Implementing a One Address CPU in Logisim Charles W
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison of Parallel and Pipelined CORDIC Algorithm Using RCA and CSA
Comparison of Parallel and Pipelined CORDIC algorithm using RCA and CSA Diego Barragan´ Guerrero Lu´ıs Geraldo P. Meloni FEEC - UNICAMP FEEC - UNICAMP Campinas, Sao˜ Paulo, Brazil, 13083-852 Campinas, Sao˜ Paulo, Brazil, 13083-852 +5519 9308-9952 +5519 9778-1523 [email protected] [email protected] Abstract— This paper presents an implementation of the algorithm has two modes of operation: the rotational mode CORDIC algorithm in digital hardware using two types of (RM) where the vector (xi; yi) is rotated by an angle θ to algebraic adders: Ripple-Carry Adder (RCA) and Carry-Select obtain a new vector (x ; y ), and the vectoring mode (VM) Adder (CSA), both in parallel and pipelined architectures. Anal- N N ysis of time performance and resources utilization was carried in which the algorithm computes the modulus R and phase α out by changing the algorithm number of iterations. These results from the x-axis of the vector (x0; y0). The basic principle of demonstrate the efficiency in operating frequency of the pipelined the algorithm is shown in Figure 1. architecture with respect to the parallel architecture. Also it is shown that the use of CSA reduce the timing processing without significantly increasing the slice use. The code was synthesized us- ing FPGA development tools for the Xilinx Spartan-3E xc3s500e ' ' E N y family. N E N Index Terms— CORDIC, pipelined, parallel, RCA, CSA, y N trigonometrics functions. Rotação Pseudo-rotação R N I. INTRODUCTION E i In Digital Signal Processing with FPGA, trigonometric y i R i functions are used in many signal algorithms, for instance N synchronization and equalization [12]. -

Basics of Logic Design Arithmetic Logic Unit (ALU) Today's Lecture
Basics of Logic Design Arithmetic Logic Unit (ALU) CPS 104 Lecture 9 Today’s Lecture • Homework #3 Assigned Due March 3 • Project Groups assigned & posted to blackboard. • Project Specification is on Web Due April 19 • Building the building blocks… Outline • Review • Digital building blocks • An Arithmetic Logic Unit (ALU) Reading Appendix B, Chapter 3 © Alvin R. Lebeck CPS 104 2 Review: Digital Design • Logic Design, Switching Circuits, Digital Logic Recall: Everything is built from transistors • A transistor is a switch • It is either on or off • On or off can represent True or False Given a bunch of bits (0 or 1)… • Is this instruction a lw or a beq? • What register do I read? • How do I add two numbers? • Need a method to reason about complex expressions © Alvin R. Lebeck CPS 104 3 Review: Boolean Functions • Boolean functions have arguments that take two values ({T,F} or {0,1}) and they return a single or a set of ({T,F} or {0,1}) value(s). • Boolean functions can always be represented by a table called a “Truth Table” • Example: F: {0,1}3 -> {0,1}2 a b c f1f2 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0 1 1 0 0 1 0 0 1 0 1 1 0 0 1 1 1 1 1 1 © Alvin R. Lebeck CPS 104 4 Review: Boolean Functions and Expressions F(A, B, C) = (A * B) + (~A * C) ABCF 0000 0011 0100 0111 1000 1010 1101 1111 © Alvin R. Lebeck CPS 104 5 Review: Boolean Gates • Gates are electronics devices that implement simple Boolean functions Examples a a AND(a,b) OR(a,b) a NOT(a) b b a XOR(a,b) a NAND(a,b) b b a NOR(a,b) a XNOR(a,b) b b © Alvin R. -

Chapter 3: Data Transmission Terminology
Chapter 3: Data Transmission CS420/520 Axel Krings Page 1 Sequence 3 Terminology (1) • Transmitter • Receiver • Medium —Guided medium • e.g. twisted pair, coaxial cable, optical fiber —Unguided medium • e.g. air, seawater, vacuum CS420/520 Axel Krings Page 2 Sequence 3 1 Terminology (2) • Direct link —No intermediate devices • Point-to-point —Direct link —Only 2 devices share link • Multi-point —More than two devices share the link CS420/520 Axel Krings Page 3 Sequence 3 Terminology (3) • Simplex —One direction —One side transmits, the other receives • e.g. Television • Half duplex —Either direction, but only one way at a time • e.g. police radio • Full duplex —Both stations may transmit simultaneously —Medium carries signals in both direction at same time • e.g. telephone CS420/520 Axel Krings Page 4 Sequence 3 2 Frequency, Spectrum and Bandwidth • Time domain concepts —Analog signal • Varies in a smooth way over time —Digital signal • Maintains a constant level then changes to another constant level —Periodic signal • Pattern repeated over time —Aperiodic signal • Pattern not repeated over time CS420/520 Axel Krings Page 5 Sequence 3 Analogue & Digital Signals Amplitude (volts) Time (a) Analog Amplitude (volts) Time (b) Digital CS420/520 Axel Krings Page 6 Sequence 3 Figure 3.1 Analog and Digital Waveforms 3 Periodic A ) s t l o v ( Signals e d u t 0 i l p Time m A –A period = T = 1/f (a) Sine wave A ) s t l o v ( e d u 0 t i l Time p m A –A period = T = 1/f CS420/520 Axel Krings Page 7 (b) Square wave Sequence 3 Figure 3.2 Examples of Periodic Signals Sine Wave • Peak Amplitude (A) —maximum strength of signal, in volts • FreQuency (f) —Rate of change of signal, in Hertz (Hz) or cycles per second —Period (T): time for one repetition, T = 1/f • Phase (f) —Relative position in time • Periodic signal s(t +T) = s(t) • General wave s(t) = Asin(2πft + Φ) CS420/520 Axel Krings Page 8 Sequence 3 4 Periodic Signal: e.g. -

The Central Processing Unit(CPU). the Brain of Any Computer System Is the CPU
Computer Fundamentals 1'stage Lec. (8 ) College of Computer Technology Dept.Information Networks The central processing unit(CPU). The brain of any computer system is the CPU. It controls the functioning of the other units and process the data. The CPU is sometimes called the processor, or in the personal computer field called “microprocessor”. It is a single integrated circuit that contains all the electronics needed to execute a program. The processor calculates (add, multiplies and so on), performs logical operations (compares numbers and make decisions), and controls the transfer of data among devices. The processor acts as the controller of all actions or services provided by the system. Processor actions are synchronized to its clock input. A clock signal consists of clock cycles. The time to complete a clock cycle is called the clock period. Normally, we use the clock frequency, which is the inverse of the clock period, to specify the clock. The clock frequency is measured in Hertz, which represents one cycle/second. Hertz is abbreviated as Hz. Usually, we use mega Hertz (MHz) and giga Hertz (GHz) as in 1.8 GHz Pentium. The processor can be thought of as executing the following cycle forever: 1. Fetch an instruction from the memory, 2. Decode the instruction (i.e., determine the instruction type), 3. Execute the instruction (i.e., perform the action specified by the instruction). Execution of an instruction involves fetching any required operands, performing the specified operation, and writing the results back. This process is often referred to as the fetch- execute cycle, or simply the execution cycle. -

Implementation of Carry Tree Adders and Compare with RCA and CSLA
International Journal of Emerging Engineering Research and Technology Volume 4, Issue 1, January 2016, PP 1-11 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Implementation of Carry Tree Adders and Compare with RCA and CSLA 1 2 G. Venkatanaga Kumar , C.H Pushpalatha Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (PG Scholar) Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (Associate Professor) ABSTRACT The binary adder is the critical element in most digital circuit designs including digital signal processors (DSP) and microprocessor data path units. As such, extensive research continues to be focused on improving the power delay performance of the adder. In VLSI implementations, parallel-prefix adders are known to have the best performance. Binary adders are one of the most essential logic elements within a digital system. In addition, binary adders are also helpful in units other than Arithmetic Logic Units (ALU), such as multipliers, dividers and memory addressing. Therefore, binary addition is essential that any improvement in binary addition can result in a performance boost for any computing system and, hence, help improve the performance of the entire system. Parallel-prefix adders (also known as carry-tree adders) are known to have the best performance in VLSI designs. This paper investigates three types of carry-tree adders (the Kogge- Stone, sparse Kogge-Stone, Ladner-Fischer and spanning tree adder) and compares them to the simple Ripple Carry Adder (RCA) and Carry Skip Adder (CSA). In this project Xilinx-ISE tool is used for simulation, logical verification, and further synthesizing. This algorithm is implemented in Xilinx 13.2 version and verified using Spartan 3e kit. -

Subchapter 2.4–Hp Server Rp5400 Series
Chapter 2 hp server rp5400 series Subchapter 2.4—hp server rp5400 series hp server rp5470 Table 2.4.1 HP Server rp5470 Specifications Server model number rp5470 Max. Network Interface Cards (cont.)–see supported I/O table Server product number A6144B ATM 155 Mb/s–MMF 10 Number of Processors 1-4 ATM 155 Mb/s–UTP5 10 Supported Processors ATM 622 Mb/s–MMF 10 PA-RISC PA-8700 Processor @ 650 and 750 MHz 802.5 Token Ring 4/16/100 Mb/s 10 Cache–Instr/data per CPU (KB) 750/1500 Dual port X.25/SDLC/FR 10 Floating Point Coprocessor included Yes Quad port X.25/FR 7 FDDI 10 Max. Additional Interface Cards–see supported I/O table 8 port Terminal Multiplexer 4 64 port Terminal Multiplexer 10 PA-RISC PA-8600 Processor @ 550 MHz Graphics/USB kit 1 kit (2 cards) Cache–Instr/data/CPU (KB) 512/1024 Public Key Cryptography 10 Floating Point Coprocessor included Yes HyperFabric 7 Electrical Characteristics TPM estimate (4 CPUs) 34,500 AC Input power 100-240V 50/60 Hz SPECweb99 (4 CPUs) 3,750 Hotswap Power supplies 2 included, 3rd for N+1 Redundant AC power inputs 2 required, 3rd for N+1 Min. memory 256 MB Current requirements at 200V 6.5 A (shared across inputs) Max. memory capacity 16 GB Typical Power dissipation (watts) 1008 W Internal Disks Maximum Power dissipation (watts) 1 1360 W Max. disk mechanisms 4 Power factor at full load .98 Max. disk capacity 292 GB kW rating for UPS loading1 1.3 Standard Integrated I/O Maximum Heat dissipation (BTUs/hour) 1 4380 - (3000 typical) Ultra2 SCSI–LVD Yes Site Preparation 10/100Base-T (RJ-45 connector) Yes Site planning and installation included No RS-232 serial ports (multiplexed from DB-25 port) 3 Depth (mm/inches) 774 mm/30.5 Web Console (including 10Base-T port) Yes Width (mm/inches) 482 mm/19 I/O buses and slots Rack Height (EIA/mm/inches) 7 EIA/311/12.25 Total PCI Slots (supports 66/33 MHz×64/32 bits) 10 Deskside Height (mm/inches) 368 mm/14.5 2 Hot-Plug Twin-Turbo (500 MB/s) and 6 Hot-Plug Turbo slots (250 MB/s) Weight (kg/lbs) Max. -

Analysis of GPGPU Programs for Data-Race and Barrier Divergence
Analysis of GPGPU Programs for Data-race and Barrier Divergence Santonu Sarkar1, Prateek Kandelwal2, Soumyadip Bandyopadhyay3 and Holger Giese3 1ABB Corporate Research, India 2MathWorks, India 3Hasso Plattner Institute fur¨ Digital Engineering gGmbH, Germany Keywords: Verification, SMT Solver, CUDA, GPGPU, Data Races, Barrier Divergence. Abstract: Todays business and scientific applications have a high computing demand due to the increasing data size and the demand for responsiveness. Many such applications have a high degree of parallelism and GPGPUs emerge as a fit candidate for the demand. GPGPUs can offer an extremely high degree of data parallelism owing to its architecture that has many computing cores. However, unless the programs written to exploit the architecture are correct, the potential gain in performance cannot be achieved. In this paper, we focus on the two important properties of the programs written for GPGPUs, namely i) the data-race conditions and ii) the barrier divergence. We present a technique to identify the existence of these properties in a CUDA program using a static property verification method. The proposed approach can be utilized in tandem with normal application development process to help the programmer to remove the bugs that can have an impact on the performance and improve the safety of a CUDA program. 1 INTRODUCTION ans that the program will never end-up in an errone- ous state, or will never stop functioning in an arbitrary With the order of magnitude increase in computing manner, is a well-known and critical property that an demand in the business and scientific applications, de- operational system should exhibit (Lamport, 1977). -
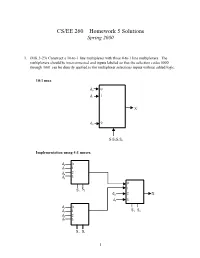
CS/EE 260 – Homework 5 Solutions Spring 2000
CS/EE 260 – Homework 5 Solutions Spring 2000 1. (MK 3-23) Construct a 10-to-1 line multiplexer with three 4-to-1 line multiplexers. The multiplexers should be interconnected and inputs labeled so that the selection codes 0000 through 1001 can be directly applied to the multiplexer selections inputs without added logic. 10:1 mux d0 0 1 d1 1 X d9 9 S3S2S1S0 Implementation using 4:1 muxes. d0 0 d2 1 d4 2 d6 3 0 S 1 S2 1 d8 2 X d9 3 d 0 1 S S d3 1 3 0 d5 2 d7 3 S2 S1 1 2. (MK 3-27) Implement a binary full adder with a dual 4-to-1 line multiplexer and a single inverter. AB Ci S Co 00 0 0 0 C 0 00 1 1 i 0 01 0 1 0 C ´ C 01 1 0 i 1 i 10 0 1 0 10 1 0Ci´ 1 Ci 11 0 0 1 C 1 11 1 1 i 1 0 C 1 i 4:1 2 S 3 mux S1 S0 A B 0 0 1 4:1 Co 2 mux 1 3 S1S0 2 3. (MK 3-34) Design a combinational circuit that forms the 2-bit binary sum S1S0 of two 2-bit numbers A1A0 and B1B0 and has both input C0 and a carry output C2. Do not use half adders or full adders, but instead use a two-level circuit plus inverters for the input variables, as needed. Design the circuit by starting with the following equations for each of the two bits of the adder. -

The Intel Microprocessors: Architecture, Programming and Interfacing Introduction to the Microprocessor and Computer
Microprocessors (0630371) Fall 2010/2011 – Lecture Notes # 1 The Intel Microprocessors: Architecture, Programming and Interfacing Introduction to the Microprocessor and computer Outline of the Lecture Evolution of programming languages. Microcomputer Architecture. Instruction Execution Cycle. Evolution of programming languages: Machine language - the programmer had to remember the machine codes for various operations, and had to remember the locations of the data in the main memory like: 0101 0011 0111… Assembly Language - an instruction is an easy –to- remember form called a mnemonic code . Example: Assembly Language Machine Language Load 100100 ADD 100101 SUB 100011 We need a program called an assembler that translates the assembly language instructions into machine language. High-level languages Fortran, Cobol, Pascal, C++, C# and java. We need a compiler to translate instructions written in high-level languages into machine code. Microprocessor-based system (Micro computer) Architecture Data Bus, I/O bus Memory Storage I/O I/O Registers Unit Device Device Central Processing Unit #1 #2 (CPU ) ALU CU Clock Control Unit Address Bus The figure shows the main components of a microprocessor-based system: CPU- Central Processing Unit , where calculations and logic operations are done. CPU contains registers , a high-frequency clock , a control unit ( CU ) and an arithmetic logic unit ( ALU ). o Clock : synchronizes the internal operations of the CPU with other system components using clock pulsing at a constant rate (the basic unit of time for machine instructions is a machine cycle or clock cycle) One cycle A machine instruction requires at least one clock cycle some instruction require 50 clocks. o Control Unit (CU) - generate the needed control signals to coordinate the sequencing of steps involved in executing machine instructions: (fetches data and instructions and decodes addresses for the ALU). -

(12) United States Patent (10) Patent No.: US 7,994,744 B2 Chen (45) Date of Patent: Aug
US007994744B2 (12) United States Patent (10) Patent No.: US 7,994,744 B2 Chen (45) Date of Patent: Aug. 9, 2011 (54) METHOD OF CONTROLLING SPEED OF (56) References Cited BRUSHLESS MOTOR OF CELING FAN AND THE CIRCUIT THEREOF U.S. PATENT DOCUMENTS 4,546,293 A * 10/1985 Peterson et al. ......... 3.18/400.14 5,309,077 A * 5/1994 Choi ............................. 318,799 (75) Inventor: Chien-Hsun Chen, Taichung (TW) 5,748,206 A * 5/1998 Yamane .......................... 34.737 2007/0182350 A1* 8, 2007 Patterson et al. ............. 318,432 (73) Assignee: Rhine Electronic Co., Ltd., Taichung County (TW) * cited by examiner Primary Examiner — Bentsu Ro (*) Notice: Subject to any disclaimer, the term of this (74) Attorney, Agent, or Firm — Browdy and Neimark, patent is extended or adjusted under 35 PLLC U.S.C. 154(b) by 539 days. (57) ABSTRACT The present invention relates to a method and a circuit of (21) Appl. No.: 12/209,037 controlling a speed of a brushless motor of a ceiling fan. The circuit includes a motor PWM duty consumption sampling (22) Filed: Sep. 11, 2008 unit and a motor speed sampling to sense a PWM duty and a speed of the brushless motor. A central processing unit is (65) Prior Publication Data provided to compare the PWM duty and the speed of the brushless motor to a preset maximum PWM duty and a preset US 201O/OO6O224A1 Mar. 11, 2010 maximum speed. When the PWM duty reaches to the preset maximum PWM duty first, the central processing unit sets the (51) Int. -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

A Soft-Switched Square-Wave Half-Bridge DC-DC Converter
A Soft-Switched Square-Wave Half-Bridge DC-DC Converter C. R. Sullivan S. R. Sanders From IEEE Transactions on Aerospace and Electronic Systems, vol. 33, no. 2, pp. 456–463. °c 1997 IEEE. Personal use of this material is permitted. However, permission to reprint or republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE. I. INTRODUCTION This paper introduces a constant-frequency zero-voltage-switched square-wave dc-dc converter Soft-Switched Square-Wave and presents results from experimental half-bridge implementations. The circuit is built with a saturating Half-Bridge DC-DC Converter magnetic element that provides a mechanism to effect both soft switching and control. The square current and voltage waveforms result in low voltage and current stresses on the primary switch devices and on the secondary rectifier diodes, equal to those CHARLES R. SULLIVAN, Member, IEEE in a standard half-bridge pulsewidth modulated SETH R. SANDERS, Member, IEEE (PWM) converter. The primary active switches exhibit University of California zero-voltage switching. The output rectifiers also exhibit zero-voltage switching. (In a center-tapped secondary configuration the rectifier does have small switching losses due to the finite leakage A constant-frequency zero-voltage-switched square-wave inductance between the two secondary windings on dc-dc converter is introduced, and results from experimental the transformer.) The VA rating, and hence physical half-bridge implementations are presented. A nonlinear magnetic size, of the nonlinear reactor is small, a fraction element produces the advantageous square waveforms, and of that of the transformer in an isolated circuit.