Simulation and Analysis of Loss in Ip Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Application Note Pre-Deployment and Network Readiness Assessment Is
Application Note Contents Title Six Steps To Getting Your Network Overview.......................................................... 1 Ready For Voice Over IP Pre-Deployment and Network Readiness Assessment Is Essential ..................... 1 Date January 2005 Types of VoIP Overview Performance Problems ...... ............................. 1 This Application Note provides enterprise network managers with a six step methodology, including pre- Six Steps To Getting deployment testing and network readiness assessment, Your Network Ready For VoIP ........................ 2 to follow when preparing their network for Voice over Deploy Network In Stages ................................. 7 IP service. Designed to help alleviate or significantly reduce call quality and network performance related Summary .......................................................... 7 problems, this document also includes useful problem descriptions and other information essential for successful VoIP deployment. Pre-Deployment and Network IP Telephony: IP Network Problems, Equipment Readiness Assessment Is Essential Configuration and Signaling Problems and Analog/ TDM Interface Problems. IP Telephony is very different from conventional data applications in that call quality IP Network Problems: is especially sensitive to IP network impairments. Existing network and “traditional” call quality Jitter -- Variation in packet transmission problems become much more obvious with time that leads to packets being the deployment of VoIP service. For network discarded in VoIP -

Latency and Throughput Optimization in Modern Networks: a Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui
READY TO SUBMIT TO IEEE COMMUNICATIONS SURVEYS & TUTORIALS JOURNAL 1 Latency and Throughput Optimization in Modern Networks: A Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui Abstract—Modern applications are highly sensitive to com- On one hand every user likes to send and receive their munication delays and throughput. This paper surveys major data as quickly as possible. On the other hand the network attempts on reducing latency and increasing the throughput. infrastructure that connects users has limited capacities and These methods are surveyed on different networks and surrond- ings such as wired networks, wireless networks, application layer these are usually shared among users. There are some tech- transport control, Remote Direct Memory Access, and machine nologies that dedicate their resources to some users but they learning based transport control, are not very much commonly used. The reason is that although Index Terms—Rate and Congestion Control , Internet, Data dedicated resources are more secure they are more expensive Center, 5G, Cellular Networks, Remote Direct Memory Access, to implement. Sharing a physical channel among multiple Named Data Network, Machine Learning transmitters needs a technique to control their rate in proper time. The very first congestion network collapse was observed and reported by Van Jacobson in 1986. This caused about a I. INTRODUCTION thousand time rate reduction from 32kbps to 40bps [3] which Recent applications such as Virtual Reality (VR), au- is about a thousand times rate reduction. Since then very tonomous cars or aerial vehicles, and telehealth need high different variations of the Transport Control Protocol (TCP) throughput and low latency communication. -

Lab 6: Understanding Traditional TCP Congestion Control (HTCP, Cubic, Reno)
NETWORK TOOLS AND PROTOCOLS Lab 6: Understanding Traditional TCP Congestion Control (HTCP, Cubic, Reno) Document Version: 06-14-2019 Award 1829698 “CyberTraining CIP: Cyberinfrastructure Expertise on High-throughput Networks for Big Science Data Transfers” Lab 6: Understanding Traditional TCP Congestion Control Contents Overview ............................................................................................................................. 3 Objectives............................................................................................................................ 3 Lab settings ......................................................................................................................... 3 Lab roadmap ....................................................................................................................... 3 1 Introduction to TCP ..................................................................................................... 3 1.1 TCP review ............................................................................................................ 4 1.2 TCP throughput .................................................................................................... 4 1.3 TCP packet loss event ........................................................................................... 5 1.4 Impact of packet loss in high-latency networks ................................................... 6 2 Lab topology............................................................................................................... -

Adaptive Method for Packet Loss Types in Iot: an Naive Bayes Distinguisher
electronics Article Adaptive Method for Packet Loss Types in IoT: An Naive Bayes Distinguisher Yating Chen , Lingyun Lu *, Xiaohan Yu * and Xiang Li School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China; [email protected] (Y.C.); [email protected] (X.L.) * Correspondence: [email protected] (L.L.); [email protected] (X.Y.) Received: 31 December 2018; Accepted: 23 January 2019; Published: 28 January 2019 Abstract: With the rapid development of IoT (Internet of Things), massive data is delivered through trillions of interconnected smart devices. The heterogeneous networks trigger frequently the congestion and influence indirectly the application of IoT. The traditional TCP will highly possible to be reformed supporting the IoT. In this paper, we find the different characteristics of packet loss in hybrid wireless and wired channels, and develop a novel congestion control called NB-TCP (Naive Bayesian) in IoT. NB-TCP constructs a Naive Bayesian distinguisher model, which can capture the packet loss state and effectively classify the packet loss types from the wireless or the wired. More importantly, it cannot cause too much load on the network, but has fast classification speed, high accuracy and stability. Simulation results using NS2 show that NB-TCP achieves up to 0.95 classification accuracy and achieves good throughput, fairness and friendliness in the hybrid network. Keywords: Internet of Things; wired/wireless hybrid network; TCP; naive bayesian model 1. Introduction The Internet of Things (IoT) is a new network industry based on Internet, mobile communication networks and other technologies, which has wide applications in industrial production, intelligent transportation, environmental monitoring and smart homes. -
Congestion Control Overview
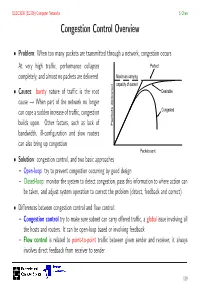
ELEC3030 (EL336) Computer Networks S Chen Congestion Control Overview • Problem: When too many packets are transmitted through a network, congestion occurs At very high traffic, performance collapses Perfect completely, and almost no packets are delivered Maximum carrying capacity of subnet • Causes: bursty nature of traffic is the root Desirable cause → When part of the network no longer can cope a sudden increase of traffic, congestion Congested builds upon. Other factors, such as lack of Packets delivered bandwidth, ill-configuration and slow routers can also bring up congestion Packets sent • Solution: congestion control, and two basic approaches – Open-loop: try to prevent congestion occurring by good design – Closed-loop: monitor the system to detect congestion, pass this information to where action can be taken, and adjust system operation to correct the problem (detect, feedback and correct) • Differences between congestion control and flow control: – Congestion control try to make sure subnet can carry offered traffic, a global issue involving all the hosts and routers. It can be open-loop based or involving feedback – Flow control is related to point-to-point traffic between given sender and receiver, it always involves direct feedback from receiver to sender 119 ELEC3030 (EL336) Computer Networks S Chen Open-Loop Congestion Control • Prevention: Different policies at various layers can affect congestion, and these are summarised in the table • e.g. retransmission policy at data link layer Transport Retransmission policy • Out-of-order caching -

The Effects of Different Congestion Control Algorithms Over Multipath Fast Ethernet Ipv4/Ipv6 Environments
Proceedings of the 11th International Conference on Applied Informatics Eger, Hungary, January 29–31, 2020, published at http://ceur-ws.org The Effects of Different Congestion Control Algorithms over Multipath Fast Ethernet IPv4/IPv6 Environments Szabolcs Szilágyi, Imre Bordán Faculty of Informatics, University of Debrecen, Hungary [email protected] [email protected] Abstract The TCP has been in use since the seventies and has later become the predominant protocol of the internet for reliable data transfer. Numerous TCP versions has seen the light of day (e.g. TCP Cubic, Highspeed, Illinois, Reno, Scalable, Vegas, Veno, etc.), which in effect differ from each other in the algorithms used for detecting network congestion. On the other hand, the development of multipath communication tech- nologies is one today’s relevant research fields. What better proof of this, than that of the MPTCP (Multipath TCP) being integrated into multiple operating systems shortly after its standardization. The MPTCP proves to be very effective for multipath TCP-based data transfer; however, its main drawback is the lack of support for multipath com- munication over UDP, which can be important when forwarding multimedia traffic. The MPT-GRE software developed at the Faculty of Informatics, University of Debrecen, supports operation over both transfer protocols. In this paper, we examine the effects of different TCP congestion control mechanisms on the MPTCP and the MPT-GRE multipath communication technologies. Keywords: congestion control, multipath communication, MPTCP, MPT- GRE, transport protocols. 1. Introduction In 1974, the TCP was defined in RFC 675 under the Transmission Control Pro- gram name. Later, the Transmission Control Program was split into two modular Copyright © 2020 for this paper by its authors. -

What Causes Packet Loss IP Networks
What Causes Packet Loss IP Networks (Rev 1.1) Computer Modules, Inc. DVEO Division 11409 West Bernardo Court San Diego, CA 92127, USA Telephone: +1 858 613 1818 Fax: +1 858 613 1815 www.dveo.com Copyright © 2016 Computer Modules, Inc. All Rights Reserved. DVEO, DOZERbox, DOZER Racks and DOZER ARQ are trademarks of Computer Modules, Inc. Specifications and product availability are subject to change without notice. Packet Loss and Reasons Introduction This Document To stream high quality video, i.e. to transmit real-time video streams, over IP networks is a demanding endeavor and, depending on network conditions, may result in packets being dropped or “lost” for a variety of reasons, thus negatively impacting the quality of user experience (QoE). This document looks at typical reasons and causes for what is generally referred to as “packet loss” across various types of IP networks, whether of the managed and conditioned type with a defined Quality of Service (QoS), or the “unmanaged” kind such as the vast variety of individual and interconnected networks across the globe that collectively constitute the public Internet (“the Internet”). The purpose of this document is to encourage operators and enterprises that wish to overcome streaming video quality problems to explore potential solutions. Proven technology exists that enables transmission of real-time video error-free over all types of IP networks, and to perform live broadcasting of studio quality content over the “unmanaged” Internet! Core Protocols of the Internet Protocol Suite The Internet Protocol (IP) is the foundation on which the Internet was built and, by extension, the World Wide Web, by enabling global internetworking. -

Packet Loss Burstiness: Measurements and Implications for Distributed Applications
Packet Loss Burstiness: Measurements and Implications for Distributed Applications David X. Wei1,PeiCao2,StevenH.Low1 1Division of Engineering and Applied Science 2Department of Computer Science California Institute of Technology Stanford University Pasadena, CA 91125 USA Stanford, CA 94305 USA {weixl,slow}@cs.caltech.edu [email protected] Abstract sources. The most commonly used control protocol for re- liable data transmission is Transmission Control Protocol Many modern massively distributed systems deploy thou- (TCP) [18], with a variety of congestion control algorithms sands of nodes to cooperate on a computation task. Net- (Reno [5], NewReno [11], etc.), and implementations (e.g. work congestions occur in these systems. Most applications TCP Pacing [16, 14]). The most commonly used control rely on congestion control protocols such as TCP to protect protocol for unreliable data transmission is TCP Friendly the systems from congestion collapse. Most TCP conges- Rate Control (TFRC) [10]. These algorithms all use packet tion control algorithms use packet loss as signal to detect loss as the congestion signal. In designs of these protocols, congestion. it is assumed that the packet loss process provides signals In this paper, we study the packet loss process in sub- that can be detected by every flow sharing the network and round-trip-time (sub-RTT) timescale and its impact on the hence the protocols can achieve fair share of the network loss-based congestion control algorithms. Our study sug- resource and, at the same time, avoid congestion collapse. gests that the packet loss in sub-RTT timescale is very bursty. This burstiness leads to two effects. -

A Network Congestion Control Protocol (NCP)
A Network Congestion control Protocol (NCP) Debessay Fesehaye, Klara Nahrstedt and Matthew Caesar Department of Computer Science UIUC, 201 N Goodwin Ave Urbana, IL 61801-2302, USA Email:{dkassa2,klara,caesar}@cs.uiuc.edu Abstract The transmission control protocol (TCP) which is the dominant congestion control protocol at the transport layer is proved to have many performance problems with the growth of the Internet. TCP for instance results in throughput degradation for high bandwidth delay product networks and is unfair for flows with high round trip delays. There have been many patches and modifications to TCP all of which inherit the problems of TCP in spite of some performance improve- ments. On the other hand there are clean-slate design approaches of the Internet. The eXplicit Congestion control Protocol (XCP) and the Rate Control Protocol (RCP) are the prominent clean slate congestion control protocols. Nonetheless, the XCP protocol is also proved to have its own performance problems some of which are its unfairness to long flows (flows with high round trip delay), and many per-packet computations at the router. As shown in this paper RCP also makes gross approximation to its important component that it may only give the performance reports shown in the literature for specific choices of its parameter values and traffic patterns. In this paper we present a new congestion control protocol called Network congestion Control Protocol (NCP). We show that NCP can outperform both TCP, XCP and RCP in terms of among other things fairness and file download times. Keywords: Congestion Control, clean-slate, fairness, download times. -

How to Properly Measure and Correct Packet Loss
White Paper How to Properly Measure and Correct Packet Loss Silver Peak avoids common packet delivery issues across the WAN White Paper How to Properly Measure and Correct Packet Loss Silver Peak avoids common packet delivery issues across the WAN Shared Wide Area Networks (WANs), like MPLS and Internet VPNs, are prone to network congestion during periods of heavy utilization. When different traffic is vying for limited shared resources, packets inevitably will be dropped or delivered out of order, a concept known as “packet loss”. As more enterprises deploy real-time traffic, like voice, video and other unified communications, packet loss is an increasingly significant problem. That is because dropped and out-of-order packets degrade the quality of latency sensitive applications – e.g. packet loss causes video pixilation, choppy phone calls, or terminated sessions. In addition, loss is increasingly problematic as more enterprises look to lower disaster recovery costs by performing data replication over shared WANs. As figure 1 shows, when a small amount of packet loss (0.1%) is combined with a marginal amount of latency (50 ms), data throughput will never exceed 10 Mbps per flow – regardless of how much bandwidth is available. This can severely hamper key enterprise initiatives that require high sustained data throughput, like replication. The problem is that most enterprises don’t know packet loss exists on their WANs as they don’t have the proper tools for measuring it. (Service Providers only exacerbate the problem by offering SLAs that are based on monthly averages, which can be quite misleading. An enterprise can experience several hours of loss during several work days and still statistically have around 0% loss over the course of a month). -

The Need for Realism When Simulating Network Congestion
The Need for Realism when Simulating Network Congestion Kevin Mills Chris Dabrowski NIST NIST Gaithersburg, MD 20899 Gaithersburg, MD 20899 [email protected] [email protected] throughout the network. The researchers identify various ABSTRACT Many researchers use abstract models to simulate network signals that arise around the critical point. Such signals congestion, finding patterns that might foreshadow onset of could foreshadow onset of widespread congestion. These congestion collapse. We investigate whether such abstract developments appear promising as a theoretical basis for monitoring methods that could be deployed to warn of models yield congestion behaviors sufficiently similar to impending congestion collapse. Despite showing promise, more realistic models. Beginning with an abstract model, we add elements of realism in various combinations, questions surround this research, as the models are quite culminating with a high-fidelity simulation. By comparing abstract, bearing little resemblance to communication congestion patterns among combinations, we illustrate networks deployed based on modern technology. We congestion spread in abstract models differs from that in explore these questions by examining the influence of realistic models. We identify critical elements of realism realism on congestion spread in network simulations. needed when simulating congestion. We demonstrate a We begin with an abstract network simulation from the means to compare congestion patterns among simulations literature. We add realism elements in combinations, covering diverse configurations. We hope our contributions culminating with a high-fidelity simulation, also from the lead to better understanding of the need for realism when literature. By comparing patterns of congestion among the simulating network congestion. combinations, we explore a number of questions. -

TCP Congestion Control Scheme for Wireless Networks Based on TCP Reserved Field and SNR Ratio
International Journal of Research and Reviews in Information Sciences (IJRRIS), ISSN: 2046-6439, Vol. 2, No. 2, June 2012 http://www.sciacademypublisher.com/journals/index.php/IJRRIS/article/download/817/728 TCP Congestion Control Scheme for Wireless Networks based on TCP Reserved Field and SNR Ratio Youssef Bassil LACSC – Lebanese Association for Computational Sciences, Registered under No. 957, 2011, Beirut, Lebanon Email: [email protected] Abstract – Currently, TCP is the most popular and widely used network transmission protocol. In actual fact, about 90% of connections on the internet use TCP to communicate. Through several upgrades and improvements, TCP became well optimized for the very reliable wired networks. As a result, TCP considers all packet timeouts in wired networks as due to network congestion and not to bit errors. However, with networking becoming more heterogeneous, providing wired as well as wireless topologies, TCP suffers from performance degradation over error-prone wireless links as it has no mechanism to differentiate error losses from congestion losses. It therefore considers all packet losses as due to congestion and consequently reduces the burst of packet, diminishing at the same time the network throughput. This paper proposes a new TCP congestion control scheme appropriate for wireless as well as wired networks and is capable of distinguishing congestion losses from error losses. The proposed scheme is based on using the reserved field of the TCP header to indicate whether the established connection is over a wired or a wireless link. Additionally, the proposed scheme leverages the SNR ratio to detect the reliability of the link and decide whether to reduce packet burst or retransmit a timed-out packet.