Asteca: Automated Stellar Cluster Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sunday October 19, 2014
Sunday October 19, 2014 Decided to use the Little Thompson Observatory’s telescopes tonight. I couldn’t connect to the 24”. Had connection failure issues. So I used the 18” f/14.2 and the 6” f/6 telescopes tonight. The 40mm eyepiece in 18” is 162x. The 22mm eyepiece in 6” is 41.5x. 7:00 PM. 68 degrees. Sky is clear. Wind is calm. Getting dark. Seeing and transparency Good. NGC 6929 7:27 PM 162x – Under a dim field star is this lopsided, faint, tiny oval glow. Glow goes to 2 o’clock from this star a tiny bit. Glow uniformly lit. NGC 6852 7:32 PM 162x – A brighter white star with very faint circular halo glow around it. With O3 see the halo a bit better and brighter. Star still prominent. NGC 6843 7:35 PM 162x – 7 very dim stars form this asterism in a small, rough circular pattern. NGC 6858 7:37 PM 162x – An asterism of 9 very dim stars in a diamond shape. NGC 6773 7:39 PM 162x – 5 stars form a box of 3 magnitudes with brightest still dim. PK 38-25.1 7:45 PM 162x – A stellar PN. A brighter white star. With O3, see a tiny bit of halo around it. It is small and hard to see. Looks like an out of focus star. Pal 11 7:49 PM 162x – With AV and waiting, see 3-4 very faint stars once in a while. In between a nice asterism pattern where picture shows it should be and where these 3-4 stars pop in. -

Astronomy Magazine Special Issue
γ ι ζ γ δ α κ β κ ε γ β ρ ε ζ υ α φ ψ ω χ α π χ φ γ ω ο ι δ κ α ξ υ λ τ μ β α σ θ ε β σ δ γ ψ λ ω σ η ν θ Aι must-have for all stargazers η δ μ NEW EDITION! ζ λ β ε η κ NGC 6664 NGC 6539 ε τ μ NGC 6712 α υ δ ζ M26 ν NGC 6649 ψ Struve 2325 ζ ξ ATLAS χ α NGC 6604 ξ ο ν ν SCUTUM M16 of the γ SERP β NGC 6605 γ V450 ξ η υ η NGC 6645 M17 φ θ M18 ζ ρ ρ1 π Barnard 92 ο χ σ M25 M24 STARS M23 ν β κ All-in-one introduction ALL NEW MAPS WITH: to the night sky 42,000 more stars (87,000 plotted down to magnitude 8.5) AND 150+ more deep-sky objects (more than 1,200 total) The Eagle Nebula (M16) combines a dark nebula and a star cluster. In 100+ this intense region of star formation, “pillars” form at the boundaries spectacular between hot and cold gas. You’ll find this object on Map 14, a celestial portion of which lies above. photos PLUS: How to observe star clusters, nebulae, and galaxies AS2-CV0610.indd 1 6/10/10 4:17 PM NEW EDITION! AtlAs Tour the night sky of the The staff of Astronomy magazine decided to This atlas presents produce its first star atlas in 2006. -

A Basic Requirement for Studying the Heavens Is Determining Where In
Abasic requirement for studying the heavens is determining where in the sky things are. To specify sky positions, astronomers have developed several coordinate systems. Each uses a coordinate grid projected on to the celestial sphere, in analogy to the geographic coordinate system used on the surface of the Earth. The coordinate systems differ only in their choice of the fundamental plane, which divides the sky into two equal hemispheres along a great circle (the fundamental plane of the geographic system is the Earth's equator) . Each coordinate system is named for its choice of fundamental plane. The equatorial coordinate system is probably the most widely used celestial coordinate system. It is also the one most closely related to the geographic coordinate system, because they use the same fun damental plane and the same poles. The projection of the Earth's equator onto the celestial sphere is called the celestial equator. Similarly, projecting the geographic poles on to the celest ial sphere defines the north and south celestial poles. However, there is an important difference between the equatorial and geographic coordinate systems: the geographic system is fixed to the Earth; it rotates as the Earth does . The equatorial system is fixed to the stars, so it appears to rotate across the sky with the stars, but of course it's really the Earth rotating under the fixed sky. The latitudinal (latitude-like) angle of the equatorial system is called declination (Dec for short) . It measures the angle of an object above or below the celestial equator. The longitud inal angle is called the right ascension (RA for short). -

Observing List Evening of 2011 Dec 25 at Boyden Observatory
Southern Skies Binocular list Observing List Evening of 2011 Dec 25 at Boyden Observatory Sunset 19:20, Twilight ends 20:49, Twilight begins 03:40, Sunrise 05:09, Moon rise 06:47, Moon set 20:00 Completely dark from 20:49 to 03:40. New Moon. All times local (GMT+2). Listing All Classes visible above 2 air mass and in complete darkness after 20:49 and before 03:40. Cls Primary ID Alternate ID Con Mag Size Distance RA 2000 Dec 2000 Begin Optimum End S.A. Ur. 2 PSA Difficulty Optimum EP Open Collinder 227 Melotte 101 Car 8.4 15.0' 6500 ly 10h42m12.0s -65°06'00" 01:32 03:31 03:54 25 210 40 challenging Glob NGC 2808 Car 6.2 14.0' 26000 ly 09h12m03.0s -64°51'48" 21:57 03:08 04:05 25 210 40 detectable Open IC 2602 Collinder 229 Car 1.6 100.0' 520 ly 10h42m58.0s -64°24'00" 23:20 03:31 04:07 25 210 40 obvious Open Collinder 246 Melotte 105 Car 9.4 5.0' 7200 ly 11h19m42.0s -63°29'00" 01:44 03:33 03:57 25 209 40 challenging Open IC 2714 Collinder 245 Car 8.2 14.0' 4000 ly 11h17m27.0s -62°44'00" 01:32 03:33 03:57 25 209 40 challenging Open NGC 2516 Collinder 172 Car 3.3 30.0' 1300 ly 07h58m04.0s -60°45'12" 20:38 01:56 04:10 24 200 30 obvious Open NGC 3114 Collinder 215 Car 4.5 35.0' 3000 ly 10h02m36.0s -60°07'12" 22:43 03:27 04:07 25 199 40 easy Neb NGC 3372 Eta Carinae Nebula Car 3.0 120.0' 10h45m06.0s -59°52'00" 23:26 03:32 04:07 25 199 38 easy Open NGC 3532 Collinder 238 Car 3.4 50.0' 1600 ly 11h05m39.0s -58°45'12" 23:47 03:33 04:08 25 198 38 easy Open NGC 3293 Collinder 224 Car 6.2 6.0' 7600 ly 10h35m51.0s -58°13'48" 23:18 03:32 04:08 25 199 -
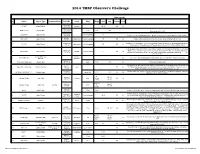
2014 Observers Challenge List
2014 TMSP Observer's Challenge Atlas page #s # Object Object Type Common Name RA, DEC Const Mag Mag.2 Size Sep. U2000 PSA 18h31m25s 1 IC 1287 Bright Nebula Scutum 20'.0 295 67 -10°47'45" 18h31m25s SAO 161569 Double Star 5.77 9.31 12.3” -10°47'45" Near center of IC 1287 18h33m28s NGC 6649 Open Cluster 8.9m Integrated 5' -10°24'10" Can be seen in 3/4d FOV with above. Brightest star is 13.2m. Approx 50 stars visible in Binos 18h28m 2 NGC 6633 Open Cluster Ophiuchus 4.6m integrated 27' 205 65 Visible in Binos and is about the size of a full Moon, brightest star is 7.6m +06°34' 17h46m18s 2x diameter of a full Moon. Try to view this cluster with your naked eye, binos, and a small scope. 3 IC 4665 Open Cluster Ophiuchus 4.2m Integrated 60' 203 65 +05º 43' Also check out “Tweedle-dee and Tweedle-dum to the east (IC 4756 and NGC 6633) A loose open cluster with a faint concentration of stars in a rich field, contains about 15-20 stars. 19h53m27s Brightest star is 9.8m, 5 stars 9-11m, remainder about 12-13m. This is a challenge obJect to 4 Harvard 20 Open Cluster Sagitta 7.7m integrated 6' 162 64 +18°19'12" improve your observation skills. Can you locate the miniature coathanger close by at 19h 37m 27s +19d? Constellation star Corona 5 Corona Borealis 55 Trace the 7 stars making up this constellation, observe and list the colors of each star asterism Borealis 15H 32' 55” Theta Corona Borealis Double Star 4.2m 6.6m .97” 55 Theta requires about 200x +31° 21' 32” The direction our Sun travels in our galaxy. -

Atlas Menor Was Objects to Slowly Change Over Time
C h a r t Atlas Charts s O b by j Objects e c t Constellation s Objects by Number 64 Objects by Type 71 Objects by Name 76 Messier Objects 78 Caldwell Objects 81 Orion & Stars by Name 84 Lepus, circa , Brightest Stars 86 1720 , Closest Stars 87 Mythology 88 Bimonthly Sky Charts 92 Meteor Showers 105 Sun, Moon and Planets 106 Observing Considerations 113 Expanded Glossary 115 Th e 88 Constellations, plus 126 Chart Reference BACK PAGE Introduction he night sky was charted by western civilization a few thou - N 1,370 deep sky objects and 360 double stars (two stars—one sands years ago to bring order to the random splatter of stars, often orbits the other) plotted with observing information for T and in the hopes, as a piece of the puzzle, to help “understand” every object. the forces of nature. The stars and their constellations were imbued with N Inclusion of many “famous” celestial objects, even though the beliefs of those times, which have become mythology. they are beyond the reach of a 6 to 8-inch diameter telescope. The oldest known celestial atlas is in the book, Almagest , by N Expanded glossary to define and/or explain terms and Claudius Ptolemy, a Greco-Egyptian with Roman citizenship who lived concepts. in Alexandria from 90 to 160 AD. The Almagest is the earliest surviving astronomical treatise—a 600-page tome. The star charts are in tabular N Black stars on a white background, a preferred format for star form, by constellation, and the locations of the stars are described by charts. -

7.5 X 11.5.Threelines.P65
Cambridge University Press 978-0-521-19267-5 - Observing and Cataloguing Nebulae and Star Clusters: From Herschel to Dreyer’s New General Catalogue Wolfgang Steinicke Index More information Name index The dates of birth and death, if available, for all 545 people (astronomers, telescope makers etc.) listed here are given. The data are mainly taken from the standard work Biographischer Index der Astronomie (Dick, Brüggenthies 2005). Some information has been added by the author (this especially concerns living twentieth-century astronomers). Members of the families of Dreyer, Lord Rosse and other astronomers (as mentioned in the text) are not listed. For obituaries see the references; compare also the compilations presented by Newcomb–Engelmann (Kempf 1911), Mädler (1873), Bode (1813) and Rudolf Wolf (1890). Markings: bold = portrait; underline = short biography. Abbe, Cleveland (1838–1916), 222–23, As-Sufi, Abd-al-Rahman (903–986), 164, 183, 229, 256, 271, 295, 338–42, 466 15–16, 167, 441–42, 446, 449–50, 455, 344, 346, 348, 360, 364, 367, 369, 393, Abell, George Ogden (1927–1983), 47, 475, 516 395, 395, 396–404, 406, 410, 415, 248 Austin, Edward P. (1843–1906), 6, 82, 423–24, 436, 441, 446, 448, 450, 455, Abbott, Francis Preserved (1799–1883), 335, 337, 446, 450 458–59, 461–63, 470, 477, 481, 483, 517–19 Auwers, Georg Friedrich Julius Arthur v. 505–11, 513–14, 517, 520, 526, 533, Abney, William (1843–1920), 360 (1838–1915), 7, 10, 12, 14–15, 26–27, 540–42, 548–61 Adams, John Couch (1819–1892), 122, 47, 50–51, 61, 65, 68–69, 88, 92–93, -

042021-Aktuelles Am Sternenhimmel
A N T A R E S NÖ AMATEURASTRONOMEN NOE VOLKSSTERNWARTE Michelbach Dorf 62 3074 MICHELBACH NOE VOLKSSTERNWARTE 3074 MICHELBACH Die VOLKSSTERNWARTE im Zentralraum Niederösterreich 02.04.1966 Luna 10 schwenkt als 1. Sonde in einen Mondorbit ein (UdSSR) 03.04.1959 Die ersten sieben Astronauten der USA werden bekanntgegeben 10.04.1970 Start Apollo 13; Nach einer Explosion kehren Jim Lovell, Jack Swigert und Fred Haise mit der Mondlandefähre als Rettungsboot zur Erde zurück 12.04.1960 Start von Transit 1B: Erster Navigationssatellit im All 12.04.1961 Vostok 1 (UdSSR) bringt den 1. Menschen ins All (Juri Gagarin!) 13.04.1862 Christian Huygens, Saturnforscher, wird geboren 18.04.1971 Start der 1. Weltraumstation Saljut 1 (UdSSR) 21.04.1971 Die erste Besatzung dockt an der ersten Raumstation Saljut 1 an (UdSSR) 22.04.1967 Wladimir Komarov stirbt als erster Kosmonaut im Weltraum (Sojus 1) 23.04.1990 Weltraumteleskop Hubble wird mit dem Shuttle Flug 31 gestartet 24.04.1962 Ariel 1, der erste internationale Satellit, wird gestartet (USA, England) AKTUELLES AM STERNENHIMMEL APRIL 2021 Die Wintersternbilder sind Objekte der westlichen Himmelshälfte; der Große Bär steht hoch im Zenit, die Frühlingssternbilder Löwe, Bärenhüter und Jungfrau mit den Galaxienhaufen können in der östlichen Himmelshälfte beobachtet werden; südlich der Jungfrau stehen Becher und Rabe, über dem Südhorizont schlänget sich die unscheinbare Wasserschlange. Mars ist am Abendhimmel in den Zwillingen auffindbar, Jupiter und Saturn werden die Planeten der zweiten Nachthälfte. INHALT Auf- und Untergangszeiten Sonne und Mond Fixsternhimmel Monatsthema – Juri Gagarin, 1. Mensch im Weltraum – 12.04.1961 Planetenlauf Sternschnuppenschwärme Vereinsabend – 09.04.2021 – ONLINE-Veranstaltung Führungstermin 16.04.2021 - ABSAGE VEREINSABEND 09.04.2021 REFERENT Doz. -

Aktuelles Am Sternenhimmel April 2020 Antares
A N T A R E S NÖ AMATEURASTRONOMEN NOE VOLKSSTERNWARTE Michelbach Dorf 62 3074 MICHELBACH NOE VOLKSSTERNWARTE 3074 MICHELBACH Die VOLKSSTERNWARTE im Zentralraum Niederösterreich 02.04.1966 Luna 10 schwenkt als 1. Sonde in einen Mondorbit ein (UdSSR) 03.04.1959 Die ersten sieben Astronauten der USA werden bekanntgegeben 10.04.1970 Start Apollo 13. Nach einer Explosion an Bord können alle 3 Astronauten mit der Mondlandefähre als Rettungsboot zur Erde zurückkehren. 12.04.1960 Start von Transit 1B: Erster Navigationssatellit im All 12.04.1961 Juri Gagarin startet als 1. Mensch mit Vostok 1 (UdSSR) ins All 15.04.1901 Wilbur Wright macht den erste Motorflug (1867 geboren) 18.04.1971 Start der 1. Weltraumstation Saljut 1 (UdSSR) 21.04.1971 Die erste Besatzung dockt an der ersten Raumstation Saljut 1 an (UdSSR) 22.04.1967 Wladimir Komarov stirbt als erster Kosmonaut im Weltraum (Sojus 1) 23.04.1990 Weltraumteleskop Hubble wird mit dem Shuttle Flug 31 gestartet 24.04.1962 Ariel 1, der erste internationale Satellit, wird gestartet (USA, England) AKTUELLES AM STERNENHIMMEL APRIL 2020 Die Wintersternbilder gehen im Westen unter; der Große Bär steht hoch im Zenit, der Löwe im Süden, Bärenhüter und Jungfrau halten sich wie die Galaxienhaufen noch in der östlichen Himmelshälfte auf; südlich der Jungfrau stehen Becher und Rabe, über dem Südhorizont schlänget sich die unscheinbare Wasserschlange. Venus ist strahlender „Abendstern“, Mars, Jupiter und Saturn werden die Planeten der zweiten Nachthälfte. INHALT Auf- und Untergangszeiten Sonne und Mond Fixsternhimmel -

Making a Sky Atlas
Appendix A Making a Sky Atlas Although a number of very advanced sky atlases are now available in print, none is likely to be ideal for any given task. Published atlases will probably have too few or too many guide stars, too few or too many deep-sky objects plotted in them, wrong- size charts, etc. I found that with MegaStar I could design and make, specifically for my survey, a “just right” personalized atlas. My atlas consists of 108 charts, each about twenty square degrees in size, with guide stars down to magnitude 8.9. I used only the northernmost 78 charts, since I observed the sky only down to –35°. On the charts I plotted only the objects I wanted to observe. In addition I made enlargements of small, overcrowded areas (“quad charts”) as well as separate large-scale charts for the Virgo Galaxy Cluster, the latter with guide stars down to magnitude 11.4. I put the charts in plastic sheet protectors in a three-ring binder, taking them out and plac- ing them on my telescope mount’s clipboard as needed. To find an object I would use the 35 mm finder (except in the Virgo Cluster, where I used the 60 mm as the finder) to point the ensemble of telescopes at the indicated spot among the guide stars. If the object was not seen in the 35 mm, as it usually was not, I would then look in the larger telescopes. If the object was not immediately visible even in the primary telescope – a not uncommon occur- rence due to inexact initial pointing – I would then scan around for it. -

Southern Sky Binocular Observing List
Southern Sky Binocular Observing List Object R.A. DEC Mag PA* Type Size Const Urn SA [ ] NGC 104 00 24.1 -72 05 4.5 ----- GbCl 25.0' Tuc 440 24 [ ] SMC 00 52.8 -72 50 2.7 10 Glxy 316'X186' Tuc 441 24 [ ] NGC 362 01 03.2 -70 51 6.6 ----- GbCl 12.9' Tuc 441 24 [ ] NGC 1261 03 12.3 -55 13 8.4 ----- GbCl 6.9' Hor 419 24 [ ] NGC 1851 05 14.1 -40 03 7.2 ----- GbCl 11.0' Col 393 19 [ ] LMC 05 23.6 -69 45 0.9 170 Glxy 646'X550' Dor 444 24 [ ] NGC 2070 05 38.6 -69 05 8.2 ----- BNeb 40'X25' Dor 445 24 [ ] NGC 2451 07 45.4 -37 58 2.8 ----- OpCl 45.0' Pup 362 19 [ ] NGC 2477 07 52.3 -38 33 5.8 ----- OpCl 27.0' Pup 362 19 [ ] NGC 2516 07 58.3 -60 52 3.8 ----- OpCl 29.0' Car 424 24 [ ] NGC 2547 08 10.7 -49 16 4.7 ----- OpCl 20.0' Vel 396 20 [ ] NGC 2546 08 12.4 -37 38 6.3 ----- OpCl 40.0' Pup 362 20 [ ] NGC 2627 08 37.3 -29 57 8.4 ----- OpCl 11.0' Pyx 363 20 [ ] IC 2391 08 40.2 -53 04 2.5 ----- OpCl 50.0' Vel 425 25 [ ] IC 2395 08 41.1 -48 12 4.6 ----- OpCl 7.0' Vel 397 20 [ ] NGC 2659 08 42.6 -44 57 8.6 ----- OpCl 2.7' Vel 397 20 [ ] NGC 2670 08 45.5 -48 47 7.8 ----- OpCl 9.0' Vel 397 20 [ ] NGC 2808 09 12.0 -64 52 6.3 ----- GbCl 13.8' Car 448 25 [ ] IC 2488 09 27.6 -56 59 7.4 ----- OpCl 14.0' Vel 425 25 [ ] NGC 2910 09 30.4 -52 54 7.2 ----- OpCl 5.0' Vel 426 25 [ ] NGC 2925 09 33.7 -53 26 8.3 ----- OpCl 12.0' Vel 426 25 [ ] NGC 3114 10 02.7 -60 07 4.2 ----- OpCl 35.0' Car 426 25 [ ] NGC 3201 10 17.6 -46 25 6.7 ----- GbCl 18.0' Vel 399 20 [ ] NGC 3228 10 21.8 -51 43 6.0 ----- OpCl 18.0' Vel 426 25 [ ] NGC 3293 10 35.8 -58 14 4.7 ----- OpCl 5.0' Car -

Charles Messier (1730-1817) Was an Observational Astronomer Working
Charles Messier (1730-1817) was an observational Catalogue (NGC) which was being compiled at the same astronomer working from Paris in the eighteenth century. time as Messier's observations but using much larger tele He discovered between 15 and 21 comets and observed scopes, probably explains its modern popularity. It is a many more. During his observations he encountered neb challenging but achievable task for most amateur astron ulous objects that were not comets. Some of these objects omers to observe all the Messier objects. At «star parties" were his own discoveries, while others had been known and within astronomy clubs, going for the maximum before. In 1774 he published a list of 45 of these nebulous number of Messier objects observed is a popular competi objects. His purpose in publishing the list was so that tion. Indeed at some times of the year it is just about poss other comet-hunters should not confuse the nebulae with ible to observe most of them in a single night. comets. Over the following decades he published supple Messier observed from Paris and therefore the most ments which increased the number of objects in his cata southerly object in his list is M7 in Scorpius with a decli logue to 103 though objects M101 and M102 were in fact nation of -35°. He also missed several objects from his list the same. Later other astronomers added a replacement such as h and X Per and the Hyades which most observers for M102 and objects 104 to 110. It is now thought proba would feel should have been included.