GENETIC STUDY of NEUROLOGICAL DISORDERS (Neuroref Global®) by MASSIVE SEQUENCING (NGS)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

The Inactive X Chromosome Is Epigenetically Unstable and Transcriptionally Labile in Breast Cancer
Supplemental Information The inactive X chromosome is epigenetically unstable and transcriptionally labile in breast cancer Ronan Chaligné1,2,3,8, Tatiana Popova1,4, Marco-Antonio Mendoza-Parra5, Mohamed-Ashick M. Saleem5 , David Gentien1,6, Kristen Ban1,2,3,8, Tristan Piolot1,7, Olivier Leroy1,7, Odette Mariani6, Hinrich Gronemeyer*5, Anne Vincent-Salomon*1,4,6,8, Marc-Henri Stern*1,4,6 and Edith Heard*1,2,3,8 Extended Experimental Procedures Cell Culture Human Mammary Epithelial Cells (HMEC, Invitrogen) were grown in serum-free medium (HuMEC, Invitrogen). WI- 38, ZR-75-1, SK-BR-3 and MDA-MB-436 cells were grown in Dulbecco’s modified Eagle’s medium (DMEM; Invitrogen) containing 10% fetal bovine serum (FBS). DNA Methylation analysis. We bisulfite-treated 2 µg of genomic DNA using Epitect bisulfite kit (Qiagen). Bisulfite converted DNA was amplified with bisulfite primers listed in Table S3. All primers incorporated a T7 promoter tag, and PCR conditions are available upon request. We analyzed PCR products by MALDI-TOF mass spectrometry after in vitro transcription and specific cleavage (EpiTYPER by Sequenom®). For each amplicon, we analyzed two independent DNA samples and several CG sites in the CpG Island. Design of primers and selection of best promoter region to assess (approx. 500 bp) were done by a combination of UCSC Genome Browser (http://genome.ucsc.edu) and MethPrimer (http://www.urogene.org). All the primers used are listed (Table S3). NB: MAGEC2 CpG analysis have been done with a combination of two CpG island identified in the gene core. Analysis of RNA allelic expression profiles (based on Human SNP Array 6.0) DNA and RNA hybridizations were normalized by Genotyping console. -

Multiple Actions of Φ-LITX-Lw1a on Ryanodine Receptors Reveal a Functional Link Between Scorpion DDH and ICK Toxins
Multiple actions of φ-LITX-Lw1a on ryanodine receptors reveal a functional link between scorpion DDH and ICK toxins Jennifer J. Smitha, Irina Vettera, Richard J. Lewisa, Steve Peigneurb, Jan Tytgatb, Alexander Lamc, Esther M. Gallantc, Nicole A. Beardd, Paul F. Alewooda,1,2, and Angela F. Dulhuntyc,1,2 aChemical and Structural Biology, Institute for Molecular Biosciences, University of Queensland, St. Lucia, QLD 4072, Australia; bLaboratory of Toxicology, University of Leuven, 3000 Leuven, Belgium; cDepartment of Molecular Bioscience, John Curtin School of Medical Research, Australian National University, Canberra, ACT 2601, Australia; and dDiscipline of Biomedical Sciences, Faculty of Education, Science, Technology and Mathematics, University of Canberra, Canberra, ACT 2601, Australia Edited by Clara Franzini-Armstrong, University of Pennsylvania Medical Center, Philadelphia, PA, and approved April 23, 2013 (received for review August 26, 2012) We recently reported the isolation of a scorpion toxin named U1- mutations, atypical posttranslational modifications of RyRs, liotoxin-Lw1a (U1-LITX-Lw1a) that adopts an unusual 3D fold termed including hyperphosphorylation and S-nitrosylation, have been the disulfide-directed hairpin (DDH) motif, which is the proposed implicated in heart failure and pathologic muscle fatigue (10– evolutionary structural precursor of the three-disulfide-containing 12). Because of their wide distribution, there is mounting evidence inhibitor cystine knot (ICK) motif found widely in animals and plants. to suggest that dysregulation of RyRs also plays a role in a plethora Here we reveal that U1-LITX-Lw1a targets and activates the mam- of other disease states, including chronic pain, neurodegenerative malian ryanodine receptor intracellular calcium release channel (RyR) disorders such as Alzheimer’s disease, and intellectual deficit (13– with high (fM) potency and provides a functional link between DDH 15). -
Cldn19 Clic2 Clmp Cln3
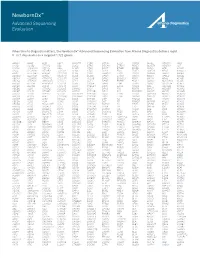
NewbornDx™ Advanced Sequencing Evaluation When time to diagnosis matters, the NewbornDx™ Advanced Sequencing Evaluation from Athena Diagnostics delivers rapid, 5- to 7-day results on a targeted 1,722-genes. A2ML1 ALAD ATM CAV1 CLDN19 CTNS DOCK7 ETFB FOXC2 GLUL HOXC13 JAK3 AAAS ALAS2 ATP1A2 CBL CLIC2 CTRC DOCK8 ETFDH FOXE1 GLYCTK HOXD13 JUP AARS2 ALDH18A1 ATP1A3 CBS CLMP CTSA DOK7 ETHE1 FOXE3 GM2A HPD KANK1 AASS ALDH1A2 ATP2B3 CC2D2A CLN3 CTSD DOLK EVC FOXF1 GMPPA HPGD K ANSL1 ABAT ALDH3A2 ATP5A1 CCDC103 CLN5 CTSK DPAGT1 EVC2 FOXG1 GMPPB HPRT1 KAT6B ABCA12 ALDH4A1 ATP5E CCDC114 CLN6 CUBN DPM1 EXOC4 FOXH1 GNA11 HPSE2 KCNA2 ABCA3 ALDH5A1 ATP6AP2 CCDC151 CLN8 CUL4B DPM2 EXOSC3 FOXI1 GNAI3 HRAS KCNB1 ABCA4 ALDH7A1 ATP6V0A2 CCDC22 CLP1 CUL7 DPM3 EXPH5 FOXL2 GNAO1 HSD17B10 KCND2 ABCB11 ALDOA ATP6V1B1 CCDC39 CLPB CXCR4 DPP6 EYA1 FOXP1 GNAS HSD17B4 KCNE1 ABCB4 ALDOB ATP7A CCDC40 CLPP CYB5R3 DPYD EZH2 FOXP2 GNE HSD3B2 KCNE2 ABCB6 ALG1 ATP8A2 CCDC65 CNNM2 CYC1 DPYS F10 FOXP3 GNMT HSD3B7 KCNH2 ABCB7 ALG11 ATP8B1 CCDC78 CNTN1 CYP11B1 DRC1 F11 FOXRED1 GNPAT HSPD1 KCNH5 ABCC2 ALG12 ATPAF2 CCDC8 CNTNAP1 CYP11B2 DSC2 F13A1 FRAS1 GNPTAB HSPG2 KCNJ10 ABCC8 ALG13 ATR CCDC88C CNTNAP2 CYP17A1 DSG1 F13B FREM1 GNPTG HUWE1 KCNJ11 ABCC9 ALG14 ATRX CCND2 COA5 CYP1B1 DSP F2 FREM2 GNS HYDIN KCNJ13 ABCD3 ALG2 AUH CCNO COG1 CYP24A1 DST F5 FRMD7 GORAB HYLS1 KCNJ2 ABCD4 ALG3 B3GALNT2 CCS COG4 CYP26C1 DSTYK F7 FTCD GP1BA IBA57 KCNJ5 ABHD5 ALG6 B3GAT3 CCT5 COG5 CYP27A1 DTNA F8 FTO GP1BB ICK KCNJ8 ACAD8 ALG8 B3GLCT CD151 COG6 CYP27B1 DUOX2 F9 FUCA1 GP6 ICOS KCNK3 ACAD9 ALG9 -

Application of Microrna Database Mining in Biomarker Discovery and Identification of Therapeutic Targets for Complex Disease
Article Application of microRNA Database Mining in Biomarker Discovery and Identification of Therapeutic Targets for Complex Disease Jennifer L. Major, Rushita A. Bagchi * and Julie Pires da Silva * Department of Medicine, Division of Cardiology, University of Colorado Anschutz Medical Campus, Aurora, CO 80045, USA; [email protected] * Correspondence: [email protected] (R.A.B.); [email protected] (J.P.d.S.) Supplementary Tables Methods Protoc. 2021, 4, 5. https://doi.org/10.3390/mps4010005 www.mdpi.com/journal/mps Methods Protoc. 2021, 4, 5. https://doi.org/10.3390/mps4010005 2 of 25 Table 1. List of all hsa-miRs identified by Human microRNA Disease Database (HMDD; v3.2) analysis. hsa-miRs were identified using the term “genetics” and “circulating” as input in HMDD. Targets CAD hsa-miR-1 Targets IR injury hsa-miR-423 Targets Obesity hsa-miR-499 hsa-miR-146a Circulating Obesity Genetics CAD hsa-miR-423 hsa-miR-146a Circulating CAD hsa-miR-149 hsa-miR-499 Circulating IR Injury hsa-miR-146a Circulating Obesity hsa-miR-122 Genetics Stroke Circulating CAD hsa-miR-122 Circulating Stroke hsa-miR-122 Genetics Obesity Circulating Stroke hsa-miR-26b hsa-miR-17 hsa-miR-223 Targets CAD hsa-miR-340 hsa-miR-34a hsa-miR-92a hsa-miR-126 Circulating Obesity Targets IR injury hsa-miR-21 hsa-miR-423 hsa-miR-126 hsa-miR-143 Targets Obesity hsa-miR-21 hsa-miR-223 hsa-miR-34a hsa-miR-17 Targets CAD hsa-miR-223 hsa-miR-92a hsa-miR-126 Targets IR injury hsa-miR-155 hsa-miR-21 Circulating CAD hsa-miR-126 hsa-miR-145 hsa-miR-21 Targets Obesity hsa-mir-223 hsa-mir-499 hsa-mir-574 Targets IR injury hsa-mir-21 Circulating IR injury Targets Obesity hsa-mir-21 Targets CAD hsa-mir-22 hsa-mir-133a Targets IR injury hsa-mir-155 hsa-mir-21 Circulating Stroke hsa-mir-145 hsa-mir-146b Targets Obesity hsa-mir-21 hsa-mir-29b Methods Protoc. -

Free PDF Download
European Review for Medical and Pharmacological Sciences 2019; 23: 1710-1721 Next-generation sequencing identifies a homozygous mutation in ACADVL associated with pediatric familial dilated cardiomyopathy S.J. CARLUS1, I.S. ALMUZAINI2, M. KARTHIKEYAN3, L. LOGANATHAN3, G.S. AL-HARBI1, A.M. ABDALLAH4, K.M. AL-HARBI1 1Pediatrics Department, Cardiogenetics Unit, College of Medicine, Taibah University, Al-Madinah, Kingdom of Saudi Arabia 2Department of Pediatric Cardiology, Al-Madinah Maternity and Children Hospital (MMCH), Al-Madinah, Kingdom of Saudi Arabia 3Department of Bioinformatics, Alagappa University, Karaikudi, Tamil Nadu, India 4West Midlands Regional Genetics Laboratory, Birmingham Women’s NHS Foundation Trust, Birmingham, United Kingdom Abstract. – OBJECTIVE: Pediatric familial di- Key Words lated cardiomyopathy (DCM) is a rare and se- Pediatric familial dilated cardiomyopathy, Targeted vere heart disease. The genetics of familial DCM gene sequencing, ACADVL, Saudi Arabia, Consanguinity, are complex and include over 100 known dis- Molecular docking, Molecular dynamics. ease-causing genes, but many causative genes are unknown. We aimed to identify the causative gene for DCM in a consanguineous Saudi Ara- bian family with affected family members and a history of sudden death. Introduction PATIENTS AND METHODS: Affected (two chil- dren) and unaffected (one sibling and the mother) Dilated cardiomyopathy (DCM) is a heart family members were screened by next-gener- ation sequencing (NGS) for 181 candidate DCM disease characterized by ventricular dilation and genes and underwent metabolic screening. Fif- impaired myocardial contractility. DCM affects ty-seven clinically annotated controls and 46 DCM 1 in 2500 of the general population and is one of cases were then tested for the identified mutation. -

Genomic and Transcriptome Analysis Revealing an Oncogenic Functional Module in Meningiomas
Neurosurg Focus 35 (6):E3, 2013 ©AANS, 2013 Genomic and transcriptome analysis revealing an oncogenic functional module in meningiomas XIAO CHANG, PH.D.,1 LINGLING SHI, PH.D.,2 FAN GAO, PH.D.,1 JONATHAN RUssIN, M.D.,3 LIYUN ZENG, PH.D.,1 SHUHAN HE, B.S.,3 THOMAS C. CHEN, M.D.,3 STEVEN L. GIANNOTTA, M.D.,3 DANIEL J. WEISENBERGER, PH.D.,4 GAbrIEL ZADA, M.D.,3 KAI WANG, PH.D.,1,5,6 AND WIllIAM J. MAck, M.D.1,3 1Zilkha Neurogenetic Institute, Keck School of Medicine, University of Southern California, Los Angeles, California; 2GHM Institute of CNS Regeneration, Jinan University, Guangzhou, China; 3Department of Neurosurgery, Keck School of Medicine, University of Southern California, Los Angeles, California; 4USC Epigenome Center, Keck School of Medicine, University of Southern California, Los Angeles, California; 5Department of Psychiatry, Keck School of Medicine, University of Southern California, Los Angeles, California; and 6Division of Bioinformatics, Department of Preventive Medicine, Keck School of Medicine, University of Southern California, Los Angeles, California Object. Meningiomas are among the most common primary adult brain tumors. Although typically benign, roughly 2%–5% display malignant pathological features. The key molecular pathways involved in malignant trans- formation remain to be determined. Methods. Illumina expression microarrays were used to assess gene expression levels, and Illumina single- nucleotide polymorphism arrays were used to identify copy number variants in benign, atypical, and malignant me- ningiomas (19 tumors, including 4 malignant ones). The authors also reanalyzed 2 expression data sets generated on Affymetrix microarrays (n = 68, including 6 malignant ones; n = 56, including 3 malignant ones). -

Differentially Methylated Genes
10/30/2013 Disclosures Key Rheumatoid Arthritis-Associated Pathogenic Pathways Revealed by Integrative Analysis of RA Omics Datasets Consultant: IGNYTA Funding: Rheumatology Research Foundation By John W. Whitaker, Wei Wang and Gary S. Firestein DNA methylation and gene regulation The RA methylation signature in FLS DNA methylation – DNMT1 (maintaining methylation) OA – DNMT3a, 3b (de novo methylation) RA % of CpG methylation: 0% 100% Nakano et al. 2013 ARD AA06 AANAT AARS ABCA6 ABCC12 ABCG1 ABHD8 ABL2 ABR ABRA ACACA ACAN ACAP3 ACCSL ACN9 ACOT7 ACOX2 ACP5 ACP6 ACPP ACSL1 ACSL3 ACSM5 ACVRL1 ADAM10 ADAM32 ADAM33 ADAMTS12 ADAMTS15 ADAMTS19 ADAMTS4 ADAT3 ADCK4 ADCK5 ADCY2 ADCY3 ADCY6 ADORA1 ADPGK ADPRHL1 ADTRP AFAP1 AFAP1L2 AFF3 AFG3L1P AGAP11 AGER AGTR1 AGXT AIF1L AIM2 AIRE AJUBA AK4 AKAP12 AKAP2 AKR1C2 AKR1E2 AKT2 ALAS1 ALDH1L1-AS1 ALDH3A1 ALDH3B1 ALDH8A1 ALDOB ALDOC ALOX12 ALPK3 ALS2CL ALX4 AMBRA1 AMPD2 AMPD3 ANGPT1 ANGPT2 ANGPTL5 ANGPTL6 ANK1 ANKMY2 ANKRD29 ANKRD37 ANKRD53 ANO3 ANO6 ANO7 ANP32C ANXA6 ANXA8L2 AP1G1 AP2A2 AP2M1 AP5B1 APBA2 APC APCDD1 APOBEC3B APOBEC3G APOC1 APOH APOL6 APOLD1 APOM AQP1 AQP10 AQP6 AQP9 ARAP1 ARHGAP24 ARHGAP42 ARHGEF19 ARHGEF25 ARHGEF3 ARHGEF37 ARHGEF7 ARL4C ARL6IP 5 ARL8B ARMC3 ARNTL2 ARPP21 ARRB1 ARSI ASAH2B ASB10 ASB2 ASCL2 ASIC4 ASPH ATF3 ATF7 ATL1 ATL3 ATP10A ATP1A1 ATP1A4 ATP2C1 ATP5A1 ATP5EP2 ATP5L2 ATP6V0CP3 ATP6V1C1 ATP6V1E2 ATXN7L1 ATXN7L2 AVPI1 AXIN2 B3GNT7 B3GNT8 B3GNTL1 BACH1 BAG3 Differential methylated genes in RA FLS BAIAP2L2 BANP BATF BATF2 BBS2 BCAS4 BCAT1 BCL7C BDKRB2 BEGAIN BEST1 BEST3 -

NIH Public Access Author Manuscript FEBS Lett
NIH Public Access Author Manuscript FEBS Lett. Author manuscript; available in PMC 2011 May 17. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: FEBS Lett. 2010 May 17; 584(10): 2102±2111. doi:10.1016/j.febslet.2010.01.037. Chloride Channels of Intracellular Membranes John C. Edwards* and Christina R. Kahl UNC Kidney Center and the Division of Nephrology and Hypertension, Department of Medicine, University of North Carolina at Chapel Hill Abstract Proteins implicated as intracellular chloride channels include the intracellular ClC proteins, the bestrophins, the cystic fibrosis transmembrane conductance regulator, the CLICs, and the recently described Golgi pH regulator. This paper examines current hypotheses regarding roles of intracellular chloride channels and reviews the evidence supporting a role in intracellular chloride transport for each of these proteins. Keywords chloride channel; ClC; CLIC; bestrophin; GPHR The study of chloride channels of intracellular membranes has seen enormous advances over the past two decades and exciting recent developments have sparked renewed interest in this field. The discovery of important roles for intracellular chloride channels in human disease processes as diverse as retinal macular dystrophy, osteopetrosis, renal proximal tubule dysfunction, and angiogenesis have highlighted the importance of these molecules in critical cellular activities. Startling discoveries regarding the intracellular ClC family of proteins have forced a re-examination -

Downregulation of Carnitine Acyl-Carnitine Translocase by Mirnas
Page 1 of 288 Diabetes 1 Downregulation of Carnitine acyl-carnitine translocase by miRNAs 132 and 212 amplifies glucose-stimulated insulin secretion Mufaddal S. Soni1, Mary E. Rabaglia1, Sushant Bhatnagar1, Jin Shang2, Olga Ilkayeva3, Randall Mynatt4, Yun-Ping Zhou2, Eric E. Schadt6, Nancy A.Thornberry2, Deborah M. Muoio5, Mark P. Keller1 and Alan D. Attie1 From the 1Department of Biochemistry, University of Wisconsin, Madison, Wisconsin; 2Department of Metabolic Disorders-Diabetes, Merck Research Laboratories, Rahway, New Jersey; 3Sarah W. Stedman Nutrition and Metabolism Center, Duke Institute of Molecular Physiology, 5Departments of Medicine and Pharmacology and Cancer Biology, Durham, North Carolina. 4Pennington Biomedical Research Center, Louisiana State University system, Baton Rouge, Louisiana; 6Institute for Genomics and Multiscale Biology, Mount Sinai School of Medicine, New York, New York. Corresponding author Alan D. Attie, 543A Biochemistry Addition, 433 Babcock Drive, Department of Biochemistry, University of Wisconsin-Madison, Madison, Wisconsin, (608) 262-1372 (Ph), (608) 263-9608 (fax), [email protected]. Running Title: Fatty acyl-carnitines enhance insulin secretion Abstract word count: 163 Main text Word count: 3960 Number of tables: 0 Number of figures: 5 Diabetes Publish Ahead of Print, published online June 26, 2014 Diabetes Page 2 of 288 2 ABSTRACT We previously demonstrated that micro-RNAs 132 and 212 are differentially upregulated in response to obesity in two mouse strains that differ in their susceptibility to obesity-induced diabetes. Here we show the overexpression of micro-RNAs 132 and 212 enhances insulin secretion (IS) in response to glucose and other secretagogues including non-fuel stimuli. We determined that carnitine acyl-carnitine translocase (CACT, Slc25a20) is a direct target of these miRNAs. -

Normalized Expression Values *
Normalized expression values 0.0 0.2 0.4 0.6 0.8 1.0 1.2 PLCG1 * T CD5 MP T B TCF7 cDC UBASH3A BCL11B C5AR1 * MP TLR4 CXCR5 B CD79B VPREB3 XCR1 CADM1 BEND5 * ARGHAP22 * cDC CIITA ZBTB46 FLT3 PLEKHA5 Figure S1. qPCR analysis of the core gene expression signature of cDC, MP, B and T cells in the chicken cell suBsets. RNA from cDC, MP, T and B cells of 2 disUnct pools of 4 chicken spleen was subjected to qPCR detecUon of the core gene expression signatures of immune cell subsets established in Fig. 3 and of transcripts from the mouse and human gene subset selected compendia that could not be detected on the array due to defecUve probes, i.e. ARGHAP22, BEND5, C5AR1, and PLCG1 (labeled by a star on the figure). Data are represented as the mean and SD of relave gene expression levels normalized to GAPDH expression and the maximal expression across the cell types was set to 1 (independent experimental duplicates). B cell T cell cDC Monocyte/MP Chicken Human Mouse Figure S2. Unsupervised hierarchical clustering of orthologous immune response genes across chicken, human and mouse reveals globally conserved clusters of lymphoïd- specific and myeloïd- specific genes. Heatmap of cross-normalized expression profiles for immune response genes present on all three species arrays and regulated at least 2 folds across all cell suBsets, including chicken B cells (c_B), T cells (c_CD3), MP (c_MP) and cDC (c_cDC), human B cells (h_B), T cells (h_CD4_T and h_CD8_T), monocyte-derived MP (h_MoMP), peripheral blood mononucleated cell-derived MP (h_PBMC_MP), non-classical monocytes (h_non- classical_MO), classical monocytes (h_classical_MO), BDCA3+ cDC (h_BDCA3), BDCA1+ cDC (h_BDCA1), murine B cells (m_B), T cells (m_CD4_T and m_CD8_T), peritoneal cavity MP (m_PC_MPII-480HI), lung MP (m_LU_MP), non-classical monocytes (m_non-classical_MO), classical monocytes (m_classical_MO), splenic CD8α+ cDC (m_SP_DC1), suBcutaneous lymph node CD8α+ cDC (m_LN_DC1), splenic CD11B+ cDC (m_SP_DC2), suBcutaneous lymph node CD11B+ cDC (m_LN_DC2). -

Perkinelmer Genomics to Request the Saliva Swab Collection Kit for Patients That Cannot Provide a Blood Sample As Whole Blood Is the Preferred Sample
Autism and Intellectual Disability TRIO Panel Test Code TR002 Test Summary This test analyzes 2429 genes that have been associated with Autism and Intellectual Disability and/or disorders associated with Autism and Intellectual Disability with the analysis being performed as a TRIO Turn-Around-Time (TAT)* 3 - 5 weeks Acceptable Sample Types Whole Blood (EDTA) (Preferred sample type) DNA, Isolated Dried Blood Spots Saliva Acceptable Billing Types Self (patient) Payment Institutional Billing Commercial Insurance Indications for Testing Comprehensive test for patients with intellectual disability or global developmental delays (Moeschler et al 2014 PMID: 25157020). Comprehensive test for individuals with multiple congenital anomalies (Miller et al. 2010 PMID 20466091). Patients with autism/autism spectrum disorders (ASDs). Suspected autosomal recessive condition due to close familial relations Previously negative karyotyping and/or chromosomal microarray results. Test Description This panel analyzes 2429 genes that have been associated with Autism and ID and/or disorders associated with Autism and ID. Both sequencing and deletion/duplication (CNV) analysis will be performed on the coding regions of all genes included (unless otherwise marked). All analysis is performed utilizing Next Generation Sequencing (NGS) technology. CNV analysis is designed to detect the majority of deletions and duplications of three exons or greater in size. Smaller CNV events may also be detected and reported, but additional follow-up testing is recommended if a smaller CNV is suspected. All variants are classified according to ACMG guidelines. Condition Description Autism Spectrum Disorder (ASD) refers to a group of developmental disabilities that are typically associated with challenges of varying severity in the areas of social interaction, communication, and repetitive/restricted behaviors.