Applications of in Silico Methods to Analyze the Toxicity and Estrogen T Receptor-Mediated Properties of Plant-Derived Phytochemicals ∗ K
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pureweigh®-FM
Manufacturers of Hypo-al ler gen ic Nutritional Sup ple ments PureWeigh®-FM INTRODUCED 2000 What Is It? than DHEA in stimulating the thermogenic enzymes of the liver, helping to support a leaner BMI (Body Mass PureWeigh®-FM is an encapsulated supplement companion Index) and healthy weight control. In a double blind to PureWeigh® PREMEAL Beverage containing banaba study involving 30 overweight adults, 7-KETO supported (Lagerstroemia speciosa L.) extract, green tea extract, healthy body composition and BMI when combined with taurine, 7-KETO™ DHEA, biotin, magnesium citrate and exercise.* chromium polynicotinate. PureWeigh®-FM may also be used independently of PureWeigh® PREMEAL Beverage to support • Biotin, facilitating protein, fat and carbohydrate healthy glucose metabolism and promote weight loss.* metabolism by acting as a coenzyme for numerous metabolic reactions. A clinical study reported that high Features Include dose administration of biotin helped promote healthy glucose metabolism. A number of animal studies support • Banaba extract, containing a triterpenoid compound this claim. Biotin may also act to promote transcription called corosolic acid, reported in studies to support and translation of glucokinase, an enzyme found in the healthy glucose function and absorption. A recent liver and pancreas that participates in the metabolism phase II, double-blind, placebo-controlled multi-center of glucose to form glycogen. In addition, a double-blind trial in Japan suggested that banaba extract maintained study reported that biotin supplementation may promote healthy glucose function and was well tolerated by healthy lipid metabolism, citing an inverse relationship volunteers. Furthermore, an independent U.S. between plasma biotin and total lipids.* preliminary clinical study reported statistically significant weight loss in human volunteers • Magnesium citrate, providing a highly bioavailable supplementing with a 1% corosolic acid banaba extract. -
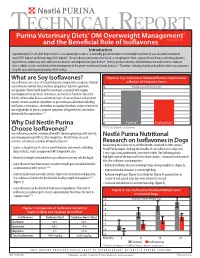
What Are Soy Isoflavones? Figure 2: Soy Isoflavones Reduced Plasma Isoprostanes Soy Isoflavones Are a Class of Natural Bioactive Compounds in Soybeans
TECHNICAL REPORT Purina Veterinary Diets® OM Overweight Management® brand canine dry formula and the Beneficial Role of Isoflavones Introduction Approximately 35% of adult dogs in the U.S. are overweight or obese1. A markedly greater incidence of overweight and obesity was observed in neutered male (59% higher) and female dogs (40% higher)1. Chronic obesity can increase the risk of, or complications from, several chronic diseases including diabetes, hypertension, pulmonary and cardiovascular disease, and degenerative joint disease2. Obesity produces chronic, mild inflammation and increases oxidative stress, which, in turn, contributes to the development of the above-mentioned chronic diseases.3,4 Therefore, reducing obesity and oxidative stress can promote a long life span and improved quality of life in dogs. What are Soy Isoflavones? Figure 2: Soy Isoflavones Reduced Plasma Isoprostanes Soy isoflavones are a class of natural bioactive compounds in soybeans. Natural a Marker of Oxidative Stress soy isoflavones include three chemical compounds: daidzein, genistein, 5 Plasma Isoprostanes (ng/ml) and glycitein. Many health benefits have been associated with regular consumption of soy products. In humans, soy has been found to reduce the 4 risk of cardiovascular disease and certain types of cancer (breast and prostate cancer); relieve a number of problems in post menopausal women including 3 hot flashes, osteoporosis, and decline in cognitive function; reduce cholesterol and triglycerides in plasma; improve symptoms of hypertension; and reduce 2 abdominal fat accumulation.5,6,7 1 Why Did Nestlé Purina 0 Control Isoflavones* Choose Isoflavones? *P<0.01 for Control vs. Isoflavones Soy isoflavones provide a number of benefits for managing dogs with obesity, and reducing rebound effects after weight loss. -

Daidzein and Genistein Content of Cereals
European Journal of Clinical Nutrition (2002) 56, 961–966 ß 2002 Nature Publishing Group All rights reserved 0954–3007/02 $25.00 www.nature.com/ejcn ORIGINAL COMMUNICATION Daidzein and genistein content of cereals J Liggins1, A Mulligan1,2, S Runswick1 and SA Bingham1,2* 1Medical Research Council Dunn Human Nutrition Unit, Hills Road, Cambridge, UK; and 2European Prospective Investigation of Cancer, University of Cambridge, Cambridge, UK Objective: To analyse 75 cereals and three soy flours commonly eaten in Europe for the phytoestrogens daidzein and genistein. Design: The phytoestrogens daidzein and genistein were extracted from dried foods, and the two isoflavones quantified after hydrolytic removal of any conjugated carbohydrate. Completeness of extraction and any procedural losses of the isoflavones 0 0 were accounted for using synthetic daidzin (7-O-glucosyl-4 -hydroxyisoflavone) and genistin (7-O-glucosyl-4 5-dihydroxyiso- flavone) as internal standards. Setting: Foods from the Cambridge UK area were purchased, prepared for eating, which included cooking if necessary, and freeze dried. Three stock soy flours were also analysed. Results: Eighteen of the foods assayed contained trace or no detectable daidzein or genistein. The soy flours were rich sources, containing 1639 – 2117 mg=kg. The concentration of the two isoflavones in the remaining foods ranged from 33 to 11 873 mg=kg. Conclusion: These analyses will supply useful information to investigators determining the intake of phytoestrogens in cereal products in order to relate intakes to potential biological activities. Sponsorship: This work was supported by the United Kingdom Medical Research Council, Ministry of Agriculture Fisheries and Food (contract FS2034) and the United States of America Army (contract DAMD 17-97-1-7028). -

Download Product Insert (PDF)
PRODUCT INFORMATION (−)-Epigallocatechin Gallate Item No. 70935 CAS Registry No.: 989-51-5 Formal Name: 3,4-dihydro-5,7-dihydroxy-2R-(3,4,5- OH trihydroxyphenyl)-2H-1-benzopyran-3R- OH yl-3,4,5-trihydroxy-benzoate H HO O Synonym: EGCG OH MF: C22H18O11 O FW: 458.4 H OH OH Purity: ≥96% O UV/Vis.: λmax: 276 nm Supplied as: A crystalline solid OH Storage: -20°C OH Stability: ≥2 years Item Origin: Plant/Folium camelliae Information represents the product specifications. Batch specific analytical results are provided on each certificate of analysis. Laboratory Procedures (−)-Epigallocatechin gallate (EGCG) is supplied as a crystalline solid. A stock solution may be made by dissolving the EGCG in an organic solvent purged with an inert gas. EGCG is soluble in organic solvents such as ethanol, DMSO, and dimethyl formamide. The solubility of EGCG in these solvents is approximately 20, 25, and 30 mg/ml, respectively. Further dilutions of the stock solution into aqueous buffers or isotonic saline should be made prior to performing biological experiments. Ensure that the residual amount of organic solvent is insignificant, since organic solvents may have physiological effects at low concentrations. Organic solvent-free aqueous solutions of EGCG can be prepared by directly dissolving the crystalline compound in aqueous buffers. The solubility of EGCG in PBS (pH 7.2) is approximately 25 mg/ml. We do not recommend storing the aqueous solution for more than one day. Description EGCG is a phenol that has been found in green and black tea plants and has diverse biological activities.1-7 1 It is lytic against T. -

Mindy Goldman, MD Clinical Professor Dept
Managing Menopause Medically and Naturally Mindy Goldman, MD Clinical Professor Dept. of Ob/Gyn and Reproductive Sciences Director, Women’s Cancer Care Program, UCSF Breast Care Center and Women’s Health University of California, San Francisco I have nothing to disclose –Mindy Goldman, MD CASE STUDY 50 yr. old G2P2 peri-menopausal woman presents with complaints of significant night sweats interfering with her ability to sleep. She has mild hot flashes during the day. She has never had a bone mineral density test but her mother had a hip fracture at age 62 due to osteoporosis. Her 46 yr. old sister was diagnosed with breast cancer at age 43, treated with lumpectomy and radiation and currently is doing well. There is no other family history of cancer. Questions 1. Would you offer her MHT? 2. If yes, how long would you continue it? 3. If no, what would you offer for alternative treatments? 4. Would your treatment differ if you knew she had underlying heart disease? Is it safe? How long can I take it? What about Mymy Bones?bones? Will it protect my heart? MHT - 2015 What about my brain? Will I get breast cancer? What about my hot flashes? Menopausal Symptoms Hot flashes Night sweats Sleep disturbances Vaginal dryness/Sexual dysfunction Mood disturbances How to Treat Menopausal Symptoms Hormone therapy Alternatives to hormones Complementary and Integrative Techniques Prior to Women’s Health Initiative Hormone therapy primary treatment of menopausal hot flashes Few women would continue hormones past one year By 1990’s well known -

Simultaneous Determination of Daidzein, Genistein and Formononetin in Coffee by Capillary Zone Electrophoresis
separations Article Simultaneous Determination of Daidzein, Genistein and Formononetin in Coffee by Capillary Zone Electrophoresis Feng Luan *, Li Li Tang, Xuan Xuan Chen and Hui Tao Liu College of Chemistry and Chemical Engineering, Yantai University, Yantai 264005, China; [email protected] (L.L.T.); [email protected] (X.X.C.); [email protected] (H.T.L.) * Correspondence: fl[email protected]; Tel.: +86-535-6902063 Academic Editor: Doo Soo Chung Received: 29 October 2016; Accepted: 20 December 2016; Published: 1 January 2017 Abstract: Coffee is a favorite and beverage in Western countries that is consumed daily. In the present study, capillary zone electrophoresis (CE) was applied for the separation and quantification of three isoflavones including daidzein, genistein and formononetin in coffee. Extraction of isoflavones from the coffee sample was carried out by extraction and purification process using ether after the acid hydrolysis with the antioxidant butylated hydroxy-toluene (BHT). The experimental conditions of the CE separation method were: 20 mmol/L Na2HPO4 buffer solution, 25 kV applied voltage, 3 s hydrodynamic injection at 30 mbar, and UV detection at 254 nm. The results show that the three compounds can be tested within 10 min with a linearity of 0.5–50 µg/mL for all three compounds. The limits of detection were 0.0642, 0.134, and 0.0825 µg/mL for daidzein, formononetin and genistein, respectively. The corresponding average recovery was 99.39% (Relative Standard Detection (RSD) = 1.76%), 98.71% (RSD = 2.11%) and 97.37% (RSD = 3.74%). Keywords: capillary zone electrophoresis (CE); daidzein; genistein; formononetin; acid hydrolysis 1. -

Contemporary Approaches for Managing Menopause Symptoms
Menopause 2017 Guidelines: Looking at Special Populations and Building on Existing Practice Patricia Geraghty, MSN, FNP-BC, WHNP Disclosures • Speaker Bureau • AbbVie • Therapeutics MD • Advisory Board • AbbVie (endometriosis) • Sharecare Inc. • Procedure Proctor • Bayer (Contraception) • Off label discussion will be included and identified in this discussion. Objectives • Identify the benefits and risks of estrogen, progesterone, and non-hormonal pharmacological management of menopause symptoms based on dosage, route of administration, pharmacokinetics, treatment population and duration of use. • Develop treatment strategies for special populations including premature ovarian insufficiency, prolonged symptoms, and women who are not candidates for estrogen. • Incorporate the NAMS 2017 Position Statement into patient counseling on the timeline of menopause symptoms and the termination of hormone therapy. Lifespan Lifespan Median 34 322 BC Aristotle describes transition Ages the Through Menopause yr JAMA. JAMA. Investigators. Initiative Health the Women's for Group Writing 2002;288(3):321 - 333. doi:10.1001/jama.288.3.321 Treated with plants s/a 1800’s cohosh, cannabis, opium 1821 French physician DeGardanne 53 lifespan lifespan calls it “Menopause” Adult - 1900’s Deficiency disease 55 1942 Premarin” copyright yr 1960’s “Forever Feminine” by Robert Wilson MD 1980’s-1990’s “Politics of Menopause” by Frances McCrea 2002 WHI- First large randomized control trial “My periods are different. Is This Menopause?” • Random cycling, sometimes early, sometimes late. • Flow variable with prodromal spotting, a long taper, or stopping and starting. • She has a day of very heavy flow. • 77% have duration 10+ days, heavy bleeding 3+ days, spotting 6+ days Paramsothy P, et al. BJOG. 2014 Nov;121(12):1564-73. -

Effect of Epigallocatechin-3-Gallate, Major Ingredient of Green Tea, on the Pharmacokinetics of Rosuvastatin in Healthy Volunteers
Journal name: Drug Design, Development and Therapy Article Designation: Original Research Year: 2017 Volume: 11 Drug Design, Development and Therapy Dovepress Running head verso: Kim et al Running head recto: Effect of green tea on the pharmacokinetics of rosuvastatin open access to scientific and medical research DOI: http://dx.doi.org/10.2147/DDDT.S130050 Open Access Full Text Article ORIGINAL RESEARCH Effect of epigallocatechin-3-gallate, major ingredient of green tea, on the pharmacokinetics of rosuvastatin in healthy volunteers Tae-Eun Kim1 Abstract: Previous in vitro studies have demonstrated the inhibitory effect of green tea on Na Ha2 drug transporters. Because rosuvastatin, a lipid-lowering drug widely used for the prevention of Yunjeong Kim2 cardiovascular events, is a substrate for many drug transporters, there is a possibility that there Hyunsook Kim1 is interaction between green tea and rosuvastatin. The aim of this study was to investigate the Jae Wook Lee3 effect of green tea on the pharmacokinetics of rosuvastatin in healthy volunteers. An open-label, Ji-Young Jeon2 three-treatment, fixed-sequence study was conducted. On Day 1, 20 mg of rosuvastatin was given to all subjects. After a 3-day washout period, the subjects received 20 mg of rosuvastatin Min-Gul Kim2,4 plus 300 mg of epigallocatechin-3-gallate (EGCG), a major ingredient of green tea (Day 4). 1 Department of Clinical After a 10-day pretreatment of EGCG up to Day 14, they received rosuvastatin (20 mg) plus Pharmacology, Konkuk University Medical Center, Seoul, 2Center for EGCG (300 mg) once again (Day 15). Blood samples for the pharmacokinetic assessments Clinical Pharmacology, Biomedical were collected up to 8 hours after each dose of rosuvastatin. -

Reducing Toxic Reactive Carbonyl Species in E-Cigarette Emissions
RSC Advances View Article Online PAPER View Journal | View Issue Reducing toxic reactive carbonyl species in e- cigarette emissions: testing a harm-reduction Cite this: RSC Adv., 2020, 10,21535 strategy based on dicarbonyl trapping Bruna de Falco, †af Antonios Petridis,†ac Poornima Paramasivan,b Antonio Dario Troise, de Andrea Scaloni,e Yusuf Deeni,b W. Edryd Stephens*c and Alberto Fiore *a Reducing the concentration of reactive carbonyl species (RCS) in e-cigarette emissions represents a major goal to control their potentially harmful effects. Here, we adopted a novel strategy of trapping carbonyls present in e-cigarette emissions by adding polyphenols in e-liquid formulations. Our work showed that the addition of gallic acid, hydroxytyrosol and epigallocatechin gallate reduced the levels of carbonyls formed in the aerosols of vaped e-cigarettes, including formaldehyde, methylglyoxal and glyoxal. Liquid chromatography mass spectrometry analysis highlighted the formation of covalent adducts between Creative Commons Attribution 3.0 Unported Licence. aromatic rings and dicarbonyls in both e-liquids and vaped samples, suggesting that dicarbonyls were formed in the e-liquids as degradation products of propylene glycol and glycerol before vaping. Short- Received 6th March 2020 term cytotoxic analysis on two lung cellular models showed that dicarbonyl-polyphenol adducts are not Accepted 29th May 2020 cytotoxic, even though carbonyl trapping did not improve cell viability. Our work sheds lights on the DOI: 10.1039/d0ra02138e ability of polyphenols to trap RCS in high carbonyl e-cigarette emissions, suggesting their potential value rsc.li/rsc-advances in commercial e-liquid formulations. Introduction smoking-related symptoms and conditions to become manifest, This article is licensed under a it is too early to evaluate the long-term clinical effects of vaping The use of e-cigarettes is a major issue in public health. -

EGCG) in Diseases with Uncontrolled Immune Activation: Could Such a Scenario Be Helpful to Counteract COVID-19?
International Journal of Molecular Sciences Review Protective Effect of Epigallocatechin-3-Gallate (EGCG) in Diseases with Uncontrolled Immune Activation: Could Such a Scenario Be Helpful to Counteract COVID-19? Marta Menegazzi 1,* , Rachele Campagnari 1, Mariarita Bertoldi 1, Rosalia Crupi 2 , Rosanna Di Paola 3 and Salvatore Cuzzocrea 3,4 1 Department of Neuroscience, Biomedicine and Movement Sciences, Biochemistry Section, School of Medicine, University of Verona, Strada Le Grazie 8, I-37134 Verona, Italy; [email protected] (R.C.); [email protected] (M.B.) 2 Department of Veterinary Science, University of Messina, Polo Universitario dell’Annunziata, I-98168 Messina, Italy; [email protected] 3 Department of Chemical, Biological, Pharmaceutical and Environmental Sciences, University of Messina, Viale Ferdinando Stagno D’Alcontres 31, I-98166 Messina, Italy; [email protected] (R.D.P.); [email protected] (S.C.) 4 Department of Pharmacological and Physiological Science, Saint Louis University School of Medicine, St. Louis, MO 63104, USA * Correspondence: [email protected] Received: 15 June 2020; Accepted: 18 July 2020; Published: 21 July 2020 Abstract: Some coronavirus disease 2019 (COVID-19) patients develop acute pneumonia which can result in a cytokine storm syndrome in response to Severe Acute Respiratory Syndrome coronavirus 2 (SARS-CoV-2) infection. The most effective anti-inflammatory drugs employed so far in severe COVID-19 belong to the cytokine-directed biological agents, widely used in the management of many autoimmune diseases. In this paper we analyze the efficacy of epigallocatechin 3-gallate (EGCG), the most abundant ingredient in green tea leaves and a well-known antioxidant, in counteracting autoimmune diseases, which are dominated by a massive cytokines production. -

Inhibitory Effect of Genistein and Daidzein on Ovarian Cancer Cell Growth
ANTICANCER RESEARCH 24: 795-800 (2004) Inhibitory Effect of Genistein and Daidzein on Ovarian Cancer Cell Growth CICEK GERCEL-TAYLOR, ANNA K. FEITELSON and DOUGLAS D. TAYLOR Department of Obstetrics, Gynecology and Women’s Health, University of Louisville, School of Medicine, Louisville, KY 40202, U.S.A. Abstract. Background: Survival from ovarian cancer has not Genistein, a soy isoflavanoid, has been intensely studied changed significantly in the past twenty years requiring in relation to breast cancer. Interest first arose upon development of additional treatment protocols. We studied the discovery of the vast difference in breast cancer rates in effect of genistein and daidzein on ovarian cancer cell growth. Asia versus Western countries (1). Large dietary differences Materials and Methods: Five ovarian cancer cell lines from Stage exist, especially in genistein consumption, as the average IIIC disease were evaluated. Sulforhodamine B and colony Asian intake is 20-80 mg/day whereas the average US intake formation assays were used to analyze growth inhibitory effects of is only 1-3 mg (2,3) The dietary and disease discrepancy genistein and daidzein alone and with cisplatin, paclitaxel or prompted further study into the chemopreventive and topotecan. Apoptosis induction was studied by determining potentially therapeutic properties of genistein. caspase-3 activity. Results: Inhibition of growth (50-80%), colony Genistein has been found to inhibit cell proliferation, formation and colony size was seen at 144 Ìm of genistein, 0-23% oncogenesis and clonogenic ability in animal and human reduction was demonstrated at 9 Ìm. At 144 Ìm, the colony size cells (3-5). Several studies have been performed to evaluate was inhibited >75%; at 9 Ìm 4/5 cell lines had >50% reduction. -

Galiellalactone Induces Cell Cycle Arrest and Apoptosis Through the ATM/ATR Pathway in Prostate Cancer Cells
www.impactjournals.com/oncotarget/ Oncotarget, Vol. 7, No. 4 Galiellalactone induces cell cycle arrest and apoptosis through the ATM/ATR pathway in prostate cancer cells Víctor García1, Maribel Lara-Chica1, Irene Cantarero1, Olov Sterner2, Marco A. Calzado1, Eduardo Muñoz1 1 Maimónides Biomedical Research Institute of Córdoba, Reina Sofía University Hospital, Department of Cell Biology, Physiology and Immunology, University of Córdoba, Córdoba, Spain 2Department of Science, Centre for Analysis and Synthesis, Lund University, Lund, Sweden Correspondence to: Marco A. Calzado, e-mail: [email protected] Eduardo Muñoz, e-mail: [email protected] Keywords: galiellalactone, cancer, cell cycle, ATM/ATR, CHK1 Received: September 11, 2015 Accepted: November 26, 2015 Published: December 14, 2015 ABSTRACT Galiellalactone (GL) is a fungal metabolite that presents antitumor activities on prostate cancer in vitro and in vivo. In this study we show that GL induced cell cycle arrest in G2/M phase, caspase-dependent apoptosis and also affected the microtubule organization and migration ability in DU145 cells. GL did not induce double strand DNA break but activated the ATR and ATM-mediated DNA damage response (DDR) inducing CHK1, H2AX phosphorylation (γH2AX) and CDC25C downregulation. Inhibition of the ATM/ATR activation with caffeine reverted GL-induced G2/M cell cycle arrest, apoptosis and DNA damage measured by γH2AX. In contrast, UCN-01, a CHK1 inhibitor, prevented GL-induced cell cycle arrest but enhanced apoptosis in DU145 cells. Furthermore, we found that GL did not increase the levels of intracellular ROS, but the antioxidant N-acetylcysteine (NAC) completely prevented the effects of GL on γH2AX, G2/M cell cycle arrest and apoptosis.