A Unified Nomenclature for Vertebrate Olfactory Receptors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genetic Variation Across the Human Olfactory Receptor Repertoire Alters Odor Perception
bioRxiv preprint doi: https://doi.org/10.1101/212431; this version posted November 1, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Genetic variation across the human olfactory receptor repertoire alters odor perception Casey Trimmer1,*, Andreas Keller2, Nicolle R. Murphy1, Lindsey L. Snyder1, Jason R. Willer3, Maira Nagai4,5, Nicholas Katsanis3, Leslie B. Vosshall2,6,7, Hiroaki Matsunami4,8, and Joel D. Mainland1,9 1Monell Chemical Senses Center, Philadelphia, Pennsylvania, USA 2Laboratory of Neurogenetics and Behavior, The Rockefeller University, New York, New York, USA 3Center for Human Disease Modeling, Duke University Medical Center, Durham, North Carolina, USA 4Department of Molecular Genetics and Microbiology, Duke University Medical Center, Durham, North Carolina, USA 5Department of Biochemistry, University of Sao Paulo, Sao Paulo, Brazil 6Howard Hughes Medical Institute, New York, New York, USA 7Kavli Neural Systems Institute, New York, New York, USA 8Department of Neurobiology and Duke Institute for Brain Sciences, Duke University Medical Center, Durham, North Carolina, USA 9Department of Neuroscience, University of Pennsylvania School of Medicine, Philadelphia, Pennsylvania, USA *[email protected] ABSTRACT The human olfactory receptor repertoire is characterized by an abundance of genetic variation that affects receptor response, but the perceptual effects of this variation are unclear. To address this issue, we sequenced the OR repertoire in 332 individuals and examined the relationship between genetic variation and 276 olfactory phenotypes, including the perceived intensity and pleasantness of 68 odorants at two concentrations, detection thresholds of three odorants, and general olfactory acuity. -

An Evolutionary Based Strategy for Predicting Rational Mutations in G Protein-Coupled Receptors
Ecology and Evolutionary Biology 2021; 6(3): 53-77 http://www.sciencepublishinggroup.com/j/eeb doi: 10.11648/j.eeb.20210603.11 ISSN: 2575-3789 (Print); ISSN: 2575-3762 (Online) An Evolutionary Based Strategy for Predicting Rational Mutations in G Protein-Coupled Receptors Miguel Angel Fuertes*, Carlos Alonso Department of Microbiology, Centre for Molecular Biology “Severo Ochoa”, Spanish National Research Council and Autonomous University, Madrid, Spain Email address: *Corresponding author To cite this article: Miguel Angel Fuertes, Carlos Alonso. An Evolutionary Based Strategy for Predicting Rational Mutations in G Protein-Coupled Receptors. Ecology and Evolutionary Biology. Vol. 6, No. 3, 2021, pp. 53-77. doi: 10.11648/j.eeb.20210603.11 Received: April 24, 2021; Accepted: May 11, 2021; Published: July 13, 2021 Abstract: Capturing conserved patterns in genes and proteins is important for inferring phenotype prediction and evolutionary analysis. The study is focused on the conserved patterns of the G protein-coupled receptors, an important superfamily of receptors. Olfactory receptors represent more than 2% of our genome and constitute the largest family of G protein-coupled receptors, a key class of drug targets. As no crystallographic structures are available, mechanistic studies rely on the use of molecular dynamic modelling combined with site-directed mutagenesis data. In this paper, we hypothesized that human-mouse orthologs coding for G protein-coupled receptors maintain, at speciation events, shared compositional structures independent, to some extent, of their percent identity as reveals a method based in the categorization of nucleotide triplets by their gross composition. The data support the consistency of the hypothesis, showing in ortholog G protein-coupled receptors the presence of emergent shared compositional structures preserved at speciation events. -
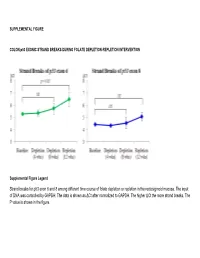
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

KLF3 and PAX6 Are Candidate Driver Genes in Late-Stage, MSI-Hypermutated Endometrioid
medRxiv preprint doi: https://doi.org/10.1101/2021.04.26.21256125; this version posted April 30, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. This article is a US Government work. It is not subject to copyright under 17 USC 105 and is also made available for use under a CC0 license. 1 KLF3 and PAX6 are candidate driver genes in late-stage, MSI-hypermutated endometrioid 2 endometrial carcinomas 3 4 Meghan L. Rudd1,#a, Nancy F. Hansen1, Xiaolu Zhang1#b, Mary Ellen Urick1, Suiyuan Zhang2, 5 Maria J. Merino3, National Institutes of Health Intramural Sequencing Center Comparative 6 Sequencing Program4; James C. Mullikin1, Lawrence C. Brody5, and Daphne W. Bell1* 7 8 1 Cancer Genetics and Comparative Genomics Branch, National Human Genome Research 9 Institute, National Institutes of Health, Bethesda, Maryland, United States of America. 10 2 Computational and Statistical Genomics Branch, National Human Genome Research Institute, 11 National Institutes of Health, Bethesda, Maryland, United States of America. 12 3 Laboratory of Pathology, Center for Cancer Research, National Cancer Institute, National 13 Institutes of Health, Bethesda, Maryland, United States of America. 14 4 NIH Intramural Sequencing Center, National Human Genome Research Institute, National 15 Institutes of Health, Rockville, Maryland, United States of America. 16 5 Medical Genomics and Metabolic Genetics Branch, National Human Genome Research 17 Institute, National Institutes of Health, Bethesda, Maryland, United States of America. 18 #a Current address: NIH Training Center, Workforce Support and Development Division, 19 National Institutes of Health, Bethesda, Maryland, United States of America. -

Molecular Triggers of Symptoms of Parosmia and Insights Into the Underlying Mechanism
Molecular triggers of symptoms of parosmia and insights into the underlying mechanism Simon Gane ( [email protected] ) Royal National Ear, Nose and Throat and Eastman Dental Hospitals Jane Parker University of Reading https://orcid.org/0000-0003-4121-5481 Christine Kelly AbScent Article Keywords: coffee, COVID-19, GC-olfactometry, mis-wiring, olfactory disorder, parosmia Posted Date: June 29th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-583178/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/21 Abstract The molecular stimuli that trigger a parosmic response have been identied. Parosmia is a debilitating condition in which familiar smells become distorted and unpleasant, frequently leading to clinical depression. Often a result of post infectious smell loss, incidences are increasing as COVID-19 cases escalate worldwide. Until now, there was little understanding of its pathophysiology, and the prevailing hypothesis for the underlying mechanism is a mis-wiring of olfactory sensory neurons. However, with novel application of avour chemistry techniques as a relatively rapid screening tool for assessment of both quantitative and qualitative olfactory loss, we identied 15 different molecular triggers in coffee. This provides evidence for peripheral causation, but places constraints on the mis-wiring theory. Furthermore, it provides the basis for development of a practical diagnostic tool and treatment strategies. Introduction Prior to the COVID-19 pandemic, olfactory dysfunction was largely unrecognised, and often underestimated by health care professionals. Since the spread of SARS-CoV-2, and the realisation that 50-65% of cases result in anosmia (the loss of sense of smell)1, there is a greater awareness of the debilitating effect of olfactory disorders2. -

The Effect of Compound L19 on Human Colorectal Cells (DLD-1)
Stephen F. Austin State University SFA ScholarWorks Electronic Theses and Dissertations Spring 5-16-2018 The Effect of Compound L19 on Human Colorectal Cells (DLD-1) Sepideh Mohammadhosseinpour [email protected] Follow this and additional works at: https://scholarworks.sfasu.edu/etds Part of the Biotechnology Commons Tell us how this article helped you. Repository Citation Mohammadhosseinpour, Sepideh, "The Effect of Compound L19 on Human Colorectal Cells (DLD-1)" (2018). Electronic Theses and Dissertations. 188. https://scholarworks.sfasu.edu/etds/188 This Thesis is brought to you for free and open access by SFA ScholarWorks. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of SFA ScholarWorks. For more information, please contact [email protected]. The Effect of Compound L19 on Human Colorectal Cells (DLD-1) Creative Commons License This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 4.0 License. This thesis is available at SFA ScholarWorks: https://scholarworks.sfasu.edu/etds/188 The Effect of Compound L19 on Human Colorectal Cells (DLD-1) By Sepideh Mohammadhosseinpour, Master of Science Presented to the Faculty of the Graduate School of Stephen F. Austin State University In Partial Fulfillment Of the Requirements For the Degree of Master of Science in Biotechnology STEPHEN F. AUSTIN STATE UNIVERSITY May, 2018 The Effect of Compound L19 on Human Colorectal Cells (DLD-1) By Sepideh Mohammadhosseinpour, Master of Science APPROVED: Dr. Beatrice A. Clack, Thesis Director Dr. Josephine Taylor, Committee Member Dr. Rebecca Parr, Committee Member Dr. Stephen Mullin, Committee Member Pauline Sampson, Ph.D. -

Positive Selection, Relaxation, and Acceleration in the Evolution of the Human and Chimp Genome
Positive Selection, Relaxation, and Acceleration in the Evolution of the Human and Chimp Genome Leonardo Arbiza1, Joaquı´n Dopazo2, Herna´n Dopazo1* 1 Pharmacogenomics and Comparative Genomics Unit, Centro de Investigacio´nPrı´ncipe Felipe (CIPF), Valencia, Spain, 2 Functional Genomics Unit, Bioinformatics Department, Centro de Investigacio´nPrı´ncipe Felipe (CIPF), Valencia, Spain For years evolutionary biologists have been interested in searching for the genetic bases underlying humanness. Recent efforts at a large or a complete genomic scale have been conducted to search for positively selected genes in human and in chimp. However, recently developed methods allowing for a more sensitive and controlled approach in the detection of positive selection can be employed. Here, using 13,198 genes, we have deduced the sets of genes involved in rate acceleration, positive selection, and relaxation of selective constraints in human, in chimp, and in their ancestral lineage since the divergence from murids. Significant deviations from the strict molecular clock were observed in 469 human and in 651 chimp genes. The more stringent branch-site test of positive selection detected 108 human and 577 chimp positively selected genes. An important proportion of the positively selected genes did not show a significant acceleration in rates, and similarly, many of the accelerated genes did not show significant signals of positive selection. Functional differentiation of genes under rate acceleration, positive selection, and relaxation was not statistically significant between human and chimp with the exception of terms related to G-protein coupled receptors and sensory perception. Both of these were over-represented under relaxation in human in relation to chimp. -

The Hypothalamus As a Hub for SARS-Cov-2 Brain Infection and Pathogenesis
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.08.139329; this version posted June 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The hypothalamus as a hub for SARS-CoV-2 brain infection and pathogenesis Sreekala Nampoothiri1,2#, Florent Sauve1,2#, Gaëtan Ternier1,2ƒ, Daniela Fernandois1,2 ƒ, Caio Coelho1,2, Monica ImBernon1,2, Eleonora Deligia1,2, Romain PerBet1, Vincent Florent1,2,3, Marc Baroncini1,2, Florence Pasquier1,4, François Trottein5, Claude-Alain Maurage1,2, Virginie Mattot1,2‡, Paolo GiacoBini1,2‡, S. Rasika1,2‡*, Vincent Prevot1,2‡* 1 Univ. Lille, Inserm, CHU Lille, Lille Neuroscience & Cognition, DistAlz, UMR-S 1172, Lille, France 2 LaBoratorY of Development and PlasticitY of the Neuroendocrine Brain, FHU 1000 daYs for health, EGID, School of Medicine, Lille, France 3 Nutrition, Arras General Hospital, Arras, France 4 Centre mémoire ressources et recherche, CHU Lille, LiCEND, Lille, France 5 Univ. Lille, CNRS, INSERM, CHU Lille, Institut Pasteur de Lille, U1019 - UMR 8204 - CIIL - Center for Infection and ImmunitY of Lille (CIIL), Lille, France. # and ƒ These authors contriButed equallY to this work. ‡ These authors directed this work *Correspondence to: [email protected] and [email protected] Short title: Covid-19: the hypothalamic hypothesis 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.06.08.139329; this version posted June 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Supplementary Table 1
Supplementary Table 1. List of genes that encode proteins contianing cell surface epitopes and are represented on Agilent human 1A V2 microarray chip (2,177 genes) Agilent Probe ID Gene Symbol GenBank ID UniGene ID A_23_P103803 FCRH3 AF459027 Hs.292449 A_23_P104811 TREH AB000824 Hs.129712 A_23_P105100 IFITM2 X57351 Hs.174195 A_23_P107036 C17orf35 X51804 Hs.514009 A_23_P110736 C9 BC020721 Hs.1290 A_23_P111826 SPAM1 NM_003117 Hs.121494 A_23_P119533 EFNA2 AJ007292 No-Data A_23_P120105 KCNS3 BC004987 Hs.414489 A_23_P128195 HEM1 NM_005337 Hs.182014 A_23_P129332 PKD1L2 BC014157 Hs.413525 A_23_P130203 SYNGR2 AJ002308 Hs.464210 A_23_P132700 TDGF1 X14253 Hs.385870 A_23_P1331 COL13A1 NM_005203 Hs.211933 A_23_P138125 TOSO BC006401 Hs.58831 A_23_P142830 PLA2R1 U17033 Hs.410477 A_23_P146506 GOLPH2 AF236056 Hs.494337 A_23_P149569 MG29 No-Data No-Data A_23_P150590 SLC22A9 NM_080866 Hs.502772 A_23_P151166 MGC15619 BC009731 Hs.334637 A_23_P152620 TNFSF13 NM_172089 Hs.54673 A_23_P153986 KCNJ3 U39196 No-Data A_23_P154855 KCNE1 NM_000219 Hs.121495 A_23_P157380 KCTD7 AK056631 Hs.520914 A_23_P157428 SLC10A5 AK095808 Hs.531449 A_23_P160159 SLC2A5 BC001820 Hs.530003 A_23_P162162 KCTD14 NM_023930 Hs.17296 A_23_P162668 CPM BC022276 Hs.334873 A_23_P164341 VAMP2 AL050223 Hs.25348 A_23_P165394 SLC30A6 NM_017964 Hs.552598 A_23_P167276 PAQR3 AK055774 Hs.368305 A_23_P170636 KCNH8 AY053503 Hs.475656 A_23_P170736 MMP17 NM_016155 Hs.159581 A_23_P170959 LMLN NM_033029 Hs.518540 A_23_P19042 GABRB2 NM_021911 Hs.87083 A_23_P200361 CLCN6 X83378 Hs.193043 A_23_P200710 PIK3C2B -

Gnomad Lof Supplement
1 gnomAD supplement gnomAD supplement 1 Data processing 4 Alignment and read processing 4 Variant Calling 4 Coverage information 5 Data processing 5 Sample QC 7 Hard filters 7 Supplementary Table 1 | Sample counts before and after hard and release filters 8 Supplementary Table 2 | Counts by data type and hard filter 9 Platform imputation for exomes 9 Supplementary Table 3 | Exome platform assignments 10 Supplementary Table 4 | Confusion matrix for exome samples with Known platform labels 11 Relatedness filters 11 Supplementary Table 5 | Pair counts by degree of relatedness 12 Supplementary Table 6 | Sample counts by relatedness status 13 Population and subpopulation inference 13 Supplementary Figure 1 | Continental ancestry principal components. 14 Supplementary Table 7 | Population and subpopulation counts 16 Population- and platform-specific filters 16 Supplementary Table 8 | Summary of outliers per population and platform grouping 17 Finalizing samples in the gnomAD v2.1 release 18 Supplementary Table 9 | Sample counts by filtering stage 18 Supplementary Table 10 | Sample counts for genomes and exomes in gnomAD subsets 19 Variant QC 20 Hard filters 20 Random Forest model 20 Features 21 Supplementary Table 11 | Features used in final random forest model 21 Training 22 Supplementary Table 12 | Random forest training examples 22 Evaluation and threshold selection 22 Final variant counts 24 Supplementary Table 13 | Variant counts by filtering status 25 Comparison of whole-exome and whole-genome coverage in coding regions 25 Variant annotation 30 Frequency and context annotation 30 2 Functional annotation 31 Supplementary Table 14 | Variants observed by category in 125,748 exomes 32 Supplementary Figure 5 | Percent observed by methylation. -

Late-Onset Pattern Macular Dystrophy Mimicking ABCA4 and PRPH2 Disease Is Caused by a Homozygous Frameshift Mutation in ROM1
COLD SPRING HARBOR Molecular Case Studies | RAPID COMMUNICATION Late-onset pattern macular dystrophy mimicking ABCA4 and PRPH2 disease is caused by a homozygous frameshift mutation in ROM1 Chu Jian Ma,1 Winston Lee,1 Nicholas Stong,2 Jana Zernant,1 Stanley Chang,1 David Goldstein,2 Takayuki Nagasaki,1 and Rando Allikmets1,3 1Department of Ophthalmology, College of Physicians and Surgeons, 2Institute of Genomic Medicine, 3Department of Pathology and Cell Biology, Columbia University, New York, New York 10032, USA Abstract ROM1 (retinal outer segment membrane protein 1) is a 351-amino acid integral membrane protein on Chromosome 11q, with high structural similarity to PRPH2/RDS. Localized at the rims of photoreceptor outer segments (OSs), it is required for the mainte- nance of OS structure. Here, we describe a case with a phenotypic manifestation of a homozygous single-base pair deletion, c.712delC (p.Leu238Cysfs∗78) in the ROM1 gene, resulting in early termination at exon 2. The variant was detected by whole-exome sequenc- ing (WES) in a 63-yr-old Caucasian woman with late-onset pattern macular dystrophy. Notably, although the phenotype resembles those caused by pathogenic variants in ABCA4 or RDS/PRPH2, no pathogenic variants in these, or any other plausible candidate genes, were identified by WES. Clinical features include the presence of hyperautofluores- cent flecks, relative sparing of the central macula, and preserved visual acuity. Reduced visual sensitivity was detected among flecked regions in the retina; however, full-field elec- troretinogram testing revealed no generalized cone dysfunction. The described first case of the complete loss of ROM1 protein function in the retina suggests its sufficiency for late- onset macular dystrophy. -

Amino Acid Sequences Directed Against Cxcr4 And
(19) TZZ ¥¥_T (11) EP 2 285 833 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C07K 16/28 (2006.01) A61K 39/395 (2006.01) 17.12.2014 Bulletin 2014/51 A61P 31/18 (2006.01) A61P 35/00 (2006.01) (21) Application number: 09745851.7 (86) International application number: PCT/EP2009/056026 (22) Date of filing: 18.05.2009 (87) International publication number: WO 2009/138519 (19.11.2009 Gazette 2009/47) (54) AMINO ACID SEQUENCES DIRECTED AGAINST CXCR4 AND OTHER GPCRs AND COMPOUNDS COMPRISING THE SAME GEGEN CXCR4 UND ANDERE GPCR GERICHTETE AMINOSÄURESEQUENZEN SOWIE VERBINDUNGEN DAMIT SÉQUENCES D’ACIDES AMINÉS DIRIGÉES CONTRE CXCR4 ET AUTRES GPCR ET COMPOSÉS RENFERMANT CES DERNIÈRES (84) Designated Contracting States: (74) Representative: Hoffmann Eitle AT BE BG CH CY CZ DE DK EE ES FI FR GB GR Patent- und Rechtsanwälte PartmbB HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL Arabellastraße 30 PT RO SE SI SK TR 81925 München (DE) (30) Priority: 16.05.2008 US 53847 P (56) References cited: 02.10.2008 US 102142 P EP-A- 1 316 801 WO-A-99/50461 WO-A-03/050531 WO-A-03/066830 (43) Date of publication of application: WO-A-2006/089141 WO-A-2007/051063 23.02.2011 Bulletin 2011/08 • VADAY GAYLE G ET AL: "CXCR4 and CXCL12 (73) Proprietor: Ablynx N.V. (SDF-1) in prostate cancer: inhibitory effects of 9052 Ghent-Zwijnaarde (BE) human single chain Fv antibodies" CLINICAL CANCER RESEARCH, THE AMERICAN (72) Inventors: ASSOCIATION FOR CANCER RESEARCH, US, • BLANCHETOT, Christophe vol.10, no.