Fuzzy Transfer Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genshiken Season Two 2 Free Ebook
FREEGENSHIKEN SEASON TWO 2 EBOOK Shimoku Kio | 200 pages | 21 Mar 2013 | Kodansha America, Inc | 9781612622422 | English | New York, United States Genshiken - Wikipedia The Society for the Study of Modern Visual Culture, otherwise known as Genshiken, is now under the charge of a more confident Sasahara. Things have changed in between semesters, and the otaku club now has a new otaku-hating member named Ogiue. Sasahara's initial goal of starting a doujin circle and selling those fan-made magazines at the next Comic Festival becomes a reality, but reality is a cruel master Afterward, the club is abuzz with talk about Tanaka and Ohno's relationship, which takes a hesitant step forward. Source: Media Blasters. Hide Ads Login Sign Up. Genshiken 2. Edit What would you like to edit? Add to My List. Add to Favorites. Buy on Manga Store. Synonyms: Gendai Shikaku Bunka Kenkyuukai 2. Type: TV. Premiered: Fall Licensors: Media Blasters. Studios: Arms. Score: 7. Ranked: 2 2 based on the top anime page. Ranked Popularity Members 71, Fall TV Arms. Preview Manga. More characters. Genshiken Season Two 2 staff. Edit Opening Theme. Edit Ending Genshiken Season Two 2. More reviews Reviews. Jan 1, Overall Rating : Jul 23, Overall Rating : 8. Jun 11, Overall Rating : 7. Mar 27, Overall Rating : 9. More discussions. More featured articles. Your harem or reverse harem anime isn't worth the time of day if it doesn't have a tsundere in it. But what is a tsundere, where did the term originate, and why are they everywhere? Read on to find out! More recommendations. -

Genshiken Season Two 1 Free
FREE GENSHIKEN SEASON TWO 1 PDF Kio Shimoku | 200 pages | 04 Sep 2012 | Kodansha America, Inc | 9781612622378 | English | New York, United States Genshiken - The series has Genshiken Season Two 1 been adapted into an anime directed by Tsutomu Mizushima. The manga originally ran in Kodansha 's monthly manga anthology Afternoon from April to Mayand has been reprinted in nine bound volumes. The ninth and final volume was released in Japan in December The series, being focused on the otaku lifestyle, contains numerous references to other mangaanimevideo games, and other aspects of otaku culture. Because the anime is co-produced by Sega Sammy Holdingsthe Guilty Gear video game series is heavily referenced, with actual gameplay sequences being shown multiple times, Ohno cosplaying as Kuradoberi Jamand other minor references. The Sega puzzle game Puyo Puyo [a] also serves as an important plot point as Kasukabe tries to gain Kousaka's attention. Discussion of erogeGenshiken Season Two 1 video games usually of the visual novel genre, also occurs often. Genshiken usually avoids referring to these series so in-depth that it would require the use of names and lines from their real-world counterparts, with several notable exceptions: in the model-building chapter of the manga but not the animeactual Gundam mecha and characters are referred to throughout, while the dialogue quoted by Sue except for one "Neko Yasha! These cultural references have remained intact for the English adaption of the manga, which include a section for translation notes. However, due to the number of allusions made and the inability for a translator to always know what is being referred to, many explanations of otaku references are still absent. -

Aniplex of America Announces Sword Art Online II Blu-Ray Disc Box Release in September
FOR IMMEDIATE RELEASE MAY 17, 2019 Aniplex of America Announces Sword Art Online II Blu-ray Disc Box Release in September ©2014 REKI KAWAHARA/PUBLISHED BY KADOKAWA CORPORATION ASCII MEDIA WORKS/SAOII Project The smash hit series gets a long-awaited box release featuring Phantom Bullet, Calibur, Mother’s Rosario, and tons of bonus content! SANTA MONICA, CA (MAY 17, 2019) – Aniplex of America is thrilled to announce the release of the Sword Art Online II Blu-ray Disc Box containing the Phantom Bullet, Calibur, and Mother’s Rosario arc later this year. The disc box will contain seven Blu-ray discs and a mini pinup poster, housed in a rigid box with illustrations by the series’s acclaimed character designer and chief animation director, Shingo Adachi. Along with all twenty-four episodes, the Blu-ray will be chock-full of bonus content including the special animation “Sword Art Offline 2,” original web previews, textless openings and endings, as well as audio commentary by the creators and Japanese cast. Fans will now have the opportunity to complete their collection alongside Aniplex of America’s Sword Art Online Blu-ray Disc Box (TV Series & Extra Edition) released in 2017. Sword Art Online II Blu-ray Disc Box will be available beginning September 24th with pre-orders open now at the online retailer, RightSttufAnime.com. Based on Reki Kawahara’s light novels with illustrations by abec, the anime series quickly became an international sensation since its premiere in 2012, followed by Sword Art Online II in 2014, with the English dub produced by Aniplex of America airing on Toonami in 2015. -

Genshiken Season Two 5 Free
FREE GENSHIKEN SEASON TWO 5 PDF Shimoku Kio | 208 pages | 18 Sep 2014 | Kodansha America, Inc | 9781612625768 | English | New York, United States Genshiken | Manga - Hide Ads Login Sign Up. Genshiken 2. Edit What would you like to edit? Add to My List. Add to Favorites. Buy on Manga Store. Synonyms: Gendai Shikaku Bunka Kenkyuukai 2. Type: TV. Premiered: Fall Licensors: Media Blasters. Studios: Arms. Score: 7. Ranked: 2 2 based on the top anime page. Add character. Add staff. More Top Airing Anime Genshiken Season Two 5 Haikyuu!! Add Detailed Info. Kasukabe, Genshiken Season Two 5 Main. Yukino, Satsuki Japanese. Jacobanis, Carol English. Kousaka, Makoto Main. Saiga, Mitsuki Japanese. Marlo, Kenneth Robert English. Madarame, Harunobu Main. Hiyama, Nobuyuki Japanese. Timoney, Bill English. Ogiue, Chika Main. Mizuhashi, Kaori Japanese. Knotz, Michele English. Oono, Kanako Main. Kawasumi, Ayako Japanese. Lillis, Rachael English. Sasahara, Kanji Main. Ooyama, Takanori Japanese. Perreca, Michael English. Tanaka, Souichiro Main. Seki, Tomokazu Japanese. Rogers, Bill English. Asada, Naoko Supporting. Saitou, Momoko Japanese. Genshiken Season Two 5, Angela Supporting. Kaida, Yuki Japanese. Haraguchi Supporting. Ishii, Kouji Japanese. Hopkins, Susanna Supporting. Gotou, Yuuko Japanese. Kato Supporting. Nakao, Eri Japanese. Koshimizu, Ami Japanese. Kitagawa, Yurie Supporting. Kobayashi, Sanae Japanese. Kuchiki, Manabu Supporting. Ishida, Akira Japanese. Lewis, Ted English. Kugayama, Mitsunori Supporting. Nomura, Kenji Japanese. Ward, James English. Nakajima, Yuuko Supporting. Endou, Aya Japanese. Sasahara, Keiko Supporting. Shimizu, Kaori Japanese. Shigeta, Mina Supporting. Iguchi, Yuka Japanese. Shodai Kaichou Supporting. Ueda, Yuuji Japanese. Ross, Jonathan Todd English. Takayanagi Supporting. Yanagisawa, Eiji Japanese. Yabusaki, Kumiko Supporting. Takagi, Reiko Japanese. Yoshimoto, Kinji Director. Aketagawa, Jin Sound Director. -
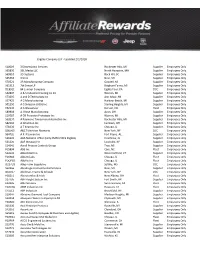
Eligible Company List - Updated 2/1/2018
Eligible Company List - Updated 2/1/2018 S10009 3 Dimensional Services Rochester Hills, MI Supplier Employees Only S65830 3BL Media LLC North Hampton, MA Supplier Employees Only S69510 3D Systems Rock Hill, SC Supplier Employees Only S65364 3IS Inc Novi, MI Supplier Employees Only S70521 3R Manufacturing Company Goodell, MI Supplier Employees Only S61313 7th Sense LP Bingham Farms, MI Supplier Employees Only D18911 84 Lumber Company Eighty Four, PA DCC Employees Only S42897 A & S Industrial Coating Co Inc Warren, MI Supplier Employees Only S73205 A and D Technology Inc Ann Arbor, MI Supplier Employees Only S57425 A G Manufacturing Harbour Beach, MI Supplier Employees Only S01250 A G Simpson (USA) Inc Sterling Heights, MI Supplier Employees Only F02130 A G Wassenaar Denver, CO Fleet Employees Only S80904 A J Rose Manufacturing Avon, OH Supplier Employees Only S19787 A OK Precision Prototype Inc Warren, MI Supplier Employees Only S62637 A Raymond Tinnerman Automotive Inc Rochester Hills, MI Supplier Employees Only S82162 A Schulman Inc Fairlawn, OH Supplier Employees Only S78336 A T Kearney Inc Chicago, IL Supplier Employees Only D80005 A&E Television Networks New York, NY DCC Employees Only S64720 A.P. Plasman Inc. Fort Payne, AL Supplier Employees Only S36205 AAA National Office (Only EMPLOYEES Eligible) Heathrow, FL Supplier Employees Only S31320 AAF McQuay Inc Louisville, KY Supplier Employees Only S14541 Aarell Process Controls Group Troy, MI Supplier Employees Only F05894 ABB Inc Cary, NC Fleet Employees Only S10035 Abbott Ball Co -

E-Title Certified Lienholders* Lienholder Idlienholder Name Address Line 1 Address Line 2 City State Zip Code 540623618001St Advantage FCU P.O
Texas Department of Motor Vehicle Registration and Title System e-Title Certified Lienholders* Lienholder IDLienholder Name Address Line 1 Address Line 2 City State Zip Code 540623618001st Advantage FCU P.O. Box 2116 Newport News VA 23609 750873880001ST Community FCU 3505 Wildewood Drive San Angelo TX 76904 460133740001st Financial Bank USA 47 Sherman Hill Rd Woodbury TX 06798 370580723001st MidAmerica Credit Union 731 E Bethalto Dr Bethalto IL 62010 9522491920020th Century Fox FCU PO Box 641849 Los Angeles CA 90064 27250498200360 Equipment Finance, LLC 300 Beardsley Lane Building D Suite 201 Austin Tx 78745 06067454100360 Federal Credit Union 191 Ella Grasso Turnpike Windsor Locks CT 06096 381524350004Front Credit Union PO Box 795 Traverse City MI 49685 82531214500777 Equipment Finance LLC 600 Brickell Ave 19th Floor Miami FL 33131 81376585600A Plus Finance PO Box 4136 McAllen TX 78502 74117864800A+ Federal Credit Union PO Box 14867 Austin TX 78761 82374905500AAB-CADI LLC 12001 SW 128th Ct Ste 106 Miami FL 33186 38029964300AAC Credit Union 177 Wilson Ave NW Grand Rapids MI 49534 11601490300AAFCU PO Box 619001 MD#2100 DFW Airport TX 752619001 75605437700AAFES Federal Credit Union PO Box 210708 Dallas TX 75211 52063737400Aberdeen Proving Ground Fed CU PO Box 1176 Aberdeen MD 21001 75088886000Abilene Teachers FCU PO Box 5706 Abilene TX 796085706 61054906800Abound Federal Credit Union PO Box 900 Radcliff KY 40159 83228040400ABT Keystone Auto Lending LLC 140 Intracoastal Pointe Dr Ste 212 Jupiter FL 33477 84056779600Academy Bank, N.A. 1111 Main St., Ste 202 Kansas City MO 64105 63113138100Acceptance Loan Company Inc PO Box 9219 Mobile AL 36691 26137562200Access Bank 210 N. -

ICRP 2019 Proceedings.Pdf
ANNALS OF THE ICRP 49 (S1) 2020 ANNALS OF THE ICRP 49 ANNALS OF THE ANNALS OF THE ICRP Annals of the ICRP is the official publication of the International Commission on Radiological Protection (ICRP). Established in 1928, ICRP advances for the public benefit the science of radiological protection, in particular by providing recommendations and guidance on all aspects of protection against ionising radiation. icrp.org ADELAIDE, AUSTRALIA ISSN ISBN Proceedings of the Fifth International Symposium on the System of Radiological Protection VOLUME 49 NO. S1, 2020 ISSN 0146-6453 • ISBN 9781529768541 AANI_49-S1NI_49-S1 ccover.inddover.indd 1 009-12-20209-12-2020 115:04:145:04:14 Subscriptions The Annals of the ICRP (ISSN: 0146-6453) is published in print and online by SAGE Publications (London, Thousand Oaks, CA, New Delhi, Singapore, Washington DC and Melbourne). Annual subscription (2020) including postage: Institutional Rate (combined print and electronic) £725/US$906. Note VAT might be applicable at the appropriate local rate. Visit sagepublishing.com for more details. To activate your subscription (institutions only) visit http://journals.sagepub.com. Abstracts, tables of contents and contents alerts are available on this site free of charge for all. Student discounts, single issue rates and advertising details are available from SAGE Publications Ltd, 1 Oliver’s Yard, 55 City Road, London EC1Y 1SP, UK, tel. +44 (0)20 7324 8500, fax +44 (0)20 7324 8600 and in North America, SAGE Publications Inc, PO Box 5096, Aims and Scope Thousand Oaks, CA 91320, USA. The International Commission on Radiological Protection (ICRP) is the primary body in protection against ionising radiation. -
A Presentation by the Comic Market Committee
www.comiket.co.jp A presentation by the Comic Market Committee January, 2008 Updated January, 2014 Copyright 2007ー2015 COMIKET www.comiket.co.jp Table of Contents Chapter 1: What is Comic Market? What are doujinshis? Chapter 2: Comic Market Today Chapter 3: History of Comic Market Chapter 4: The Ideals of Comic Market and its Present Status 2 Copyright 2007-2015 COMIKET www.comiket.co.jp Chapter One What is Comic Market? What are Doujinshis? Copyright 2007ー2015 COMIKET www.comiket.co.jp What are Doujinshis? What are Doujinshi Marketplaces? What are Doujinshis? - Doujinshis are defined in Japanese dictionaries as "magazines published as a cooperative effort by a group of individuals who share a common ideology or goals with the aim of establishing a medium through which their works can be presented." Originating from the world of literature, fine arts, and academia, doujinshis experienced unprecedented growth in Japan as a medium of self-expression for various subcultures centered around manga. - At present, books edited and published by individuals with the aim of presenting their own material are also considered doujinshis. - As a norm, doujinshis are not included in the commercial publishing distribution system. > The primary goal of doujinshi publishing is that of self-expression of one's own works--Ordinarily commercial gain is not the primary rationale behind engaging in the production of doujinshis. > Their distribution is limited in scope. What are Doujinshi Marketplaces? - Social functions centered around the display and distribution of doujinshis. - Their scale and function can vary from anywhere between small gatherings taking place in regular conference spaces where only a few dozen circles (doujinshi publishing groups) attend but can be big as the Comic Market where over 35,000 circles congregate. -

Aniplex of America to Release SWORD ART ONLINE -Extra Edition
FOR IMMEDIATE RELEASE September 27, 2014 Aniplex of America to Release SWORD ART ONLINE -Extra Edition- © REKI KAWAHARA/ASCII MEDIA WORKS/SAO Project The Sequel to the Hit SWORD ART ONLINE Series Coming This Winter! SANTA MONICA, CA (September 27, 2014) –Aniplex of America, Inc. recently announced at their industry panel at Anime Weekend Atlanta (Atlanta, GA.) that they will be releasing the home video versions of SWORD ART ONLINE –Extra Edition– on Blu-ray and DVD on December 23rd. Pre-orders for this product will begin next Monday (9/29/2014) on the official U.S. Sword Art Online homepage (www.SwordArt-OnlineUSA.com) and also through official retailers. The SWORD ART ONLINE –Extra Edition– will be available in the U.S., Canada, Central and South Americas. The SWORD ART ONLINE –Extra Edition– will feature both the original Japanese and English audios with English and Spanish subtitles. Bonus contents for the Blu-ray release will include the “Sword Art Offline” special animation (English subtitles included), the Sword Art Online II trailer, a deluxe booklet and an exclusive poster. The standard edition DVD will include the SAO II trailer as the bonus content. < BD Features> Spoken Languages: Japanese & English Subtitles: English & Spanish Total Run Time: Approx. 100 min. Rating: 13UP Special Animation “Sword Art Offline” (English subtitled) SAO II Trailer <Bonus Materials> Deluxe booklet Exclusive poster *Bonus contents subject to change. Product number and UPC bar code Title Street Date SKU # UPC SRP Store price Sword Art Online –Extra 12/23/2014 AOA-2905B 856137005216 $59.98 $49.98 Edition– Blu-ray < DVD Features> Spoken Languages: Japanese & English Subtitles: English & Spanish Total Run Time: Approx. -

Realismo En El Anime: Una Perspectiva Occidental a Través De Sus Obras Populares
UNIVERSIDAD COMPLUTENSE DE MADRID FACULTAD DE CIENCIAS DE LA INFORMACIÓN DEPARTAMENTO DE COMUNICACIÓN AUDIOVISUAL Y PUBLICIDAD I TESIS DOCTORAL El realismo en el anime: Una perspectiva occidental a través de sus obras populares MEMORIA PARA OPTAR AL GRADO DE DOCTOR PRESENTADA POR Iván Rodríguez Fernández Directora Mar Marcos Molano Madrid, 2014 ©Iván Rodríguez Fernández, 2014 El realismo en el anime: Una perspectiva occidental a través de sus obras más populares Iván Rodríguez Fernández Departamento Comunicación Audiovisual y Publicidad I Dirección: Mar Marcos Molano 2 3 4 Índice Resumen Español ............................... 17 Resumen Inglés ................................... 21 I Introducción ..................... 27 II Metodología ..................... 37 1. Objeto de estudio .................... 39 2. Objetivos ............................ 39 3. Hipótesis ............................ 40 4. Marco Conceptual ..................... 40 4.1. El anime .................................... 40 4.1.1. Definición común de anime ................... 40 4.1.1.1. Contradicciones en la definición ............ 40 5 4.1.2. Otro términos ............................... 42 4.1.2.1. Japanimation ................................ 43 4.1.2.2. Manga ....................................... 43 4.1.2.3. Películas manga ............................. 43 4.1.2.4. Manga-Eiga .................................. 44 4.1.3. Origen del término .......................... 45 4.1.4. ¿Qué es anime? .............................. 45 5. Contexto metodológico: Realismo ..... -
Protoculture Addicts #62
Sample file CONTENTS 3 ○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ PROTOCULTURE ✾ PRESENTATION ........................................................................................................... 4 STAFF WHAT'S GOING ON? ANIME & MANGA NEWS .......................................................................................................... 5 Claude J. Pelletier [CJP] — Publisher / Manager VIDEO & MANGA RELEASES ................................................................................................... 6 Martin Ouellette [MO] — Editor-in-Chief PRODUCTS RELEASES .............................................................................................................. 8 Miyako Matsuda [MM] — Editor / Translator NEW RELEASES ..................................................................................................................... 10 Contributors Aaron Dawe, Asaka Dawe, Keith Dawe REVIEWS Kevin Lillard, James S. Taylor LIVE-ACTION ........................................................................................................................ 15 Layout BOOKS ......................................................................................................................... 19, 49 MODELS .............................................................................................................................. 36 The Safe House MANGA ............................................................................................................................. -

Universidad Autónoma Del Estado De México Facultad De Humanidades
UNIVERSIDAD AUTÓNOMA DEL ESTADO DE MÉXICO FACULTAD DE HUMANIDADES LICENCIATURA EN CIENCIAS DE LA INFORMACIÓN DOCUMENTAL T E S I S Biblioteca digital de partituras de anime: visión desde la Licenciatura en Ciencias de la Información Documental (LCID) Que para obtener el título de: Licenciada en Ciencias de la Información Documental Presenta: María de la Paz Álvarez Martínez Asesor: Mtro. Evaristo Hernández Carmona Toluca, Estado de México, 2020. Contenido pág. Introducción……………………………………………………………………………………………………. 1 1. Bases de la investigación…………………………………………………………………………………… 3 2. Bases teóricas de la recuperación de la información, sistemas de recuperación de 16 información (SRI) y bibliotecas digitales (BD)…………………………………………………………… 2.1. Recuperación de la información…………………………………………………………………….. 16 2.2. Sistemas de recuperación de información……………………………………………………….. 17 2.3. Bibliotecas digitales (BD) ……………………………………………………………………………. 18 2.3.1. Definición y antecedentes generales…………………………………………………….. 18 2.3.2. Características de las BD…………………………………………………………………… 20 2.3.3. Colecciones…………………………………………………………………………………… 21 2.3.4. Servicios………………………………………………………………………………………. 23 2.3.5. Tipos de BD…………………………………………………………………………………… 25 2.3.6. Software para integración de BD…………………………………………………………. 25 2.3.6.1. Software libre…………………………………………………………………….. 26 2.3.6.2. Software propietario o comercial……………………………………………… 28 2.3.6.3. Ventajas y desventajas del software libre y propietario………………….. 29 2.3.7. Bibliotecas digitales y partituras…………………………………………………………. 31 2.3.8. Catalogación de partituras…………………………………………………………………. 36 2.3.8.1. Reglas de Catalogación Angloamericanas (Segunda Edición)…………. 36 2.4. Las bibliotecas digitales y su relación con los sistemas de recuperación de información 42 2.4.1. Recuperación de la información a través de la indización…………………………… 42 3. El anime: historia, géneros, música e impacto y uso en diversos campos del conocimiento 46 3.1.