Design of a Power-Scalable Digital Least-Means-Square Adaptive
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Season Paul Rudd Talks Ant-Man and the Wasp
JULY 2018 | VOLUME 19 | NUMBER 6 Inside HENRY CAVILL NEVE CAMPBELL ANTOINE FUQUA BUG SEASON PAUL RUDD TALKS ANT-MAN AND THE WASP PUBLICATIONS MAIL AGREEMENT NO. 41619533 10 FUN FACTS ABOUT MAMMA MIA! HERE WE GO AGAIN, PAGE 24 CONTENTS JULY 2018 | VOL 19 | Nº6 COVER STORY 36 SUPERBUGS Feeling down after the events of Avengers: Infinity War? Paul Rudd, a.k.a. Ant-Man, LILLY. RUDD AND ’S EVANGELINE PAUL is here to lighten the load as he talks about his sequel, Ant-Man and the Wasp, which takes place before Infinity War. The affable actor keeps quiet PHOTO BY MICHAEL MULLER/MARCO GROB/©MARVEL STUDIOS PHOTO on the movie’s plot but opens AND THE ANT-MAN WASP up about working with co-star Evangeline Lilly and what makes Ant-Man so darn likable BY INGRID RANDOJA ON THE COVER: REGULARS 4 EDITOR’S NOTE 6 SNAPS 8 IN BRIEF 12 SPOTLIGHT CANADA 14 ALL DRESSED UP 16 IN THEATRES 40 CASTING CALL 44 RETURN ENGAGEMENT 46 CINEPLEX STORE 50 FINALLY… FEATURES 24 MORE 26 ON A MISSION 28 GOING UP 32 JUSTICE SERVED MAMMA MIA! Henry Cavill tells us about Skyscraper star Neve Campbell The Equalizer 2 director We count down 10 fascinating Mission: Impossible - Fallout says being a former dancer Antoine Fuqua talks about facts that set the stage for this and explains why doing stunts helped when it came to dealing with violence both month’s ABBA-riffic sequel on a Tom Cruise pic is such performing stunts in the on screen and in the real Mamma Mia! Here We Go Again good, scary fun Dwayne Johnson action pic communities where he films BY MARNI WEISZ BY MELISSA SHEASGREEN BY INGRID RANDOJA BY MARNI WEISZ JULY 2018 | CINEPLEX MAGAZINE | 3 EDITOR’S NOTE PUBLISHER SALAH BACHIR EDITOR MARNI WEISZ DEPUTY EDITOR INGRID RANDOJA CREATIVE DIRECTOR LUCINDA WALLACE GRAPHIC DESIGNER DARRYL MABEY VICE PRESIDENT, PRODUCTION SHEILA GREGORY CONTRIBUTORS MELISSA SHEASGREEN ADVERTISING SALES FOR CINEPLEX MAGAZINE IS HANDLED BY CINEPLEX MEDIA. -

Movie Inventory - Dvd 4/2/2019 Movie Title Rating
MOVIE INVENTORY - DVD 4/2/2019 MOVIE TITLE RATING 10 CLOVERFIELD LANE PG-13 12 STRONG 12 YEARS A SLAVE R 13 HOURS R THE 15:17 PARIS PG-13 211 R 20TH CENTURY WOMEN R 47 METERS DOWN PG-13 5 FLIGHTS UP PG-13 50-1 PG-13 THE 5TH WAVE PG-13 6 DAYS R 7 DAYS IN ENTEBBE PG-13 THE ACCOUNTANT R ACTS OF VIOLENCE R ADRIFT PG-13 AFTERMATH R AIR STRIKE R ALEX & ME G ALICE THROUGH THE LOOKING GLASS PG ALL THE MONEY IN THE WORLD R ALMOST CHRISTMAS PG13 ALPHA PG-13 ALVIN AND THE CHIPMUNKS G THE AMAZING SPIDER-MAN 2 PG-13 AMERICAN ANIMALS R AMERICAN ASSASSIN R AMERICAN MADE R AMERICAN SNIPER R AMITYVILLE: THE AWAKENING PG-13 THE ANGRY BIRDS MOVIE PG-13 ANNABELLE: CREATION R ANNIHILATION R ANT-MAN PG-13 ANT-MAN: THE WASP PG-13 AQUAMAN PG-13 ARRIVAL PG-13 PAGE 1 of 18 MOVIE INVENTORY - DVD 4/2/2019 MOVIE TITLE RATING ARSENAL R ASSASIN'S CREED PG-13 ASSASSINATION NATION R ATOMIC BLONDE R AVENGERS: AGE OF ULTRON PG-13 AVENGERS: INFINITY WAR PG-13 BAD MOMS R A BAD MOMS CHRISTMAS R BAD SANTA 2 R BAD TIMES AT THE EL ROYALE R BAMBIE G BARBIE & MARIPOSA THE FAIRY PRINCESS UNRATED BARBIE & THE DIAMOND CASTLE UNRATED BARBIE & THE 3 MUSKETEERS UNRATED BARBIE IN A MERMAID TALE 2 UNRATED BARBIE IN PRINCESS POWER UNRATED BATMAN V SUPERMAN DAWN OF JUSTICE PG-13 BEATRIZ AT DINNER R BEAUTY & THE BEAST PG BEFORE I FALL PG-13 THE BEGUILED R BEIRUT DVD BLU RAY R THE BELKO EXPERIMENT R BEN-HUR PG-13 BEN IS BACK R THE BFG PG THE BIRTH OF A NATION R BLACKHAT R BLACK MASS R BLACK PANTHER PG-13 BLACKkKLANSON R BLADE RUNNER 2049 R BLAIR WITCH R BLIND R THE BLIND SIDE PG-13 BLINDSPOTTING -

Blu-Ray Players May Play Either Dvrs Or Dvds. DVD Players Can Only Play Dvds
___ DVD 0101 - 2 Guns Rated R ___ DVD 0644 - 12 Strong Rated R ___ DVD 0100 - 12 Years A Slave Rated R ___ DVD 0645 - The 15:17 to Paris Rated PG-13 ___ DVD 0102 - 21 Jump Street Rated R ___ DVD 0314 - 22 Jump Street Rated R ___ DVR 0315 - 22 Jump Street Rated R ___ DVD 0316 - 23 Blast Rated PG-13 ___ DVD 0577 - The 33 Rated PG-13 ___ DVD 0103 - 42: The Jackie Robinson Story PG-13 ___ DVD 0964 - 101 Dalmations Rated G ___ DVR 0965 - 101 Dalmations Rated G ___ DVR 0966 - 2001: A Space Odyssey (Blu-Ray) Rated G ___ DVD 0108 - About Time Rated R ___ DVD 0107 - Abraham Lincoln: Vampire Hunter R ___ DVD 0242 - The Adjustment Bureau Rated PG-13 ___ DVD 0646 - Adrift (Based on the a True Story) PG-13 ___ DVD 0243 - The Adventures Of Tintin Rated PG ___ DVD 0706 - The Aftermath Rated R ___ DVD 0319 - Age Of Adaline Rated PG-13 Blu-Ray players may play either DVRs or DVDs. DVD players can only play DVDs. 1 | SD BTBL Descriptive Video Order Form: 2020 Catalog ___ DVR 0320 - Age Of Adaline Rated PG-13 ___ DVD 0995 - Aladdin (Animated) Rated G ___ DVR 0996 - Aladdin (Animated) Rated G ___ DVD 0997 - Aladdin (live action) Rated PG ___ DVR 0998 - Aladdin (live action) Rated PG ___ DVD 0321 - Alexander And The Terrible, Horrible, No Good, Very Bad Day Rated PG ___ DVD 0109 - Alice In Wonderland Rated PG ___ DVD 0723 - Alita: Battle Angel Rated PG-13 ___ DVR 0724 - Alita: Battle Angel Rated PG-13 ___ DVD 0725 - All Is True Rated PG-13 ___ DVD 0473 - Almost Christmas Rated PG-13 ___ DVR 0322 - Aloha (Blu-Ray) Rated PG-13 ___ DVD 0726 - Alpha Rated PG-13 ___ DVD 0111 - Alvin And The Chipmunks: The Squeakquel Rated PG ___ DVD 0110 - Alvin And The Chipmunks: Chipwrecked Rated G ___ DVD 0474 - Alvin And The Chipmunks: The Road Chip Rated PG ___ DVD 0244 - The Amazing Spider-Man Rated PG-13 Blu-Ray players may play either DVRs or DVDs. -

Multi-Platinum Artist Brainpower Brings International Flavor to the Equalizer 2 with New Single
MULTI-PLATINUM ARTIST BRAINPOWER BRINGS INTERNATIONAL FLAVOR TO THE EQUALIZER 2 WITH NEW SINGLE MC Brainpower Continues to Claim His Spot in the Hip Hop World with Release of "Animal Sauvage" Los Angeles, California - The Equalizer 2, starring actor Denzel Washington, is expected to be the hottest movie of the summer. The new music from the thriller is starting to make its own noise, as well. The World Song Network is releasing a new, hot single "Animal Sauvage" from international powerhouse, Brainpower. With "Animal Sauvage", Brainpower, based in Amsterdam, takes the listeners on a hip hop journey through a high- impact, techno world. "Animal Sauvage", which is featured in the film, is now available on all digital platforms. Brainpower's "Animal Sauvage" features Stix, Pitcho and Pharoahe Monch. The song is a bilingual, international hip-hop/rock mashup representing Amsterdam, Holland, Brussels, Los Angeles, and New York. Jabari Ali, music supervisor for The Equalizer 2, saw Brainpower as a natural fit to the storyline of the film. "I respect the talent of Brainpower as an artist, songwriter and producer. This song tremendously enhances the story telling for the film," says Ali. Brainpower is a pioneering bilingual triple threat from Amsterdam, who has sold well over a million records as an artist/songwriter. He was the first hip hop artist to win the MTV Europe Music Awards for Best Dutch Act; and his Youtube channel has recently crossed the 10 million views mark. "I am humbled to be a part of a major blockbuster like The Equalizer 2. I have been a Denzel Washington fan all of my life, so this is just crazy! And I love Antoine Fuqua's body of work," says Brainpower. -
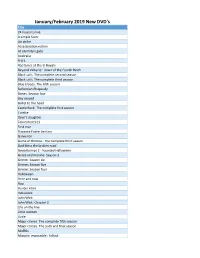
Listofitems (36).Csv
January/February 2019 New DVD's Title 24 hours to live A simple favor Air strike Assassination nation At eternity's gate Australia A-X-L Bad times at the El Royale Beyond Valkyrie : dawn of the Fourth Reich Black sails. The complete second season Black sails. The complete third season Blue bloods. The fifth season Bohemian Rhapsody Bones. Season four Boy erased Bullet to the head Castle Rock. The complete first season Colette Devil's daughter Fahrenheit 911 First man Florence Foster Jenkins Galveston Game of thrones : the complete third season God bless the broken road Goosebumps 2 : haunted Halloween Grace and Frankie: Season 3 Grimm. Season six Grimm: Season five Grimm: Season four Halloween Here and now Hop Hunter killer Indivisible John Wick John Wick: Chapter 2 Life on the line Little women Lizzie Major crimes. The complete fifth season Major crimes. The sixth and final season Mid90s Mission: impossible : fallout Night school Nobody's fool North and South: complete collection Nothing left to fear Operation Finale Peppermint Poldark. The complete third season River runs red September dawn Sgt. Stubby : an American hero Six feet under. The complete first season Smallfoot Solomon Kane Super troopers The bookshop The Cloverfield paradox The crown. Season two The equalizer 2 The girl in the spider's web The Grinch The handmaid's tale. Season two The happytime murders The hate u give The house with a clock in its walls The Houses October Built The little drummer boy The little witch The miseducation of Cameron Post The nun The Nutcracker and the four realms The oath The Orville. -

Moneydown No
Wednesday, Sept. 23, 2020 POSTAL PATRON B Dustin White B surcharge & fuel delivery Plus tax, 20 Yards 20 Yards 15 Yards 7 Yards BLACK TOPSOIL BLACK NORTH WOODS We canbeavailablewithin24hours! We Jordan StumpGrinding Jordan WHITE &CUSTOMBUILDERS, TO BE A PART OF THIS DIRECTORY, CALL(715)479-4421TODAY! OFTHISDIRECTORY, BEAPART TO jordanstumpgrinding.com FAST SERVICE • LOW RATES • FULLY INSURED •FULLY SERVICE •LOWRATES FAST PRSRT STD ECRWSS – INSURED– FULLY New Construction Northwoods GeneralContractor $ Timber &LogFramePorches Timber 168 $ $ U.S. Postage SERVING NORTHERN WISCONSIN 360 307 715-892-3954 P.O. Box 662, Eagle River, WI54521 Box662,EagleRiver, P.O. USINESS USINESS 00 PAID FREE ESTIMATES 00 50 Permit No. 13 Eagle River AWARD-WINNING NEWS COVERAGE NOW AVAILABLE ONTHE AVAILABLE NEWSCOVERAGENOW AWARD-WINNING Perfect forlawns&gardens — Screened &Pulverized T vcnewsreview.com vcnewsreview.com Decks Dave’s Topsoil Dave’s T Tom Goehe Tom Wis. Conover, Dock DoctorsInc. 715-479-6546 Doctors ofAllHome Services Remodeling T IF YOU NEED WE IT, CANIF YOU DO IT! From your roof to the water, we cover itall. cover we thewater, to your roof From Roofing • Permanent Piers •Boat• Permanent Shelters © Eagle River D A SPECIAL SECTION OF THE VILAS COUNTY NEWS-REVIEW 715-889-9557 Publications, Inc. 1972 OING ~ FromYourRooftotheWater ~ OR SMALL! OR NO STUMP NO TOO BIG AND THE THREE LAKES NEWS (715) 479-4421 Fully Insured – Free Estimates –Free Fully Insured • Stairs •DockRepair B LLC USINESS FOR THE PAUL BUNYAN OF NORTH WOODS ADVERTISING MasterCard, Visa &Discoveraccepted. MasterCard, Visa O BASEMAN BROS.INC. INSTALLATION •SANDINGFINISHING INSTALLATION JEFF BASEMAN for Wednesday’s News-Review. for Wednesday’s 1982 Croker Rd., Eagle River, WI54521 EagleRiver, Rd., 1982 Croker VER THANK-YOU &MEMORIALADS THANK-YOU & S 2 col.x1 & S Due payableinadvance. -

Developments in Revenge, Justice and Rape in the Cinema
Int J Semiot Law https://doi.org/10.1007/s11196-019-09614-7 Developments in Revenge, Justice and Rape in the Cinema Peter W. G. Robson1 © The Author(s) 2019 Abstract The index to the 2018 VideoHound Guide to Films suggests that under the broad heading of “revenge” there have been something in excess of 1000 flms. This appears to be the largest category in this comprehensive guide and suggests that this is, indeed, a theme which permeates the most infuential sector of popular cul- ture. These flms range from infuential and lauded flms with major directors and stars like John Ford (The Searchers (1956) and Alejandro González Iñárritu (The Revenant (2015)) to “straight to video” gorefests with little artistic merit and a spe- cifc target audience (The Hills Have Eyes (1977)). There is, as the Film Guide numbers suggest much in between like Straw Dogs (1972) and Outrage (1993). The making and re-making of “revenge” flms continues with contributions in 2018 from such major stars as Denzel Washington in The Equalizer 2 and Brue Willis in Death Wish. Within this body of flm is a roster of flms which allow us to speculate on the nature of the legal system and what individual and to a lesser extent commu- nity responses are likely where there appears to be a defcit of justice. One of the sub-groups within the revenge roster is a set of flms which focus on revenge by the victim for rape which are discussed for their rather diferent approach to the issue of justice. -

1 Academy Award ® Nominee Bryan Cranston, Acclaimed Actor And
Academy Award ® nominee Bryan Cranston, acclaimed actor and comedian Kevin Hart, and Academy Award ® Winner Nicole Kidman come together in STXfilms and Lantern Entertainment’s THE UPSIDE, an inspirational comedy based on the true-life friendship and lifelong bond forged between a wealthy man with quadriplegia and the ex-con he hires as his live- in care giver. Directed by Neil Burger (The Illusionist, Limitless), with a screenplay by Jon Hartmere, THE UPSIDE chronicles the unexpected friendship between Phillip Lacasse (Cranston), a Park Avenue billionaire left paralyzed after a paragliding accident, and ex-con Dell Scott (Kevin Hart), in need of a fresh start. Newly paroled and in desperate need of a job, Dell is frustrated by the menial opportunities available to an ex-con. After finding himself at the wrong job interview Dell uses his irreverent charisma to charm Phillip, who, despite protests from his chief-of-staff Yvonne (Nicole Kidman), offers him the home aid position. Despite a rocky start, the two quickly realize how much they can learn from each other’s experiences. From worlds apart, Phillip and Dell form an unlikely bond, bridging their differences and gaining invaluable wisdom in the process, giving each man a renewed sense of passion for all of life’s possibilities. 1 FILMMAKER’S VISION THE UPSIDE is inspired by the 2011 box office hit French film Les Intouchables. Producers Jason Blumenthal, Todd Black and Steve Tisch from Escape Artists were thrilled at the prospect of recreating the French classic, having seen it a few years back and absolutely loving the story. -
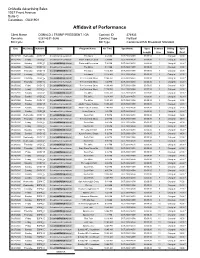
Affidavit of Performance
OnMedia Advertising Sales 1037 Front Avenue Suite C Columbus , GA31901 Affidavit of Performance Client Name DONALD J TRUMP PRESIDENT / GA Contract ID 274935 Remarks 62814631-3646 Contract Type Political Bill Cycle 9/20 Bill Type Condensed EAI Broadcast Standard Date Weekday Network Zone Program Name Air Time Spot Name Spot Contract Billing Spot Length Line Status Cost 09/23/2020 Wednesday CMDY_E Columbus-Valley-Auburn Futurama 8:43 AM DJT 20091405H 00:00:30 1 Charged 13.00 * 09/25/2020 Friday CMDY_E Columbus-Valley-AuburnWOW GA Parks and Recreation 7:39 AM DJT 20091405H 00:00:30 1 Charged 13.00 * 09/26/2020 Saturday CMDY_E Columbus-Valley-AuburnWOW GA Parks and Recreation 7:39 AM DJT 20091405H 00:00:30 1 Charged 13.00 * 09/26/2020 Saturday CMDY_E Columbus-Valley-AuburnWOW GA The Office 8:44 AM DJT 20091405H 00:00:30 1 Charged 13.00 * 09/24/2020 Thursday CMDY_E Columbus-Valley-AuburnWOW GA Futurama 11:12 AM DJT 20091405H 00:00:30 3 Charged 13.00 * 09/24/2020 Thursday CMDY_E Columbus-Valley-AuburnWOW GA Futurama 11:25 AM DJT 20091405H 00:00:30 3 Charged 13.00 * 09/24/2020 Thursday CMDY_E Columbus-Valley-AuburnWOW GA The Cleveland Show 11:46 AM DJT 20091405H 00:00:30 3 Charged 13.00 * 09/24/2020 Thursday CMDY_E Columbus-Valley-AuburnWOW GA The Cleveland Show 1:40 PM DJT 20091405H 00:00:30 3 Charged 13.00 * 09/25/2020 Friday CMDY_E Columbus-Valley-AuburnWOW GA The Cleveland Show 11:39 AM DJT 20091405H 00:00:30 3 Charged 13.00 * 09/25/2020 Friday CMDY_E Columbus-Valley-AuburnWOW GA The Cleveland Show 12:39 PM DJT 20091405H 00:00:30 3 Charged -

Ripped from the Headlines
Choose Your Next Adventure Get where you want to go with an SEPTEMBER 25 - OCTOBER 1, 2020 outstanding deal on a quality vehicle! SCENIC CHEVROLET BUICK GMC CADILLAC SUBARU WWW.SCENICGMAUTOS.COM 2300 ROCKFORD ST. MOUNT AIRY, N.C. 336-789-9011 70040249 Jeff Daniels stars in “The Comey Rule” Frank Fleming BODY SHOP WE WORK WITH ALL INSURANCE COMPANIES! 2162 SPRINGS RD. MOUNT AIRY, NC 336-786-9244 WWW.FRANKFLEMINGBODYSHOP.ORG 70039951 YOUR SOURCE FOR LOCAL NEWS Ripped from 319 N. Renfro Street Mount Airy NC, 27030 the headlines 336.786.4141 | mtairynews.com Keep In Touch Your local newspaper keeps you connected to the faces, places, information and events that matter most to you. The Mount Airy News In Print, Online & Mobile Now with print, online and mobile access, we’ve made it easier than ever to keep your finger on 336.786.4141 the pulse of what’s happening in our community and around the world. mtairynews.com V2 Page 2 — Friday, September 25, 2020 — The Mount Airy News SPORTS THIS WEEK ON THE COVER Political power play: ‘The Comey Rule’ The Mount Airy News premieres on Showtime (336) 786-4141 By Kyla Brewer from the Harry Potter film franchise. TV Media His other film credits include “Brave- heart” (1995), “Cold Mountain” s Nov. 3 looms on the horizon, (2003) and “Paddington 2” (2018), Athe U.S. presidential election while his television work includes campaign is in full swing. No matter “Mr. Mercedes” and the 2009 TV which way you intend to vote, film “Into the Storm,” for which he chances are that you have been in- won an Emmy. -

Box Office: 'Equalizer 2' Narrowly Edges Past 'Mamma Mia! Here We
7/23/2018 Box Office: ‘Equalizer 2’ Beats ‘Mamma Mia!’ Sequel in Surprise Twist – Variety JULY 22, 2018 7:46AM PT HOME > FILM > BOX OFFICE Box Office: ‘Equalizer 2’ Narrowly Edges Past ‘Mamma Mia! Here We Go Again’ to Land at No. 1 By REBECCA RUBIN CREDIT: GLEN WILSON COLUMBIA/SONY/KOBAL/SHUTTERSTOCK In a twist straight out of a movie, “The Equalizer 2” shot past “Mamma Mia! Here We Go Again” to steal the box oice crown. Going into the weekend, it looked like “Mamma Mia! 2” would easily debut at No. 1. Final numbers won’t come in until Monday, but weekend estimates show Sony’s “The Equalizer” sequel opened above estimates with $35.8 million when it launched in 3,388 locations, while Universal’s highly anticipated follow-up to “Mamma Mia!” debuted with $34.4 million from 3,317 screens. “Equalizer 2,” the irst sequel of Denzel Washington’s nearly four-decade long career, debuted overseas with $3.3 million in 11 international territories. In North America, “Equalizer 2” premiered ahead of its predecessor. 2014’s “The Equalizer” opened with $35 million and went on to generate $192 million worldwide, including $101 million domestically. https://variety.com/2018/film/box-office/box-office-equalizer-beats-mamma-mia-here-we-go-again-1202880521/ 1/4 7/23/2018“It was a surprise to come in at No 1. inBox an Office: extremely ‘Equalizer competitive2’ Beats ‘Mamma marketplace,”Mia!’ Sequel in Surprise Adrian Twist –Smith, Variety Sony’s head of domestic distribution, said. “It really speaks to the power of Denzel, without a doubt. -

NEW Releasescorrections
SWANK.COM/CORRECTIONAL 1.800.876.5577 1.800.876.5577 CorrectionsNEW RELEASES SUMMER 2018 © Paramount Pictures © Columbia Pictures Industries, Inc. © 2018 Marvel © Lions Gate Entertainment, Inc. © Universal Studios © Warner Bros. Entertainment Inc. MOVIE Ratings Guide Not Rated: Rated PG: Rated R: Black Cop Christopher Robin Action Point BlacKkKlansman Hotel Transylvania 3: Summer Vacation American Animals Boom for Real: The Late Teenage Incredibles 2 An Ordinary Man Years of Jean-Michel Basquiat Leave No Trace Backstabbing for Beginners Devil and Father Amorth, The Paws P.I. Beast Eighth Grade Pope Francis: A Man of His Word Blindspotting Equalizer 2, The Show Dogs Borg vs. McEnroe Escape, The Teen Titans GO! To the Movies Catcher Was a Spy, The Feral Zoo Cleanse, The Ghost Stories Con Is On, The Ideal Home Dark Crimes Juliet, Naked Rated PG-13: Don't Worry, He Won't Get Far on Foot Kid Like Jake, A A.X.L. First Purge, The © 2018 Marvel © Warner Bros. Entertainment Inc. Little Stranger, The Adrift First Reformed Robert Downey Jr., Sandra Bullock, Cate Blanchett, Ocean's 8 Mile 22 Chris Hemsworth, Mark Ruffalo Avengers: Infinity War Upon her release from prison, Debbie, the estranged Alpha Future World The Avengers assemble their power in order to Anne Hathaway Nancy Walt Disney Pictures Warner Bros. sister of legendary conman Danny Ocean, puts together Always at The Carlyle Gemini Directed by Anthony Russo fight their collective enemy, Thanos, before he can a team of unstoppable crooks to pull of the heist of the wreak havoc on the entire planet. Directed by Gary Ross Our House Rated PG-13; 149 minutes Rated PG-13; 110 minutes century.