Cyclic Codes, BCH Codes, RS Codes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

10. on Extending Bch Codes
University of Plymouth PEARL https://pearl.plymouth.ac.uk 04 University of Plymouth Research Theses 01 Research Theses Main Collection 2011 Algebraic Codes For Error Correction In Digital Communication Systems Jibril, Mubarak http://hdl.handle.net/10026.1/1188 University of Plymouth All content in PEARL is protected by copyright law. Author manuscripts are made available in accordance with publisher policies. Please cite only the published version using the details provided on the item record or document. In the absence of an open licence (e.g. Creative Commons), permissions for further reuse of content should be sought from the publisher or author. Copyright Statement This copy of the thesis has been supplied on the condition that anyone who consults it is understood to recognise that its copyright rests with its author and that no quotation from the thesis and information derived from it may be published without the author’s prior consent. Copyright © Mubarak Jibril, December 2011 Algebraic Codes For Error Correction In Digital Communication Systems by Mubarak Jibril A thesis submitted to the University of Plymouth in partial fulfilment for the degree of Doctor of Philosophy School of Computing and Mathematics Faculty of Technology Under the supervision of Dr. M. Z. Ahmed, Prof. M. Tomlinson and Dr. C. Tjhai December 2011 ABSTRACT Algebraic Codes For Error Correction In Digital Communication Systems Mubarak Jibril C. Shannon presented theoretical conditions under which communication was pos- sible error-free in the presence of noise. Subsequently the notion of using error correcting codes to mitigate the effects of noise in digital transmission was intro- duced by R. -

Decoding Beyond the Designed Distance for Certain Algebraic Codes
INFORMATION AND CONTROL 35, 209--228 (1977) Decoding beyond the Designed Distance for Certain Algebraic Codes DAVID MANDELBAUM P.O. Box 645, Eatontown, New Jersey 07724 It is shown how decoding beyond the designed distance can be accomplished for a certain decoding algorithm. This method can be used for subcodes of generalized Goppa codes and generalized Reed-Solomon codes. 1. INTRODUCTION A decoding algorithm for generalized Goppa codes is presented here. This method directly uses the Euclidean algorithm, it is shown how subcodes of these generalized codes can be decoded for errors beyond the designed distance. It is proved that all coset leaders can be decoded by this method. Decoding of errors beyond the BCH bound may involve solution of nonlinear equations. The method used is similar to the use of continued fractions for decoding within the BCH bound (Mandelbaum, 1976). The Euclidean algorithm is also used by Sugiyama et aL (1975) in a different manner for decoding Goppa codes within the BCH bound. Section 2 defines the generalized codes and shows the relationship with the Mattson-Solomon polynomial. Section 3 defines the decoding algorithm and gives, as a detailed example, the decoding of the (15, 5) BCH code for a quadruple error. Application to the Golay code is pointed out. This method can also be used for decoding the Generalized Reed-Solomon codes constructed by Delsarte (1975). Section 4 presents a method of obtaining the original information and syndrome in an iterated manner, which results in reduced computation for codewords with no errors. Other methods for decoding beyond the BCH bound for BCH codes are given by Berlekamp (1968) and Harmann (1972). -

Chapter 6 Modeling and Simulations of Reed-Solomon Encoder and Decoder
CALIFORNIA STATE UNIVERSITY, NORTHRIDGE The Implementation of a Reed Solomon Code Encoder /Decoder A graduate project submitted in partial fulfillment of the requirements For the degree of Master of Science in Electrical Engineering By Qiang Zhang May 2014 Copyright by Qiang Zhang 2014 ii The graduate project of Qiang Zhang is approved: Dr. Ali Amini Date Dr. Sharlene Katz Date Dr. Nagi El Naga, Chair Date California State University, Northridge iii Acknowledgements I would like to thank my project professor and committee: Dr. Nagi El Naga, Dr. Ali Amini, and Dr. Sharlene Katz for their time and help. I would also like to thank my parents for their love and care. I could not have finished this project without them, because they give me the huge encouragement during last two years. iv Dedication To my parents v Table of Contents Copyright Page.................................................................................................................... ii Signature Page ................................................................................................................... iii Acknowledgement ............................................................................................................. iv Dedication ............................................................................................................................v List of Figures .................................................................................................................. viii Abstract ................................................................................................................................x -

Chapter 9: BCH, Reed-Solomon, and Related Codes
Draft of February 23, 2001 Chapter 9: BCH, Reed-Solomon, and Related Codes 9.1 Introduction. In Chapter 7 we gave one useful generalization of the (7, 4) Hamming code of the Introduction: the family of (2m − 1, 2m − m − 1) single error-correcting Hamming Codes. In Chapter 8 we gave a further generalization, to a class of codes capable of correcting a single burst of errors. In this Chapter, however, we will give a far more important and extensive generalization, the multiple-error correcting BCH and Reed-Solomon Codes. To motivate the general definition, recall that the parity-check matrix of a Hamming Code of length n =2m − 1 is given by (see Section 7.4) H =[v0 v1 ··· vn−1 ] , (9.1) m m where (v0, v1,...,vn−1) is some ordering of the 2 − 1 nonzero (column) vectors from Vm = GF (2) . The matrix H has dimensions m × n, which means that it takes m parity-check bits to correct one error. If we wish to correct two errors, it stands to reason that m more parity checks will be required. Thus we might guess that a matrix of the general form v0 v1 ··· vn−1 H2 = , w0 w1 ··· wn−1 where w0, w1,...,wn−1 ∈ Vm, will serve as the parity-check matrix for a two-error-correcting code of length n. Since however the vi’s are distinct, we may view the correspondence vi → wi as a function from Vm into itself, and write H2 as v0 v1 ··· vn−1 H2 = . (9.3) f(v0) f(v1) ··· f(vn−1) But how should the function f be chosen? According to the results of Section 7.3, H2 will define a n two-error-correcting code iff the syndromes of the 1 + n + 2 error pattern of weights 0, 1 and 2 are all distinct. -

Chapter 9: BCH, Reed-Solomon, and Related Codes
Draft of February 21, 1999 Chapter 9: BCH, Reed-Solomon, and Related Codes 9.1 Introduction. In Chapter 7 we gave one useful generalization of the (7, 4)Hamming code of the Introduction: the family of (2m − 1, 2m − m − 1)single error-correcting Hamming Codes. In Chapter 8 we gave a further generalization, to a class of codes capable of correcting a single burst of errors. In this Chapter, however, we will give a far more important and extensive generalization, the multiple-error correcting BCH and Reed-Solomon Codes. To motivate the general definition, recall that the parity-check matrix of a Hamming Code of length n =2m − 1 is given by (see Section 7.4) H =[v0 v1 ··· vn−1 ] , (9.1) m m where (v0, v1,...,vn−1)is some ordering of the 2 − 1 nonzero (column)vectors from Vm = GF (2) . The matrix H has dimensions m × n, which means that it takes m parity-check bits to correct one error. If we wish to correct two errors, it stands to reason that m more parity checks will be required. Thus we might guess that a matrix of the general form v0 v1 ··· vn−1 H2 = , w0 w1 ··· wn−1 where w0, w1,...,wn−1 ∈ Vm, will serve as the parity-check matrix for a two-error-correcting code of length n. Since however the vi’s are distinct, we may view the correspondence vi → wi as a function from Vm into itself, and write H2 as v0 v1 ··· vn−1 H2 = . (9.3) f(v0) f(v1) ··· f(vn−1) But how should the function f be chosen? According to the results of Section 7.3, H2 will define a n two-error-correcting code iff the syndromes of the 1 + n + 2 error pattern of weights 0, 1 and 2 are all distinct. -
Introduction to Coding Theory
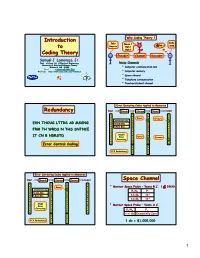
Introduction Why Coding Theory ? Introduction Info Info Noise ! Info »?# Sink to Source Heh ! Sink Heh ! Coding Theory Encoder Channel Decoder Samuel J. Lomonaco, Jr. Dept. of Comp. Sci. & Electrical Engineering Noisy Channels University of Maryland Baltimore County Baltimore, MD 21250 • Computer communication line Email: [email protected] WebPage: http://www.csee.umbc.edu/~lomonaco • Computer memory • Space channel • Telephone communication • Teacher/student channel Error Detecting Codes Applied to Memories Redundancy Input Encode Storage Detect Output 1 1 1 1 0 0 0 0 1 1 Error 1 Erasure 1 1 31=16+5 Code 1 0 ? 0 0 0 0 EVN THOUG LTTRS AR MSSNG 1 16 Info Bits 1 1 1 0 5 Red. Bits 0 0 0 0 0 0 0 FRM TH WRDS N THS SNTNCE 1 1 1 1 0 0 0 0 1 1 1 Double 1 IT CN B NDRSTD 0 0 0 0 1 Error 1 Error 1 Erasure 1 1 Detecting 1 0 ? 0 0 0 0 1 1 1 1 Error Control Coding 0 0 1 1 0 0 31% Redundancy 1 1 1 1 Error Correcting Codes Applied to Memories Input Encode Storage Correct Output Space Channel 1 1 1 1 0 0 0 0 Mariner Space Probe – Years B.C. ( ≤ 1964) 1 1 Error 1 1 • 1 31=16+5 Code 1 0 1 0 0 0 0 Eb/N0 Pe 16 Info Bits 1 1 1 1 -3 0 5 Red. Bits 0 0 0 6.8 db 10 0 0 0 0 -5 1 1 1 1 9.8 db 10 0 0 0 0 1 1 1 Single 1 0 0 0 0 Error 1 1 • Mariner Space Probe – Years A.C. -

Error Detection and Correction Using the BCH Code 1
Error Detection and Correction Using the BCH Code 1 Error Detection and Correction Using the BCH Code Hank Wallace Copyright (C) 2001 Hank Wallace The Information Environment The information revolution is in full swing, having matured over the last thirty or so years. It is estimated that there are hundreds of millions to several billion web pages on computers connected to the Internet, depending on whom you ask and the time of day. As of this writing, the google.com search engine listed 1,346,966,000 web pages in its database. Add to that email, FTP transactions, virtual private networks and other traffic, and the data volume swells to many terabits per day. We have all learned new standard multiplier prefixes as a result of this explosion. These days, the prefix “mega,” or million, when used in advertising (“Mega Cola”) actually makes the product seem trite. With all these terabits per second flying around the world on copper cable, optical fiber, and microwave links, the question arises: How reliable are these networks? If we lose only 0.001% of the data on a one gigabit per second network link, that amounts to ten thousand bits per second! A typical newspaper story contains 1,000 words, or about 42,000 bits of information. Imagine losing a newspaper story on the wires every four seconds, or 900 stories per hour. Even a small error rate becomes impractical as data rates increase to stratospheric levels as they have over the last decade. Given the fact that all networks corrupt the data sent through them to some extent, is there something that we can do to ensure good data gets through poor networks intact? Enter Claude Shannon In 1948, Dr. -

Reed-Solomon Encoding and Decoding
Bachelor's Thesis Degree Programme in Information Technology 2011 León van de Pavert REED-SOLOMON ENCODING AND DECODING A Visual Representation i Bachelor's Thesis | Abstract Turku University of Applied Sciences Degree Programme in Information Technology Spring 2011 | 37 pages Instructor: Hazem Al-Bermanei León van de Pavert REED-SOLOMON ENCODING AND DECODING The capacity of a binary channel is increased by adding extra bits to this data. This improves the quality of digital data. The process of adding redundant bits is known as channel encod- ing. In many situations, errors are not distributed at random but occur in bursts. For example, scratches, dust or fingerprints on a compact disc (CD) introduce errors on neighbouring data bits. Cross-interleaved Reed-Solomon codes (CIRC) are particularly well-suited for detection and correction of burst errors and erasures. Interleaving redistributes the data over many blocks of code. The double encoding has the first code declaring erasures. The second code corrects them. The purpose of this thesis is to present Reed-Solomon error correction codes in relation to burst errors. In particular, this thesis visualises the mechanism of cross-interleaving and its ability to allow for detection and correction of burst errors. KEYWORDS: Coding theory, Reed-Solomon code, burst errors, cross-interleaving, compact disc ii ACKNOWLEDGEMENTS It is a pleasure to thank those who supported me making this thesis possible. I am thankful to my supervisor, Hazem Al-Bermanei, whose intricate know- ledge of coding theory inspired me, and whose lectures, encouragement, and support enabled me to develop an understanding of this subject. -

Lecture 14: BCH Codes Overview 1 General Codes
CS681 Computational Number Theory Lecture 14: BCH Codes Instructor: Piyush P Kurur Scribe: Ramprasad Saptharishi Overview We shall look a a special form of linear codes called cyclic codes. These have very nice structures underlying them and we shall study BCH codes. 1 General Codes n Recall that a linear code C is just a subspace of Fq . We saw last time that by picking a basis of C we can construct what is known as a parity check matrix H that is zero precisely at C. Let us understand how the procedure works. Alice has a message, of length k and she wishes to transmit across the channel. The channel is unreliable and therefore both Alice and Bob first agree on some code C. Now how does Alice convert her message into a code word in C? If Alice’s message could be written as (x1, x2, ··· , xk) where each xi ∈ Fq, then Alice Pk simply sends i=1 xibi which is a codeword. Bob receives some y and he checks if Hy = 0. Assuming that they choose a good distance code (the channel cannot alter one code into an- other), if Bob finds that Hy = 0, then he knows that the message he received was untampered with. But what sort of errors can the channel give? Let us say that the channel can change atmost t positions of the codeword. If x was sent and x0 was received with atmost t changes between them, then the vector e = x0−x can be thought of as the error vector. -

The Binary Golay Code and the Leech Lattice
The binary Golay code and the Leech lattice Recall from previous talks: Def 1: (linear code) A code C over a field F is called linear if the code contains any linear combinations of its codewords A k-dimensional linear code of length n with minimal Hamming distance d is said to be an [n, k, d]-code. Why are linear codes interesting? ● Error-correcting codes have a wide range of applications in telecommunication. ● A field where transmissions are particularly important is space probes, due to a combination of a harsh environment and cost restrictions. ● Linear codes were used for space-probes because they allowed for just-in-time encoding, as memory was error-prone and heavy. Space-probe example The Hamming weight enumerator Def 2: (weight of a codeword) The weight w(u) of a codeword u is the number of its nonzero coordinates. Def 3: (Hamming weight enumerator) The Hamming weight enumerator of C is the polynomial: n n−i i W C (X ,Y )=∑ Ai X Y i=0 where Ai is the number of codeword of weight i. Example (Example 2.1, [8]) For the binary Hamming code of length 7 the weight enumerator is given by: 7 4 3 3 4 7 W H (X ,Y )= X +7 X Y +7 X Y +Y Dual and doubly even codes Def 4: (dual code) For a code C we define the dual code C˚ to be the linear code of codewords orthogonal to all of C. Def 5: (doubly even code) A binary code C is called doubly even if the weights of all its codewords are divisible by 4. -

Cyclic Codes
Cyclic Codes Saravanan Vijayakumaran [email protected] Department of Electrical Engineering Indian Institute of Technology Bombay August 26, 2014 1 / 25 Cyclic Codes Definition A cyclic shift of a vector v0 v1 ··· vn−2 vn−1 is the vector vn−1 v0 v1 ··· vn−3 vn−2 . Definition An (n; k) linear block code C is a cyclic code if every cyclic shift of a codeword in C is also a codeword. Example Consider the (7; 4) code C with generator matrix 21 0 0 0 1 1 03 60 1 0 0 0 1 17 G = 6 7 40 0 1 0 1 1 15 0 0 0 1 1 0 1 2 / 25 Polynomial Representation of Vectors For every vector v = v0 v1 ··· vn−2 vn−1 there is a polynomial 2 n−1 v(X) = v0 + v1X + v2X + ··· + vn−1X Let v(i) be the vector resulting from i cyclic shifts on v (i) i−1 i n−1 v (X) = vn−i +vn−i+1X +···+vn−1X +v0X +···+vn−i−1X Example v = 1 0 0 1 1 0 1, v(X) = 1 + X 3 + X 4 + X 6 v(1) = 1 1 0 0 1 1 0, v(1)(X) = 1 + X + X 4 + X 5 v(2) = 0 1 1 0 0 1 1, v(2)(X) = X + X 2 + X 5 + X 6 3 / 25 Polynomial Representation of Vectors • Consider v(X) and v(1)(X) 2 n−1 v(X) = v0 + v1X + v2X + ··· + vn−1X (1) 2 3 n−2 v (X) = vn−1 + v0X + v1X + v2X + ··· + vn−2X h 2 n−2i = vn−1 + X v0 + v1X + v2X + ··· + vn−2X n h n−2 n−1i = vn−1(1 + X ) + X v0 + ··· + vn−2X + vn−1X n = vn−1(1 + X ) + Xv(X) • In general, v(X) and v(i)(X) are related by X i v(X) = v(i)(X) + q(X)(X n + 1) i−1 where q(X) = vn−i + vn−i+1X + ··· + vn−1X • v(i)(X) is the remainder when X i v(X) is divided by X n + 1 4 / 25 Hamming Code of Length 7 Codeword Code Polynomial 0000000 0 1000110 1 + X 4 + X 5 0100011 X + X 5 + X 6 1100101 1 + X + X 4 + X 6 0010111 X 2 + X 4 + X 5 + X 6 1010001 1 + X 2 + X 6 0110100 X + X 2 + X 4 1110010 1 + X + X 2 + X 5 0001101 X 3 + X 4 + X 6 1001011 1 + X 3 + X 5 + X 6 0101110 X + X 3 + X 4 + X 5 1101000 1 + X + X 3 0011010 X 2 + X 3 + X 5 1011100 1 + X 2 + X 3 + X 4 0111001 X + X 2 + X 3 + X 6 1111111 1 + X + X 2 + X 3 + X 4 + X 5 + X 6 5 / 25 Properties of Cyclic Codes (1) Theorem The nonzero code polynomial of minimum degree in a linear block code is unique. -

ABSTRACT IDEMPOTENTS in CYCLIC CODES by Benjamin Brame April 9, 2012
ABSTRACT IDEMPOTENTS IN CYCLIC CODES by Benjamin Brame April 9, 2012 Chair: Dr. Zachary Robinson Major Department: Mathematics Cyclic codes give us the most probable method by which we may detect and correct data transmission errors. These codes depend on the development of advanced math- ematical concepts. It is shown that cyclic codes, when viewed as vector subspaces of a vector space of some dimension n over some finite field F, can be approached as polynomials in a ring. This approach is made possible by the assumption that the set of codewords is invariant under cyclic shifts, which are linear transformations. Developing these codes seems to be equivalent to factoring the polynomial xn −x over F. Each factor then gives us a cyclic code of some dimension k over F. Constructing factorizations of xn − 1 is accomplished by using cyclotomic polyno- mials and idempotents of the code algebra. The use of these two concepts together allows us to find cyclic codes in Fn. Hence, the development of cyclic codes is a journey from codewords and codes to fields and rings and back to codes and codewords. IDEMPOTENTS IN CYCLIC CODES A Thesis Presented to The Faculty of the Department of Mathematics East Carolina University In Partial Fulfillment of the Requirements for the Degree Master of Arts in Mathematics by Benjamin Brame April 9, 2012 Copyright 2012, Benjamin Brame IDEMPOTENTS IN CYCLIC CODES by Benjamin Brame APPROVED BY: DIRECTOR OF THESIS: Dr. Zachary Robinson COMMITTEE MEMBER: Dr. Chris Jantzen COMMITTEE MEMBER: Dr. Heather Ries COMMITTEE MEMBER: Dr. David Pravica CHAIR OF THE DEPARTMENT OF MATHEMATICS: Dr.