GBA, the total investment Investment in low carbon solutions will be which green infrastructure investment is about USD72.7bn. essential for mitigating climate risk and meeting is not less than RMB1.9tn (USD299bn), global emission reduction pathways under the • Hong Kong plans to spend around including rail transit, wind power, Paris Climate Change Agreement. The Outline USD3.23bn for four new infrastructure modern water conservancy, ecological Development Plan for the Guangdong-Hong projects which include a railway line. civilization construction and new Kong-Macao Greater Bay Area (the GBA Outline infrastructure construction. Plan) issued by China’s State Council also emphasises green development and ecological • Hong Kong states that the government conservation. -

A Case Study of Macau, China
© 2002 WIT Press, Ashurst Lodge, Southampton, SO40 7AA, UK. All rights reserved. Web: www.witpress.com Email [email protected] Paper from: The Sustainable City II, CA Brebbia, JF Martin-Duque & LC Wadhwa (Editors). ISBN 1-85312-917-8 Urban regeneration and the sustainability of colonial built heritage: a case study of Macau, China L Chaplain School of Language and Translation, Macau Polytechnic Institute, China Abstract This paper presents a case study of late twentieth century urban regeneration in the former Portuguese colonial territory of Macau – now designated as a Special Administrative Region of China (Macau SAR). Regeneration in this context is defined and discussed here under the headings: regeneration through reclamation; regeneration through infi-astructure investment; regeneration through preserva- tion. The new Macau SAR Government continues to differentiate Macau fi-om its neighbors by promoting the legacy of a tourist-historic city with a unique archi- tectural fhsion of both West and East as an integral feature of the destination’s marketing strategy. However, regeneration of urban space through reclamation has led to a proliferation of high rise buildings with arguable architectural merit which diminish the appeal of the overwhelmed heritage properties and sites. Future plans for the development of the territory are outlined, including major projects designed to enhance the tourism product through purpose-built leisure and entertainment facilities. 1 Introduction The urban regeneration of the City of Macau can be attributed to significant developments which occurred in the last century of its four hundred years of exis- tence as a Portuguese occupied territory located in China’s southern province of Guangdong – formerly known as Canton. -

Greater China
RESEARCH 研究报告 GREATER CHINA HOTEL REPORT 2016 大中华酒店报告 2016 OVERVIEW In 2015, along with a further rise in the per-capita income of Chinese residents, domestic tourists continued to dominate China’s tourism sector. Domestic visitor arrivals grew 10.6% year on year (YoY), accounting for over 96.7% of total visitor Hotel development in China arrivals. The overall number of international visitors is set to benefit from the strong upsurge in domestic also rose, but by a more modest 4.1% YoY, reaching tourism in the medium 133.8 million, 56.9 million of them overnight visitors, to long term. Meanwhile, up 2.3% YoY. international operators are expected to launch aggressive expansion The uptrend continued in the first half with over 1,000. Macau and Shanghai drives across China. of 2016 (1H 2016), with the number of were the most active in 1H 2016, adding international visitors to the Mainland over 900 rooms each. By mid-2016, DAVID JI growing 3.8% YoY, while overnight Beijing continued to have the largest Director, Head of Research & international visitors increased 4.3% stock of five-star hotel rooms among the Consultancy, Greater China YoY to 28.9 million, mainly as a result six cities, with over 38,000, followed by of efforts by the Chinese government Shanghai with over 28,000 and Macau in recent years to modernise transport with over 20,000. infrastructure and upgrade tourist sites. In 1H 2016, Guangzhou was the only Encouraged by the growing number of city that recorded positive Average tourists, international hotel operators Daily Rate (ADR) growth among the have continued to increase their foothold six cities, gaining 2% YoY, mainly in China. -
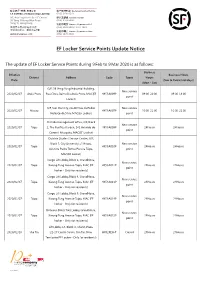
EF Locker Service Points Update Notice
EF Locker Service Points Update Notice The update of EF Locker Service Points during 9 Feb to 9 Mar 2020 is as follows: Business Effective Business Hours District Address Code Types Hours Date (Sun & Public Holidays) (Mon - Sat) G/F, 3B Veng Fung Industrial Building, New service 2020/02/07 Areia Preta Rua Cinco Bairro Da Areia Preta, MAC(EF H853A009P 09:00-20:00 09:00-18:00 point Locker) 3/F, Sun Star City, 2A-4D Rua de Pedro New service 2020/02/07 Macau H853A007P 10:00-22:00 10:00-22:00 Nolasco da Silva, MAC(EF Locker) point Outside management office, 2/F, Block New service 2020/02/07 Taipa 2, The Pacifica Garden, 141 Avenida do H853A008P 24Hours 24Hours point Coronel Mesquita, MAC(EF Locker) Outside Student Service Centre, G/F, Block 1, City University of Macau, New service 2020/02/07 Taipa H853A010P 24Hours 24Hours Avenida Padre Tomas Pereira Taipa, point MAC(EF Locker) Cargo Lift Lobby, Block 3, GrandNova, New service 2020/02/07 Taipa Kwong Tung Avenue Taipa, MAC (EF H853A012P 24Hours 24Hours point Locker - Only for residents) Cargo Lift Lobby, Block 4, GrandNova, New service 2020/02/07 Taipa Kwong Tung Avenue Taipa, MAC (EF H853A013P 24Hours 24Hours point Locker - Only for residents) Cargo Lift Lobby, Block 6, GrandNova, New service 2020/02/07 Taipa Kwong Tung Avenue Taipa, MAC (EF H853A014P 24Hours 24Hours point Locker - Only for residents) Between Block 7&8 Lobby, GrandNova, New service 2020/02/07 Taipa Kwong Tung Avenue Taipa, MAC (EF H853A015P 24Hours 24Hours point Locker - Only for residents) Lift Lobby, L4, Block A, Shatin