Annual Conference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hamilton County (Ohio) Naturalization Records – Surname M
Hamilton County Naturalization Records – Surname M Applicant Age Country of Origin Departure Date Departure Port Arrive Date Entry Port Declaration Dec Date Vol Page Folder Naturalization Naturalization Date Maag, Frederick 46 Oldenburg Bremen New Orleans T 11/01/1852 5 132 F F Maag, Frederick 46 Oldenburg Bremen New Orleans T 11/01/1854 6 258 F F Maag, Sebastian 31 Baden Liverpool New York T 01/02/1858 16 296 F F Maahan, James 32 Ireland Toronto Buffalo T 01/20/1852 24 37 F F Maas, Anton 30 Prussia Bremen New York T 01/17/1853 7 34 F F Maas, Carl 18 Mannheim, Germany ? ? T 05/04/1885 T F Maas, Garrett William 25 Holland Rotterdam New York T 11/15/1852 5 287 F F Maas, Garrett William 25 Holland Rotterdam New York T 11/15/1852 6 411 F F Maas, Jacob 55 Germany Rotterdam New York F ? T T Maas, John 55 Germany Havre New York F ? T T Maas, John William 28 Holland Rotterdam New Orleans T 09/27/1848 22 56 F F Maas, Julius J. 48 Germany Bremen New York F ? T T Maas, Leonardus Aloysius 37 Holland Rotterdam New Orleans T 03/01/1852 24 6 F F Maass, F.W. 45 Hanover Bremen Baltimmore T 11/02/1860 18 3 F F Macalusa, Michael 23 Italy Palermo New York T 3/18/1903 T F MacAvoy, Henry 48 England Liverpool New York T 10/26/1891 T F MacDermott, Joseph England ? ? T 2/26/1900 T F Machenheimer, Christoph 29 Hesse Darmstadt Havre New York T 02/19/1850 2 100 F F Machnovitz, Moses 50 Russia Bremen Baltimore T 4/27/1900 T F Maciejensky, Martin 28 Prussia Hamburg New York T 04/28/1854 8 280 F F Maciejensky, Martin 28 Prussia Hamburg New York T 04/28/1854 9 151 F -

Summary by Title
Summary NEWLAWS 2002 Summary by Title RESOLUTIONS No-fault automobile insurance full medical Resolution supporting personnel responding to expense benefits entitlement..................................................................................94 Sept. 11 terrorist attacks. ..............................................................................................89 Automobile insurance damaged window glass claims Resolution urging delayed termination of LTV pension plan. .........................89 payment basis modified. .............................................................................................94 Real estate industry licensee conduct regulated. ...................................................95 AGRICULTURE POLICY Fire insurance excess coverage prohibitions..............................................................95 Insurance provisions modification; medical malpractice insurance Biodiesel fuel mandate. ............................................................................................................89 Joint Underwriting Association issuance prohibition. .............................95 Phosphorus fertilizer use regulated. ................................................................................89 Cities additional liquor licenses; hotel rooms liquor cabinets Pesticides application prohibition exceptions (gypsy moth bill). .................90 hours of sale restrictions exemption. ..................................................................95 Omnibus agriculture policy bill. .........................................................................................90 -

Minn. GOP Wants Bachmann for Sen., Pawlenty for Pres
FOR IMMEDIATE RELEASE December 10, 2010 INTERVIEWS: DEAN DEBNAM 888-621-6988 / 919-880-4888 (serious media inquiries only please, other questions can be directed to Tom Jensen) QUESTIONS ABOUT THE POLL: TOM JENSEN 919-744-6312 Minn. GOP wants Bachmann for Sen., Pawlenty for Pres. Raleigh, N.C. – Despite getting no love from the state’s at-large electorate against President Obama in PPP’s Wednesday release, outgoing Minnesota Governor Tim Pawlenty is the slim favorite of his own party faithful to get the state’s Republican National Convention delegates. In the race to take on popular Senator Amy Klobuchar, however, he does less well despite coming closest to beating Klobuchar in Tuesday’s look at the general election. Instead, newly empowered Congresswoman Michele Bachman is overwhelmingly the darling of hardcore GOP voters. Bachmann pulls 36% support from usual GOP primary voters, with a wide margin over Pawlenty’s 20%, Norm Coleman’s 14%, and a host of prospective contenders bunched in single digits: 8th-District Congressman-elect Chip Cravaack at 7%, Tom Emmer at 6%, 2nd-District Congressman John Kline at 5%, state legislator Laura Brod at 4%, and Erik Paulsen at 2%, with 6% undecided or favoring someone else. Pawlenty trails Klobuchar by only ten points, versus Bachmann’s 18 and Coleman’s 14. There is a huge ideological divide at play. Bachmann, founder of the Congressional Tea Party Caucus, gets a whopping 42% from the conservative supermajority, which makes up almost three-quarters of the electorate. That puts her far ahead of second-place Pawlenty’s 19%. -

Capitol Insurrection at Center of Conservative Movement
Capitol Insurrection At Center Of Conservative Movement: At Least 43 Governors, Senators And Members Of Congress Have Ties To Groups That Planned January 6th Rally And Riots. SUMMARY: On January 6, 2021, a rally in support of overturning the results of the 2020 presidential election “turned deadly” when thousands of people stormed the U.S. Capitol at Donald Trump’s urging. Even Senate Republican leader Mitch McConnell, who rarely broke with Trump, has explicitly said, “the mob was fed lies. They were provoked by the President and other powerful people.” These “other powerful people” include a vast array of conservative officials and Trump allies who perpetuated false claims of fraud in the 2020 election after enjoying critical support from the groups that fueled the Capitol riot. In fact, at least 43 current Governors or elected federal office holders have direct ties to the groups that helped plan the January 6th rally, along with at least 15 members of Donald Trump’s former administration. The links that these Trump-allied officials have to these groups are: Turning Point Action, an arm of right-wing Turning Point USA, claimed to send “80+ buses full of patriots” to the rally that led to the Capitol riot, claiming the event would be one of the most “consequential” in U.S. history. • The group spent over $1.5 million supporting Trump and his Georgia senate allies who claimed the election was fraudulent and supported efforts to overturn it. • The organization hosted Trump at an event where he claimed Democrats were trying to “rig the election,” which he said would be “the most corrupt election in the history of our country.” • At a Turning Point USA event, Rep. -

NRCC: MN-07 “Vegas, Baby”
NRCC: MN-07 “Vegas, Baby” Script Documentation AUDIO: Taxpayers pay for Colin Peterson’s Since 1991, Peterson Has Been Reimbursed At personal, private airplane when he’s in Minnesota. Least $280,000 For Plane Mileage. (Statement of Disbursements of House, Chief Administrative Officer, U.S. House of Representatives) (Receipts and Expenditures: Report of the Clerk of TEXT: Collin Peterson the House, U.S. House of Representatives) Taxpayers pay for Peterson’s private plane Statement of Disbursements of House AUDIO: But do you know where else he’s going? Peterson Went Las Vegas On Trip Sponsored By The Safari Club International From March AUDIO: That’s right. Vegas, Baby. Vegas. 22, 2002 To March 25, 2002 Costing, $1,614. (Collin Peterson, Legistorm, Accessed 3/17/14) Peterson Went Las Vegas On Trip Sponsored By The American Federation Of Musicians From June 23, 2001 To June 25, 2001, Costing $919. (Collin Peterson, Legistorm, Accessed 3/17/14) Peterson Went Las Vegas On Trip Sponsored By The Safari Club International From January 11, 2001 To January 14, 2001, Costing $918.33. (Collin Peterson, Legistorm, Accessed 3/17/14) AUDIO: Colin Peterson took 36 junkets. Vacation- Throughout His Time In Congress, Peterson like trips, paid for by special interest groups. Has Taken At Least 36 Privately Funded Trip Worth $57,942 (Collin Peterson, Legistorm, Accessed 3/17/14) TEXT: 36 Junkets paid for by special interest groups See backup below Legistorm AUDIO: In Washington, Peterson took $6 million in Collin Peterson Took $6.7 Million In Campaign campaign money from lobbyists and special Money From Special Interest Group PACs interests. -

Freshman Class of the 110Th Congress at a Glance
Freshman Class of the 110th Congress at a Glance NEW HOUSE MEMBERS BY DISTRICT Position on Position on District Republican Democrat1 Winner Immigration Immigration Border security with AZ-05 J.D. Hayworth Enforcement first Harry E. Mitchell Mitchell • guest worker program Employer sanctions; Randy Graf AZ-08 Enforcement first Gabrielle Giffords “comprehensive Giffords (Jim Kolbe) reform” “Comprehensive CA-11 Richard W. Pombo• Enforcement first Jerry McNerney reform” and “path to McNerney citizenship” Kevin McCarthy Enforcement and tighter CA-22 Sharon M. Beery No clear position McCarthy (Bill Thomas) border security Doug Lamborn Tighter security; CO-05 Jay Fawcett Enforcement first Lamborn (Joel Hefley) opposes amnesty “Comprehensive Rick O’Donnell Enforcement first; CO-07 Ed Perlmutter reform” and “path to Perlmutter (Bob Beauprez) employer sanctions citizenship” CT-02 Bob Simmons• Enforcement first Joe Courtney Employer Sanctions Courtney Supports tighter border CT-05 Nancy L. Johnson Christopher S. Murphy “Path to citizenship” Murphy • security 1For simplification, this column also includes Independents. Incumbent Retiring incumbent Vacating to run for higher office Resigning Lost in the primary Position on Position on District Republican Democrat1 Winner Immigration Immigration Gus Bilirakis FL-09 Enforcement first Phyllis Busansky Supports border security Bilirakis (Michael Bilirakis) Kathy Castor “Comprehensive FL-11 Eddie Adams Opposes amnesty Castor (Jim Davis) reform” Supports enforcement, Vern Buchanan Employer sanctions; FL-13 tighter security; Christine Jennings Buchanan (Katherine Harris) “path to citizenship” opposes amnesty Supports border Joe Negron FL-16 Tighter border security Tim Mahoney security; “path to Mahoney (Mark Foley) citizenship” “Comprehensive reform”; FL-22 E. Clay Shaw Ron Klein Employer sanctions Klein • guest worker program Hank Johnson “Comprehensive GA-04 Catherine Davis Enforcement first; removal (Cynthia A. -

Donald Trump, Twitter, and Islamophobia: the End of Dignity in Presidential Rhetoric About Terrorism
Montclair State University Montclair State University Digital Commons Department of Justice Studies Faculty Scholarship and Creative Works Department of Justice Studies Spring 3-22-2020 Donald Trump, Twitter, and Islamophobia: The End of Dignity in Presidential Rhetoric about Terrorism Gabriel Rubin Follow this and additional works at: https://digitalcommons.montclair.edu/justice-studies-facpubs Part of the Administrative Law Commons, International Humanitarian Law Commons, International Law Commons, Legal Ethics and Professional Responsibility Commons, Legal Profession Commons, Near and Middle Eastern Studies Commons, Peace and Conflict Studies Commons, Place and Environment Commons, President/Executive Department Commons, Public Administration Commons, Public Affairs Commons, Public Policy Commons, Social Justice Commons, and the Terrorism Studies Commons Chapter Four Donald Trump, Twitter, and Islamophobia: The End of Dignity in Presidential Rhetoric about Terrorism Presidential rhetoric is critically important in guiding American foreign and domestic policy as well as in determining which threats are pursued by the U.S. government1. After the September 11 attacks, terrorism was touted as a threat that would “never again” be ignored. This threat was repeatedly harped on by Presidents George W. Bush and Barack Obama. After Bush set the agenda for an expansive terror war and a presidential rhetoric replete with fear, Obama attempted to recalibrate and narrow the war on terror but ended up largely maintaining Bush’s policies and falling into some of Bush’s rhetoric regarding the terror threat. President Donald Trump, who campaigned viciously against Obama’s legacy, also did not change much in terms of terrorism policy. Even so, the rhetoric adopted by Trump has upended decades of presidential decorum and dignity in the way he speaks about terrorists and the brazen way he links terrorism to the negatives he attaches to immigration. -

June 26, 2011 Transcript
© 2011, CBS Broadcasting Inc. All Rights Reserved. PLEASE CREDIT ANY QUOTES OR EXCERPTS FROM THIS CBS TELEVISION PROGRAM TO "CBS NEWS' FACE THE NATION." June 26, 2011 Transcript GUEST: REPRESENTATIVE MICHELE BACHMANN R-Minnesota; Republican Presidential Candidate MODERATOR/ PANELIST: Bob Schieffer, CBS News Political Analyst This is a rush transcript provided for the information and convenience of the press. Accuracy is not guaranteed. In case of doubt, please check with FACE THE NATION - CBS NEWS (202) 457-4481 TRANSCRIPT BOB SCHIEFFER: Today on FACE THE NATION, who is Michele Bachmann and why does she want to be President. Critics had dismissed her as a religious zealot and a shoot from the hip extremist. But the conservative journal Weekly Standard puts her on the cover this week and calls her Queen of the Tea Party. And the poll out this morning shows that she and Mitt Romney have a big lead over the other Republican candidates in Iowa. That after rave reviews in the first campaign debate in New Hampshire. REPRESENTATIVE MICHELE BACHMANN (R-Minnesota/Republican Presidential Candidate): President Obama is a one-term President. BOB SCHIEFFER: So how broad is her appeal? Tomorrow in Iowa, she announces officially that she’s running for the Republican nomination. Today, she’s in our studio to tell us how and why she is doing. It’s all ahead on FACE THE NATION. ANNOUNCER: FACE THE NATION with CBS News chief Washington correspondent Bob Schieffer. And now from Washington, Bob Schieffer. BOB SCHIEFFER: And good morning again and welcome to FACE THE NATION. Well, Congresswoman, your day is off to-- I would say to a very good start. -

Extensions of Remarks E763 HON. MICHELE BACHMANN HON. BRADLEY S. SCHNEIDER HON. HENRY C
CONGRESSIONAL RECORD — Extensions of Remarks E763 PERSONAL EXPLANATION TRIBUTE TO PASTOR JOSEPH stood as a location for work relief for the Civil- WILLIAMS, SR. ian Conservation Corps. In 1940, the national forest was ceded to the War Department to be HON. MICHELE BACHMANN HON. HENRY C. ‘‘HANK’’ JOHNSON, JR. used for a proving ground for aircraft arma- OF MINNESOTA OF GEORGIA ment. Major General William E. Kepner, who served as the Commanding General of the Air IN THE HOUSE OF REPRESENTATIVES IN THE HOUSE OF REPRESENTATIVES Proving Ground, helped preserve the site of Monday, May 19, 2014 Monday, May 19, 2014 Camp Pinchot, and today it is home to Eglin Mrs. BACHMANN. Mr. Speaker, due to re- Mr. JOHNSON of Georgia. Mr. Speaker, I Air Force Base Commander’s quarters. sponsibilities within my district I would like to submit the following Proclamation. Mr. Speaker, surrounded by live oaks submit how I intended to vote on the following: Whereas, Pastor Joseph Williams, Sr., is draped with Spanish moss, Camp Pinchot to this day maintains the turn of the century spirit Tuesday May 6—‘‘yes’’ on rollcall 194; celebrating today thirty-two (32) years as Pas- of a quiet and simple life, and I am honored ‘‘yes’’ on rollcall 195; ‘‘yes’’ on rollcall 196. tor of Greater Moses Baptist Church; and Whereas, Pastor Williams, under the guid- to commemorate its one hundred years of ex- Thursday, May 8—‘‘yes’’ on rollcall 205; ance of God has pioneered and sustained istence. ‘‘yes’’ on rollcall 206; ‘‘yes’’ on rollcall 207; Greater Moses Baptist Church, as an instru- f ‘‘no’’ on rollcall 208; ‘‘yes’’ on rollcall 209. -

Counties C Thru E
Official Results CERTIFICATE OF DETERMINATION AND/OR ··..., .:- " ,, ,.,:- r:- ; c- .... rr -.. , , .. ·--.. - - ·- .. -· . " OFFICIAL CANVASS 7"'7•·· J { ? t. l, • 1.. I.;," I '- STATE OF MICHIGAN } '~ ~ . I -3 } ss [. --- ,.r- . ... .. COUNTY OF CALHOUN } The Board of Canvassers of the County of Calhoun, having Ascertained and Canvassed the Votes of the County of Calhoun. for the said Presidential Primary Election, held on TUESDAY, the TWENTY-EIGHTH day of FEBRUARY 2012. DO HEREBY CERTIFY AND DETERMINE THAT THE FOLLOWING VOTES WERE CAST: That, Michele Bachmann, received 24 (Twenty-four) votes by the Republican Party for the office of President of the United States. These votes were received in the following districts: 6th Congressional District: 1 (One) vote; 7th Congressional District: 23 (Twenty-three) votes. That. Herman Cain, received 25 (Twenty-five) votes by the Republican Party for the office of President of the United States. These votes were received in the following districts: 6th Congressional District: 0 (Zero) votes; 7th Congressional District: 25 (Twenty-five) votes. That, Newt Gingrich, received 1,086 (One thousand, eighty-six) votes by the Republican Party for the office of President of the United States. These votes were received in the following districts: 6th Congressional District: 78 (Seventy-eight) votes; 7th Congressional District: 1,008 (One thousand eight) votes. That, Jon Huntsman, received 14 (Fourteen) votes by the Republican Party for the office of President of the United States. These votes were received in the following districts: 6th Congressional District: 2 (Two) votes; 7th Congressional District: 12 (Twelve) votes. That, Gary Johnson, received 6 (Six) votes by the Republican Party for the office of President of the United States. -

Going Off the Rails on a Crazy Train: the Causes and Consequences of Congressional Infamy
The Forum Volume 9, Issue 2 2011 Article 3 Going off the Rails on a Crazy Train: The Causes and Consequences of Congressional Infamy Justin Buchler, Case Western Reserve University Recommended Citation: Buchler, Justin (2011) "Going off the Rails on a Crazy Train: The Causes and Consequences of Congressional Infamy," The Forum: Vol. 9: Iss. 2, Article 3. DOI: 10.2202/1540-8884.1434 Available at: http://www.bepress.com/forum/vol9/iss2/art3 ©2011 Berkeley Electronic Press. All rights reserved. Going off the Rails on a Crazy Train: The Causes and Consequences of Congressional Infamy Justin Buchler Abstract Legislators like Michele Bachmann and Alan Grayson become nationally infamous for their provocative behavior, yet there is little scholarly attention to such infamy. This paper examines the predictors of congressional infamy, along with its electoral consequences. First, infamy is measured through the frequency with which internet users conduct searches of legislators’ names, paired with epithets attacking their intelligence or sanity. Then, ideological extremism and party leadership positions are shown to be the best statistical predictors. The electoral consequences of infamy follow: infamous legislators raise more money than their lower-profile colleagues, but their infamy also helps their challengers to raise money. In the case of House Republicans, there appears to be an additional and direct negative effect of infamy on vote shares. The fundraising effect is larger in Senate elections, but there is no evidence of direct electoral cost for infamous senatorial candidates. KEYWORDS: Congress, Elections, polarizing, internet Author Notes: Justin Buchler is an Associate Professor of Political Science at Case Western Reserve University. -
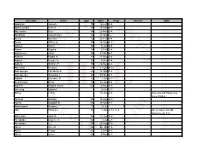
Surname Given Age Date Page Maiden Note Abdullah Joseph 70 5-Feb A-8 Abercrombie Bert H
Surname Given Age Date Page Maiden Note Abdullah Joseph 70 5-Feb A-8 Abercrombie Bert H. 88 29-Dec B-9 Abernathy Kate 84 22-Nov B-4 Abraham Joseph Ben 86 21-Mar D-2 Acela Michael 73 23-Feb A-4 Achor Arthur A. 58 16-Sep A-11 Adalay Steve 92 6-Jan B-6 Adam Sophia 78 3-Feb B-4 Adamczyk John 85 21-Oct B-7 Adams Edwin B. 81 27-Aug B-4 Adank Cassie R. 75 7-Dec A-4 Adank William F. 76 24-Dec A-8 Adelman Irving D. 59 31-Oct D-10 Adelsperger Elizabeth A. 60 18-Mar A-8 Adelsperger Susanna T. 82 25-Oct A-7 Adoba Michael, Sr. 80 1-Jun A-12 Aeschliman Betty 32 18-Jan B-4 Aguirre Regina Avilla 63 4-Nov A-6 Ahlering Edward 6-Oct C-7 Ahley Lillian 15-Jun A-6 Also spelled Haley see June 16 E-2 Ahmed Hassan 68 13-Aug A-9 Akers Edward W. 66 16-Mar A-7 Aksentijevic Rodney 15 8-Jul 1 Alb Florence 70 1-Jun A-12, C-5 Gives name as Alb Florence on C-5 Albertson Jack R. 59 11-Jun C-2 Alexander Eugene A. 62 7-Jul C-8 Alexander L.C. 58 20-Aug B-3 Allen Cleo D. 66 26-Jan A-6 Allen Frosty 65 2-Dec B-6 Allen Grace 65 9-Nov B-3 Allen James Virgil 55 19-Aug A-4 Allen Weber 62 2-Mar A-4 Alley George Wesley 54 4-Jan A-5 Alonzo Maria 73 15-Oct B-5 Altshuller Nathan D.