Computational Simulations to Predict Creatine Kinase-Associated Factors: Protein-Protein Interaction Studies of Brain and Muscle Types of Creatine Kinases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KPNA1 Antibody Cat
KPNA1 Antibody Cat. No.: 5981 Western blot analysis of KPNA1 in Hela cell lysate with KPNA1 antibody at 1μg/mL. Immunocytochemistry of KPNA1 in HeLa cells with KPNA1 antibody at 2.5 μg/mL. Immunofluorescence of KPNA1 in K562 cells with KPNA1 antibody at 20 μg/mL. Specifications HOST SPECIES: Rabbit SPECIES REACTIVITY: Human, Mouse, Rat HOMOLOGY: Predicted species reactivity based on immunogen sequence: Bovine: (100%) KPNA1 antibody was raised against a 15 amino acid synthetic peptide near the amino terminus of human KPNA1. IMMUNOGEN: The immunogen is located within amino acids 30 - 80 of KPNA1. TESTED APPLICATIONS: ELISA, ICC, IF, WB September 30, 2021 1 https://www.prosci-inc.com/kpna1-antibody-5981.html KPNA1 antibody can be used for detection of KPNA1 by Western blot at 1 μg/mL. Antibody can also be used for immunocytochemistry starting at 2.5 μg/mL. For immunofluorescence start at 20 μg/mL. APPLICATIONS: Antibody validated: Western Blot in human samples; Immunocytochemistry in human samples and Immunofluorescence in human samples. All other applications and species not yet tested. POSITIVE CONTROL: 1) Cat. No. 1201 - HeLa Cell Lysate 2) Cat. No. 17-001 - HeLa Cell Slide 3) Cat. No. 17-004 - K-562 Cell Slide Properties PURIFICATION: KPNA1 Antibody is affinity chromatography purified via peptide column. CLONALITY: Polyclonal ISOTYPE: IgG CONJUGATE: Unconjugated PHYSICAL STATE: Liquid BUFFER: KPNA1 Antibody is supplied in PBS containing 0.02% sodium azide. CONCENTRATION: 1 mg/mL KPNA1 antibody can be stored at 4˚C for three months and -20˚C, stable for up to one STORAGE CONDITIONS: year. -

Targeted Genes and Methodology Details for Neuromuscular Genetic Panels
Targeted Genes and Methodology Details for Neuromuscular Genetic Panels Reference transcripts based on build GRCh37 (hg19) interrogated by Neuromuscular Genetic Panels Next-generation sequencing (NGS) and/or Sanger sequencing is performed Motor Neuron Disease Panel to test for the presence of a mutation in these genes. Gene GenBank Accession Number Regions of homology, high GC-rich content, and repetitive sequences may ALS2 NM_020919 not provide accurate sequence. Therefore, all reported alterations detected ANG NM_001145 by NGS are confirmed by an independent reference method based on laboratory developed criteria. However, this does not rule out the possibility CHMP2B NM_014043 of a false-negative result in these regions. ERBB4 NM_005235 Sanger sequencing is used to confirm alterations detected by NGS when FIG4 NM_014845 appropriate.(Unpublished Mayo method) FUS NM_004960 HNRNPA1 NM_031157 OPTN NM_021980 PFN1 NM_005022 SETX NM_015046 SIGMAR1 NM_005866 SOD1 NM_000454 SQSTM1 NM_003900 TARDBP NM_007375 UBQLN2 NM_013444 VAPB NM_004738 VCP NM_007126 ©2018 Mayo Foundation for Medical Education and Research Page 1 of 14 MC4091-83rev1018 Muscular Dystrophy Panel Muscular Dystrophy Panel Gene GenBank Accession Number Gene GenBank Accession Number ACTA1 NM_001100 LMNA NM_170707 ANO5 NM_213599 LPIN1 NM_145693 B3GALNT2 NM_152490 MATR3 NM_199189 B4GAT1 NM_006876 MYH2 NM_017534 BAG3 NM_004281 MYH7 NM_000257 BIN1 NM_139343 MYOT NM_006790 BVES NM_007073 NEB NM_004543 CAPN3 NM_000070 PLEC NM_000445 CAV3 NM_033337 POMGNT1 NM_017739 CAVIN1 NM_012232 POMGNT2 -

Karyopherin Alpha Proteins Regulate Oligodendrocyte Differentiation
RESEARCH ARTICLE Karyopherin Alpha Proteins Regulate Oligodendrocyte Differentiation Benjamin M. Laitman1,2,3*, John N. Mariani1,2,3, Chi Zhang1,2,3, Setsu Sawai1,2,3, Gareth R. John1,2,3 1 Friedman Brain Institute, New York, New York, United States of America, 2 Corinne Goldsmith Dickinson Center for Multiple Sclerosis, New York, New York, United States of America, 3 Neurology, Icahn School of Medicine at Mount Sinai, New York, NY, New York, United States of America * [email protected] a1111111111 a1111111111 a1111111111 a1111111111 Abstract a1111111111 Proper regulation of the coordinated transcriptional program that drives oligodendrocyte (OL) differentiation is essential for central nervous system myelin formation and repair. Nuclear import, mediated in part by a group of karyopherin alpha (Kpna) proteins, regulates transcription factor access to the genome. Understanding how canonical nuclear import OPEN ACCESS functions to control genomic access in OL differentiation may aid in the creation of novel Citation: Laitman BM, Mariani JN, Zhang C, Sawai therapeutics to stimulate myelination and remyelination. Here, we show that members of S, John GR (2017) Karyopherin Alpha Proteins the Kpna family regulate OL differentiation, and may play distinct roles downstream of differ- Regulate Oligodendrocyte Differentiation. PLoS ONE 12(1): e0170477. doi:10.1371/journal. ent pro-myelinating stimuli. Multiple family members are expressed in OLs, and their phar- pone.0170477 macologic inactivation dose-dependently decreases the rate of differentiation. Additionally, Editor: Fernando de Castro, Instituto Cajal-CSIC, upon differentiation, the three major Kpna subtypes (P/α2, Q/α3, S/α1) display differential SPAIN responses to the pro-myelinating cues T3 and CNTF. -

Toxicogenomics Article
Toxicogenomics Article Discovery of Novel Biomarkers by Microarray Analysis of Peripheral Blood Mononuclear Cell Gene Expression in Benzene-Exposed Workers Matthew S. Forrest,1 Qing Lan,2 Alan E. Hubbard,1 Luoping Zhang,1 Roel Vermeulen,2 Xin Zhao,1 Guilan Li,3 Yen-Ying Wu,1 Min Shen,2 Songnian Yin,3 Stephen J. Chanock,2 Nathaniel Rothman,2 and Martyn T. Smith1 1School of Public Health, University of California, Berkeley, California, USA; 2Division of Cancer Epidemiology and Genetics, National Cancer Institute, Bethesda, Maryland, USA; 3National Institute of Occupational Health and Poison Control, Chinese Center for Disease Control and Prevention, Beijing, China were then ranked and selected for further exam- Benzene is an industrial chemical and component of gasoline that is an established cause of ination using several forms of statistical analysis. leukemia. To better understand the risk benzene poses, we examined the effect of benzene expo- We also specifically examined the expression sure on peripheral blood mononuclear cell (PBMC) gene expression in a population of shoe- of all cytokine genes on the array under the factory workers with well-characterized occupational exposures using microarrays and real-time a priori hypothesis that these key genes polymerase chain reaction (PCR). PBMC RNA was stabilized in the field and analyzed using a involved in immune function are likely to be comprehensive human array, the U133A/B Affymetrix GeneChip set. A matched analysis of six altered by benzene exposure (Aoyama 1986). exposed–control pairs was performed. A combination of robust multiarray analysis and ordering We then attempted to confirm the array find- of genes using paired t-statistics, along with bootstrapping to control for a 5% familywise error ings for the leading differentially expressed rate, was used to identify differentially expressed genes in a global analysis. -

Altered Integrin Alpha 6 Expression As a Rescue for Muscle Fiber Detachment in Zebrafish (Danio Rerio)
The University of Maine DigitalCommons@UMaine Honors College Spring 2014 Altered Integrin Alpha 6 Expression As A Rescue For Muscle Fiber Detachment In Zebrafish (Danio Rerio) Rose E. McGlauflin Follow this and additional works at: https://digitalcommons.library.umaine.edu/honors Part of the Animal Diseases Commons, and the Musculoskeletal Diseases Commons Recommended Citation McGlauflin, Rose E., Alter" ed Integrin Alpha 6 Expression As A Rescue For Muscle Fiber Detachment In Zebrafish (Danio Rerio)" (2014). Honors College. 140. https://digitalcommons.library.umaine.edu/honors/140 This Honors Thesis is brought to you for free and open access by DigitalCommons@UMaine. It has been accepted for inclusion in Honors College by an authorized administrator of DigitalCommons@UMaine. For more information, please contact [email protected]. ALTERED INTEGRIN ALPHA 6 EXPRESSION AS A RESCUE FOR MUSCLE FIBER DETACHMENT IN ZEBRAFISH (DANIO RERIO) by Rose E. McGlauflin A Thesis Submitted in Partial Fulfillment of the Requirements for a Degree with Honors (Biology) The Honors College University of Maine May 2014 Advisory Committee: Clarissa A. Henry, Ph.D., Associate Professor of Biological Sciences, Advisor Mary S. Tyler, Ph.D., Professor of Zoology Mary Astumian, Henry Lab Manager Michelle Smith, Ph.D., Assistant Professor of Biological Sciences Mark Haggerty, Ph.D., Honors Preceptor for Civic Engagement Abstract Cells adhere to their extracellular matrix by way of integrins, transmembrane molecules that attach the cytoskeleton to the extracellular basement membrane (one kind of extracellular matrix). In some muscular dystrophies, specific integrins are disrupted and muscle fibers detach from the myotendenous junction and degenerate. This integrin disruption causes a constant cycle of regeneration and degeneration, which greatly harms the tissue over time. -

Blueprint Genetics ENO3 Single Gene Test
ENO3 single gene test Test code: S00654 Phenotype information Glycogen storage disease Panels that include the ENO3 gene Glycogen Storage Disorder Panel Comprehensive Metabolism Panel Hypoglycemia, Hyperinsulinism and Ketone Metabolism Panel Metabolic Myopathy and Rhabdomyolysis Panel Test Strengths The strengths of this test include: CAP accredited laboratory CLIA-certified personnel performing clinical testing in a CLIA-certified laboratory Powerful sequencing technologies, advanced target enrichment methods and precision bioinformatics pipelines ensure superior analytical performance Careful construction of clinically effective and scientifically justified gene panels Our Nucleus online portal providing transparent and easy access to quality and performance data at the patient level Our publicly available analytic validation demonstrating complete details of test performance ~2,000 non-coding disease causing variants in our clinical grade NGS assay for panels (please see ‘Non-coding disease causing variants covered by this test’) Our rigorous variant classification scheme Our systematic clinical interpretation workflow using proprietary software enabling accurate and traceable processing of NGS data Our comprehensive clinical statements Test Limitations This test does not detect the following: Complex inversions Gene conversions Balanced translocations Mitochondrial DNA variants Repeat expansion disorders unless specifically mentioned Non-coding variants deeper than ±20 base pairs from exon-intron boundary unless otherwise indicated (please see above non-coding variants covered by the test). This test may not reliably detect the following: Low level mosaicism (variant with a minor allele fraction of 14.6% is detected with 90% probability) Stretches of mononucleotide repeats Indels larger than 50bp Single exon deletions or duplications Variants within pseudogene regions/duplicated segments The sensitivity of this test may be reduced if DNA is extracted by a laboratory other than Blueprint Genetics. -

Poised Lineage Specification in Multipotential Hematopoietic Stem
Cell Stem Cell Short Article Poised Lineage Specification in Multipotential Hematopoietic Stem and Progenitor Cells by the Polycomb Protein Bmi1 Hideyuki Oguro,1,2 Jin Yuan,1,2 Hitoshi Ichikawa,4 Tomokatsu Ikawa,5 Satoshi Yamazaki,3,6 Hiroshi Kawamoto,5 Hiromitsu Nakauchi,3,6 and Atsushi Iwama1,2,* 1Department of Cellular and Molecular Medicine, Graduate School of Medicine, Chiba University, Chiba 260-8670, Japan 2JST, CREST 3JST, ERATO Sanbancho, Chiyoda-ku, Tokyo 102-0075, Japan 4Genetics Division, National Cancer Center Research Institute, Tokyo, 104-0045, Japan 5Laboratory for Lymphocyte Development, RIKEN Research Center for Allergy and Immunology, Yokohama 230-0045, Japan 6Laboratory of Stem Cell Therapy, Center for Experimental Medicine, Institute of Medical Sciences, University of Tokyo, Tokyo 108-8679, Japan *Correspondence: [email protected] DOI 10.1016/j.stem.2010.01.005 SUMMARY Pietersen and van Lohuizen, 2008). They reside in two main complexes, termed Polycomb repressive complex 1 and 2 Polycomb group (PcG) proteins are essential regula- (PRC1 and PRC2). PRC2 and trithorax group (trxG) proteins tors of stem cells. PcG and trithorax group proteins mark developmental regulator gene promoters with bivalent mark developmental regulator gene promoters with domains consisting of overlapping repressive and activating bivalent domains consisting of overlapping repres- histone modifications to keep developmental regulators sive and activating histone modifications to keep ‘‘poised’’ for activation in embryonic stem cells (ESCs) (Bernstein them poised for activation in embryonic stem cells. et al., 2006; Spivakov and Fisher 2007; Mendenhall and Bern- stein, 2008). Likewise, in adult stem cells, developmental regula- Bmi1, a component of PcG complexes, maintains tors that govern lineage specification are supposedly repressed the self-renewal capacity of adult stem cells, but its epigenetically to maintain their multipotency (Pietersen and van role in multipotency remains obscure. -

Propranolol-Mediated Attenuation of MMP-9 Excretion in Infants with Hemangiomas
Supplementary Online Content Thaivalappil S, Bauman N, Saieg A, Movius E, Brown KJ, Preciado D. Propranolol-mediated attenuation of MMP-9 excretion in infants with hemangiomas. JAMA Otolaryngol Head Neck Surg. doi:10.1001/jamaoto.2013.4773 eTable. List of All of the Proteins Identified by Proteomics This supplementary material has been provided by the authors to give readers additional information about their work. © 2013 American Medical Association. All rights reserved. Downloaded From: https://jamanetwork.com/ on 10/01/2021 eTable. List of All of the Proteins Identified by Proteomics Protein Name Prop 12 mo/4 Pred 12 mo/4 Δ Prop to Pred mo mo Myeloperoxidase OS=Homo sapiens GN=MPO 26.00 143.00 ‐117.00 Lactotransferrin OS=Homo sapiens GN=LTF 114.00 205.50 ‐91.50 Matrix metalloproteinase‐9 OS=Homo sapiens GN=MMP9 5.00 36.00 ‐31.00 Neutrophil elastase OS=Homo sapiens GN=ELANE 24.00 48.00 ‐24.00 Bleomycin hydrolase OS=Homo sapiens GN=BLMH 3.00 25.00 ‐22.00 CAP7_HUMAN Azurocidin OS=Homo sapiens GN=AZU1 PE=1 SV=3 4.00 26.00 ‐22.00 S10A8_HUMAN Protein S100‐A8 OS=Homo sapiens GN=S100A8 PE=1 14.67 30.50 ‐15.83 SV=1 IL1F9_HUMAN Interleukin‐1 family member 9 OS=Homo sapiens 1.00 15.00 ‐14.00 GN=IL1F9 PE=1 SV=1 MUC5B_HUMAN Mucin‐5B OS=Homo sapiens GN=MUC5B PE=1 SV=3 2.00 14.00 ‐12.00 MUC4_HUMAN Mucin‐4 OS=Homo sapiens GN=MUC4 PE=1 SV=3 1.00 12.00 ‐11.00 HRG_HUMAN Histidine‐rich glycoprotein OS=Homo sapiens GN=HRG 1.00 12.00 ‐11.00 PE=1 SV=1 TKT_HUMAN Transketolase OS=Homo sapiens GN=TKT PE=1 SV=3 17.00 28.00 ‐11.00 CATG_HUMAN Cathepsin G OS=Homo -
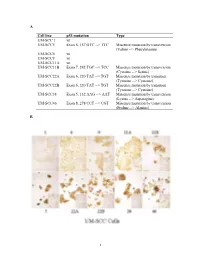
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Transcriptomic Analysis of the Aquaporin (AQP) Gene Family
Pancreatology 19 (2019) 436e442 Contents lists available at ScienceDirect Pancreatology journal homepage: www.elsevier.com/locate/pan Transcriptomic analysis of the Aquaporin (AQP) gene family interactome identifies a molecular panel of four prognostic markers in patients with pancreatic ductal adenocarcinoma Dimitrios E. Magouliotis a, b, Vasiliki S. Tasiopoulou c, Konstantinos Dimas d, * Nikos Sakellaridis d, Konstantina A. Svokos e, Alexis A. Svokos f, Dimitris Zacharoulis b, a Division of Surgery and Interventional Science, Faculty of Medical Sciences, UCL, London, UK b Department of Surgery, University of Thessaly, Biopolis, Larissa, Greece c Faculty of Medicine, School of Health Sciences, University of Thessaly, Biopolis, Larissa, Greece d Department of Pharmacology, Faculty of Medicine, School of Health Sciences, University of Thessaly, Biopolis, Larissa, Greece e The Warren Alpert Medical School of Brown University, Providence, RI, USA f Riverside Regional Medical Center, Newport News, VA, USA article info abstract Article history: Background: This study aimed to assess the differential gene expression of aquaporin (AQP) gene family Received 14 October 2018 interactome in pancreatic ductal adenocarcinoma (PDAC) using data mining techniques to identify novel Received in revised form candidate genes intervening in the pathogenicity of PDAC. 29 January 2019 Method: Transcriptome data mining techniques were used in order to construct the interactome of the Accepted 9 February 2019 AQP gene family and to determine which genes members are differentially expressed in PDAC as Available online 11 February 2019 compared to controls. The same techniques were used in order to evaluate the potential prognostic role of the differentially expressed genes. Keywords: PDAC Results: Transcriptome microarray data of four GEO datasets were incorporated, including 142 primary Aquaporin tumor samples and 104 normal pancreatic tissue samples. -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated.